#论文阅读# Universial language model fine-tuning for text classification

论文链接:https://aclweb.org/anthology/P18-1031
对文章内容的总结
文章研究了一些在general corpus上pretrain LM,然后把得到的model transfer到text classiffication上 整个过程的训练技巧。这些技巧的切入点是learning rate. 主要是三个:(1)discriminative fine-tuning (其中的discriminative 指 fine-tune each layer with different learning rate LR)(2)slanted triangular learning rate (在训练过程中先增加LR,增到预设的最大值后减小(减小速度<增加速度,所以LR随训练步数的曲线看起来是slanted triangle))(3)在训练text classiffication model时, perform gradual unfreezing. (即先锁住所有层的参数,训练过程中从最后一层开始,每训练一个epoch向前放开一层)
以下是ABSTACT和INTRODUCTION主要内容的翻译:
Abstract:
Inductive transfer learning 已经在很大程度上影响了CV,但在NLP领域仍然需要task-specific微调或需要从头开始训练。这篇文章提出了一个Universial language model Fine-tuning (ULMFiT),这是一种可以应用于任何NLP任务的迁移学习方法。此外,文章还介绍了几种主要的fine-tuning language model 的技术。实验证明:ULMFiT outperforms the state-of-the-art on 三种文本分类任务(共计6个数据集)。
实验结果:
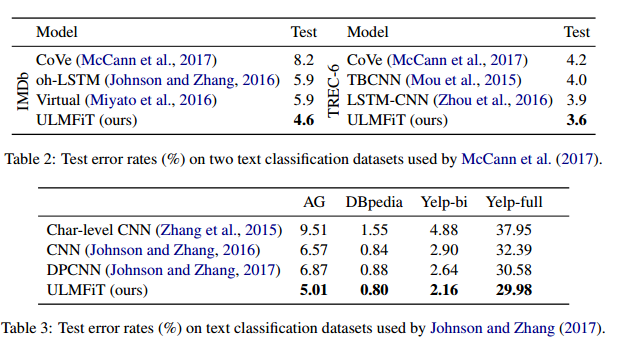
Introduction:
p1: Inductive transfer learning 对CV应用于CV时,rarely需要从头开始训练,只要fine-tuning from models that have been pretrained on ImageNet, MS-COCO等。
P2: Text classification属于NLP tasks with rea-world applications such as spam, fraud, and bot detection, emergency response and commercial document classification,such as for legal discovery.
P3: DL models 在很多NLP tasks 上取得了state-of-the-art, 这些models是从头开始训练,requiring large datasets 和days to converge. NLP领域中的transfer learning 研究大多是 transductive transfer. 而inductive transfer,如fine-tuning pre-trained word embeddings 这种只是针对第一层的transfer technique,已经在实际中有了large impact, 并且也被应用到了很多state-of-the-art models。但是recent approaches 在使用embeddings时只是把它们作为fixed parameters从头开始训练main task model,这样做limit了这些embedding的作用。
P4: 按照pretraining的思路,我们可以 do better than randomly initializing 模型的其他参数。However,有文献说inductive transfer via fine-tuning has been unsuccessful.
P5: 本文并不是想强调LM fine-tuning这个想法,而是要指出对模型进行有效训练的技术的缺乏才是阻碍transfer learning应用的关键所在。 LMs overfit to small datasets and suffered catastrophic forgetting when fine-tuned with a classifier. 跟CV相比,NLP models 非常shallow, 它们需要不同的fine-tuning methods.
P6: 本文提出ULMFiT来解决上述issuses, 并且在any NLP task上得到了robust inductive transfer. ULMFiT 的architecture是 3-layer LSTM。各层使用相同的超参数,除了 tuned dropout hyperparameters 没有任何额外东西。ULMFiT 能够 outperforms highly engineered models.

Contributions:
(1) 提出ULMFiT,一种可以在any NLP task上achieve CV-like transfer learning的方法。
(2) 提出用于retain previous knowledge进而avoid catastrophic forgetting的novel techniques: discriminative fine-tuning, slanted triangular learning rate, and gradual unfreezing.
(3) siginificantly outperform the state-of-the-art on six representative text classification datasets, with an error reduction of 18-24% on the majority of datasets.
(4) 本文方法能够实现非常sample-efficient 的transfer learning,并且做了extensive ablation analysis.
(5) 作者们预训练了模型并且可用于wider adoption.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号