爬虫大作业
1.选一个自己感兴趣的主题。
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
3.对爬了的数据进行文本分析,生成词云。
4.对文本分析结果进行解释说明。
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
主题:虎扑骑士新闻
实现的过程:主要是先获取虎扑骑士新闻网站的url,然后找不同页数之间的url有什么关系,用一个for循环就可以访问数个页面的网址了,然后就是解决一个页面中获取超链接到新闻的详情页面的url,接着就是获取当前页面的所有新闻内容,然后再调用函数将每个新闻页面的内容都记录到记事本,然后再用正则表达式去标点符号,去掉无意义字符,排序,然后生成词云字典再将它写到记事本中,再调用wordcloud打开这个记事本,引用系统中的字体otf,然后设置好其他参数,进行渲染,还有设置好输出的文件名,就成下面这个样子了。

中途遇到的问题更多的是在安装wordcloud这个插件踩了很多的坑,不过也学到了在pycharm报错插件导入失败怎么处理。
在安装这个插件之前,我还不知道我的python版本号是多少以至我下错了版本,大家可以先查查自己的python版本是什么
然后我 按照网上这个兄弟的指导这样做,我在pip install scapy 的时候,报了这个错误,于是我就根据版本号去找twisted这个文件开头的cp36的whl,然后也重新下载了wordcloud相应的版本,继续安装。
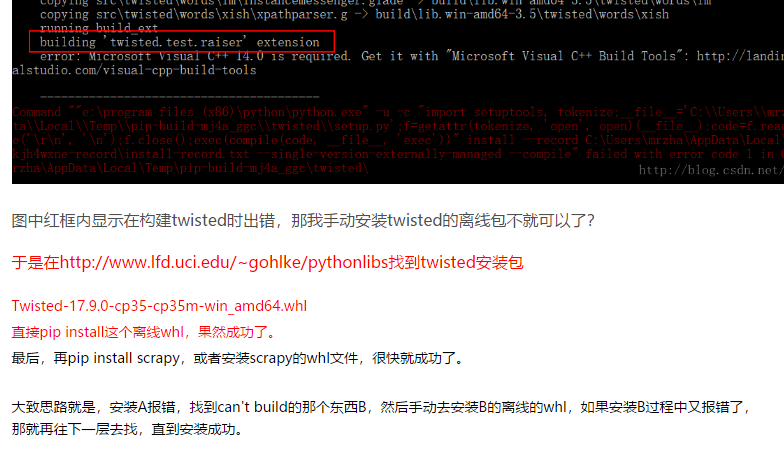
可惜的是再次报错,如图还是这个错误

所以我就想了下,干脆我直接将那个wordcloud那个包复制黏贴我的项目好了,就这样,有时候越直接的方法效果越好,我的wordcloud ok了,
然后起初如果我们没有设置词云的字体的话,渲染出来的图片将会是很多个矩形框交织在一起的图片,将计算机上的字体路径弄过来就好了
数据分析思想及结论
因为我爬取的是骑士的新闻,从这张图中,我们可以看到出现频率最高的是骑士跟步行者这两支球队,其次是季后赛,还有篮板,助攻,大比分这些词,说明两支球队最近是打系列赛才会有这么多的出镜率,篮板助攻表明在这焦灼的系列赛中的重要性,还有大比分显示出了某些比赛时刻的比分很悬殊,在这个数据分析中我们海看到了詹姆斯这个球员字眼,证明他的表现在这个季后赛中扮演着举足轻重的作用。
以上是我所从词云图中获取的信息。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
# -*- coding : UTF-8 -*- # -*- author : onexiaofeng -*- import requests from bs4 import BeautifulSoup import re import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt # 将词云写入到文件 def writeFilekeynews(keywords): f = open('keyword.txt', 'a', encoding='utf-8') for word in keywords: f.write(" "+word) f.close() #将新闻内容写入文件 def writeFilecontent(contnet): f = open('content.txt', 'a', encoding='utf-8') f.write("\n"+contnet) f.close() def getWordCloud(): keynewsTowordcloud = open('keyword.txt', 'r', encoding='utf-8').read() print(keynewsTowordcloud) wc = WordCloud(font_path='C:\Windows\Fonts\AdobeKaitiStd-Regular.otf', background_color='white',max_words=150).generate(keynewsTowordcloud).to_file("wordcloud.jpg") plt.imshow(wc) plt.axis('off') plt.show() def getKeynews(content): content = ''.join(re.findall('[\u4e00-\u9fa5]', content)) # 通过正则表达式选取中文字符数组,拼接为无标点字符内容 # 去掉重复的字符生成集合 newSet = set(jieba._lcut(content)) newDict = {} for i in newSet: newDict[i] = content.count(i) deleteList, keynews = [], [] for i in newDict.keys(): if len(i) < 2: deleteList.append(i) #去掉单音无意义字符 deleteList.append('编辑') for i in deleteList: del newDict[i] dictList = list(newDict.items()) dictList.sort(key=lambda item: item[1], reverse=True) # 排序,返回前三关键字 for dict in dictList: keynews.append(dict[0]) return keynews def getNewsDetail(newsUrl): resd = requests.get(newsUrl) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') content = soupd.select('.artical-main-content')[0].text writeFilecontent(content) keynews = getKeynews(content) writeFilekeynews(keynews) def Get_page(url): res = requests.get(url) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') # print(soup.select('.tag-list-box')[0].select('.list')) for new in soup.select('.tag-list-box')[0].select('.list'): # print(new.select('.list-content')[0] .select('.name')[0].select('.n1')[0].select('a')[0]['href']) url = new.select('.list-content')[0].select('.name')[0].select('.n1')[0].select('a')[0]['href'] getNewsDetail(url) url = 'https://voice.hupu.com/nba/tag/3023-1.html' resd = requests.get(url) resd.encoding = 'utf-8' soup1 = BeautifulSoup(resd.text, 'html.parser') Get_page(url) for i in range(2, 4): Get_page('https://voice.hupu.com/nba/tag/3023-{}.html'.format(i)) getWordCloud()
文件附件下载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号