爬取拉勾网关于python职位并进行数据分析和可视化
一、主题式网络爬虫设计方案
1、主题式网络爬虫名称:抓取拉勾网关于python职位相关的数据信息
2、主题式网络爬虫爬取的内容:关于python职位相关信息
3、主题式网络爬虫设计方案概述:找到网站地址,分析网站源代码,找到所需要的数据所在位置并进行提取、整理和数据可视化操作。
二、主题页面的结构特征分析
主题页面的结构与特征分析:打开网址找到我们需要的数据所在位置
找到我们需要的数据


然后进行数据清洗

爬取到的关于python职位相关信息导出excel文件后如下如下
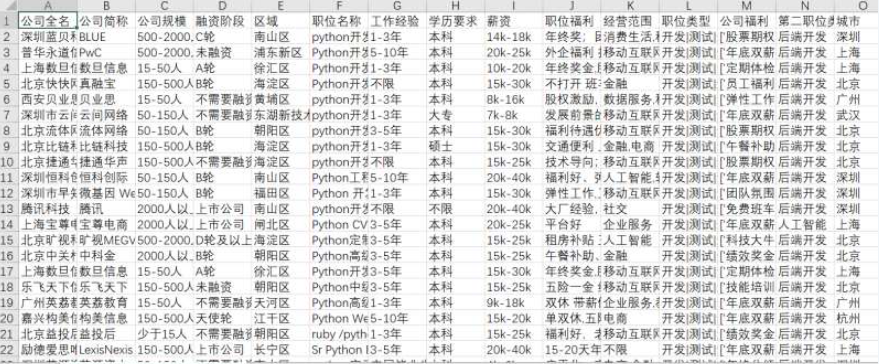
数据整理完毕、进行数据可视化
绘制python薪资的频率直方图

运行结果如下

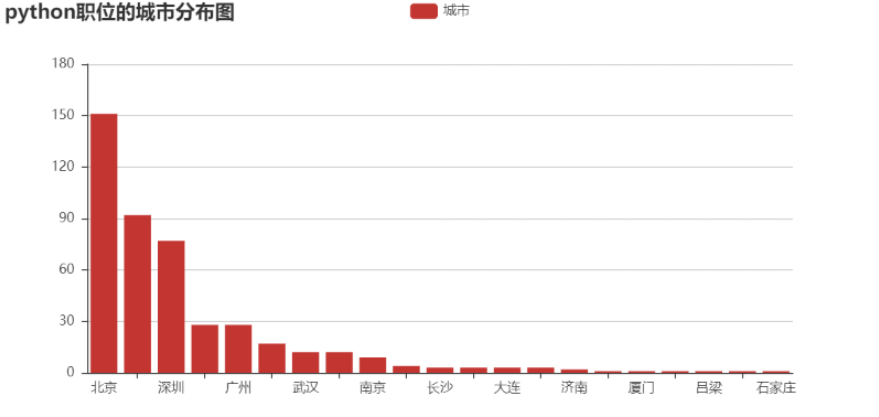
绘制python职位的城市柱状图

四、附上完整程序代码
import requests
import math
import time
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from wordcloud import WordCloud
from scipy.misc import imread
import jieba
def get_json(url, num):
url1 = 'https://www.lagou.com/jobs/list_python%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88?labelWords=&fromSearch=true&suginput='
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36','Host': 'www.lagou.com','Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest'}
data = { 'first': 'true','pn': num, 'kd': 'python工程师'}
s = requests.Session()
print('建立session:', s, '\n\n')
s.get(url=url1, headers=headers, timeout=3)
cookie = s.cookies
print('获取cookie:', cookie, '\n\n')
res = requests.post(url, headers=headers, data=data, cookies=cookie, timeout=3)
res.raise_for_status()
res.encoding = 'utf-8'
page_data = res.json()
print('请求响应结果:', page_data, '\n\n')
return page_data
def get_page_num(count):
page_num = math.ceil(count / 15)
if page_num > 30:
return 30
else:
return page_num
def get_page_info(jobs_list):
page_info_list = []
for i in jobs_list:
job_info = []
job_info.append(i['companyFullName'])
job_info.append(i['companyShortName'])
job_info.append(i['companySize'])
job_info.append(i['financeStage'])
job_info.append(i['district'])
job_info.append(i['positionName'])
job_info.append(i['workYear'])
job_info.append(i['education'])
job_info.append(i['salary'])
job_info.append(i['positionAdvantage'])
job_info.append(i['industryField'])
job_info.append(i['firstType'])
job_info.append(i['companyLabelList'])
job_info.append(i['secondType'])
job_info.append(i['city'])
page_info_list.append(job_info)
return page_info_list
def main():
url = ' https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
first_page = get_json(url, 1)
total_page_count = first_page['content']['positionResult']['totalCount']
num = get_page_num(total_page_count)
total_info = []
time.sleep(10)
print("python开发相关职位总数:{},总页数为:{}".format(total_page_count, num))
for num in range(1, num + 1):
page_data = get_json(url, num)
jobs_list = page_data['content']['positionResult']['result']
page_info = get_page_info(jobs_list)
print("每一页python相关的职位信息:%s" % page_info, '\n\n')
total_info += page_info
print('已经爬取到第{}页,职位总数为{}'.format(num, len(total_info)))
time.sleep(20)
df = pd.DataFrame(data=total_info,
columns=['公司全名', '公司简称', '公司规模', '融资阶段', '区域', '职位名称', '工作经验', '学历要求', '薪资', '职位福利', '经营范围',
'职位类型', '公司福利', '第二职位类型', '城市'])
print('python相关职位信息已保存')
if __name__ == '__main__':
main()
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
df = pd.read_csv('Python_development_engineer.csv', encoding='utf-8')
pattern = '\d+'
df['工作年限'] = df['工作经验'].str.findall(pattern)
print(type(df['工作年限']), '\n\n\n')
avg_work_year = []
count = 0
for i in df['工作年限']:
if len(i) == 0:
avg_work_year.append(0)
count += 1
elif len(i) == 1:
avg_work_year.append(int(''.join(i)))
count += 1
else:
num_list = [int(j) for j in i]
avg_year = sum(num_list) / 2
avg_work_year.append(avg_year)
count += 1
print(count)
df['avg_work_year'] = avg_work_year
df['salary'] = df['薪资'].str.findall(pattern)
avg_salary_list = []
for k in df['salary']:
int_list = [int(n) for n in k]
avg_salary = int_list[0] + (int_list[1] - int_list[0]) / 4
avg_salary_list.append(avg_salary)
df['月薪'] = avg_salary_list
plt.hist(df['月薪'], bins=8, facecolor='#ff6700', edgecolor='blue')
plt.xlabel('薪资(单位/千元)')
plt.ylabel('频数/频率')
plt.title('python薪资直方图')
plt.savefig('python薪资分布.jpg')
plt.show()
city = df['城市'].value_counts()
print(type(city))
print(city)
# print(len(city))
keys = city.index
values = city.values
from pyecharts import Bar
bar = Bar("python职位的城市分布图")
bar.add("城市", keys, values)
bar.print_echarts_options()
bar.render(path='a.html')
结论:
1、经过这次利用python对数据进行爬取分析和可视化的操作,我深刻体会到了python的强大,让我一次次客服难点,让我对python有进一步的理解,也让我发现我的能力还有很大的不足。
2、经过这次可视化分析,我发现python的薪资有待提高,在发达地区需要的职位更多。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号