CVPR2021提出的一些新数据集汇总
前言
在《
本文来自公众号CV技术指南的
关注公众号CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
一些新发布的数据集可以提供一个窗口,通过这些数据集可以了解试图解决的问题的复杂程度。公共领域中新发布的数据集可以很好地代表理解计算机视觉的发展以及有待解决的问题的新途径。
本文简要总结了一些CVPR 2021 上发表的数据集论文,并通读了论文以提取一些重要的细节。
1. The Multi-Temporal Urban Development SpaceNet Dataset
数据集论文:https://paperswithcode.com/paper/the-multi-temporal-urban-development-spacenet
下载地址:https://registry.opendata.aws/spacenet/

![]()
新的 SpaceNet 数据集包含每个月拍摄的建筑区域的卫星图像。目标是在空间时间序列的帮助下在全球范围内跟踪这种建筑活动。
由于其解决非常困难的全局问题的方法,这是 CVPR 中最有趣的数据集论文。该数据集试图使用卫星图像分析解决量化一个地区城市化的问题,这对于没有基础设施和财政资源来建立有效的民事登记系统的国家来说是一个巨大的帮助。
该数据集主要是关于使用在 18 到 26 个月的时间跨度内捕获的卫星图像跟踪世界各地大约 101 个地点的建筑。随着时间的推移,有超过 1100 万条注释带有单个建筑物和施工现场的独特像素级标签。
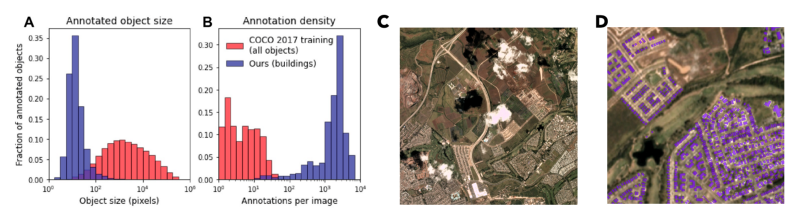
![]()
A.) 与 COCO 数据集对象相比,带注释的对象的大小非常小 B.) 在此数据集中,每张图像的标签数量太高。C.) 像云这样的遮挡(这里)会使跟踪探测变得困难。D.) Spacenet 数据集中单个图像中的带注释对象。
所有这些可能使它听起来像是一个更具挑战性的对象分割和跟踪问题。为了清楚起见,每帧大约有 30 多个对象。此外,与普通视频数据不同,由于天气、光照和地面季节性影响等原因,帧之间几乎没有一致性。这使得它比视频分类数据集(如 MOT17 和斯坦福无人机数据集)更加困难。
虽然这可能是一个难题,但解决它对于全球福利来说是值得的。
2. Towards Semantic Segmentation of Urban-Scale 3D Point Clouds: A Dataset, Benchmarks and Challenges
数据集论文:https://arxiv.org/abs/2009.03137
下载地址:https://github.com/QingyongHu/SensatUrban
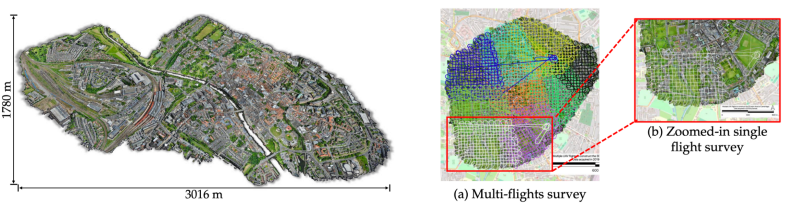
Sensat Urban 数据集的整体图,包括英国约克市的连续区域,扩展到 3 平方公里。
今年的会议重点讨论了 3D 图像处理及其相应的方法。因此,这个名为 Sensat Urban 的数据集也不足为奇,只是这个摄影测量 3D 点云数据集比迄今为止可用的任何开源数据集都要大。它覆盖超过7.6公里。涵盖约克、剑桥和伯明翰的城市景观广场。每个点云都被标记为 13 个语义类之一。
该数据集有可能推动许多有前途的领域的研究,如自动化区域测量、智慧城市和大型基础设施规划和管理。
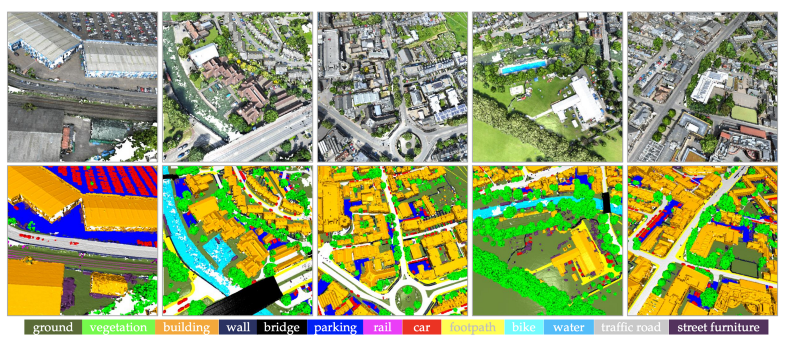
Sensat Urban 数据集中的不同分割类别。
在论文中,他们还对点云中的颜色信息进行了实验,并证明了在色彩丰富的点云上训练的神经网络能够在测试集上更好地泛化。这实际上为该领域未来应用的发展提供了重要方向。
3.Spoken Moments: Learning Joint Audio-Visual Representations from Video Descriptions
数据集论文:https://arxiv.org/abs/2105.04489
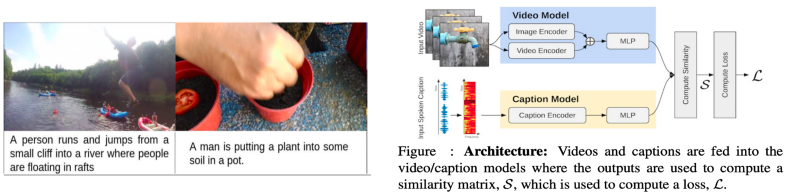
![]()
来自 MIT 音频字幕数据集的一些样本 [左] 在数据集中结合视听信息的提议架构 [右]
这是今年另一个最受欢迎的数据集,因为它对图像字幕和视频摘要问题采用了略有不同的方法。通常,对于此类任务,我们有像 COCO 这样的数据集,其中包含图像及其随附的文本标题。虽然这种方法已被证明是有前途的,但我们经常忘记,在口语方面对我们的视觉体验进行了很多丰富的总结。
该数据集构建了一个包含 50 万个描述各种不同事件的短视频音频描述的语料库。然而,他们并没有止步于展示一个很棒的数据集,他们还提供了一个优雅的解决方案来使用自适应平均边距(AMM)方法来解决视频/字幕检索问题。
4.Conceptual 12M : Pushing Web-Scale Image-Text Pre-training to recognise Long-Tail visual concepts
数据集论文:https://arxiv.org/abs/2102.08981

来自Conceptual 12M 数据集的一些图像标题对。虽然 alt-text 本身的信息量并不大,但它对于学习视觉概念的更广义的文本表示非常有帮助。
最近,由于预训练transformer和 CNN 架构的性能提升,模型预训练获得了极大的欢迎。通常,我们希望在一个类似的数据集上训练模型。然后使用迁移学习在下游任务上利用模型。
到目前为止,唯一可用的用于预训练的大规模数据集是用于视觉+语言任务的 CC-3M 数据集,有 300 万个字幕。现在,谷歌研究团队通过放宽数据抓取的限制,将该数据集扩展到 1200 万个图像字幕对--Conceptual 12M。
更有趣的是生成数据集的方法。在数据集管理期间使用 Google Cloud Natural Language API 和 Google Cloud Vision API 过滤任务对于任何未来的数据集管理任务来说都是一个很好的教训。
使用 12M 数据集,图像字幕模型能够学习长尾概念,即数据集中非常具体且罕见的概念。训练方法的结果令人印象深刻,并在下面进行了可视化。

在概念 12M 数据集上预训练的神经图像标题模型的预测示例很少。
5. Euro-PVI:密集城市中心的行人车辆交互
数据集论文:
https://openaccess.thecvf.com/content/CVPR2021/supplemental/Bhattacharyya_Euro-PVI_Pedestrian_Vehicle_CVPR_2021_supplemental.pdf

![]()
实时车辆-行人行为示例。预测行人将采取什么样的轨迹来响应接近的车辆对于构建全自动自动驾驶汽车至关重要。
虽然有很多关于完全自主的自动驾驶系统的讨论,但事实仍然是,它是一个非常困难的问题,需要同时实时解决多个问题。关键部分之一是使这些自主系统了解行人对其存在的反应,在密集环境中预测行人轨迹是一项具有挑战性的任务。
因此,Euro-PVI 数据集旨在通过在行人和骑自行车者轨迹的标记数据集上训练模型来解决这个问题。早些时候,斯坦福无人机、nuScenes 和 Lyft L5 等数据集专注于附近车辆的轨迹,但这只是自主系统完整画面的一部分。
Euro-PVI通过交互时的视觉场景、交互过程中的速度和加速度以及整个交互过程中的整体坐标轨迹等信息,提供了一个全面的交互图。
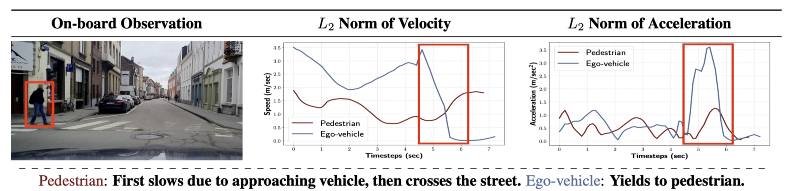
Euro-PVI 数据集包含有关行人车辆交互的丰富信息,例如场景中所有参与者的视觉场景、速度和加速度。
所有这些信息都必须由经过训练的模型映射到相关的潜在空间。为了解决潜在空间中轨迹和视觉信息的联合表示问题,同一篇论文还提出了 Joint-B-VAE 的生成架构,这是一种经过训练的变分自动编码器,用于对参与者的轨迹进行编码并将其解码为未来的合成轨迹。
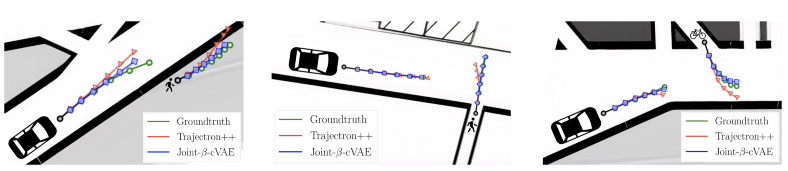
ground truth,Trajectron++ 预测的轨迹和联合 B-VAE 的预测轨迹(在同一数据集论文中提出)
在公众号CV技术指南中回复关键字 “ 0010 ” 可获取以上论文。
作者:Shwetank Panwar
编译:CV技术指南
原文链接:
https://medium.com/@shwetank.ml/datasets-cvpr-2021-problems-that-shouldnt-be-missed-6128d07c59c3
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “技术总结”可获取公众号原创技术总结文章的汇总pdf。

![]()
其它文章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号