#论文阅读#attention is all you need
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in Neural Information Processing Systems. 2017: 5998-6008.
文章提出纯粹基于attention的NN model: Transformer。
the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequencealigned RNNs or convolution.

旨在解决的问题是:
现有的encoder-decoder framework为了factor句子的positional information,在encoder和decoder部分都使用RNN。这样做 precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples. 尽管已有一些工作在提高LSTM或Gated RNN的效率方面取得进展,但 The fundamental constraint of sequential computation, however, remains.
此外,不使用CNN来解决RNN中sequential computation的原因是: the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions, linearly for ConvS2S . This makes it more difficult to learn dependencies between distant positions。
所以,提出Transformer的总体目标是: reducing sequential computation。
Transformer总体模型结构:
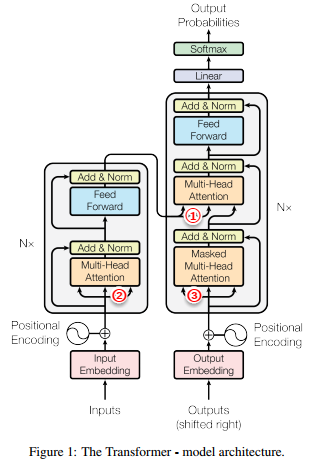
Transformer中使用了三种方式的attention:
① encoder-decoder attention
② self-attention in encoder
③ self-attention in decoder
Transformer中的两个小细节:
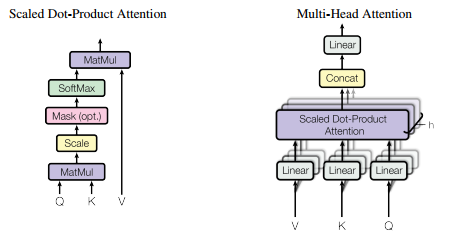
(1)规格化点乘内积注意力(原文3.2.1 Scaled Dot-Product Attention)
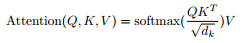
(2)多头注意力 (原文3.2.2 Multi-Head Attention)
把Query, Key, Value分别线性变换到不同维度空间(变换多次,即multi-, 每次的结果用Attention(Q,K,V) 得到一个attention ,即一个head),然后把得到的多个head级联起来就是 multi-head attention。

(3)position encoding(原文 3.5 Positional Encoding)
由于Transformer中没有使用RNN或CNN,为了学习到sequence中各个token的relative position information和absolute position information, 添加了position encoding,使其和token embedding的维数相同,以便把(token embedding + position embedding)作为encoder和decoder的stack里最底层layer的输入。
position embedding的dimensionality也是dmodel

这种学习位置信息的方式很巧妙,测试了一下序列长度设为8,dmodel 设为32时,可视化效果:
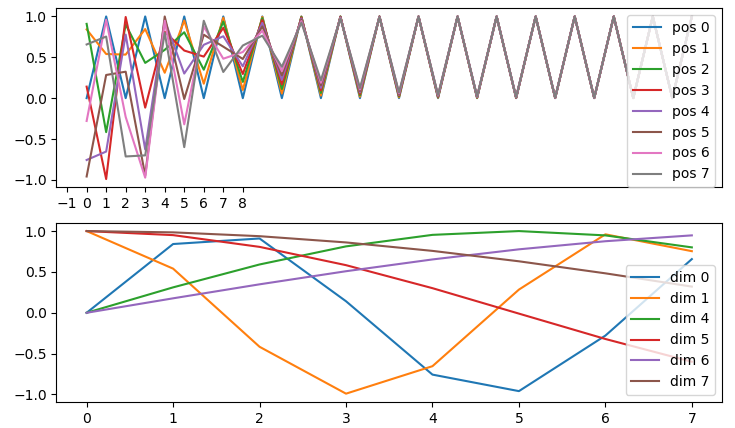
关于正余弦值来近似位置的相对关系,参考苏剑林的解释:
苏剑林. (2018, Jan 06). 《《Attention is All You Need》浅读(简介+代码) 》[Blog post]. Retrieved from https://www.spaces.ac.cn/archives/4765注:这篇文章写得很好。

Transformer对该文总体goal(reducing sequential computation)的回应:
从3个角度对比解释why Transformer可以reduce computation(原文 4 Why Self-Attention)
(主要功劳是self-attention)下图是时间复杂度的对比:

实验结果:
任务一: machine translation
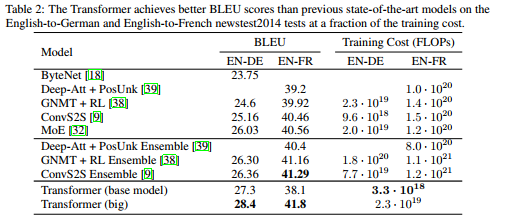
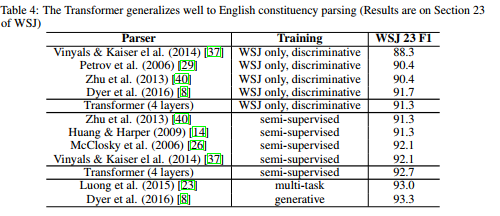
任务二: english constituency parsing
对Transformer 的 implementation:
The official Tensorflow Implementation can be found in: tensorflow/tensor2tensor.
To learn more about self-attention mechanism, you could read "A Structured Self-attentive Sentence Embedding".
Tranformer结构及实现过程可视化:
http://jalammar.github.io/illustrated-transformer/
总结:
论文提出的模型结构,确实在同等甚至优于先前模型实验结果的前提下,节省了计算时间和计算资源。这也是论文中一直强调的目标。
还有如下3点学习心得:
(1)之前对attention的使用都是在已有经典模型(如LSTM, CNN)的基础上使用注意力机制。这篇论文抛开这些基础模型,纯粹使用attention搭建encoder-decoder模型,从实验结果来看,验证了attention机制本身的威力,就像论文题目说的“attention is all you need”。
(2)另外,在encoder和decoder的内部分别使用attention,即self-attention说明自注意力机制能够很好地学习sentence内部各个token的位置信息,并为不同位置的token赋权。
(3)multi-head和在encoder和decoder部分的stacks很巧妙地在层与层之间和单层上增加了学习参数,如文中说的“分别在不同的维度空间学习到不同的关键信息”,最后把这些关键信息级联构成一个特征向量,与cnn池化层后的flat向量有异曲同工之妙。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号