
CNN结构演变总结(三)设计原则
前言:
前两篇对一些经典模型和轻量化模型关于结构设计方面的一些创新进行了总结,在本文将对前面的一些结构设计的原则,作用进行总结。
本文将介绍两种提升模型的表示能力的结构或方式,模型的五条设计原则,轻量化模型的四个设计方式。
提升模型的表示能力的结构或方式
1.“split-transform-merge”结构
这个概念来源于ResNeXt(2017年),在文中作了如下解释。
1) Split:将向量x分成低维嵌入表示;
2) Transform:每个低维特征经过一个线性变换;
3) Merge:通过单位加合成最后的输出;
Inception系列就是采用了这种策略的一个结构,在Inception模块中,Split采用的是1x1降维的方式,Transform采用卷积,Merge采用Concate的方式。通过 ”split-transform-merge”这种策略,使得模型可以以较少的参数和计算量,实现更深更大模型才具备的特征表示能力。
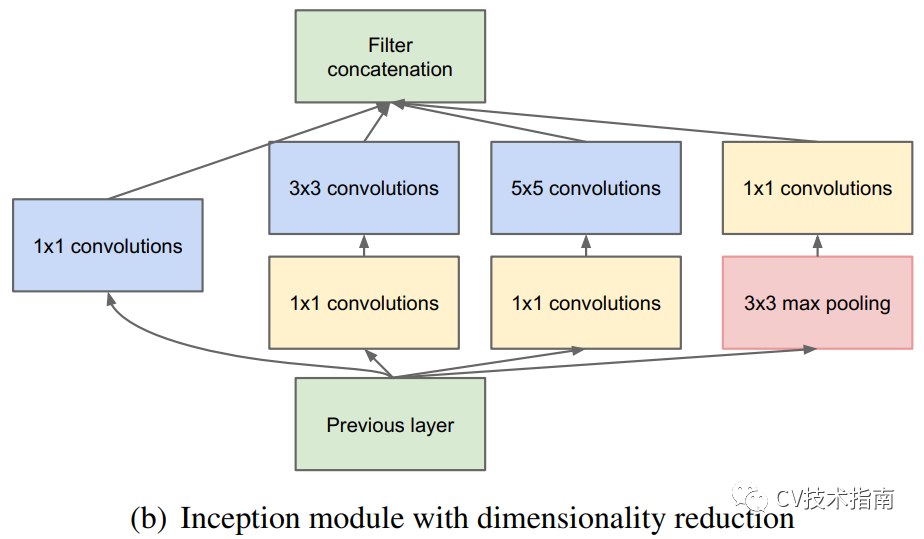
![]()
在ResNeXt中提到,基数(cardinality,也就是分支数)增多是一种比加深加宽网络更有效的方式提升精度。基于这一点,在PELEE网络中,就将DenseNet中的结构从单路变成双路的方式来改进模型。
2. 特征复用(feature reuse)
传统的卷积网络在一个前向过程中每层只有一个连接,ResNet增加了残差连接从而增加了信息从一层到下一层的流动。FractalNets重复组合几个有不同卷积块数量的并行层序列,增加名义上的深度,却保持着网络前向传播短的路径。相类似的操作还有Stochastic depth和Highway Networks,DenseNet等。
这些模型都显示一个共有的特征,缩短前面层与后面层的路径,其主要的目的都是为了增加不同层之间的信息流动,使用的方式就是特征复用。
特征复用的实现方式有以下几种:残差连接;feature maps留下一半进入下一层;feature maps通过不同的卷积核数量的并行层序列。
残差连接:采用直接相加的方式。
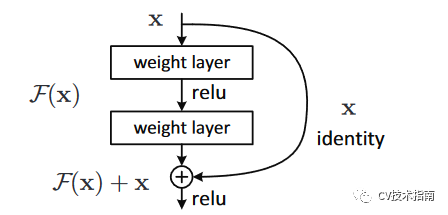
![]()
feature maps留下一半进入下一层:CSPNet。
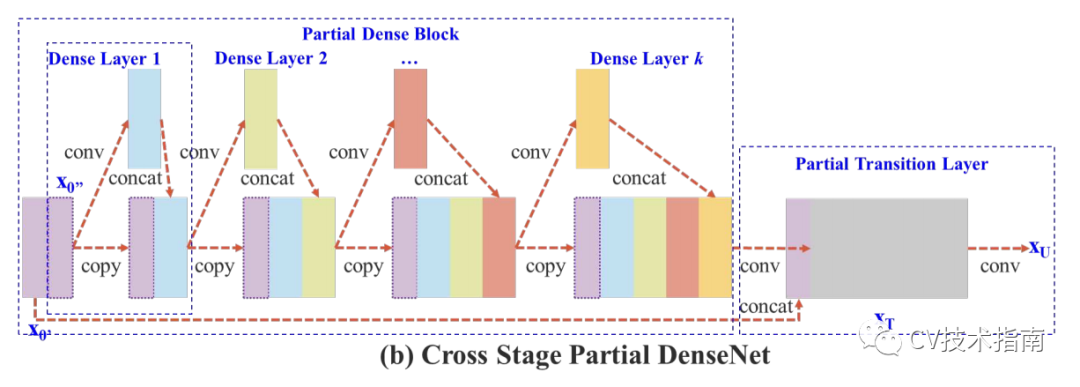
![]()
feature maps通过不同的卷积核数量的并行层序列:FractalNets。
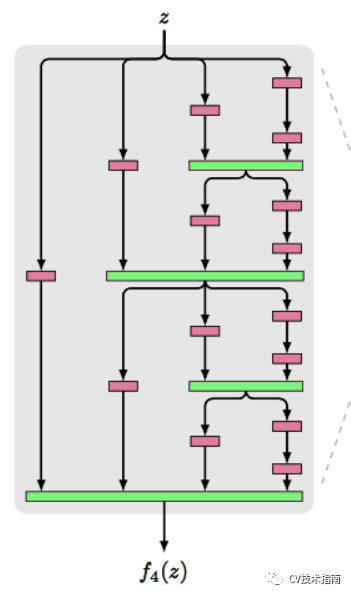
![]()
模型的设计原则
在Inception系列的第三篇论文里总结了四条CNN设计的四条原则。
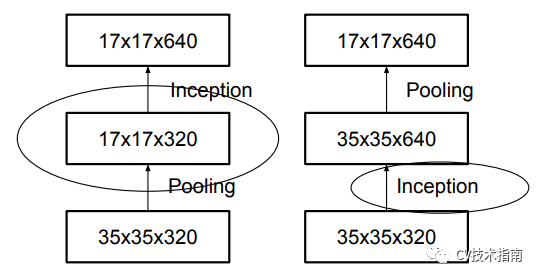
1. 避免表示瓶颈,特别是在网络的浅层。
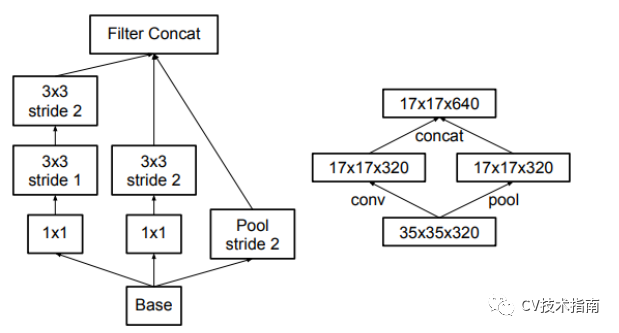
一个前向网络每层表示的尺寸应该是从输入到输出逐渐变小的。以下图为例,按照左边第一种的方式进行下采样,将会出现表示瓶颈。为了避免这个问题,提出了第四个图所示的结构来进行降采样。
![]()
![]()
2. 高维度的表示很容易在网络中处理,增加激活函数的次数会更容易解析特征,也会使网络训练的更快。
3. 可以在较低维的嵌入上进行空间聚合,而不会损失很多表示能力。
例如,在执行更分散(例如3×3)的卷积之前,可以在空间聚集之前(浅层)减小输入表示的尺寸,而不会出现严重的不利影响。
我们假设这样做的原因是,如果在空间聚合环境中(中高层)使用输出,则相邻单元之间的强相关性会导致在尺寸缩减期间信息损失少得多。鉴于这些信号应易于压缩,因此减小尺寸甚至可以促进更快的学习。
4. 平衡网络的宽度和深度。
通过平衡每个阶段的滤波器数量和网络深度,可以达到网络的最佳性能。增加网络的宽度和深度可以有助于提高网络质量。但是,如果并行增加两者,则可以达到恒定计算量的最佳改进。因此,应在网络的深度和宽度之间以平衡的方式分配计算预算。
5. 此外再补充一条关于池化的使用。
在网络的特征提取部分,使用最大池化。在分类部分,使用平均池化。具体原因与细节,请阅读CV技术指南中的《池化技术总结》。
轻量化模型设计原则
1. 改进底层实现方式。
如sigmoid函数在实现过程中采用近似的方式,不仅很复杂,还会导致精度损失,因此MobileNet_v3中提出了h-swish非线性激活函数,这个函数的特点就是底层实现很简单,也不会导致推理阶段的精度损失。
2. 减少参数量。
基于这一原则的方式目前有1)使用深度可分离卷积;2)使用分解卷积;3)使用分组卷积;4)使用特征表示能力强的结构;5)使用1x1卷积代替3x3卷积;
3. 减少计算量。
第二条中的五种方式都具有减少计算量的作用,此外,特征复用也具备减少计算量的作用。
4. 降低实际运行时间。
下面提到ShuffleNet_v2中的四条原则就是基于这一点。
在ShuffleNet的第二篇论文里总结了四条实现降低模型实际运行时间的原则。
MAC: memory access cost
1. 卷积层输入输出通道数相同时,MAC最小。
为简化计算表达式,这里使用1x1卷积来进行理论上的推导。
对于空间大小为 h,w的特征图,输入和输出通道数分别为c1和c2,使用1x1卷积, 则FLOPs为B = h x w x c1 x c2。而MAC = hw(c1 + c2 ) + c1 x c2。
这里hwc1为输入特征图内存访问成本,hwc2为输出特征图内存访问时间成本,c1xc2x1x1为卷积核内存访问时间成本。
将B表达式代入MAC表达式中,并根据不等式定理,可有如下不等式:
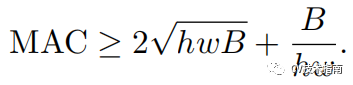
![]()
由此式可知,MAC存在下限,当c1 = c2时,MAC取最小值。
这种方式主要指模块的输入输出通道数相同,并非单纯是一层卷积层的输入输出。
2. 分组卷积的分组数越大,MAC越大。
分组卷积在一方面,使得在相同FLOPs下,分组数越大,在通道上的密集卷积就会越稀疏,模型精度也会增加,在另一方面,更多的分组数导致MAC增加。
使用分组卷积的FLOPs表达式为B=h w c1 c2 /g , MAC表达式如下:
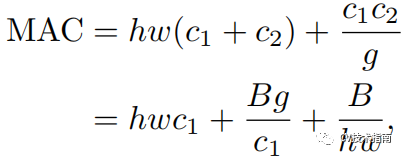
![]()
3. 网络支路会降低模型的并行度。
前面提到当网络支路数量增加时,会提高模型的特征表示能力,但同时也降低了效率,这是因为支路对GPU并行运算来说是不友好的,此外,它还引入了额外的开销,如内核启动与同步。
4. Element-wise操作不可忽视。
Element-wise操作在GPU上占的时间是相当多的。Element-wise操作有ReLU, AddTensor, AddBias等。它们都有比较小的FLOPs,却有比较大的MAC。特别地,depthwise conv也可以认为是一个Element-wise操作,因为它有较大的MAC/FLOPs比值。
总结:《CNN结构演变总结》这个系列对目前神经网络的结构设计部分进行了比较完整的总结,但神经网络不仅仅包括结构部分,此外还包括激活函数,训练技巧,避免过拟合的方法,学习方式等诸多内容,在后续的总结系列文章中将会对这些内容进行总结,将放在CV技术指南的CV技术总结部分。
参考论文
第一篇忘记放参考论文,在这里补上,再加上本文的一些参考论文。
-
Gradient-based learning applied to document recognition
-
ImageNet Classification with Deep Convolutional Neural Networks
-
Network In Network
-
Very Deep Convolutional Networks For Large-scale Image Recognition
-
Going Deeper with Convolutions
-
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
-
Rethinking the Inception Architecture for Computer Vision
-
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
-
Deep Residual Learning for Image Recognition
-
Wide Residual Networks
-
Densely Connected Convolutional Networks
-
Training very deep networks
-
Aggregated Residual Transformations for Deep Neural Networks
-
FractalNet: Ultra-Deep Neural Networks without Residuals
更多技术总结内容
本文来源于公众号《CV技术指南》的技术总结部分,更多相关技术总结请扫描文末二维码关注公众号。

![]()

