中文词频统计
下载一长篇中文文章。
从文件读取待分析文本。
news = open('gzccnews.txt','r',encoding = 'utf-8')
安装与使用jieba进行中文分词。
pip install jieba
import jieba
list(jieba.lcut(news))
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
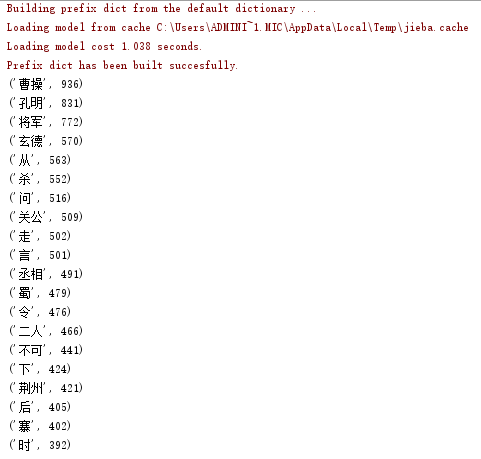
输出词频最大TOP20
# -*- coding : UTF-8 -*- # -*- author : onexiaofeng -*- import jieba f=open('bbb.txt','r',encoding='utf-8') notes=f.read() notelist=list(jieba.lcut(notes)) NoteDic={} for i in set(notelist): #计算次数 NoteDic[i]=notelist.count(i) delete_word={'曰',' ','之',';', '吾', '而', '为', '将', '皆', '与', '乃', '见',',','。',':','“','”','亦','矣','?','等','今',\ '操','遂','与','不','是','、','也','又','!', '\n','…','?','了','有','在','来','我','去','于','人','中','欲','却说',\ '至','此','到','便','兵','得','若','以','若','汝','已','可','出','上','被','使','却'} for i in delete_word: #删除非法词汇 if i in NoteDic: del NoteDic[i] sort_word = sorted(NoteDic.items(), key= lambda d:d[1], reverse = True) # 由大到小排序 for i in range(20): #输出词频Top20 print(sort_word[i])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号