MobileNet系列之MobileNet_v2
Inception系列之Batch Normalization
导言:
MobileNet_v2提出了一些MobileNet_v1存在的一些问题,并在此基础上提出了改进方案。其主要贡献为提出了线性瓶颈(Linear Bottlenecks)和倒残差(Inverted Residuals)。
关注公众号CV技术指南,及时获取更多计算机视觉技术总结文章。
01Linear Bottlenecks

![]()
如上图所示,MobileNet_v2提出ReLU会破坏在低维空间的数据,而高维空间影响比较少。因此,在低维空间使用Linear activation代替ReLU。如下图所示,经过实验表明,在低维空间使用linear layer是相当有用的,因为它能避免非线性破坏太多信息。

![]()
此外,如果输出是流形的非零空间,则使用ReLU相当于是做了线性变换,将无法实现空间映射,因此MobileNet_v2使用ReLU6实现非零空间的非线性激活。
上方提出使用ReLU会破坏信息,这里提出ReLU6实现非零空间的非线性激活。看起来有些难以理解。这里提出我自己的理解。
根据流形学习的观点,认为我们所观察到的数据实际上是由一个低维流形映射到高维空间的。由于数据内部特征的限制,一些高维中的数据会产生维度上的冗余,实际上这些数据只要比较低的维度的维度就能唯一的表示。

![]()
图像分布是在高维空间,神经网络中使用非线性激活函数实现将高维空间映射回低维流形空间。而这里提出使用ReLU6即增加了神经网络对非零空间的映射,否则,在非零空间使用ReLU相当于线性变换,无法映射回流形低维空间。而前文提出的使用线性激活函数来代替ReLU是在已经映射后的流形低维空间。
区别就是ReLU6是在将高维空间映射到流形低维空间时使用,Linear layer是在映射后的流形低维空间中使用。
其使用的如下表所示
![]()
![]()

![]()
02 Inverted Residuals
MobileNet_v1中的结构如下左图,MobileNet_v2如下右图。、
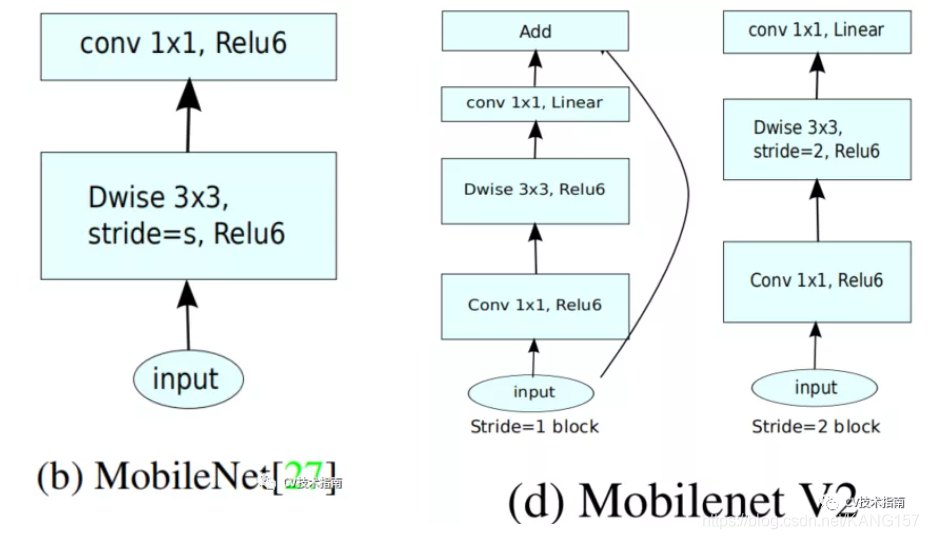
![]()
MobileNet_v2是在2018年发表的,此时ResNet已经出来了,经过几年的广泛使用表明,shortcut connection和Bottlenck residual block是相当有用的。MobileNet_v2中加入了这两个结构。
![]()
![]()
但不同的是,ResNet中的bottleneck residual是沙漏形的,即在经过1x1卷积层时降维,而MobileNet_v2中是纺锤形的,在1x1卷积层是升维。这是因为MobileNet使用了Depth wise,参数量已经极少,如果使用降维,泛化能力将不足。
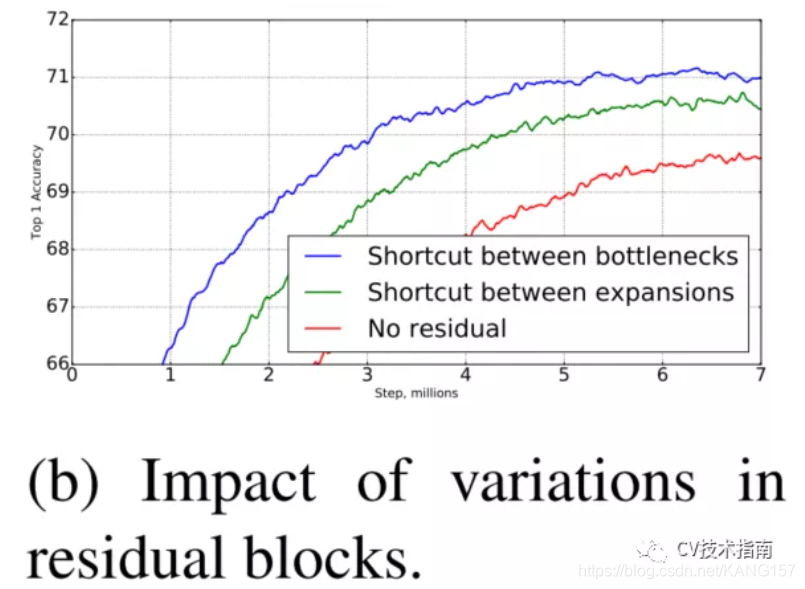
![]()
此外,在MobileNet_v2中没有使用池化来降维,而是使用了步长为2的卷积来实现降维,此外如上图所示,步长为2的block没有使用shortcut connection。

![]()
这里的t是膨胀因子,取6。
Inverted residuals block 与ResNet中的residuals block对比如下图所示:

![]()
图来源于网络
ResNet中residual block是两端大,中间小。而MobileNet_v2是中间大,两端小,刚好相反,作者把它取名为Inverted residual block。
整体结构如下图所示:

![]()
论文里提到Bottleneck有19层,但其给出的结构图中却只有17层。
MobileNet_v2相比与MobileNet_v1,参数量有所增加,主要增加在于Depth wise前使用1x1升维。此外,在CPU上的推理速度也比后者慢,但精度更高。

![]()
本文来源于公众号 CV技术指南 的模型解读系列。
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “入门指南“可获取计算机视觉入门所有必备资料。

其它文章
在公众号《CV技术指南》中回复“技术总结”可获取以上所有总结系列文章的汇总pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号