经典论文系列 | 重新思考在ImageNet上的预训练
前言:
这是一篇19年何凯明发的论文,论文基于目标检测、实例分割和人体关键点检测三个方向进行了多项实验,比较了从零使用随机初始化开始训练与使用预训练进行fine-tuning的效果,并得出了一些结论。
在本文将介绍论文的主要思想,主要结论,一些细节和作者基于实验结论上的讨论。
论文: Rethinking ImageNet Pre-training
主要思想
近年来一个通用的模式是将模型在大规模数据集上预训练,再到目标数据集上进行fine-tuning。这样的模式在很多任务上取得了SOTA性能,如目标检测,图像分割和行为识别。通过在类似ImageNet的数据上大规模地训练“通用”特征表示,似乎为“解决”计算机视觉问题铺平了道路。然而,我们对于这样的模式提出了质疑。
我们使用从随机初始化中训练的标准模型,获得了目标检测和姿态分割在COCO数据集上的竞争性结果。即使使用为fine-tuning预训练模型而优化的基准系统的超参数(Mask R-CNN),其结果也不会比ImageNet预训练的结果差。来自随机初始化的训练鲁棒性非常好。
即使在以下情况下,我们的结果仍然成立:
(i)仅使用10%的训练数据;
(ii)使用更深入和更广泛的模型;
(iii)使用多个任务和指标。
实验表明,ImageNet预训练可以在训练早期加快收敛速度,但不一定能提供正则化功能或提高最终目标任务的准确性。
为了突破极限,我们演示了在不使用任何外部数据的情况下在COCO对象检测上达到50.9 AP的结果-与使用ImageNet预训练的COCO 2017顶级竞赛结果相当。这些观察结果挑战了ImageNet预训练有关独立任务的传统智慧,我们希望这些发现将鼓励人们重新思考计算机视觉中“预训练和微调”的当前实际范式。
主要结论
1. ImageNet 预训练可以加速收敛,特别是在训练早期,但随机初始化训练在与预训练加fine-tuning同样的时间内可以赶上。图中的五次飞跃是因为学习率调整。
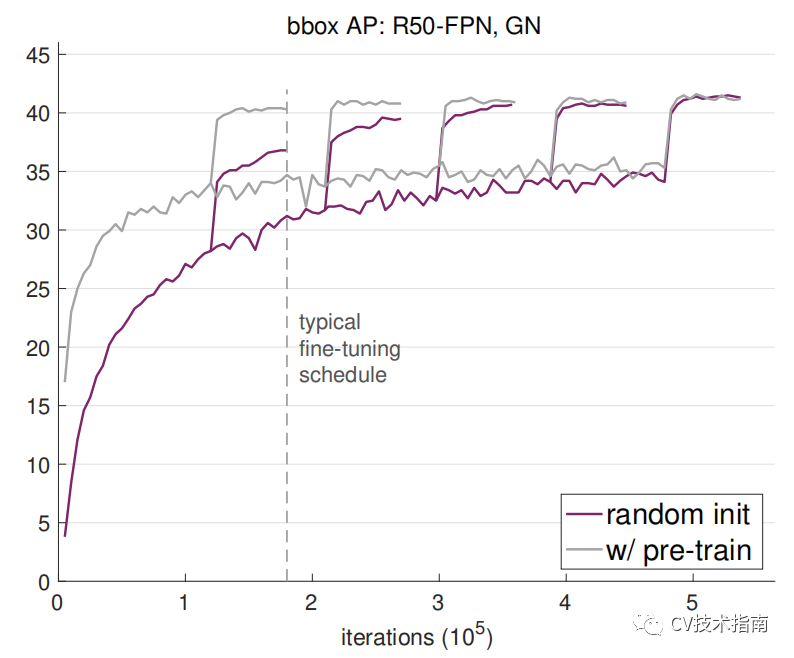
![]()
2. ImageNet预训练不会自动带来更好的正则化。当训练数据集比较少时(例如只有COCO的10%),我们发现预训练的模型在fine-tuning时必须选择新的超参数才能避免过拟合。而随机初始化训练使用相同的超参数,不需要额外的正则化就可以达到预训练模型的精度。
左图为fine-tuning时过拟合,中图为重新选择新的超参数的结果,右图在只有10k数据时随机初始化训练不需要额外的正则化就可以达到与预训练并经过优化超参数进行fine-tuning的结果。
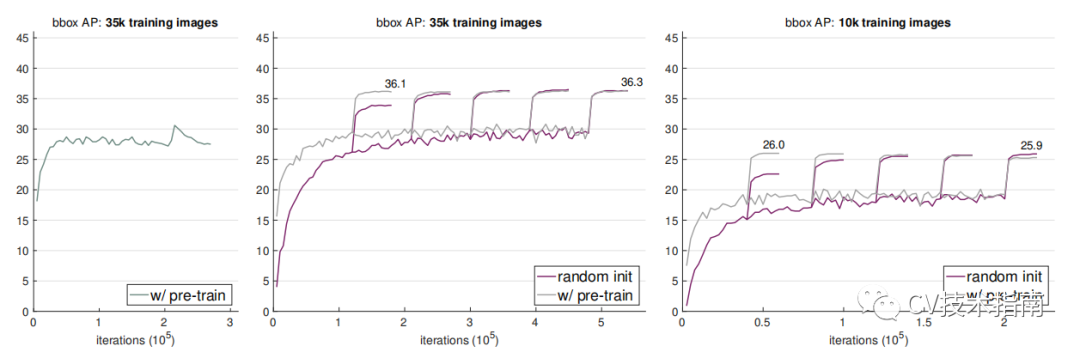
![]()
3. 当目标任务/指标对空间局部定位的预测更加敏感时,ImageNet预训练不会有任何好处。从头开始训练时,对于高框重叠阈值,我们观察到了AP的显着改善;我们还发现,需要精细空间定位的关键点AP从头开始会相对较快地收敛。直观地讲,类似ImageNet的预训练在基于分类的目标任务和对定位敏感的目标任务之间的任务差距可能会限制预训练的优点。
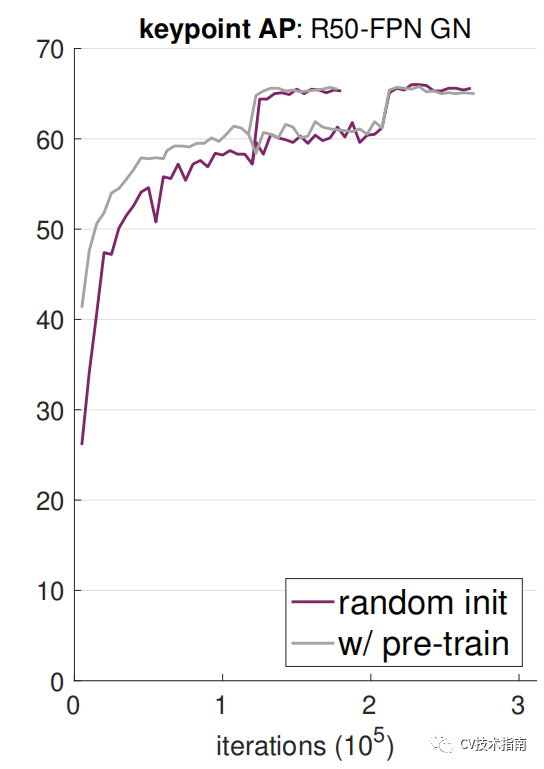
![]()
一些细节
Normalization
Batch Normalization是目前比较通用的正则化方法,部分情况下可能会使得从零训练一个检测器变得困难。不像分类器,目标检测器一般使用高分辨率输入,由于内存限制,这使得batch size设置得比较小,小batch size会严重退化BN的效果。
如果使用预训练的话可以规避这个问题,因为fine-tuning可以冻结BN数据,但从零训练没办法这么做。
为此,论文提出了两个正则化策略来处理小batch的问题:
1)Group Normalization (GN),由于GN的计算跟batch size无关,因此使用GN的模型将对batch size不敏感。
2)Synchronized Batch Normalization (SyncBN),这会跨多个GPU设备计算BN,例如batch size为8,GPU数量为10,BN是每个GPU上对8个样本进行归一化,而SyncBN是对10个GPU上所有样本,即80个样本进行归一化。这在一定程度上避免了小batch size。
Discussions
ImageNet pre-training有必要吗?
没必要,如果我们有足够的数据集。实验表明预训练可以加速收敛,除非在数据集非常非常小时(例如少于10k COCO images),否则不能提高精度。如果数据集足够,从零训练完全足够。这表明收集训练数据更加有利于提高任务表现。
ImageNet有用吗?
有用的。它可以让人们看到大规模数据对于提升模型性能的意义。而且,由于可以加快收敛速度,因此可以节省研究周期。最后,在ImageNet上的预训练可以节省很多没必要的计算成本。
大数据有用吗?
有用的。但是,如果我们考虑到收集和清理数据的额外工作,那么通用的大规模分类级别的预训练集就不理想了,收集ImageNet的资源需求已被大大忽略,但是“pre-training”步骤 实际上,当我们扩展此模式时,“pre-training+fine-tuning”模式实际上并不是免费的。 如果大规模分类级预训练的收益成倍减少,则在目标域中收集数据会更有效。
我们应追求通用表示吗?
我们相信学习通用表示时一个不错的目标。我们实验的结果并不意味着偏离了这一目标,只是我们在以往关注预训练带来的效益时,别忽略了从零训练也可以达到很好的效果。
最近把公众号(CV技术指南)所有的技术总结打包成了一个pdf,在公众号中回复关键字“技术总结”可获取。

![]()
本文来源于公众号CV技术指南的技术总结系列,更多内容请扫描文末二维码关注公众号。

![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号