ECCV 2022 | MVDG:一种用于域泛化的统一多视图框架
前言 论文提出了一种新的多视图分布式目标框架,以有效地减少训练和测试阶段的过拟合。
具体来说就是,在训练阶段,开发了一种多视图正则化元学习算法,利用多个优化轨迹产生适合模型更新的优化方向。在测试阶段,利用多幅增强图像进行多视图预测,缓解了预测不稳定的问题,显著提高了模型的可靠性。
在三个基准数据集上的大量实验验证了本文方法可以找到一个平坦的最小值来增强泛化,并优于几种SOTA的方法。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。目前公众号正在征稿中,可以获取对应的稿费哦。
QQ交流群: 444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。

论文:https://arxiv.org/pdf/2112.12329.pdf
代码:https://github.com/koncle/MVDG
创新思路
传统的监督学习假设训练数据和测试数据来自同一个分布。然而,当训练数据和测试数据之间存在域转移时,这种传统的假设在现实世界中并不总是满足。最近,学习一个鲁棒和有效的模型来对抗域转移引起了相当多的关注。
无监督域适应(unsupervised domain adaption, UDA)是域变换下最具代表性的学习范式之一,旨在解决在领域变换下由标记源域向未标记目标域的适应问题。
尽管目前的UDA模型取得了巨大的成功,但是将之前训练好的UDA模型部署到其他不可见区域时,需要将新收集的不可见区域的数据重新训练模型。这种再训练过程不仅增加了额外的空间/时间成本,而且在某些情况下(例如,临床数据)还违反了隐私政策,使得这些UDA方法不适用于某些实际任务。
而在DG中,只需要从已有的源域学习相关知识,就可以将训练好的模型直接应用到以前没有见过的域上,而不需要再进行训练。为了保证模型在不可见的目标域上的有效性,以往的DG方法是通过学习域不变表示来减少源域对特定域的影响,但不可避免地存在过拟合的问题。
因此,基于元学习的方法已经成为训练中最受欢迎的抵抗过拟合的方法之一,它偶然性地模拟域转移进行正则化。然而,这些方法在每次迭代中只使用一个任务来训练它们的模型,这可能会导致有偏差和噪声的优化方向。
此外,在研究了训练模型在测试阶段的预测后,过拟合也会导致预测不稳定。作者通过对测试图像进行扰动(例如,随机裁剪和翻转)来进行实验。如图1所示,预测在受到扰动后通常会发生变化。
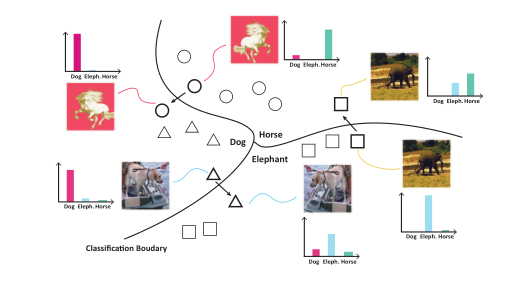
图1:PACS数据集上测试图像在不可见区域受到轻微扰动时,预测概率的变化示例。
如上所述,过拟合问题不仅出现在训练阶段,而且很大程度上也影响了测试过程。为了防止过拟合,本文提出了一种多视图框架来处理泛化能力较差和预测不稳定的问题。
本文的主要贡献
1、在训练中,设计了一个有效的多视图正则化元学习方案,以防止过拟合,并找到一个平坦的最小值,可以更好地泛化。
2、从理论上证明了增加训练阶段的任务数量可以使泛化差距变小,泛化性更好。
3、在测试阶段,引入了一种多视图预测策略,通过利用多视图信息来提高预测的可靠性。
4、本文的方法在多个DG基准数据集上进行了广泛的实验,并优于其他SOTA方法。
方法
情景训练框架
假设数据空间和标签空间分别为X和Y,N个源域为D1,…, DN,将θ参数化的模型记为f。
给定输入x,模型输出f(x|θ),将一个域作为元测试域Dte,其余域作为元序列域Dtr。然后从这些域抽取小批量样本,得到元序列Btr和元测试数据Bte。参数θ定义B上的损失:
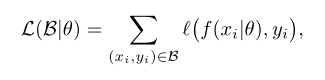
与以往采用二阶梯度更新模型参数的元学习算法不同,Reptile是一阶算法,以降低计算成本。因此,采用MLDG的Reptile版本。在第j次迭代时,给定模型参数θj,先用L(Btr|θj),再用L(Bte|θj)训练模型。然后,得到沿该优化轨迹的临时更新参数θtmp。
最后,以(θtmp−θj)为优化方向,更新原始参数θj:
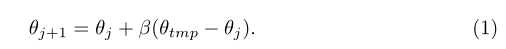
这样,θtmp就可以利用一部分当前权值空间,为当前采样任务找到一个更好的优化方向。
多视图正则化元学习
虽然Reptile降低了计算成本,但上述训练方案存在几个问题。
1、模型沿单一优化轨迹训练,只产生一个临时参数θtmp。
2、由于该模型在每个轨迹中使用单个任务进行训练,因此它无法充分探索权重空间,并且难以逃避局部极小值,从而导致过拟合问题。
为了更好地探索权重空间以获得更精确的优化方向并消除过度拟合的影响,通过在每次迭代中利用多视图信息,设计了一种简单而有效的多视图正则化元学习(MVRML)算法。
具体而言,为了找到稳健的优化方向,将沿着不同的优化轨迹获得T个临时参数{θ1tmp,…,θTtmp}。与MLDG不同,使用s个采样任务训练每个临时参数,以帮助其脱离局部最小值。
此外,在不同的轨迹中对不同的任务进行采样,以鼓励临时模型的多样性。从这些任务中学习可以利用补充视图探索权重空间中的不同信息。完整算法如算法1所示,如图2所示。

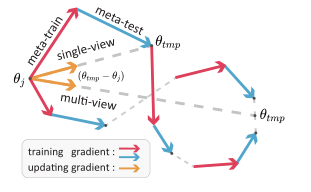
图2:Reptile和多视图正则化元学习算法的图示。
多视图预测
由于本文的模型是在源域内训练的,因此学习到的数据的特征表示是很好聚类的。然而,当出现不可见的图像时,由于过拟合和域差异,这些图像更容易靠近决策边界,导致特征表示不稳定。当对测试图像施加小扰动时,它们的特征表示会被推过边界,如图1所示。
因此,作者采用多视图预测(multi-view prediction, MVP)来代替单一视图进行测试。通过多视图预测,整合这些视图的互补信息,获得更稳健、更可靠的预测结果。
假设有一张图像x要测试,通过一些微弱的随机变换T(·)生成该图像的不同视图。则图像预测p由:
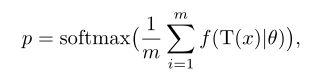
只对MVP应用弱变换(如随机翻转),因为强增强(如颜色抖动)会使增强图像偏离原始图像的流形,导致预测精度不理想。
实验
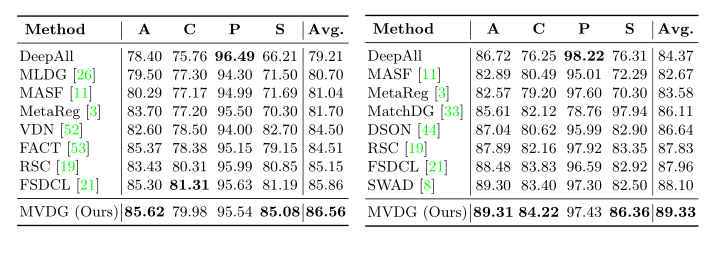
表1:使用ResNet-18(左)和ResNet-50(右)的PACS数据集上的域泛化精度(%)。
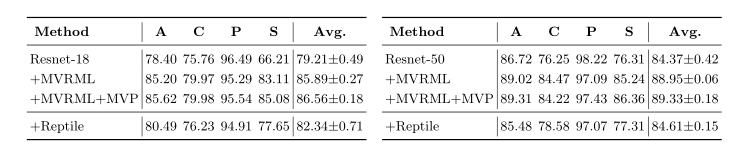
表3:消融实验在PACS数据集上对DeepAll、Reptile和多视图正则化元学习(MVRML)、多视图预测(MVP)各组件的准确率(%)。
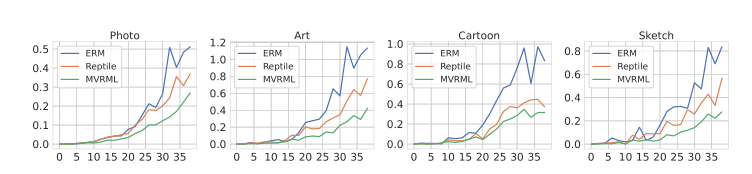
图4:ERM、Reptile和MVRML在PACS目标区域的局部锐度比较。
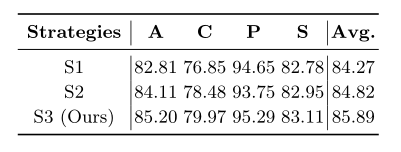
表4:PACS数据集上MVRML不同任务采样策略的比较。
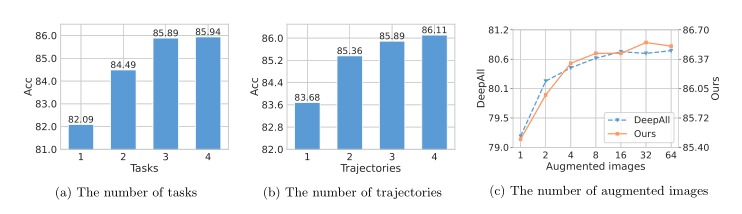
图5:MVRML中任务数量(a)和轨迹数量(b)的影响。
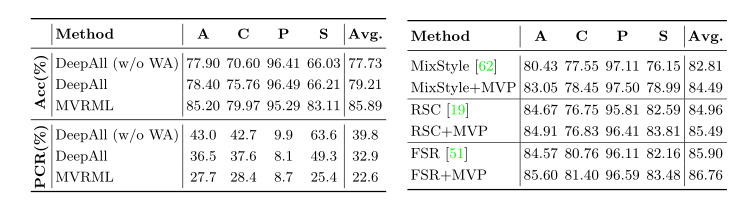
表5:左表为ResNet-18在PACS数据集上不同方法的准确率和预测变化率(PCR)。右表显示了在PACS数据集上将MVP应用于其他SOTA方法的准确率(%)。
结论
为了抵抗过拟合,基于任务增强训练和样本增强测试的DG模型都能提高模型的性能,本文提出了一种新的多视图框架,以提高泛化能力,减少过拟合导致的不稳定预测。
在训练过程中,设计了一种多视图正则化元学习算法。在测试过程中,引入多视图预测,生成单个图像的不同视图,以稳定集成的预测。通过在三个DG基准数据集上进行广泛的实验,验证了本文方法的有效性。
搞了个QQ交流群,打算往5000人的规模扩展,还专门找了大佬维护群内交流氛围,大家有啥问题可以直接问,主要用于算法、技术、学习、工作、求职等方面的交流,征稿、公众号或星球招聘、一些福利也会优先往群里发。感兴趣的请搜索群号:444129970
加微信群加知识星球方式:关注公众号CV技术指南,获取编辑微信,邀请加入。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。目前公众号正在征稿中,可以获取对应的稿费哦。
其它文章
ECCV 2022 | MorphMLP:一种有效的用于视频建模的MLP类架构
CVPR 2022 | BatchFormerV2:新的即插即用的用于学习样本关系的模块
CVPR 2022|RINet:弱监督旋转不变的航空目标检测网络
ECCV 2022 | FPN:You Should Look at All Objects
ECCV 2022 | ScalableViT:重新思考视觉Transformer面向上下文的泛化
ECCV 2022 | RFLA:基于高斯感受野的微小目标检测标签分配
迁移科技-工业机器人3D视觉方向2023校招-C++、算法、方案等岗位
文末赠书 |【经验】深度学习中从基础综述、论文笔记到工程经验、训练技巧
ECCV 2022 | 通往数据高效的Transformer目标检测器
ECCV 2022 Oral | 基于配准的少样本异常检测框架
CVPR 2022 | 网络中批处理归一化估计偏移的深入研究

 浙公网安备 33010602011771号
浙公网安备 33010602011771号