词法分析和语法分析
词法分析和语法分析(例子)
让我们以一个简单的例子来说明词法分析和语法分析的过程,假设我们有一个非常基础的编程语言片段:
x = 3 + 5
词法分析(Lexical Analysis):
- 读取源代码: 系统首先读取这行代码的字符流。
- 分割和识别词法单元:
x被识别为一个标识符(Identifier)。=被识别为赋值运算符(Assignment Operator)。3被识别为整型字面量(Integer Literal)。+被识别为加法运算符(Addition Operator)。5再次被识别为整型字面量。- 代码中的空白字符(如空格)和换行符在词法分析阶段通常会被忽略,除非它们在某些语言中具有特殊意义。
输出的词法单元序列可能是:[Identifier('x'), AssignmentOperator('='), IntegerLiteral('3'), AdditionOperator('+'), IntegerLiteral('5')]。
语法分析(Syntactic Analysis):
接下来,语法分析器会根据这些词法单元构建抽象语法树(AST):
-
应用语法规则:
- 可能的规则之一是表达式语句的结构,比如
assignment_statement -> identifier '=' expression。 expression又可以细分为更简单的结构,如expression -> term '+' term,其中term可以是integer_literal。
- 可能的规则之一是表达式语句的结构,比如
-
构建抽象语法树:
- 根据上述规则,构造出的AST可能如下
( assignment ├── identifier: 'x' └── expression ├── term │ └── integer_literal: '3' └── addition_operator: '+' └── term └── integer_literal: '5' )
在这个过程中,语法分析器确保了表达式x = 3 + 5符合语言的语法规则,形成了一个有效的赋值语句结构。如果不符合规则,比如写成x = 3 + + 5,语法分析器就会报告错误,指出多余的运算符。
ANTLR4:从零开始构建一个简单的DSL解析器
ANTLR4 是一个强大的解析器生成器,用于读取、处理、执行或翻译结构化文本或二进制文件。它广泛应用于 构建领域特定语言(DSL)。以下是一个使用ANTLR4构建简单DSL的示例,这个DSL用于执行基本的算术运算。
步骤 1: 定义语法规则 (Calculator.g4)
首先,你需要定义你的DSL的语法规则。创建一个名为Calculator.g4的文件,并输入以下内容:
grammar Calculator; expr: expr op=('+'|'-') expr # AddSub | expr op=('*'|'/') expr # MulDiv | INT # Number | '(' expr ')' # Parens ; op: '+' | '-'; INT: [0-9]+; WS: [ \t\r\n]+ -> skip;
这个规则定义了一个简单的四则运算表达式的解析规则,包括加减乘除和括号。
Calculator.g4文件通过定义一系列的Parser规则和Lexer规则,建立了处理基本数学表达式的语法规则。ANTLR4根据这些规则生成Java(或其他目标语言)的解析器和词法分析器代码,使得我们可以解析并计算输入的数学表达式。1 grammar Calculator; /* 声明了这是一个ANTLR4的语法文件,定义了一个名为Calculator的语法。grammar(/ˈɡræmə(r)/ 语法)关键字后跟的是语法的名称,通常与.g4文件名相匹配。*/ 2 /* 3 * Parser Rules(实现语法分析的代码称为 parser) 4 calculation规则是整个输入的顶级规则,它定义了一个计算过程由一个expression(表达式)跟随着文件结束符EOF(End Of File)构成。这意味着解析器期望处理完一个表达式后到达输入的末尾。 5 6 */ 7 calculation: expression EOF; 8 9 10 /* 11 expression规则定义了表达式如何由更小的部分组合而成。这里有三条分支: 12 第一条表示两个表达式之间加上一个term(项)构成加法。 13 第二条表示减法,结构类似加法。 14 第三条是递归基底,即一个表达式可以直接是一个term。 15 */ 16 expression 17 : expression '+' term # Addition 18 | expression '-' term # Subtraction 19 | term # BaseExpression 20 ; 21 22 23 /* 类似地,term规则定义了项可以通过乘法、除法组合更小的factor(因子、系数、因素),或者直接是一个factor。 */ 24 term 25 : term '*' factor # Multiplication 26 | term '/' factor # Division 27 | factor # BaseTerm 28 ; 29 30 /* factor可以是一个整数INT或者是一个括号内的expression,允许嵌套表达式。 */ 31 factor 32 : INT # IntegerNumber 33 | '(' expression ')' # Parentheses 34 ; 35 36 /* 37 * Lexer Rules (实现词法分析的代码称为 lexer , 也有人叫 scanner 或者 tokenizer。) 38 */ 39 INT: [0-9]+ ; / * INT规则定义了如何识别一个整数,即一个或多个数字字符组成的序列。 */ 40 WS: [ \t\r\n]+ -> skip ; /* WS规则匹配空白字符(包括空格、制表符、回车、换行),并使用箭头(->)指令skip告诉ANTLR在词法分析阶段忽略这些字符,不生成对应的Token。*/ 41 42 /* 43 * Parser Rule Definitions (if any custom behavior is needed) 44 */ 45 ...
语法规则释义
在ANTLR4或者更广泛的编译原理和语法分析领域中,expression rule、term rule、factor rule是用来定义语言中不同层次表达式的语法规则。它们是构建抽象语法树(AST)的基础,每个层级代表了源代码或输入文本中的一种结构或运算概念。下面是对这三个概念的简要解释:
1. Factor Rule (factor)
factor规则通常定义了表达式中最基本、不可再分解的单元。在数学表达式中,因子通常是数字(如整数、浮点数)、变量、函数调用或者括号内的子表达式。它是最小的计算单位,对于简单的计算器来说,可能包含字面量数字和括号表达式。
例如:
1factor: NUMBER | '(' expression ')';这里,factor可以是一个数字(NUMBER)或者是括号包围的另一个expression。
2. Term Rule (term)
term 项 规则建立在factor之上,定义了通过算术运算(如乘法和除法)连接的因子。在数学中,项指的是乘法操作的结果,例如“3 * x”中的“3 * x”就是一个项。因此,term规则会涉及到因子之间的乘法或除法运算。
例如:
1term: factor ('*' factor | '/' factor)*;这个规则说明,一个term可以是一个factor,后面跟着零个或多个乘法或除法操作和相应的因子。
3. Expression Rule (expression)
expression规则位于最顶层,它定义了通过加法和减法运算连接的项。在数学和编程中,表达式是最完整的计算单元,涵盖了所有基本的算术运算。它能够包含任何复杂的加减运算序列,并且通常以term为基础构建。
例如:
1expression: term (('+' | '-') term)*;这表示一个expression可以开始于一个term,随后可以跟随零个或多个加号或减号以及相应的term。
综上所述,这三个规则从简单到复杂,层层嵌套,共同构成了处理数学或类似结构化文本的基础。它们帮助ANTLR理解输入文本的结构,并将其转换成可以被程序处理的数据结构,如抽象语法树。
Lexer和Parser
Lexer Rules(词法规则)在ANTLR这样的解析工具中起到基础而关键的作用。ANTLR使用这些规则来将输入文本切分成一个个有意义的符号,这些符号被称为tokens(词法单元)。 Lexer(词法分析器)负责读取输入字符流,并根据定义好的词法规则将其转换为token序列。
Lexer Rules定义了如何识别这些token,比如怎样识别一个标识符(identifier)、关键字(keyword)、数字(number)、字符串(string)或者运算符(operator)等。每个规则都描述了一种特定模式的字符组合,当 Lexer 遇到符合该模式的文本时,就会生成对应的token类型。
例如,一些基本的Lexer规则可能如下所示:
1WS : [ \t\r\n]+ -> skip; // 忽略空白字符 2INTEGER : [0-9]+; // 匹配整数 3PLUS : '+'; // 匹配加号 4MINUS : '-'; // 匹配减号 5STAR : '*'; // 匹配乘号 6SLASH : '/'; // 匹配除号 7IDENTIFIER : [a-zA-Z_][a-zA-Z_0-9]*; // 匹配标识符在ANTLR的.g4文件中,这些规则是用正则表达式或者特定的符号来表述的,ANTLR基于这些规则生成代码,实现对输入文本的词法分析。每个规则名(如INTEGER, PLUS等)对应一个token类型,在后续的Parser Rules中会被用来构建更复杂的语法结构。
步骤 2: 生成解析器和词法分析器
使用ANTLR4命令行工具,将上述.g4文件转换为Java、Python或其他支持的语言的解析器和词法分析器代码。例如,如果你想要生成Java代码,可以运行:
1antlr4 Calculator.g4这将会生成几个Java文件,包括CalculatorLexer.java(词法分析)和CalculatorParser.java(语法分析)。
这两个文件的具体实现细节会根据你的.g4文件中的语法规则有所不同,但大致结构和流程是类似的。生成的代码通常不需要手动编辑,除非你需要对解析过程进行一些特定的定制。
1 /* 2 这个类负责将输入的字符流切分成词法符号(tokens),如关键字、标识符、运算符等。ANTLR4会根据你的语法规则自动生成识别这些token的代码。 3 4 这里你会看到ANTLR为每种token类型分配了编号,并定义了如何识别它们的方法,比如识别整数INT、运算符、空白字符等。 5 */ 6 import org.antlr.v4.runtime.*; 7 import org.antlr.v4.runtime.atn.*; 8 import org.antlr.v4.runtime.dfa.DFA; 9 ... 10 11 public class CalculatorLexer extends Lexer { 12 ... 13 public static final int INT=4; 14 public static final int T__0=5; 15 public static final int WS=6; 16 17 // Lexer modes 18 19 // Token definitions 20 @Override 21 public void emit(Token token) { super.emit(token); } 22 @Override 23 public Token nextToken() { 24 ... 25 } 26 27 // Lexer rules 28 @Override 29 public String getText() { 30 ... 31 } 32 33 // Skip whitespace and comments 34 ... 35 36 // Token names and literals 37 ... 38 }
1 /* 2 这个类基于词法分析器输出的token序列构建抽象语法树(AST)。ANTLR根据你的语法规则定义了对应的解析规则方法。 3 4 在这个文件中,ANTLR为你的每个语法规则(如expr)生成一个对应的解析方法,以及相关的Context类来表示解析树中的节点。expr方法会递归调用自身来处理操作符的优先级,构建出表达式的解析树。 5 */ 6 import org.antlr.v4.runtime.*; 7 import org.antlr.v4.runtime.atn.*; 8 import org.antlr.v4.runtime.dfa.DFA; 9 ... 10 11 public class CalculatorParser extends Parser { 12 ... 13 14 public static class ExprContext extends ParserRuleContext { 15 public Token op; 16 public ExprContext(ParserRuleContext parent, int invokingState) { ... } 17 public TerminalNode INT() { return getToken(CalculatorParser.INT, 0); } 18 public List<ExprContext> expr() { 19 return getRuleContexts(ExprContext.class); 20 } 21 ... 22 } 23 24 public ExprContext expr() { 25 return expr(0); 26 } 27 28 private ExprContext expr(int precedence) { 29 ... 30 // Parsing rules based on your grammar 31 ... 32 } 33 34 // Other helper methods and context classes for each rule in your grammar 35 ... 36 }
步骤 3: 编写解析逻辑
1 import org.antlr.v4.runtime.*; 2 import org.antlr.v4.runtime.tree.*; 3 4 public class CalculatorMain { 5 public static void main(String[] args) throws Exception { 6 String input = "3 + 4 * 2"; 7 CharStream cs = CharStreams.fromString(input); 8 CalculatorLexer lexer = new CalculatorLexer(cs); 9 CommonTokenStream tokens = new CommonTokenStream(lexer); 10 CalculatorParser parser = new CalculatorParser(tokens); 11 ParseTree tree = parser.expr(); // 解析入口规则 expr 12 System.out.println(tree.toStringTree(parser)); // 打印抽象语法树(AST) 13 14 // 如果需要,你可以进一步遍历AST并计算结果 15 } 16 }
步骤 4: 执行并测试
编译并运行上述Java程序,它会打印出抽象语法树的结构。要实际计算表达式的结果,你还需要实现一个访问者模式的遍历器来遍历抽象语法树并计算每个节点的值。
这个例子展示了ANTLR4如何被用来从零开始构建一个简单的DSL解析器。你可以根据需要扩展这个基础框架,增加更多的语法规则、错误处理逻辑以及复杂的操作。
汇编补充
https://decaf-lang.github.io/minidecaf-tutorial-deploy/docs/lab1/part1.html
第一个步骤中,MiniDecaf 语言的程序就只有 main 函数,其中只有一条语句,是一条 return 语句,并且只返回一个整数(非负常量),如 int main() { return 233; }。
第一个步骤,我们的任务是把这样的程序翻译到汇编代码。 不过,比起完成这个任务,更重要的是你能
- 知道编译器包含哪些阶段,并且搭建起后续开发的框架
- 了解一大堆基本概念、包括 词法分析、语法分析、语法树、栈式机模型、中间表示
- 学会开发中使用的工具和设计模式,包括 gcc/qemu、词法语法分析工具 和 Visitor 模式*
读内容 *词法分析* *语法分析* *目标代码生成*
MiniDecaf 源文件 --------> 字节流 ----------> Tokens(词) ---------> 语法树-------> RISC-V 汇编
词法分析
词法分析(lexical analysis) 是我们编译器的第一个阶段,实现词法分析的代码称为 lexer , 也有人叫 scanner 或者 tokenizer。
-
它的输入 是源程序的字节流
如
"\x69\x6e\x74\x20\x6d\x61\x69\x6e\x28\x29\x7b\x72\x65\x74\x75\x72\x6e\x20\x30\x3b\x7d"。上面的其实就是
"int main(){return 0;}"。 -
它的输出 是一系列 词(token) 组成的流(token stream)1
上面的输入,经过 lexer 以后输出如
[关键字(int),空白、标识符(main),左括号,右括号,左花括号,关键字(return),空白、整数(0),分号,右花括号]。
如果没有词法分析,编译器看到源代码中的一个字符 '0',都不知道它是一个整数的一部分、还是一个标识符的一部分,那就没法继续编译了。
为了让 lexer 完成把字节流变成 token 流的工作,我们需要告诉它
-
有哪几种 token
如上,我们有:关键字,标识符,整数,空白,分号,左右括号花括号这几种 token
token 种类 和 token 是不一样的,例如 Integer(0) 和 Integer(222) 不是一个 token,但都是一种 token:整数 token。
-
对于每种 token,它能由哪些字节串构成
例如,“整数 token” 的字节串一定是 “包含一个或多个 '0' 到 '9' 之间的字节串”。 不过这没考虑负数,后面 “语义检查” 会继续讨论。
词法分析的正经算法会在理论课里讲解,但我们可以用暴力算法实现一个 lexer。 例如我们实现了一个 minilexer(代码)当中, 用一个包含所有 token 种类的列表告诉 lexer 有哪几种 token(上面第 1. 点), 对每种 token 用正则表达式描述它能被那些字节串构成(上面第 2. 点)。
细化到代码,Lexer 的构造函数的参数就包含了所有 token 种类。 例如其中的 TokenType("Integer", f"{digitChar}+", ...) 就定义了 Integer 这种 token, 并且要求每个 Integer token 的字符串要能匹配正则表达式
[0-9]+,和上面第 2. 点一样。
你可尝试运行 minilexer,运行结果如下(我们忽略了空白)
$ python3 minilexer.py1 token kind text 2 Int int 3 Identifier main 4 Lparen ( 5 Rparen ) 6 Lbrace { 7 Return return 8 Integer 123 9 Semicolon ; 10 Rbrace }
语法分析
语法分析
语法分析(syntax analysis) 是紧接着词法分析的第二个阶段,实现语法分析的代码称为 parser 。
- 它的输入 是 token 流
就是 lexer 的输出,例子上面有
- 如果输入没有语法错误,那么 它的输出 是一棵 语法树(syntax tree)
比如上面的程序的语法树类似
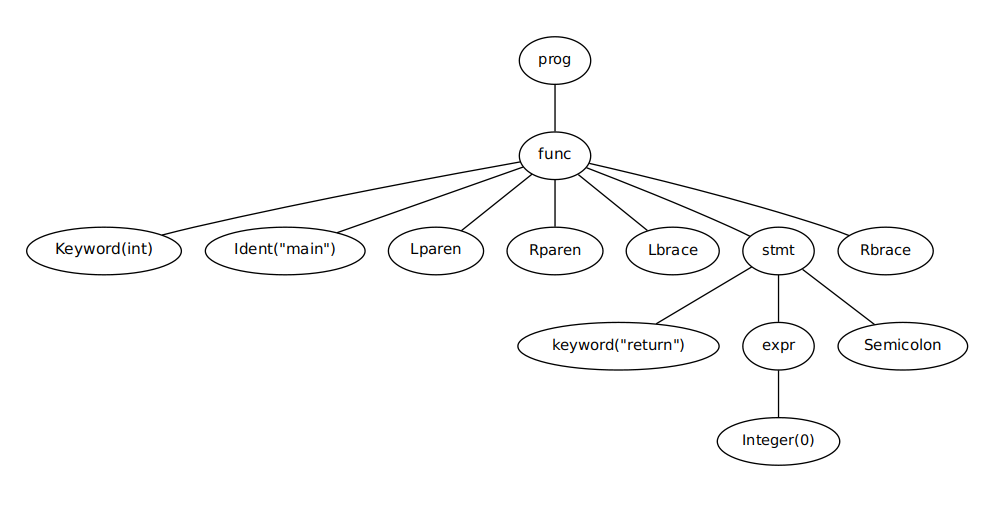
编译原理的语法树就类似自动机的 语法分析树,不同的是语法树不必表示出实际语法中的全部细节。 例如上图中,几个表示括号的结点在语法树中是可以省略的。
语法分析在词法分析的基础上,又把程序的语法结构展现出来。 有了语法分析,我们才知道了一个 Integer(0) token 到底是 return 的参数、if 的条件还是参与二元运算。
语义检查
有时我们会用 语法检查 这个词,因为语法分析能发现输入程序的语法错误。 对应语法检查,还有一个词叫 语义检查。 它检查源程序是否满足 语义规范,是否有 语义错误,例如类型错误、使用未定义变量、重复定义等等。
目标代码生成
- 它的输入 是一棵 AST(抽象语法树(AST, abstract syntax tree))
- 它的输出 是汇编代码
这一步中,为了生成代码,我们只需要
- 遍历 AST,找到 return 语句对应的
stmt结点,然后取得 return 的值, 设为 X 2 - [可选] 语义检查,若 X 不在 [-2147483648, 2147483647] 中则报错;并且检查函数名是否是 main。
- 打印一个返回 X 的汇编程序


