
机器学习——正则化-L2
学了线性回归和逻辑回归后不得不提一下正则化
正则化是解决过拟合问题,是机器学习算法中为防止数据过拟合而采取的“惩罚”措施。
拟合:通俗的讲就是贴近的关系,拟合的三种状态,欠拟合(贴的不够紧),just right(刚刚好,恰到好处),过拟合(贴的太紧,以至于很容易出错,不能泛化)
故事:
校服的故事,学校要做一批校服,由1班的学生来进行训练,对于1班的学生来说衣服合适,想拿到2班进行推广,可是发现二班的情况不理想,不合适的居多,原因就是完全太贴近1班的数据,导致不能被推广。要想退广的话就得拉大1班的实测值与预测值得距离,面对这样的过拟合问题,进行修改,引入缓冲概念正则化 lamda,这里比喻成马甲,用马甲来调节1班的实测值与与测试的差距
问题由来:


中间知识:
针对过拟合问题,给代价函数加入一个“马甲”lamda
针对线性回归:
h=1/2m*sum((h-y)^2)+lamda/2m*sum(theta^2)
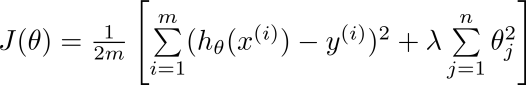
针对逻辑回归:
h=
梯度下降:
dettheta=1/m*X.T.dot(h-y)+lamda/m*theta

