使用Dice loss实现清晰的边界检测
前言:
在深度学习和计算机视觉中,人们正在努力提取特征,为各种视觉任务输出有意义的表示。在一些任务中,我们只关注对象的几何形状,而不管颜色、纹理和照明等。这就是边界检测的作用所在。
关注公众号CV技术指南,及时获取更多计算机视觉技术总结文章。
问题定义
![]()
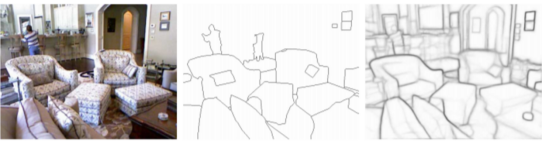
图1是一个边界检测的例子,顾名思义,边界检测是从图像中检测对象边界的任务。这是一个不适定的问题,因为问题设置本身存在歧义。如图所示,对于室内房间图像(左),ground truth(中)定义房间内的ground truth对象边界,并且预测(右)估计房间的对象边界。然而,我们可以看到,估计的边界远不止是ground truth,包括来自房间布局、窗帘,甚至沙发纹理的不必要的边界线。提取干净且有意义的对象边界并不容易。
原始方法
边界检测的一个直接解决方案是将其视为语义分割问题。在标注中简单地将边界为1和其他区域标记为0,我们可以将其表示为一个二分类语义分割问题,以二值交叉熵损失为损失函数。然而,它有两个原因:高度不平衡的标签分布和每像素交叉熵损失的内在问题。
Cross Entropy Loss的局限性
当使用交叉熵损失时,标签的统计分布对训练精度起着很重要的作用。标签分布越不平衡,训练就越困难。虽然加权交叉熵损失可以减轻难度,但改进并不显著,交叉熵损失的内在问题也没有得到解决。在交叉熵损失中,损失按每像素损失的平均值计算,每像素损失按离散值计算,而不知道其相邻像素是否为边界。因此,交叉熵损失只考虑微观意义上的损失,而不是全局考虑,这还不足以预测图像水平。

图2 具有交叉熵损失的边界预测
如图2所示。对于输入图像(左),比较了交叉熵损失(中)和加权交叉熵损失(右)的预测。右边的边界比中间的要好得多,但预测的边界并不干净,肮脏的草地纹理边界仍然存在。
Dice Loss
Dice Loss起源于Sørensen-Dice系数,这是20世纪40年代用来测量两个样本之间的相似性的统计数据。它是由米勒塔里等人带到计算机视觉的。2016年进行三维医学图像分割。
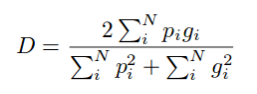
图3 骰子系数
上式显示了骰子系数方程,其中pi和gi分别表示对应的像素预测值和ground truth。在边界检测场景中,pi和gi的值为0或1,表示像素是否为边界,是的时候值为1,否则值为0。因此,分母是预测和ground truth的总边界像素的和,数值是正确预测的边界像素的和,因为只有当pi和gi值匹配时(两个值1)才递增。
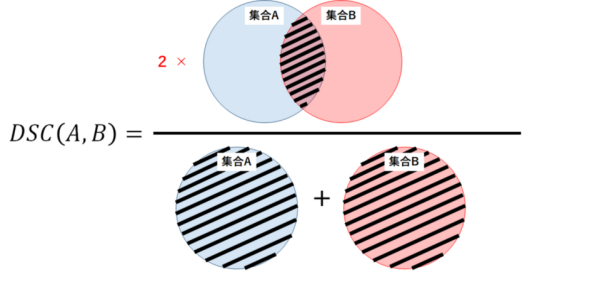
图4 骰子系数(设定视图)
图4是图3的另一个视图。从集理论的角度来看,其中骰子系数(DSC)是两个集合之间重叠的度量。例如,如果两组A和B完全重叠,DSC的最大值为1。否则,DSC开始减少,如果两个组完全不重叠,则最小值为0。因此,DSC的范围在0到1之间,越大越好。因此,我们可以使用1-DSC作为骰子损失来最大化两组之间的重叠。
在边界检测任务中,ground truth边界像素和预测的边界像素可以被视为两个集合。通过利用Dice Loss,这两组被训练一点地重叠。如图4所示。分母考虑全局尺度上的边界像素的总数,而数值考虑局部尺度上的两个集合之间的重叠。因此,Dice Loss在本地和全局上都考虑了损失信息,这对于高精度至关重要。
结果

图5 边界预测的结果
如图5所示。使用Dice Loss(c列)的预测结果比其他方法(d、e列)具有更高的精度。特别是对于薄边界,因为只有当预测的边界像素与ground truth薄边界重叠,并且在其他区域没有预测的边界像素时,才可以减少Dice Loss
参考论文
V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation, Milletari et al., 3DV 2016
Learning to Predict Crisp Boundaries, Deng et al., ECCV 2018
原文链接:
https://medium.com/ai-salon/understanding-dice-loss-for-crisp-boundary-detection-bb30c2e5f62b
本文来源于公众号 CV技术指南 的论文分享系列。
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “技术总结” 可获取以下文章的汇总pdf。
![]()


其它文章
在做算法工程师的道路上,你掌握了什么概念或技术使你感觉自我提升突飞猛进?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号