Inception系列之Inception_v2-v3
Inception系列之Batch-Normalization
引言:
Inception_v2和Inception_v3是在同一篇论文中,提出BN的论文并不是Inception_v2。两者的区别在于《Rethinking the Inception Architecture for Computer Vision》这篇论文里提到了多种设计和改进技术,使用其中某部分结构和改进技术的是Inception_v2, 全部使用了的是Inception_v3。
模型设计原则
Inception_v1结构由于比较复杂,很难在其基础上有所改变,如果随意更改其结构,则很容易直接丧失一部分计算收益。同时,Inception_v1论文中没有详细各个决策设计的因素的描述,这使得它很难去简单调整以便适应一些新的应用。为此,Inception_v2论文里详细介绍了如下的设计基本原则,并基于这些原则提出了一些新的结构。
1.避免表示瓶颈,特别是在网络的浅层。一个前向网络每层表示的尺寸应该是从输入到输出逐渐变小的。(当尺寸不是这种变化时就会出现瓶颈)
2.高维度的表示很容易在网络中处理,增加激活函数的次数会更容易解析特征,也会使网络训练的更快。(这条原则的意思是表示维度越高,越适合用网络来处理,像二维平面上的数据分类反而就不适合用网络来处理,增加激活函数的次数会使得网络更容易学到其表示特征)
3. 可以在较低维的嵌入上进行空间聚合,而不会损失很多表示能力。例如,在执行更分散(例如3×3)的卷积之前,可以在空间聚集之前(浅层)减小输入表示的尺寸,而不会出现严重的不利影响。我们假设这样做的原因是,如果在空间聚合环境中(中高层)使用输出,则相邻单元之间的强相关性会导致在尺寸缩减期间信息损失少得多。鉴于这些信号应易于压缩,因此减小尺寸甚至可以促进更快的学习。
4. 平衡网络的宽度和深度。通过平衡每个阶段的滤波器数量和网络深度,可以达到网络的最佳性能。增加网络的宽度和深度可以有助于提高网络质量。但是,如果并行增加两者,则可以达到恒定计算量的最佳改进。因此,应在网络的深度和宽度之间以平衡的方式分配计算预算。
一些特殊的结构
01 卷积分解
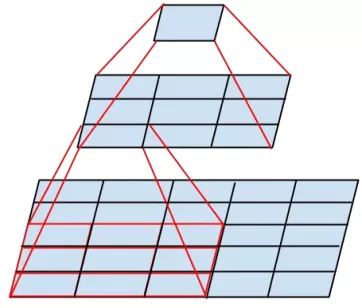
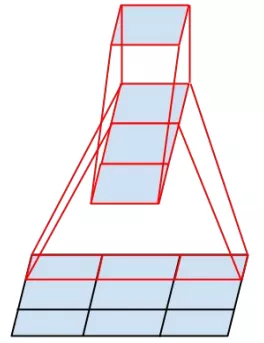
一个5x5的卷积核可通过两个连续的3x3卷积核来代替,其中第一个是正常的3x3卷积,第二个卷积是在上一层3x3卷积的基础上进行全连接。这样做的好处是既实现了5x5卷积该有的感受野,又实现了更小的参数2x9/25,大概缩小了28%。具体如下左图fig1所示。更进一步,采用非对称分解,将一个3x3的卷积分解为3x1和1x3。具体如下右图fig2.
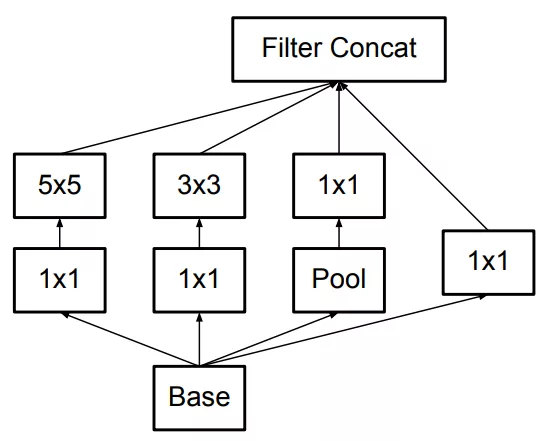
因此原来的Inception结构(左图fig3)就可以变成如下所示的结构(中图fig5)和(右图fig6)。

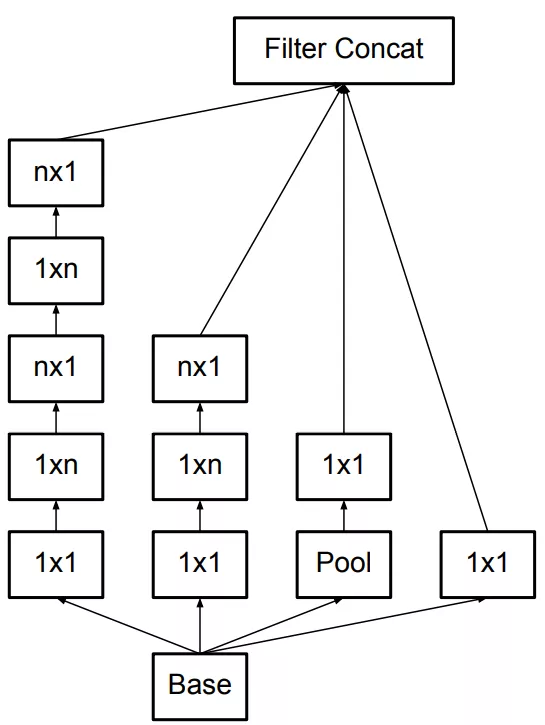
最终还衍生出了如下图所示(fig7)一种混合两种分解方式的结构。

在实际应用中,使用这样的分解结构在网络低层的效果并不好。它在中等尺寸大小(mxm的feature map 其中m在12到20范围内)的层中会有比较好的效果。这是考虑到第二条原则,这样的Inception结构将会放在网络中间层,而在网络低层仍然使用一般卷积网络的结构。
02 辅助分类器的效用
辅助分类器在训练的前期并没有起什么作用,到了训练的后期才开始在精度上超过没有辅助分类器的网络,并达到稍微高的平稳期。并且,在去除这两个辅助分类器后并没有不利的影响,因此在Inception_v1中提到的帮助低层网络更快训练的观点是有问题的。如果这两个分支有BN或Dropout,主分类器的效果会更好,这是BN可充当正则化器的一个微弱证据。
03 高效降低Grid Size
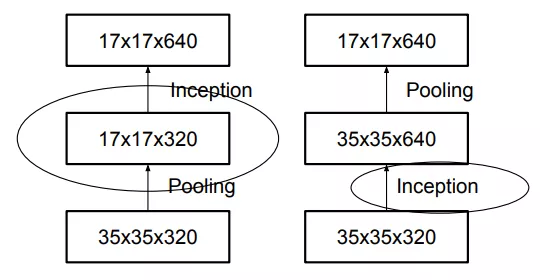
关于降低Grid Size大小的方式,有如上图所示两种做法。左边这种违背了第一条原则,即尺寸应该逐层递减,否则会出现bottleneck。右图符合第一条原则,然而这样参数量巨大。为此作者提出了一种如下图(fig10)所示的新方式。即并行操作,利用步长都为2的卷积和池化操作,在不违背第一条原则的基础上实现降低Grid Size。

完整的Inception_v2结构图如下:
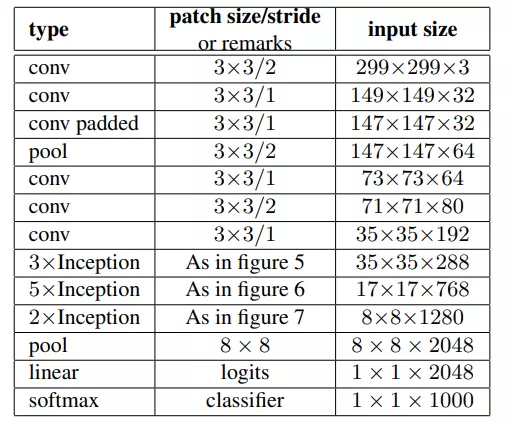
整个结构中都没有用到padding, 提出的fig10结构用在了中间每个Inception模块之间。
04
通过标签平滑化的模型正则化
如果模型在训练过程中学习使得全部概率值给ground truth标签,或者使得最大的Logit输出值与其他的值差别尽可能地大,直观来说就是模型预测的时候更自信,这样将会出现过拟合,不能保证泛化能力。因此标签平滑化很有必要。
![]()
前面的δk,y 是狄拉克函数,即类别k = y,即为1,否则为0。原本的标签向量q(k|x) = δk,y。而标签平滑化后的标签向量变为如下公式。
这里的∈为超参数,u(k)取1/k,k表示类别数。即新的标签向量(假定是三分类)将变为(∈/3, ∈/3, 1-2∈/3 ),而原来的标签向量是(0,0,1)。
结论
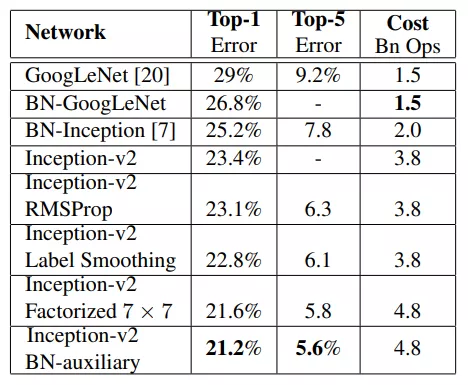
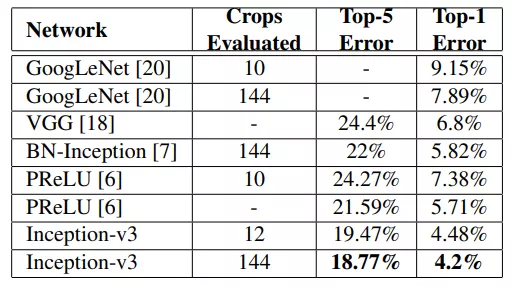
实际效果如图所示,在这里说明Inception_v2与Inception_v3的区别,Inception_v2指的是使用了Label Smoothing 或BN-auxiliary或RMSProp或Factorized技术中的一种或多种的Inception模块。而Inception_v3指的是这些技术全用了的Inception模块。
如有错误或不合理之处,欢迎在评论中指正。
欢迎关注公众号“CV技术指南”,主要进行计算机视觉方向的论文解读,最新技术跟踪,以及CV技术的总结。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号