Zookeeper数据模型及其应用
Zookeeper作为分布式系统的底层协调服务有着其简单可依靠的数据模型,数据模型加之数据同步、一致性处理和可靠性,在此之上有很多经典的应用,例如,分布式锁、服务器动态上线下感知、主节点选举、数据发布与订阅、负载均衡等等。虽然应用场景很多,但是最根本的还是基于两个核心的服务,1.管理和存储数据结点,2.提供对结点的监听服务。
一.Zookeeper数据模型
Zookeeper数据模型类似Linux操作系统的文件系统,也是以树的形式来存储。严格来说是一颗多叉树,每个节点上都可以存储数据,每个节点还可以拥有N个子结点,最上层是根节点以“/”来代表。
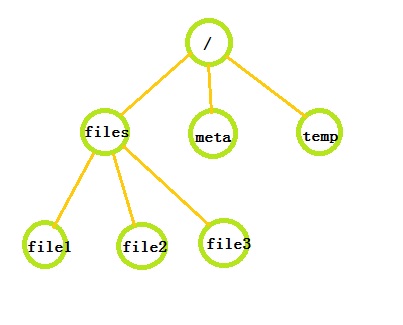
在每个结点上都存储了相应的数据,数据可以是字符串、二进制数。但是默认情况下每个结点的数据大小的上限是1M,这是因为Zookeeper主要是用来协调服务的,而不是存储数据,管理一些配置文件和应用列表之类的数据。虽然可以修改配置文件来改变数据大小的上限,但是为了服务的高效和稳定,建议结点数据不要超过默认值。
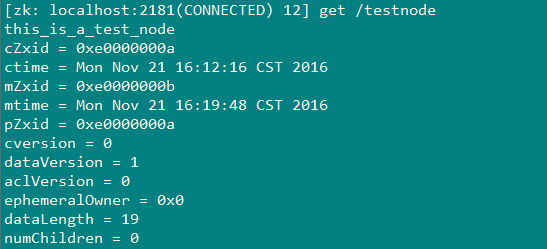
可以看到,在Zookeeper中存储的创建的结点和存储的数据包含结点的创建时间、修改时间、结点id、结点中存储数据的版本、权限版本、孩子结点的个数、数据的长度等信息。在创建结点的时候还可以选择临时结点、序列化节点等类型,这在应用时就非常方便了。在后面的应用中会有所体现。
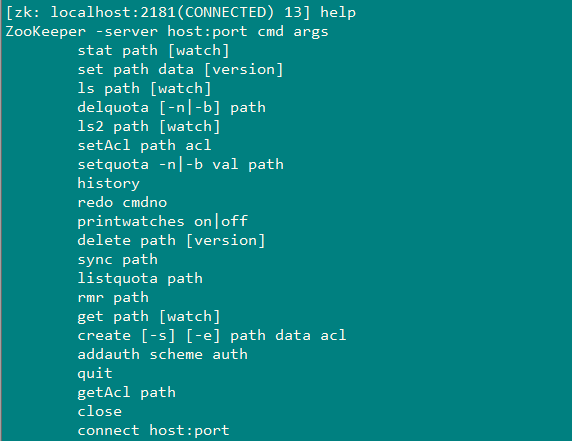
Zookeeper提供了两种客户端,命令行客户端和API客户端,关于命令行客户端的使用可以help一下。
二.Zookeeper典型应用示例
1.分布式共享锁
需求描述:在一个分布式系统中,所有服务器结点共享一种资源,为了保证数据的一致性和准确性就必须对共享资源做出访问限制。因为不在一台机器上所以不能使用并发锁来同步。需要Zookeeper做分布式协调服务。
设计思路:在Zookeeper上创建一个锁结点,然后每个服务器如果需要访问共享资源那么就在锁结点下创建一个锁结点的孩子结点,这里需要注意的是,孩子结点需要创建成为临时序列结点,这样一来如果某个服务器在拥有锁的时候挂了,其拥有的锁会自动释放。序列结点会使所有的锁都可以有序。在获取锁的时候创建监听该锁上一个锁的删除事件,这样可以避免“羊群效应”,在一个锁结点被释放(删除)时不会唤醒所有在等待的锁结点,可以节约网络和服务资源。

这只是一个基本的实现思路,具体的规则就是序列最小的获取锁,优先级是按照时间来算的,但是基本思路都是一样的,可以基于此上修改成为优先级可调节的,或者改成分布式读写锁提高访问性能。
分布式共享锁的实现请参考:https://github.com/wxisme/zoopack/blob/master/zoopack/src/main/java/org/zoopack/lock/
2.服务器动态上下线感知
需求描述:在分布式系统中,可能有很多个结点,在提供服务的过程中可能会有服务器异常的或者正常的下线、挂掉或者修复之后上线继续提供服务,那么为了提高系统的可靠性就需要实时的更新在线服务器列表,以便在分发请求的时候不会分发到已经下线的服务器中。那么实时更新服务器列表就可以使用Zookeeper的数据结点来存储、用NodeChildrenChangedWatcher来监听所有的服务器下线和上线的事件。
设计思路:在Zookeeper根目录下创建一个服务器父节点,在这个父节点下可以有多个服务器子节点,在父节点上注册一个NodeChildrenChangedWatcher来监听子节点的增加和删除事件,如果有服务器子节点增加或者删除就会更新服务器列表。一般的就可以认为服务器列表就是实时更新、有效的。这样在做请求分发或者负载均衡的时候就能够做到稳定和正确。
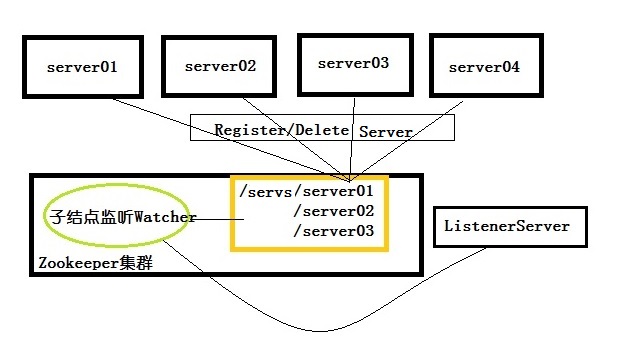
关于服务器动态上下线动态感知的实现请参考:https://github.com/wxisme/zoopack/tree/master/zoopack/src/main/java/org/zoopack/perception
三.总结
通过以上两个例子也可以看出来,不管Zookeeper应用场景再多,业务逻辑再复杂,只要抓住两个核心可以了,1.管理和存储数据结点(小数据量),2.提供对结点的监听服务。只要合理的应用这两个特性就可以很好的使用它,当然任何一个系统都不是简单的一个技术可以完成的,在特定的业务场景下有特定的解决方案,在不同的应用环境和数据压力下也要对Zookeeper及其上下游技术进行调优,这样的话就需要对zk的配置文件和内部实现的算法,选举算法、数据一致性算法等有一定的理解和实践。









 浙公网安备 33010602011771号
浙公网安备 33010602011771号