机器学习
【Coursera版本学习目录】 https://github.com/fengdu78/Coursera-ML-AndrewNg-Notes
(一)监督学习(线性回归、逻辑回归、神经网络、支持向量机SVM)。
(二)无监督学习:聚类K-meas算法、主成分分析PCA,异常检测(主要用于无监督,某些角度又类似监督学习),推荐系统(基于内容的推荐、协同过滤—基于用户喜好的推荐)。
(三)在机器学习的最佳实践(偏差/方差理论;误差分析;偏差/方差权衡)
- Cost Function代价函数
- 概念区别
- Hypothesis Function:h代表学习算法的解决方案或函数也称为假设(hypothesis),或称为假设函数
- 损失函数(Loss Function )是定义在单个样本上的,算的是一个样本的误差。
- 代价函数(Cost Function )J 是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。
- 目标函数(Object Function)定义为:最终需要优化的函数。等于经验风险+结构风险(也就是代价函数 + 正则化项)。代价函数最小化,降低经验风险,正则化项最小化降低
1. 监督学习
1.1 线性回归
已知:3个训练样本(1,1)、(2,2)、(3,3); 假设 假设函数为h(x)=𝞡1*x(𝞡0=0);
当 𝞡1=1时,J(𝞡1)=0;𝞡1=0.5时,J(𝞡1)=0.58;𝞡1=0时,J(𝞡1)=2.3;𝞡1=-0.5时,J(𝞡1)=3.75; 画出J(𝞡1)曲线--即目标函数(不同𝞡1情况下,代价--平方误差和);

梯度下降方法::需要同时更新𝞡0、𝞡1,convergence:收敛
- 𝞡0、𝞡1:初始值,比如0
- 𝜶:learning rate(学习率)—— 梯度下降时,我们迈出多大的步子;𝜶就用大步子下山,𝜶很小就迈着小碎步下山
- 求梯度(导数/偏导数):∂J(𝞡0、𝞡1) / ∂J𝞡0


1.1.1 梯度下降技巧
1.1.1.1 特征缩放
特征缩放的方法:(Feature Scaling,也称 Feature Normalization 特征标准化):如果能确保不同特征的取值在相近范围内,梯度下降法就能更快的收敛(否则:来回震荡)
- X / (max-min)
- 均值归一化
- (X-mean) / (max-min)
- (X-mean) / std

1.1.1.2 选择学习率𝜶
𝜶从0.001开始,取3的倍数

1.1.2 特征和多项式回归
当你预测房子价格时,你不一定要直接只用给出的特征x1(长)、x2(宽),你可以自己创造新的特征 如area=长 * 宽;有时通过构造新特征,你可能会得到一个更好的模型。
如何将模型与数据进行拟合呢?(so how do we actually fit a model like this to our data?)
- 先看下述的点,用线性方程不能很好拟合;感觉用二次方程可以拟合 再往后看又不太对 因为会下降 随着面积加大 房价下降 不太对;用三次方程可能是更合理的
- 令 x2 = size^2 ,x3 = size^3 用线性回归的方法,就可以拟合这个模型了
- 涉及平方,立方,特征的缩放就特别重要

1.1.3 梯度下降与正规方程的比较:
|
梯度下降 |
正规方程 |
|
需要选择学习率 |
不需要 |
|
需要多次迭代 |
一次运算得出 |
|
当特征数量大时也能较好适用 |
需要计算 如果特征数量n较大则运算代价大,因为矩阵逆的计算时间复杂度为,通常来说当小于10000 时还是可以接受的 |
|
适用于各种类型的模型 |
只适用于线性模型,不适合逻辑回归模型等其他模型 |
1.2 分类
把线性回归应用于分类中:有时候会有效果,但通常不是好办法。
如果我们要用线性回归算法来解决一个分类问题,对于分类, y 取值为 0 或者1,但如果你使用的是线性回归,那么假设函数的输出值可能远大于 1,或者远小于0,即使所有训练样本的标签 y 都等于 0 或 1。尽管我们知道标签应该取值0 或者1,但是如果算法得到的值远大于1或者远小于0的话,就会感觉很奇怪。
接下来的要研究的算法就叫做逻辑回归算法,这个算法的性质是:它的输出值永远在0到 1 之间。

1.2.1 逻辑回归
1.2.1.1 假设函数&决策边界&梯度下降求解
假设 假设函数为h(x)=g(𝞡^T*x);

模型的解释:estimated probability 概率估计
给定的参数是 𝞡 ,病人的特征为x的情况下(肿瘤的大小),为恶性肿瘤的概率为 h 𝞡(x)=P(y=1 | x; 𝞡 )

现在讲下决策边界(decision boundary)的概念。这个概念能更好地帮助我们理解逻辑回归的假设函数在计算什么。
我希望大家能够清晰的理解什么时候h(x)将>=0.5,即最终预测y=1
- 中间这条线:x1 + x2 =3称为 决策边界(decision boundary),对应h 𝞡(x)=0.5;该条线将平面分成了两部分,其中一部分假设函数预测y=1 (h 𝞡(x)>0.5,即当 𝞡’x>0时),另一部分假设函数预测y=0(h 𝞡(x)<0.5,即当 𝞡’x<0时)
- 决策边界:是假设函数本身的属性,决定于𝞡,而不是数据集的属性(虽然如下图画出了数据集,正好在决策边界两侧)
- 当然,后面我们还学习如何拟合数据,即如何利用训练集来确定参数的值;但是如果我们一旦确定参数𝞡,我们将完全确定决策边界,而不需要通过绘制训练集来确定决策边界。


梯度下降求解:
- 目标 min J(𝞡),新的x要预测时候,求假设函数h 𝞡(x) = P(y=1 | x; 𝞡)
- 求解:梯度下降法


1.2.1.2 多分类问题
对上述所有的例子, y 可以取一个很小的数值,一个相对"谨慎"的数值,比如1 到3、1到4或者其它数值,以上说的都是多类分类问题,顺便一提的是,对于下标是0 1 2 3,还是 1 2 3 4 都不重要,我更喜欢将分类从 1 开始标而不是0,其实怎样标注都不会影响最后的结果。
- 现在我们有一个训练集,好比上图表示的有3个类别,我们用三角形表示y=1 ,方框表示y=2,叉叉表示y=3 。我们下面要做的就是使用一个训练集,将其分成3个二分类问题(一个正例,其它负例)。
- 最后,在我们需要做预测时,我们将所有的分类机都运行一遍,然后对每一个输入变量,都选择最高可能性的输出变量。

1.2.2 正则化-解决过拟合
上面的回归问题中如果我们的模型是:h 𝞡(x) = 𝞡0 + 𝞡1x1 + 𝞡2x2^2 + 𝞡3x3^3 + 𝞡4x4^4; 我们可以从之前的事例中看出,正是那些高次项导致了过拟合的产生,所以如果我们能让这些高次项的系数(𝞡3、𝞡4)接近于0的话,我们就能很好的拟合了。 所以我们要做的就是在一定程度上减小这些参数𝞡 的值,这就是正则化的基本方法。我们决定要减少𝞡3和𝞡4的大小,我们要做的便是修改代价函数J(𝞡),在其中𝞡3和𝞡4 设置一点惩罚(penalize)。这样做的话,我们在尝试最小化代价时也需要将这个惩罚纳入考虑中,并最终导致选择较小一些的和。 修改后的代价函数如下:(正则化背后的思想-左图)
101个参数𝛉,我不知道该去缩小哪些,于是我将缩小每个参数的值,加入𝝀项 ( 惩罚项——约定俗成,𝛉下标从1开始,实际中两者没什么区别),并且让代价函数最优化的软件来选择这些惩罚的程度。——右图
- 𝝀:正则化参数,作用为:控制两个不同目标之间的取舍,从而保持假设模型的相对简单,避免出现过拟合的情况。
- 第一个目标:与目标函数的第一项有关, 就是我们想去训练,更好的拟合数据(训练集)
- 第二个目标:保持参数𝛉尽量地小,与目标函数的第二项有关


- 例子:
- 如果用高阶多项式拟合,会得到一个图像非常曲折的函数 —— 蓝色
- 如果你想保留所有多项式里的特征,加一个正则项,就可以得到一个曲线,不是二次函数但却相对更平滑、简单(相对上述曲折函数) —— 红色
- 欠拟合(右图):𝝀过大


1.2.3 决策树
1.2.3.1 决策树和LR的区别
LR模型是一股脑儿的把所有特征塞入学习,而决策树更像是编程语言中的if-else(一个个特征连续判断)一样(也像人类的思维),去做条件判断,这就是根本性的区别。

1.2.3.2 信息熵
信息熵(补充):对信息不确定性进行度量,越小让我们判断越有序(有价值);熵在化学中是表示分子的混乱程度,分子越混乱,它的熵就越大,而若分子越有序,熵值就越小。
假设你要知道一件未知的事情,比如明天会不会下雨。这时候你就需要去获取一些信息,比如空气干湿度,今天是万里无云还是多云等等(假设没有天气预报)。这些信息中,有的可以让你能更加准确判断明天会不会下雨(比如今天有没有云——信息熵小),而有信息些则不会让你判断更加准确(比如今天晚餐吃什么——信息熵大)。
计算信息熵的公式如下:(log_2为底的)

其中U指的是某一信息,pi则是指信息中各种可能出现的结果的概率。
比如U为空气湿度,空气湿度一共有3种(干燥,微湿,湿润),则可以p1表示空气干燥的概率,p2表示空气微湿的概率,p3表示空气湿润的概率,这些概率都是可以通过样本统计出来的。
然后空气湿度的信息熵就可以计算出来了:
H(空气湿度) = -[p1 * log(p1) + p2 * log(p2) + p3 * log(p3)]
1.2.3.3 如何构建决策树
- 计算类别变量(即因变量y)的熵。
- 现在我们需要计算每个特征的加权平均熵,即我们已经计算出的每个特征x_i的权重总和乘以概率:E(S, outlook) = (5/14)*E(3,2) + (4/14)*E(4,0) + (5/14)*E(2,3) = (5/14)(-(3/5)log(3/5)-(2/5)log(2/5))+ (4/14)(0) + (5/14)((2/5)log(2/5)-(3/5)log(3/5)) = 0.693)
-
计算信息增益:即 计算的父节点的熵与特征加权平均熵之间的差(选择差最大的)。信息增益描述了一个特征带来的信息量的多少。在决策树分类问题中,信息增益就是决策树在进行属性选择划分前和划分后的信息差值
-
- 接下来是在决策树中找到下一个节点。我们在晴天(sunny)下找一个节点。

熵:表示随机变量的不确定性。
条件熵:在一个条件下,随机变量的不确定性。
信息增益:熵 - 条件熵。表示在一个条件下,信息不确定性减少的程度。
通俗地讲,X(明天下雨)是一个随机变量,X的熵可以算出来, Y(明天阴天)也是随机变量,在阴天情况下下雨的信息熵我们如果也知道的话(此处需要知道其联合概率分布或是通过数据估计)即是条件熵。
X的熵减去Y条件下X的熵,就是信息增益。具体解释:原本明天下雨的信息熵是2,条件熵是0.01(因为如果知道明天是阴天,那么下雨的概率很大,信息量少),这样相减后为1.99。在获得阴天(条件)这个信息后,下雨信息不确定性减少了1.99,不确定减少了很多,所以信息增益大。也就是说,阴天这个信息对明天下雨这一推断来说非常重要。
所以在特征选择的时候常常用信息增益,如果IG(信息增益大)的话那么这个特征对于分类来说很关键,决策树就是这样来找特征的。
链接:https://www.zhihu.com/question/22104055/answer/67014456
1.2.4 生成学习算法(高斯判别、朴素贝叶斯)
到目前为止,我们讨论的学习算法都是直接对 p(y | x;𝚹)建模,即对给定的x,y的条件分布。这里我们将讨论一种不同类型的学习算法。
学习算法可以分为两种,
- 一种是尝试去直接学习得到 p(y | x) (直接学到后验概率 例如逻辑回归),或者尝试去学习直接将输入映射到0或1的方法(例如感知器算法),这种算法被称为「判别学习算法」;
- 而另外一种学习算法被称为「生成学习算法」,这种算法会尝试先对 p(x | y) 以及p(y) 建模。当我们为 p(y) (被称为「class priors 先验类,y是一种分类」) 和 p(x | y)建模后,我们的算法会使用「高斯判别分析-连续 / 贝叶斯定理-离散」来计算给定 x后 y的「后验概率 p(y | x)」:p(y | x) = p(x | y) p(y) / p(x),其中分子可以通过条件概率的转换表达式 p(x, y) = p(x | y) p(y)得到,分母可以通过 p(x) = p(x | y=1)p(y=1) + p(x | y=0)p(y=0)得到(针对二分类)
对于分类问题,我们需要对每种 y 的情况分别进行建模。当有一个新的 x 时,计算每个 y 的后验概率(即 p(y | x)),并取概率最大的那个 y 作为预测输出。
由于只需要比较大小,而 p(x) 对于大家都是一样的,所以可以忽略分母,得到下式:


【对于这个函数:P ( x ∣ θ ) 】输入有两个:x表示某一个具体的数据;θ 表示模型的参数。
- 如果θ 是已知确定的,x 是变量,这个函数叫做概率函数(probability function),它描述对于不同的样本点x,其出现概率是多少。
- 如果x 是已知确定的,θ 是变量,这个函数叫做似然函数(likelihood function), 它描述对于不同的模型参数,出现x这个样本点的概率是多少。
【极大似然估计 vs 最大后验估计】
- 极大似然估计(Maximum likelihood estimation, 简称MLE):是求参数θ , 使似然函数P(x | θ) 最 大 (x是确定的)。
- 可以认为:把先验概率P ( θ ) 认为等于1,即认为θ 是客观存在的
- 最大后验概率估计(Maximum a posteriori estimation, 简称MAP:贝叶斯估计):则是想求y ,使P(x0 | y ) P(y)最 大 。求得的θ 不单单让似然函数P(x0 | y)大,y 自己出现的 先验概率P (y)也得大。 (这有点像正则化里加惩罚项的思想,不过正则化里是利用加法,而MAP里是利用乘法)
- 可以认为:把先验概率P ( y )也是服从某种分布的,即认为y 是随机的
- p(y | x) = p(x | y) p(y) / p(x), arg max(y) {p(y | x) }= arg max(y) { p(x | y) p(y)},因为求最大、分母 p(x) 对大家都是一样的,(x1, x2, x3) = (大小, 颜色, 形状)
- 假定,给定y时,苹果的三个特征:大小、颜色、形状 是条件独立的,即第i个样本 x^(i) = [ x_1^(i), x_2^(i), x_3^(i) ],则 P(x^(i) | y) = P( x_1^(i), x_2^(i), x_3^(i) | y) = P(x_1^(i) | y) P(x_2^(i) | y) P(x_3^(i) | y)
- arg max(y) { p(x | y) p(y)} = arg max(y) { p(x | y) p(y)} = arg max(y) {P(x_1^(i) | y) P(x_2^(i) | y) P(x_3^(i) | y) p(y)}
1.2.4.1 高斯判别分析GDA
在这个模型中,我们会假设 p(x | y)属于「多元正态分布」(即已知类别y的情况下,样本特征x属于多元正态分布) (x是连续变量)。y ~ 伯努利分布
1.2.4.2 朴素贝叶斯
例1:
让我们以识别垃圾邮件为例,这类问题被称为「文本分类」问题。假设我们有一个训练集(已经标记好了是否为垃圾邮件的邮件集合),我们首先需要构建表示一封邮件的特征向量。
我们通过如下方式表示特征向量:其长度为词表的长度,词表为所有可能出现的词的集合(维数极高的分布),一般通过训练集生成。如果这封邮件包含了第 i 个词,x_i = 1,否则x_i = 0。下图为一个简单的例子:


选择好特征向量后,我们需要来构建生成模型。但考虑到 x 是一个高维向量,因此如果直接对 p(x | y) 建模,那么会得到一个参数向量的维数极高的多项分布,使计算过于复杂。
因此,我们需要做一个强力的假设,假设给定 y 时,每一个 x_i 是条件独立的。这个假设被称为「朴素贝叶斯假设」,其引出的算法被称为「朴素贝叶斯分类器」。注意是条件独立而不是独立,即仅在给定 y 的情况下独立。
现在我们有(以50000维度为例):

第一个等式来自于概率的基本性质;第二个等式则使用了朴素贝叶斯假设()。即使这个假设在现实中不一定成立,但其实际的效果还是不错的。
例2:朴素贝叶斯分类器的训练学习的过程便是基于训练数据(苹果集),求得类的先验概率P(c)(即先验类P(y):好果、坏果的概率),并且为新样本的每个属性求得类条件概率,然后相乘取最大值的过程。
例如:
现在在超市我正要买的一个苹果(新的样本)的特征如下:
大小 颜色 形状 好果
大 红色 圆形 ?
问是好果还是一般的苹果,根据已有的数据集概率是多大?
(1)先验概率 P(c) ,简化的求解方法:c类样本的个数除以所有样本个数,因此:
P(c=好果)= 4/10
P(c=坏果) = 6/10
(2)每个属性的类条件概率,可以初步这么求解:新的样本 x^(i)=[大, 红色, 圆形],在原有训练集中(10个),这个类别下的样本中对应这个属性的样本个数除以这个类别下的样本个数,因此:
P(大小=大 | c=好果) = 3/4
P(颜色=红色 | c=好果) = 4/4
P(形状=圆形 | c=好果) = 3/4
P(大小=大 | c=坏果) = 3/6
P(颜色=红色 | c=坏果) = 1/6
P(形状=圆形 | c=坏果) = 2/6
因此:
P(c=好果) * [ P(大小=大 | c=好果) * P(颜色=红色 | c=好果) * P(形状=圆形 | c=好果) ]
= 4/10 * 3/4 * 4/4 * 3/4
= 0.225
P(c=一般) * [ P(大小=大 | c=一般) * P(颜色=红色 | c=一般) * P(形状=圆形 | c=一般) ]
= 6/10 * 3/6 * 1/6 * 2/6
= 0.0167
显然,0.225 > 0.0167, 所以:这个苹果为好果。
1.2.5 集成学习(随机森林)
集成学习的思路是通过合并多个模型来提升机器学习性能,这种方法相较于当个单个模型通常能够获得更好的预测结果。这也是集成学习在众多高水平的比赛如奈飞比赛,KDD和Kaggle,被首先推荐使用的原因。
一般来说集成学习可以分为三大类:
- 用于减少方差的bagging(袋装):在原始数据集上通过有放回的抽样的方式,重新选择出 T 个新数据集来分别训练 T 个分类器的集成技术(结合策略,得到最后的强化学习器)。也就是说这些模型的训练数据中允许存在重复数据。
- 用于减少偏差的boosting(提高)
- 用于提升预测结果的stacking(堆叠)
Bagging和Boosting的区别
1 样本选择︰Bagging算法是有放回的随机采样;Boosting算法是每一轮训练集不变,只是训练集中的每个样例在分类器中的权重发生变化,而权重根据上一轮的分类结果进行调整;
2 样例权重︰Bagging使用随机抽样,样例的权重;Boosting根据错误率不断的调整样例的权重值,错误率越大则权重越大;
3 预测函数︰Bagging所有预测模型的权重相等; Boosting算法对于误差小的分类器具有更大的权重;
4 并行计算︰Bagging算法可以并行生成各个基模型;Boosting理论上只能顺序生产,因为后一个模型需要前一个模型的结果;
5 Bagging是减少模型的variance(方差);Boosting是减少模型的Bias(偏度);
6 Bagging里每个分类模型都是强分类器,因为降低的是方差,方差过高需要降低是过拟合;Boosting里每个分类模型都是弱分类器,因为降低的是偏度,偏度过高是欠拟合。
1.2.5.1 bagging和随机森林
- 随机森林(Random Forest):在Bagging策略的基础上进行修改后的一种算法
- 从样本集中用Bootstrap采样选出 $n$ 个样本;
- 从所有属性中随机选择 $K$ 个属性,选择出最佳分割属性作为节点创建决策树;
- 重复以上两步 $m$ 次,即建立 $m$ 棵决策树;
- 这 $m$ 个决策树形成随机森林,通过投票表决结果决定数据属于那一类。
1.2.5.2 boosting
在正式介绍Boosting思想之前,先介绍两个例子:
第一个例子:不知道大家有没有做过错题本,我们将每次测验的错的题目记录在错题本上,不停的翻阅,直到我们完全掌握。
第二个例子:对于一个复杂任务来说,将多个专家的判断进行适当的综合所作出的判断,要比其中任何一个专家单独判断要好。实际上这是一种“三个臭皮匠顶个诸葛亮的道理"。
这两个例子都说明Boosting的道理,也就是不错地重复学习达到最终的要求。
Boosting(提升学习)算法指将弱学习算法组合成强学习算法,它的思想起源于Valiant提出的PAC(Probably Approximately Correct)学习模型。可以用于回归和分类的问题。
Boosting: 是一种串行的算法,通过弱学习器开始加强,它每一步产生弱预测模型(如决策树),并加权累加到总模型中;如果每一步的弱预测模型的生成都是依据损失函数的梯度方式的,那么就称为梯度提升(Gradientboosting)。
基本思想:不同的训练集是通过调整每个样本对应的权重实现的,不同的权重对应不同的样本分布,而这个权重为分类器不断增加对错分样本的重视程度。 (类似于专家经验)
Boosting 的意义∶如果一个问题存在弱预测模型,那么可以通过提升技术的办法得到一个强预测模型;
常见的模型有:
- Adaboost (是英文"Adaptive Boosting"(自适应增强)的缩写)
- Gradient Boosting(GBT/GBDT/GBRT/XGBoost) (梯度提升算法)
基本步骤:
- 首先赋予每个训练样本相同的初始化权重,在此训练样本分布下训练出一个弱分类器;
- 利用该弱分类器更新每个样本的权重,分类错误的样本认为是分类困难样本,权重增加,反之权重降低,得到一个新的样本分布;
- 在新的样本分布下,在训练一个新的弱分类器,并且更新样本权重,重复以上过程T次,得到T个弱分类器。
1.3 神经网络
我们已经学习了线性回归、逻辑回归,为什么还要学习神经网络学习。为了阐述研究神经网络学习的目的,我们首先来看几个机器学习问题作为例子,他们都需要学习复杂的非线性假设。
如下的非线性的多项式项,其中包含很多像这样的多项式,当多项式项数足够多时,那么你就可以得到将正负样本分开的假设(如下 红色的非线性决策边界)。当只有两个特征时 x1、x2,这种方法确实能得到不错的结果,因为你可以把x1、x2的所有组合都包含到多项式中。
- 但是,许多机器学习问题的特征远不止两项,例如下面问题有100个特征,即使只包含二次多项式(如x1^2、x1*x2、x1*x3… ,约为5000个二次项特征= C5000 2;如果再包含3次项,特征空间膨胀更厉害 大概是O(n^3))。因此,要包括所有二次项特征并不是一个好方法:
- 由于项数过多,最终的结果可能是过拟合的
- 运算量过大
- 你也可以选择只包含上述二次项中的子集作为特征(如x1^2、x2^2、x3^2…),则决策边界可能是椭圆,无法像左上角这么复杂的边界
- 如果要拟合如下这样的分类问题,不可能得到理想的结果
- 如果初始特征个数n较大,把这些高阶多项式包含到特征里面,会使得特征空间急剧膨胀,增加这样的特征来建立非线性分类器并不是一个好办法。
-
当人眼看到一辆汽车(一张图片)时,计算机看到的是像素点矩阵(一个像素的表示:黑白图--1二进制位,灰度图—256种情况(1字节=8二进制位,2^8)、0-255,RGB彩色图—3个字节(红、绿、蓝)、每个字节8位
- 假设我们用 50*50像素的图片,即长宽各有50个像素点
- 灰度图片:n=2500 传统的计算机视觉 x = [pixel1 pixel2 … pixel2500]’ 或者 50*50矩阵,每个元素的值是灰度值(0-255)
- 彩色图片 RGB:每个像素点包含红绿蓝三个值,即3个50*50矩阵,n=7500
- 如要我们要通过包含所有的二次项特征(xi * xj)来学习得到非线性假设,那所有特征约为 3 million features (7500^2)
- 可以看到上述图片尺寸是500 * 338 的,表示图片是由一个500 * 338的像素点矩阵构成的,这张图片的宽度是500个像素点的长度,高度是338个像素点的长度,共有500 * 338 = 149000个像素点
- 因为一个像素点的颜色是由RGB三个值来表现的,所以像素点矩阵对应三个颜色向量矩阵,分别是R矩阵(500 *338大小),G矩阵(500 *338大小),B矩阵(500 *338大小)
- 如果每个矩阵的第一行第一列的值分别为:R:240,G:223,B:204,所以这个像素点的颜色就是(240,223,204)
- 如果每个矩阵的第一行第二列的值分别为:R:255,G:0,B:9,所以这个像素点的颜色就是(255, 0, 9)
- 因为一个像素点的颜色是由RGB三个值来表现的,所以像素点矩阵对应三个颜色向量矩阵,分别是R矩阵(500 *338大小),G矩阵(500 *338大小),B矩阵(500 *338大小)
-
- 接下来的课程中,我将为大家讲解神经网络,它在学习复杂的非线性假设上被证明是一种好得多的方法。即使n很大,也能很快搞定。


1.3.1 直观理解
我们学习该如何表示神经网络,即运用神经网络时 我们该如何表示我们的假设或模型。神经网络模仿了大脑中的神经元或神经网络,为了解释如何表示假设模型,我们先来看单个神经元在大脑中是什么样的。我们的大脑中充满了这样的神经元,神经元是大脑中的细胞。其中有三点值得注意:
- 神经元有像这样的细胞体(cell body)
- 神经元有很多的输入通道(输入电线)(input wires),叫树突(dendrites);接收其它神经元的输入信息
- 有一条 输出通道,叫住轴突(axon):用来给其它神经元传递信号
简而言之,神经元是一个计算单元,它从输入通道接手一定数目的信息,并做一些计算,然后将结果通过它的轴突传送到其它节点。

人工神经网络:
将使用一个简单的模型,来模拟神经元的工作。我们将神经元模拟成一个逻辑单元:
- 黄色圆圈可以理解为类似神经元细胞体的东西,对 h 𝞡(x)
- 𝞡为模型的参数,在神经网络中也会称为权重(weights),完全一样的东西
- 一些输入通道
- 通常会增加一个x0,称为偏置单元(bias unit) 或 偏置神经元(bias neuron)(x0==1,总等于1,有时候会画出,有时候不画出)
- 一个输出通道(轴突输出计算结果)
sigmoid(logistic) activation function (带有sigmoid(logistic)激活函数的人工神经元):激活函数的主要作用是提供网络的非线性建模能力(若没有激活函数,就是x的线性组合)

上图代表的是单个神经元,神经网络其实就是一组神经元连接在一起的集合。
- 最左侧:输入层
- 最右侧:输出层,输出整个假设的最终结果
- 中间的第二层:称为 隐藏层(hidden layer)——神经网络中可能不止一个隐藏层
- 直觉上,在监督学习中,我们能看到输入,也能看到正确的输出,而隐藏层的值在训练集里是看不到的
- 它的值不是x,也不是y,所以我们叫它为隐藏层
1.3.2 前向传播算法
为了方便计算(记号统一),把x记录为:a^(1),(1)为上标;右侧为整个向量化表示方法,用右侧的公式就会得到一个有效的计算h(x)的方法;前向传播算法( FORWARD PROPAGATION ))

这种向前传播算法,也可以帮助我们了解神经网络的作用,和它为什么能够帮助我们学习有趣的非线性假设函数。
- 盖住左边,有点像逻辑回归,用Lay3的节点来预测(这个逻辑回归单元)来预测h(x)的值
- 如果你只观察蓝色的标记,跟逻辑回归非常像
- 其实就是逻辑回归,只是逻辑回归的输入是通过隐藏层计算的这些数值(而不是原始输入x1、x2、x3);即把逻辑回归中的输入向量[x1~x3]变成了中间层的[a1^(2) ~ a3^(2)]
(比前面更复杂的特征)( 而每一层的结果由网络参数 𝛳决定,如第一层隐射到第二层的函数,这个函数由𝛳^(1)决定)
1.3.3 反向传播算法
1.3.3.1 神经网络的代价函数
- 在神经网络中使用的代价函数是逻辑回归代价函数的一般形式 (第二项是:正则化项;不包括𝛉0,这只是一个合理的约定,即使加进去了𝛉0,依然是有效的,即使结果有点不一致)
-
我们将来尝试优化这个代价函数。

1.3.3.2 如何最小化代价函数(最优化的迭代)
上节课中我们学习了代价函数(cost function),本节课我们将学习让代价函数最小化的算法:即反向传播算法(Backpropagation)。 —— 计算代价函数的偏导数
为了计算min J(𝛉) (𝛉是参数),需要计算J(𝛉)和偏导数(重点)

- 反向传播算法的名字 源于如下:即把输出层的误差项,反向传播给了前一层误差项(层层传播,如下图橙色标识和箭头)
- 我们从输出层开始计算误差项 𝛅 项:
- 𝛅 j ^(4) = a j ^(4) - y j —— 第4层第j个节点的误差
- 然后返回到上一层,计算该隐藏层的 𝛅 项
- 如下为误差项 𝛅 j ^(3) 、𝛅 j ^(2) 等的表示;如 𝛅 j ^(3) = (𝛉^(3))^T 𝛅 j ^(4) .* g’(z^(3))
- g’(z^(3)) 是S型函数的导数= a^(3) * (1 - a^(3))
- g’(z) = e^(-z) / (1+e^(-z))^2 = g(z) (1-g(z))
- a^(3) = g(z^(3))
- 如下为误差项 𝛅 j ^(3) 、𝛅 j ^(2) 等的表示;如 𝛅 j ^(3) = (𝛉^(3))^T 𝛅 j ^(4) .* g’(z^(3))
-
一种直观的理解就是,反向传播算法就是在计算 𝛅 j^(l)
* 直观理解:第l层中第j个单元(unit j in layer l)得到的激活项 a j^(l) 的误差
* 正式理解:𝛅 j^(l):cost(i)关于 z (j)^(l)的偏导数 ( z (j)^(l) 是一个中间项,即加权和);或者说代价函数关于z项的偏导数
* 把中间项z (j)^(l) 的值稍微改一下,就会影响到神经网络的输出值h 𝚹(x),最终将改变代价函数的值。
- 我们从输出层开始计算误差项 𝛅 项:
- 我们有了所有的误差的表达式后,便可以计算代价函数的偏导数了(如下公式)



当我们有一个非常大的训练样本时,如何进行计算参数的偏导项
- set 𝚫ij^(l) = 0(最好随机初始化网络参数)(for all l, i, j)
- for循环对每一个样本(x^(i), y^(i)):即首先用正向传播方法计算出每一层的激活单元,利用训练集的结果与神经网络预测的结果求出最后一层的误差,然后利用该误差运用反向传播法计算出直至第二层的所有误差。
- set a^(1) = x^(i);把x^(i)赋值给 输入层的激活值
- 利用前向传播算法,计算每一层的激活值a^(l),l=2,3,…,L
- 利用y^(i)计算输出层的误差 𝛅 ^(L) = a^(L) - y
- 利用反向传播算法计算前面各个层次的误差𝛅 ^(L-1)、𝛅 ^(L-2),… ,𝛅 ^(2) (没有𝛅 ^(1),因为我们不用考虑输入层的误差)
- 𝚫ij^(l) := 𝚫ij^(l) + a j^(l) 𝛅 i^(l+1),用偏导数来累计𝚫ij^(l) 项
- 向量化的形式:𝚫^(l) := 𝚫^(l) + 𝛅^(l+1) (a^(l))^T
- 原始英文:we’re going to use these capital delta terms to accumulate these partial derivative terms that we wrote down on the previous line. 用delta项来累积我们在前一行写下的偏导数项
- 最后,跳出循环—— 在求出了𝚫ij^(l) 之后,我们便可以计算代价函数的偏导数(就是 Dij^(l))
1.3.4 CNN和ResNet
1.3.4.1 简单神经网络
深度学习(神经网络)的基本流程就是:
- 准备和标注数据
- 定义模型的结构(或叫 选用模型) (第2步,图片识别领域有很多公开模型,通常情况下直接选用这些公开模型就可以了)
- 训练模型从而找到一组合适的参数 (第3步训练模型也是有现成的算法,我们只需要调整训练参数(比如learning rate等)即可)
- 测试模型的效果并根据情况进行迭代
一个简单的神经网络,包括1个输入层,1个输出层和1个隐藏层。
如果输入图片是28x28的灰度图片,分成10个分类,那么构建一个神经网络来实现这个分类模型的话,它的输入层就需要28x28=784个神经元(RGB图片还要*3)(每个值为0-255),输出层就有10个神经元。
下面这种神经网络每层的神经元之间都是全连接的(简单神经网络),它的参数量和计算量都非常大,非常难以训练,这种结构在图片识别领域中不实用。在图片识别领域中,最常见的是神经网络结构叫卷积神经网络(洋文叫convolutional nerual network,CNN)

1.3.4.2 CNN
CNN中的隐藏层主要有3种类型(https://easyai.tech/ai-definition/cnn/):
- 卷积层Convolution – 主要作用是提取图片的特征 (我们使用一个过滤器(卷积核)来过滤图像的各个小区域,从而得到这些小区域的特征值。和用PhotoShop中的滤镜突出某些特征相似)——对于像素矩阵来说,也是降维了;
- CNN中常用的激活函数有ReLU、Sigmoid和Tanh等,ReLU(Rectified Linear Unit) ReLU是非常常用的激活函数,它的定义为f(x) = max(0, x)
- 池化层Pooling – 主要作用是把数据降维,可以有效的避免过拟合 (max [1, 1, 5, 6] = 6)
- 全连接层Fullly connected – 根据不同任务输出我们想要的分类结果;
-
因此全连接层就是执行WX得到一个T*1的向量(也就是图中的logits[T*1]),这个向量里面的每个数都没有大小限制的,也就是从负无穷大到正无穷大。然后如果你是多分类问题,一般会在全连接层后面接一个softmax层,这个softmax的输入是T*1的向量,输出也是T*1的向量(也就是图中的prob[T*1],这个向量的每个值表示这个样本属于每个类的概率),只不过输出的向量的每个值的大小范围为0到1。(https://blog.csdn.net/u014380165/article/details/77284921)
-

注:denselayer 密集层 https://www.sohu.com/a/199026699_610300
1.3.4.2.1 迁移学习和微调
迁移学习是指利用已有的神经网络模型来解决其他不同但相关的问题。举个例子,现在图片分类模型已经很多,比如VGG,Inception,Resnet, Mobilenet等(
AlexNet(2010)—> VGG(2014) ——> GoogLeNet V1(2014)——>ResNet(2015)——>DenseNet(2017)——>MobileNet(2019))
,这些模型已经在Imagenet的1000个分类的数据集上训练好了。我们就可以借助这些已经预先训练好的模型来解决其他的图片分类问题,比如上面视频中hotdog or not hotdog模型。具体怎么做呢?
我们以VGG模型为例
上图是VGG的模型是个1000个图片分类模型,输出层包含了1000个神经元,也就是输入图片分别属于这1000个分类的概率。输入的图片经过一系列卷积和Pooling层以后,最后变成了倒数第二层的4096维的向量(也就是4096个数值),这4096个数值与最后输出层的1000个神经元全连接。模型中倒数第二层左边的细节可以先暂时忽略。
现在我们要借助这个模型来训练我们的2个分类的模型(比如判断图片是否为汽车),只需把上述模型的最后一层的那1000个节点给去掉,改成最后一层只包含2个节点,这样这个模型就变成了一个二分类的模型了。你需要训练几分类的模型,就把最后一层改为几个节点。这样我们就得到了一个基于VGG模型、适用于我们场景的模型了。其他的模型,比如Inception, Resnet, Mobilenet(https://blog.csdn.net/qq_43257640/article/details/105155476)都是一样的操作。

如果直接用这样修改过的模型到进行预测,效果肯定是不会好的。那么接下来我们就需要用我们收集到数据来训练模型。由于模型的参数很多,
- 1. 通常我们首先固定倒数第二层左边所有层的参数,让这些参数在训练过程中保持不变,训练过程中只调整倒数第二层和最后一层的之间的参数。如果一切顺利的话,这样也可以得到一个效果不错的模型。
- 2. 如果你还要进一步提高模型的准确率的话,可以逐渐将倒数第二层左边的层的参数 逐渐设置为可调(这个过程叫做fine tune 微调,应该包含1),这样通常能提高模型的准确率。
到此,理论部分的介绍就结束了,接下来是实战,利用keras和tensorFlow来训练适合特定场景的分类和目标检测模型。(现在我们开始用Keras来训练一个图片分类模型。Keras是构建在Theano、TensorFlow等底层深度学习引擎上的一套API。相比较于直接使用TensorFlow,Keras的API非常易于理解和使用。只需要几行代码(简单易用、门槛低),就可以开始训练你的模型了。)
1.3.4.3 ResNet
1.3.4.3.1 深度学习退化问题
自AlexNet以来,以CNN为基石的网络模型越来越深(层数越来越多)。AlexNet有5个卷积层,VGG有19层,GoogleNet( 也称Inception_v1)有22层。之所以这么一直在增加网络深度,是有这么一个理论:根据卷积的计算方式,我们认为深度卷积网络逐层整合了不同层级的特征,伴随着模型前向推演,模型获得了更加抽象、更多层级、更加丰富的图像特征,进而获得了更好的模型性能。因此我们会倾向于使用更深层次的网络结构!!!!
补充:低层级特征拥有更多的细节信息;高层级特征更加抽象,能够更好的表达图像局部或者整体的意义。
但是经过试验证明,很深的网络一般会有两个问题:
(1)在很深的网络层中,由于参数初始化一般更接近0,这样在训练过程中通过反向传播更新浅层网络的参数时,很容易随着网络的深入而导致梯度消失,浅层的参数无法更新。
(2)当网络达到一定深度后,模型性能会暂时陷入一个瓶颈很难增加,当网络继续加深后,模型在测试集上的性能反而会下降!这其实就是深度学习退化(degradation)(如下)!
我们看图可以发现无论是在训练集还是在测试集上,56层的神经网络性能都不如20的神经网络。

注意:造成这种现象的原因可能有(1)过拟合(2)梯度消失/梯度爆炸(3)网络退化。
(1)不可能是过拟合
过拟合是过多的拟合了训练集,因此在训练集上效果好(偏差低),而在测试集上效果差(方差高)。但是我们发现无论是训练集误差还是测试集误差其实都在下降,只是幅度不一样。这说明了更深的网络性能不好是因为网络没有被训练好,其原因是后面的多层非线性网络无法通过训练去逼近恒等映射网络。
解释一下上面红字的意思:通常认为在同一个训练集上,深层网络的性能无论如何都不应该比浅层网络差。假设A是一个56层的网络,B是一个20层的网络,若想让A和B拥有同样的性能,只需要将A中的20层替换为B,然后将A中剩下的36层全部优化为恒等映射(即输入=输出)。但是实验证明,后面36层的非线性网络很难学习逼近恒等映射(看图即可得到)。
(2)不是梯度消失/梯度爆炸:层数过多,梯度反向传播时由于链式求导连乘使得梯度过大或者过小,使得梯度出现消失/爆炸
作者在论文中说到,理论上的梯度消失和梯度爆炸都应该被批量归一化 Batch normalization(BN)解决了。BN通过规整数据的分布解决梯度消失/爆炸的问题。
————————————————
原文链接:https://blog.csdn.net/xiao_ling_yun/article/details/109092265
1.3.4.3.2 深层CNN为啥发生退化
网络退化原因:论文大意是当神经网络越来越深,在反向传播时候,反传回来的梯度之间的相关性会越来越差,最后接近白噪声。因为我们知道图像是具备局部相关性的(所谓局部相关,就是你判断图片中某个物体的属性时,起关键作用的是物体邻近的小片像素区域,而距离较远的像素相关性较弱),那其实可以认为梯度也应该具备类似的相关性,这样更新的梯度才有意义,如果梯度接近白噪声,那梯度更新可能根本就是在做随机扰动。即使BN过后梯度的模稳定在了正常范围内,但梯度的相关性实际上是随着层数增加持续衰减的。而经过证明,ResNet可以有效减少这种相关性的衰减。
1.3.4.3.3 ResNet到底解决了什么
https://zhuanlan.zhihu.com/p/139772304
对于深层网络的退化现象,何凯明大神希望用一种方式,使得深层神经网络至少能和浅层神经网络相持平(深层不能比浅层的差),因此设计了一种残差结构来解决该问题。
这里说个概念:恒等映射,让x的映射等于x,即H(x) = x 。
如下图所示,左边为浅层网络,右边为深层网络,如果想让左右两边持平,就得让后面的五层网络进行恒等映射,即输入等于输出,相当于不起任何作用。ResNet就是利用这种恒等映射,使得网络加深时,至少能保证和浅层网络相持平。
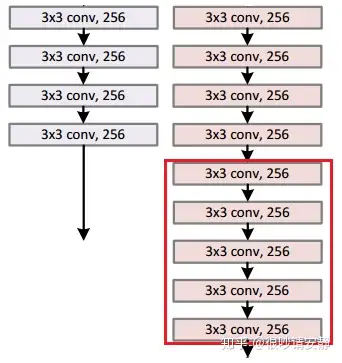
残差单元设计
基于上述思想,希望设计一个如下的网络结构,输入x,输出H(x) = F(x) = x , F(x) 表示残差单元的输出,H(x) 表示期望的输出,即恒等映射。
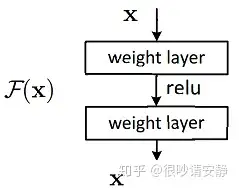
但是有种更巧妙的方式,将残差单元设计成如下的方式:
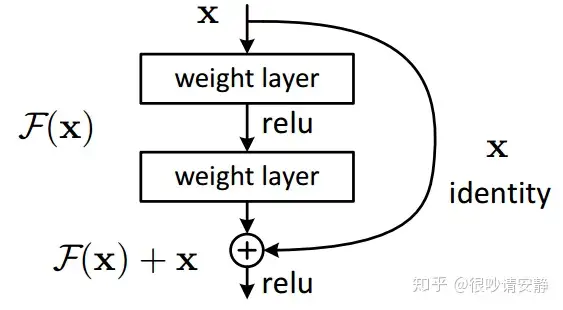
令 H(x)=F(x, w) + x ,所以 F(x, w) =H(x) - x ,即残差形式, w为残差结构中的参数矩阵。当 H(x)为恒等变换时, F(x, w)=0 。
这样设计非常巧妙,主要有以下优点:
- 首先直观理解,如上图所示,x通过shortcuts(跳接操作)作为残差单元的一部分,如果图中的两层网络对结果无益,那么直接通过跳接输出结果(即 w=0 ),即输入等于输出;
- 使得残差单元中参数学习恒等隐私更加容易,
- 如果直接使得 F(x, w) = H(x) = x ,那么 w 通常是个非稀疏矩阵 —— 直接学习恒等映射是困难的;
- 如果令 F(x, w) =H(x) - x,在恒等映射情况下, F(x, w) =0=>w=0 ,而参数初始化时一般都在0附近,使其产生恒等映射更加容易;
- H'(x)=F'(x,w)+1 ,除非F'(x,w)=−1 ,否则不会出现梯度消失的情况;
1.3.4.3.4 ResNet的网络结构
ResNet18的18层代表的是带有权重的18层,包括卷积层和全连接层,不包括池化层和BN层。
1.4 支持向量机SVM
到目前为止,你已经见过一系列不同的学习算法。在监督学习中,许多学习算法的性能都非常类似,所以,经常要考虑的东西不是你该选择使用学习算法A还是学习算法B,而更重要的是,应用这些算法时,所创建的大量数据在应用这些算法时,表现情况通常依赖于你的水平。这就体现了你应用这些算法时的技巧,比如你所设计的用于学习算法的特征的选择,以及正则化参数的选择等等。
还有一个更加强大的算法广泛的应用于工业界和学术界,它被称为支持向量机(Support Vector Machine)。与逻辑回归和神经网络相比,支持向量机,或者简称SVM,在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。
1.4.1 从逻辑回归优化目标逐步修改得出SVM
1.4.1.1 构建SVM的单样本的代价函数
我将会从逻辑回归开始展示我们如何一点一点修改来得到本质上的支持向量机。
现在考虑一下,我们想要逻辑回归做什么:
- 如果我们有一个样本(来自训练集 或 交叉验证集 或 测试集),如果y=1,那我们希望 h 𝚹(x)尽可能接近1 即 h 𝚹(x)≈1(因为我们想要正确地将样本进行分类),𝚹^(T)x >> 0 (远大于0)
- 对应地,如果有另一个样本,其中y=0,那我们希望 h 𝚹(x)尽可能接近0 即h 𝚹(x)≈0,𝚹^(T)x << 0

如果观察逻辑回归的代价函数,你会发现每个样本(x,y)都会为总的代价函数增加这样一项(Cost of example,表示每个单独的训练样本对逻辑回归总体目标函数所做的“贡献”)。因此,对于总的代价函数,我通常会对多有的训练样本从1到m项目进行求和。
现在我们考虑两种情况,一种是y=1的情况,一种是y=0的情况。
- y=1的情况(左侧),这时目标函数中只有第一项起作用,因为当y=1,第二项就等于0;画出Cost of example曲线如左下角,也就是说当𝚹^(T)x >> 0 ,Cost of example接近0 该样本对代价函数的影响很小;
-
y=0的情况(右侧),这时目标函数中只有第二项起作用,因为y=0时,第一项等于0
为了构建支持向量机SVM,我们把单样本的代价函数(cost of example)改成如下玫红色的两段直线,左右两侧分别记为cost1(z)、cost0(z)

1.4.1.2 构建SVM的整个训练集的代价函数
从逻辑回归的训练集代价函数,做修改:
1.替换单样本代价为cost1(z)、cost2(z)
2.我们要去掉1/m这一项
3.第三个是符号的变化 (A + 𝛌B 变成 CA + B),你也可以把C想象成 1/𝛌,这并不是说这两个表达式是相等的,是说这两个表达式的优化目标应该得到相同的 𝚹 最优解。
于是,就得到了SVM的总体优化目标。当你最小化这个函数,就得到了SVM学习得到的参数(左图)
最后,与逻辑回归不同的是,SVM并不会输出概率,支持向量机进行了一个直接的预测 h 𝚹(x) = 1 或 0,SVM的假设函数为(Hypothesis)—右图:
- h 𝚹(x) = 1 ,if 𝚹^(T)x >= 0
- h 𝚹(x) = 0 ,otherwise
- SVM——目标 min J(𝞡) (代价函数从逻辑回归修改演进而来),求出𝞡; 新的x要预测时候,求假设函数h 𝞡(x) =1 if 𝞡^Tx>=0, 0 otherwise (不是输出概览,直接预测1或0)


- 逻辑回归——目标 min J(𝞡),求出𝞡; 新的x要预测时候,求假设函数h 𝞡(x) = P(y=1 | x; 𝞡) (若𝞡^Tx>=0,则h 𝞡(x) >= 0.5 预测y=1;否则 预测y=0)


1.4.2 大边界分类器
这是支持向量机一个很有趣的性质,也就是如果你有一个正样本,比如y=1,其实我们只需要使 𝚹^(T)x >=0 ,就能正确地进行分类。因为如果 𝚹^(T)x >= 0,假设模型的预测结果就为0 (上一节 h 𝚹(x) 的定义)。
但是,支持向量机对此有更高的要求,不是恰好能正确分类就行了,𝚹^(T)x不是略大于0就可以了,我们需要的是 𝚹^(T)x 比0大很多,比如 𝚹^(T)x > =1;负样本也类似, 𝚹^(T)x <= -1。这就相当于在SVM中,构建了一个安全因子(或安全间距)。 如下为解释;
如果C很大很大,那么当最小化优化目标的时候,我们将迫切希望能找到一个值,使得第一项等于0。
- 当你有一个标签y=1的训练样本,如果你要使第一项为0(即代价函数cost1(z)==0),那么你需要找到一个𝚹值使得𝚹^(T)x^i >= 1
- 同样的,当你有一个标签y=0的训练样本,为了使代价函数cost0(z)==0,需要 𝚹^(T)x^i <= -1

因此,如果我们把优化问题看作是 通过参数选择来使得第一项==0,那么原始优化问题就变成了另一个优化问题(如下面这样)
min C*0 + (1/2)∑𝚹j^2(因为我们通过选择参数,使得它等于0)
s.t. 𝚹^(T)x^i >= 1 if y^i=1 (正样本时)
𝚹^(T)x^i <= -1 if y^i=0(负样本时)
(中图)从数学上来说,也就是这条黑色的决策边界拥有更大的距离,这个距离叫做间距(that distance is called margin)。现在我再画两条蓝色的线,可以发现黑色的【决策边界 和 训练样本的最小距离 】要更大一些。相比之下紫线和绿色,它们与训练样本的间距就非常地近,在分离样本时,它们的表现会比黑线更差。因此,这个距离叫做支持向量机的间距(margin),这使得支持向量机具有鲁棒性,因为它在分离数据时会用尽量大的间距去分离。因此,SVM有时被称为大间距分类器(large margin classifier),这就是我们上页(左图)幻灯片列出的优化问题的结果。
(右图)关于大间距分类器,我这里还想说最后一点。现在的这个【大间距分类器 直观理解】,是在常数C被设的非常大的情况下得出的(C very large);给定这样一个数据集,也许我们会选择这样一条决策边界 用大间距来分开正样本和负样本,现在SVM实际上要画比这个大间距的视图更加复杂,尤其当你只使用大间距分类器的时候,这时你的学习算法对异常点会很敏感,我们加进去一个额外的正样本(左下角),那么为了将样本用大间距分开,可能会是这样的一条边界(紫色)。在这样一个异常点的影响下,只因为这样一个样本,就将决策边界从这条黑色 变为 这条紫色 可能不是个好主意。因此,如果C (即正则化常数C )被设得非常大,那么SVM就会将决策边界从黑线变成紫线;
但如果C比较小,如果你把C设置的不是那么大(C not too large)那么最后你得到的还是这条黑线 (异常点 不影响)。当然;如果数据不是线性可分的,比如 多了两个 两个正样本(左上角)、多了一个 负样本(右侧),那么SVM依然能够正确地进行分类 (决策边界是线性的直线吗??? 只是 不受 异常点影响???);
因此,这幅描述大间距分类器的图片,只有在正则化参数C被设得非常大的时候,才能让人直观理解大间距分类器的作用。同时也提醒你理解C的作用,类似于1/𝛌(𝛌是我们之前使用的正则化参数)
- C 较大时,相当于 𝛌 较小,可能会导致过拟合,高方差。
- C 较小时,相当于 𝛌 较大,可能会导致低拟合,高偏差。
也就是当1/𝛌非常大 或者 𝛌 非常小的时候,你最终会得到类似这条紫色的决策边界。但是【实际中,当应用支持向量机的时候,当C不是非常大时】,它可以忽略像这样的异常点来得到正确地结果,甚至数据不是线性可分的时候,支持向量机也能做的很好。当之后我们讲到,SVM环境中的偏差和方差的时候,希望你那时候可以更清楚的理解正则化参数的权衡。



1.4.3 改造SVM支持非线性分类器-核函数;
1.4.3.1 核函数的概念-如何训练非线性边界
本次课程中,我们将改造支持向量机算法来构造复杂的非线性分类器,主要的技巧就是称之为核(kernel)的一种东西。我们看看核函数是什么 以及 如何使用它。
如果你有一个像这样的训练集,然后你希望拟合一个非线性的判别边界来区别正负实例。一种办法是构造一个复杂多项式的集合,可能的模型决策边界为 𝚹0 + 𝚹1 x1 + 𝚹2 x2 + 𝚹3 x1x2 + 𝚹4 x1^2 + 𝚹5 x2^2 + .. ≥ 0,那假设函数
- h 𝚹(x) = 1 , if 𝚹0 + 𝚹1 x1 + 𝚹2 x2 + 𝚹3 x1x2 + 𝚹4 x1^2 + 𝚹5 x2^2 + .. ≥ 0;
- h 𝚹(x) = 0 , otherwise.
我先引入后面会用到的新的符号,我们可以把假设函数看成是用这个𝚹0 + 𝚹1 f1 + 𝚹2 f2 + 𝚹3 f3 + … 计算的决策边界。在这里,我将用这几个新的符号f1、f2等来表示我将要计算的新的特征变量,所以f1=x1,f2=x2,f3=x1x2,f4=x1^2,f5=x2^2,… 我们之前看到的这些高阶项,是一种得到更多特征的方式(非线性—>线性)。但问题是,我们可以有很多不同的特征选择,或者可能会存在比这些高阶多项式更好的特征。
有一种可以构造新特征f1、f2、f3…的方法。在这行中我将只定义三个新特征,但对于实际问题而言,我们可以定义非常多的特征变量。但我们这里要做的是,对于特征x1、x2(I’am going to leave x0 out of this),我打算选取一些点,然后将这个点称为l^(1),再取一个不同的点l^(2),再取第三个点l^(3)。现在假设我只手动选取这三个点,我把这些点叫做标记(landmark,标记、地标),标记1、标记2、标记3。我要做的是,像这样定义新的特征,给定一个实例x,让我将第一个特征f1定义为 一种相似度的度量,即度量训练样本与第一个标记l^(1)的相似度(其实就是距离的远近)
- given x:f1 =similarity(x, l^(1)) = exp(- || x-l^(1) ||^2 / 2𝛔^2);其中分子为点x与标记l^(1)之间的欧氏距离取平方
- f2 =similarity(x, l^(2)) = exp(- || x-l^(2) ||^2 / 2𝛔^2)
- f3 =similarity(x, l^(3)) = exp(- || x-l^(3) ||^2 / 2𝛔^2)
相似度函数用数学家的术语来说就是 一个核函数(kernel function),这里用的是高斯核函数(之后我们会看到别的核函数)。注:这个函数与正态分布没什么实际上的关系,只是看上去像而已。
我们一般不写similarity(x, l^(i)),而是用 k(x, l^(i))。我们看下核函数到底做了什么,为什么这些相似度函数表达式(如上的f1、f2、f3的定义)是有意义的
先来看看我们的第一个标记l^(1),f1 =similarity(x, l^(1)) = exp(- || x-l^(1) ||^2 / 2𝛔^2) = exp (- ∑(xj - l j^(l))^2 / 2𝛔^2)
这这几张幻灯片中 我忽略了x0,因此暂时先不管截距项x0,x0总是等于1;那么现在你应该知道了如何计算核函数,用x和标记之间的相似度。让我们来看看这个函数做了什么。
- If x ≈ l^(1) 假设x与其中一个标记点非常接近;那么这个欧式距离 以及 这个分子就会接近于0,那 f1 ≈ 1
- if x is far from l^(1),那 f1 = exp(- (large number)^2 / 2𝛔^2) ≈ 0
这些特征做的就是衡量x到标记l^(1)的相似度,如果x非常接近标记l^(1),那么特征f1非常接近1,如果x和标记l^(1)非常远,那么f1会接近于0。
这就是【核函数这部分的概念,以及我们如何在支持向量机中使用它们】:我们通过标记点和相似性函数 来定义新的特征变量,从而训练复杂的非线性边界。

1.4.3.2 怎么选取标记点l^(1)、l^(2)...:用m个训练样本;
直接将m个训练样本作为标记点。
如果我们有一个训练样本(x^(i), y^(i)),我们对这个样本要计算新的特征就是这样的,第i项为1,其它为两两相似度,即特征向量 f^(i),共m维

1.5 不同分类器的选择
我们从逻辑回归开始构造了SVM,然后更改了一下代价函数。在这个视频中,最后要说明的一点,当你使用两者任意的一种算法时,比如n代表特征的数量,m代表样本的数量,那我们该如何选择两者中的一个呢?
- (1)如果相较于m而言,n要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归 或者 不带核函数的支持向量机( 或叫 线性核函数( a linear kernel ,用原始特征x)
- 如n=10000,m=10-1000,如垃圾邮件分类问题中 你有1w个特征(与1w个单词对应的特征向量),但你可能只有10个训练样本(或多达1000个)
- 因为,如果你有许多特征变量,而相对较小的训练集,线性函数可能会工作得很好;而且你也没有足够多的数据,来拟合非常复杂的非线性函数。
- (2) 如果n较小,而且m大小中等,例如n在 1-1000 之间,而m在10-10000之间(也许多达5w,但不是100w),使用高斯核函数的支持向量机。
- 这个在我们之前也讨论过一个具体的例子,如果你有一个二维的训练集(n=2),可以画出相当多的训练样本,高斯核函数可以把正分类和负分类很好的区分开来
- (3) 如果n较小,而m超大,例如n在1-1000之间,而m大于50000 甚至上百万,则使用高斯核函数的支持向量机会非常慢,【解决方案】是创造、增加更多的特征,然后使用 逻辑回归 或 不带核函数的支持向量机。
- 若n在1-1000之间(或稍大);m=5w,现有的SVM软件包会工作得很好,若m=10w,也能工作,但会有点慢;若m=100w,则会很慢
最后,【什么时候使用神经网络?】对上述所有的这些情况,设计良好的神经网络可能非常有效。
- 神经网络有一个缺点 或者 有时可能不会使用神经网络的原因是,对于许多这样的问题,神经网络训练起来可能会特别慢。
- 但是如果你有一个非常好的SVM实现包,可能会运行得比较快、比神经网络快很多。
- 尽管我们之前没有展示,但是事实证明SVM具有的优化问题是一种凸优化问题,好的SVM软件包总是会找到全局最小值 或者 接近它的值。对于SVM,你不需要担心局部最优。 在实际应用中,对于神经网络局部最优是一个不大不小的问题,所以这是你在使用SVM的时候不需要太去担心的一个问题。根据你的问题,神经网络可能会比SVM慢,尤其是 在这样一个体系中(上述(2))。
2. 应用机器学习的建议
2.1 决定下一步做什么
使用预测房价的学习例子,假如你已经完成了正则化线性回归,也就是最小化代价函数的值,假如,在你得到你的学习参数以后,如果你要将你的假设函数放到一组新的房屋样本上进行测试,假如说你发现在预测房价时产生了巨大的误差,现在你的问题是要想改进这个算法,接下来应该怎么办?实际上你可以想出很多种方法来改进这个算法的性能,
- 其中一种办法是使用更多的训练样本。
- 他们总认为,要是我有两倍甚至十倍数量的训练数据,那就一定会解决问题的是吧?但有时候获得更多的训练数据实际上并没有作用。在接下来的几段视频中,我们将解释原因。 我们也将知道怎样避免把过多的时间浪费在收集更多的训练数据上,这实际上是于事无补的。
- 另一个方法,你也许能想到的是尝试选用更少的特征集。因此如果你有一系列特征比如x1、x2、x3、…x100等等。也许有很多特征,也许你可以花一点时间从这些特征中仔细挑选一小部分来防止过拟合。
- 或者也许你需要用更多的特征,也许目前的特征集,对你来讲并不是很有帮助。你希望从获取更多特征的角度来收集更多的数据
- 增加多项式特征(x1^2、x2^2、x1x2等)
- 加大正则化项𝛌
- 减小正则化项𝛌
幸运的是,有一系列简单的方法(机器学习诊断法)能让你事半功倍,排除掉单子上的至少一半的方法,留下那些确实有前途的方法。它们也被称为"机器学习诊断法”(maching learning diagnostics)。“诊断法”的意思是:
- 这是一种测试法,你通过执行这种测试,能够深入了解某种算法到底是否有用。
- 这通常也能够告诉你,要想改进一种算法的效果,什么样的尝试,才是有意义的。
2.2 评估一个假设 (数据洗牌:分为训练集和测试集)
当我们确定学习算法的参数的时候,我们考虑的是选择参量来使训练误差最小化,有人认为得到一个非常小的训练误差一定是一件好事,但我们已经知道,仅仅是因为这个假设具有很小的训练误差,并不能说明它就一定是一个好的假设函数。而且我们也学习了过拟合假设函数的例子,所以这推广到新的训练集上是不适用的。
那么,你该如何判断一个假设函数是过拟合的呢?
- 对于这个简单的例子,我们可以对假设函数h(x)进行画图,然后观察图形趋势
- 但对于特征变量不止一个的这种一般情况,还有像有很多特征变量的问题,想要通过画出假设函数来进行观察,就会变得很难甚至是不可能实现。
- 因此,我们需要另一种方法来评估我们的假设函数过拟合检验。 为了检验算法是否过拟合,我们将数据分成训练集和测试集,通常用70%的数据作为训练集,用剩下30%的数据作为测试集。很重要的一点是训练集和测试集均要含有各种类型的数据,通常我们要对数据进行“洗牌”(随机处理),然后再分成训练集(70%)和测试集(30%)。
2.3 模型选择和交叉验证集
假设你想要确定对于一个数据集最合适的多项式次数(Suppose you’d like to decide what degree of polynomial to fit a data set),怎样选用正确的特征来构造学习算法;或者假如你需要选择学习算法中的正则化参数𝛌。你应该怎样做呢?这类问题称作模型选择问题。
如下图,不仅要确定参数𝚹,还要确定多项式维度d,即需要你的数据集来确定参数𝚹和多项式维度d。你要做的就是从如下10个模型中选择一个,拟合这个模型,并且估计这个拟合好的模型假设对新样本的泛化能力。那么你可以这样做
- 首先选择第一个模型然后最小化训练误差,这样你就会得到一个参数向量𝚹^(1),然后你再选择第二个模型来最小化训练误差,这样你就会得到另一个参数向量𝚹^(2)
- 对所有这些模型,求出测试集误差如J test(𝚹^(1))、J test(𝚹^(2))…
- 正确的:用10个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值)J cv(𝚹^(1))、J cv(𝚹^(2))…
- 3.选择测试集误差最小的那个模型(如5次方多项式)
- 这个模型的泛化能力如何呢?重新计算J test(𝚹^(5))。
- 实际上d=5是在测试集上拟合得到的,我再在测试集上评估假设就不公平了。
- 实际上假设在测试集上的表现可能好过它从来没见过的新样本。
- 正确的:
- 选取交叉验证误差(代价函数值)最小的模型(如3次方多项式)
- 用步骤3中选出的模型对测试集计算得出推广误差(代价函数的值)(或测试误差) J test(𝚹^(4)) —— 为了计算泛化能力;

为了解决模型选择(多个模型选1个)出现的问题,我们通常会采用如下的方法来评估一个假设。给定一个数据集,我们不是把他们分成训练集和测试集,而是把他们分成三个部分:训练集(training set)60%、交叉验证集(the cross validation set,或简称cv、验证集)20%、测试集(test set)20% ;典型比例 60%:20%:20%
2.4 诊断偏差和方差(多项式维度d和偏差 方差的关系)
当你运行一个学习算法时,如果这个算法的表现不理想,那么多半是出现两种情况:要么是偏差比较大(a high bias problem),要么是方差比较大( a high variance problem)。换句话说,出现的情况要么是欠拟合,要么是过拟合问题。 搞清楚是偏差问题 还是 方差问题,或者两者都有关系,这一点很重要。因为弄清楚到底是哪种情况就能很快找到有效的方法和途径来改进算法。
在这段视频中,我想更深入地探讨一下有关偏差和方差的问题,希望你能对它们有一个更深入的理解,并且也能弄清楚怎样评价一个学习算法,能够判断一个算法是偏差还是方差有问题,因为这个问题对于弄清如何改进学习算法的效果非常重要。

上面这幅图能帮助我们更好地理解偏差和方差的概念。具体来说,假设你得出了一个学习算法,而这个算法并没有表现地像你期望的那么好( 如你的交叉验证误差 或者 测试误差都很大),我们怎么判断此时的算法出现了高偏差的问题 还是 高方差的问题?
- 交叉验证误差比较大的情况
- 左侧:对应高偏差的问题(也就是 欠拟合情况,under fitting),也就是使用了一个过于小的多项式次数(如d=1),但实际上我们需要一个较高的多项式次数来拟合数据
- 右侧:对应高方差问题。如d=4 对于我们的数据来讲太大了
- 另一个视角
- 左侧:高偏差的情况(欠拟合的情况),训练误差和交叉验证误差都很大。
- 因此,如果你看到 J train(𝚹) 很大 且J cv(𝚹) ≈ J train(𝚹),则可推断你的算法可能是高偏差问题(欠拟合)
- 右侧:有高方差的问题(过拟合问题),训练误差会很小而交叉误差会很大
- 因此,如果你看到 J train(𝚹) 很小 且 J cv(𝚹) ≫J train(𝚹) ,则可推断你的算法可能是高方差问题(过拟合)
2.5 正则化和偏差/方差 (正则化参数𝛌和偏差 方差的关系)
你已经知道了正则化可以防止过拟合,但是你知道正则化和偏差和方差有什么关系呢?本节视频中,我想更深入讨论下偏差和方差的问题,它们和算法的正则化之间的关系,以及正则化是如何影响偏差和方差的。
- 𝛌 很大:则对 𝚹1、𝚹2、𝚹3等惩罚很重,最优化的结果就是这些参数大部分接近于0,则h𝚹(x)≈ 𝚹0 是一条直线。假设函数处于高偏差,对于数据严重欠拟合。
- 𝛌 很小:当我们拟合高阶多项时,如果未进行正则化(或者正则化项很小),则通常会出现过拟合。
- 中间合理的𝛌 :才能对数据比较好的拟合。
-
那么如何自动选择一个最合适的正则化参数值𝛌 呢?
-
我们选择一系列的想要尝试的 𝛌 值,如无正则化(𝛌 =0)、𝛌 =0.01、𝛌 =0.02…(通常我会以2倍速度增长,直到一个比较大的值 𝛌 = 10.24),最后再用上面的模型选择问题的方法选择合适的𝛌(在交叉验证集上误差最小,测试集上误差也符合预期(泛化能力))
-

2.6 学习曲线(J train(𝚹)、J cv(𝚹)关于m 的变化)
到目前为止,我们已经从不同角度了解了偏差和方差的问题,下一节视频中,我要做的是结合我们学过的所有概念在此基础上建立一个机器学习诊断方法也称为学习曲线,我通常用这个工具来诊断一个学习上算法是处在偏差问题还是方差问题,还是这两者都有的问题。
学习曲线 — J train(𝚹)、J cv(𝚹)关于m的曲线 】,来判断某一个学习算法,是否处于偏差、方差问题 或者 二者皆有。下面我们就来介绍学习曲线。
【通用情况】
为了绘制一条学习曲线,我通常先绘制出J train(𝚹)关于m(训练集中样本的数量)的曲线,m一般是常数,但是我要人为减小训练集 如m=50、40、30、20、10等,画出J train(𝚹)、J cv(𝚹)的变化。
- 以h𝚹(x)=𝚹0+𝚹1x+𝚹2x^2 二次函数为例,看J train(𝚹)的变化 (只有 一个特征x1:面积,用x1构造第二个特征 x1^2; 如果有另一个特征 x2:卧室数,可以构造另外的特征 x1x2, x2^2等)
- m很小时(如m=1、2、3),J train(𝚹)=0(无正则项),有的话也是接近于0
- 每一个样本,都能很容易的拟合到很好
- m很大时,要保证二次函数对所有样本的拟合效果依然很好就越来越困难了,J train(𝚹)很大↑
- 看J cv(𝚹)的变化,交叉验证集误差就是在没见过的交叉验证集上的误差
- 当训练集m很小的时候,泛化程度不会很好(J cv(𝚹)大),即不能很好的适应新样本
- 训练集m变大时,泛化程度变好(J cv(𝚹)↓);

【高偏差情况】
随着m增大, J train(𝚹) (训练误差)逐渐增大,最后接近 J cv(𝚹) (交叉验证误差) —— 这是因为你的参数很少,而数据量m又很大( 增加训练集m不一定能有帮助,如m从1到5几乎还是同一条直线),训练集和交叉验证集的误差将会非常接近。
【高方差情况】
高方差问题可以由交叉验证误差和训练误差之间有一段很大的差距(gap)反应出来。如果增大样本m数量,左图的蓝色和紫色曲线正在相互靠近,结论:高方差情况下,增大样本数量m对改进算法是有帮助的。
2.7 决定下一步做什么
- 获得更多的训练样本——解决高方差
- 尝试减少特征的数量——解决高方差
- 尝试获得更多的特征——解决高偏差
- 尝试增加多项式特征——解决高偏差
- 尝试减少正则化程度λ——解决高偏差
- 尝试增加正则化程度λ——解决高方差
2.8 如何为神经网络模型选择结构或者连接方式
最后,我们回顾一下学过的内容,并且看看它们和神经网络的联系,我想介绍一些很实用的经验,关于我平时是如何为神经网络模型选择结构或者连接形式。
当你在神经网络拟合的时候,你可以选择一种比如说一个相对简单的神经网络模型,如隐藏单元比较少的 甚至只有一个隐藏单元。当你在神经网络拟合的时候,其中一个选择就是选用比较简单的神经网络模型,比如只有很少甚至只有一个隐藏层,并且每一层只有少量的隐藏单元。像这样的神经网络,参数就不会很多,容易出现欠拟合,这种比较小型的神经网络最大的优势在于计算量较小。
与之相对的另一种情况是,拟合较大型的神经网络结构,比如每一层中的隐藏单元数很多 或者 有很多个隐藏层。这种比较复杂的神经网络,参数一般较多,更容易出现过拟合。这种结构的一大劣势,也许不是主要的 但还是需要考虑,那就是当网络有大量神经元时,这种结构会有很大的计算量,虽然这个情况通常来讲不成问题。这种大型网络结构,最主要的潜在问题 还是它更容易出现过拟合现象。但如果出现了过拟合,你可以使用正则化的方法来修正。用一个较大型的网络+正则化修正 通常比用 小型问题效果更好,唯一的问题就是计算量可能稍大。
最后,你还需要选择隐藏层的层数(模型选择的方法),你应该用一个隐藏层呢 还是用3个呢? 就像前面讲的,通常默认情况选择一个隐藏层是比较合理的选项,但是如果你想要选择一个最合适的隐藏层数,你也可以试试把数据分割为训练集、验证集合测试集,然后训练1个隐藏层、2个隐藏层、3个隐藏等..的神经网络,然后看看哪个神经网络在交叉验证集上表现得最理想。也就是用3个神经网络,分别有1个、2个、3个隐藏层,然后计算每个模型的J cv(𝚹),然后选出你认为最好的神经网络结构。
3. 机器学习系统的设计
3.1 机器学习系统设计步骤
当面对一个机器学习算法问题时:
- 如果你想学习机器学习(从事相关工作),最好的办法不是建立一个很复杂的有许多复杂特征的系统,而是通过一个简单的算法来快速实现它,每当我开始一个机器学习问题时,我最多只会花一天时间也就是24小时把这个项目简单粗暴的做出来,而不是设计一个很复杂的系统,即使这个速成的东西并不是很完美,然后通过交叉验证来测试它。
- 做完这些以后,你就能画出相应学习曲线(训练集m和 J train(𝚹)、J cv(𝚹)) 看看你的学习算法是否存在高偏差 或 高方差问题。在做出这些分析后,再来决定是否使用更多的数据或者特征等
- 误差分析(error analysis):意思就是当实现一个比如垃圾邮件分类器的时候,我经常会观察交叉验证集的情况,然后看看那些被算法错误分类的文件。通过查看这些被错误分类的垃圾邮件和非垃圾邮件,看看这些经常被错误分类的邮件,有什么共同的特征和规律。这样做多了以后,这个过程就会启发你应该设计怎样的新特征,或是告诉你现在的系统有什么优点和缺点,然后指导你想办法来改进它。
3.2 学习算法的数值(单一数字评价)评估
当你改进学习算法时,你总是要去尝试很多新主意和新版本的算法,如果你每次试用新方法都手动地去检测这些例子 看看表现地好不好,会让你很难去决定到底应不应该使用词干提取,该不该区分大小写。但是,通过一个【单一规则的数值评价指标 (如交叉验证误差 或叫 分类错误率)】,did the error go up or go down? 你可以通过它更快地实践你的新想法,它能直接告诉你 你的想法能提高还是降低 学习算法的表现,这会大大加速你的进程。
所以我强烈推荐在交叉验证集上来做误差分析,而不是测试集上。但是还是会有很多人,会在测试集上做,这样做从数学的角度来讲是不合适的。所以我推荐你,在交叉验证集上来做误差分析。
3.3 准召和F1 Score和AUC
3.3.1 有了分类错误率,为什么还要有准召
我们假设y=1表示患者患有癌症,假设y=0表示他们没有得癌症,我们训练逻辑回归模型,假设我们用测试集检验了这个分类模型并且发现它只有1%的错误,因此我们99%会做出正确诊断,看起来结果是非常不错的。
但是,假如我们在测试集中只有0.5%的患者真正得了癌症,因此在我们的筛选程序里只有0.5%的患者患了癌症。因此在这个例子中,1%的错误率就不再显得那么好了。
举个具体的例子,这里有一行代码 不是机器学习代码,它忽略了输入值x,它总是让y=0,因此它总是预测没人得癌症。那么这个算法只有0.5%的分类错误率(甚至比我们之前1%的错误率更好)。
这种情况发生在正样本和负样本的比例是一个极端情况,该例中正样本的数量与负样本的数量相比非常非常少,因为y=1非常少,我们把这种情况叫偏斜类(the case of skewed classes)
因此,如果你有一个偏斜类,用分类精确度/分类错误率 并不能很好地衡量算法,因为你很可能会获得一个很高的精确度和非常低的错误率,但是我们并不知道我们是否真的提升了分类模型的质量(因为总是预算y=0,并不是一个好的分类模型,但是总是预测y=0会将你的误差降低至比如0.5%)。
让我画一个2x2的表格(基于实际类 actual class和预测类 predicted class)。
- 预测=1 且 实际=1(阳性,positive),这个样本叫做 真阳性(true positive)
- 预测=0 且 实际=0(阴性,negative),这个样本叫做 真阴性(true negative)
- 预测=1 且 实际=0,这个样本叫做 假阳性(false positive)
- 预测=0 且 实际=1,这个样本叫做 假阴性(false negative)
第一个叫做查准率(precision):对于所有我们预测他们患有癌症的病人 有多大比率的病人是真正患有癌症的,分母是第一行
第二个叫做召回率(recall):如果所有的病人 假设测试集中或者交叉验证集中的的病人 如果所有这些在数据集中的病人确实得了癌症,有多大比率我们正确预测他们得了癌症。分母是第一列
通过计算准确率和召回率,我们能更好的知道分类模型到底好不好。具体地说,如果我们有一个算法,总是预测y=0即没人得癌症(即前面的例子,错误率只有0.5%—-准确率不是0.5%),那么这个分类模型 召回率=0,因为它不会有真阳性,因此我们能很快发现这个分类模型总是预测y=0,它不是一个好的模型。
- 查准率=0/0+0=???? (无意义??)
- 召回率=0/(0+5)=0%
|
|
|
Actual class |
Actual class |
|
|
|
1 |
0 |
|
Predict class |
1 |
0 |
0 |
|
Predict class |
0 |
5 |
955 |
3.3.2 准召的平衡:F1 score
让我们继续用癌症分类的例子,如果病人患有癌症 则y=1,反之则y=0。假设我们用逻辑回归模型训练了数据,输出概率0-1之间的值,因此我们预测y=1 如果h(x)>=0.5,预测值为0 如果h(x)<0.5。
——避免 假阳性:因为如果你告诉一个病人他们得了癌症,他们会非常震惊,鉴于这是一个非常坏的消息,而且他们会经历一段非常痛苦的治疗过程。因此,我们希望只有在非常确信的情况下才告诉这个人他得了癌症,避免假阳性。这样做的一种方法是修改算法,我们不再将临界值设为0.5,也许临界值提升0.7,如h(x)>=0.7才预测y=1(h(x)<0.7预测y=0); 或者提升到0.9
- 会有较高的查准率(high precision)—— 因为是在非常确信的情况下做出的预测
- 与之相反,这个回归模型会有较低的召回率(lower recall)—— 因为当我们做出预测的时候,我们只给小部分的病人预测y=1
——避免 假阴性:假设我们希望避免漏掉患有癌症的人,即我们希望避免 假阴性(avoid false negatives)。我们不再设置高的临界值,我们会设置另一个较低的临界值(如0.3),我们认为他们有30%的概览患有癌症,我们以更加保守的方式告诉他们患有癌症,因此他们能够接受检查和治疗。
- 这种情况下我们会有一个较高召回率的模型。
- 会得到较低的查准率
如下右图 称为 PR曲线:


这又产生了另一个有趣的问题,那就是有没有办法自动选取临界值? 或者,更广泛地说,如果我们有不同的算法或者不同的想法,我们如何比较不同的查准率和召回率?
如果我们正在试图比较算法1、2、3,最后问我们自己到底0.5的查准率与0.4的召回率好,还是说0.7的查准率与0.1的召回率好,或者每一次你设计一个新算法都要坐下来思考到底0.5 0.4 还是说0.7 0.1好,我不知道,这会大大降低你的决策速度。
如果我们有一个评估度量值,一个数字能够告诉我们到底是算法1(准确率0.5、召回率:0.4)好还是算法2(准确率0.7、召回率0.1)好,只能够帮助我们更快地决定哪一个算法更好。
- 你可能会去尝试的第一件事情是计算查准率和召回率的平均值 Average = (P+R)/2;但这可能并不是一个很好的解决办法。
如果你只是使用(P+R)/2 ,算法3的这个平均值是最高的(即使你通过总是预测y=1得到这样的值),但这并不是一个好的模型;算法1、2 比算3更有用,但是3的(P+R)/2最高
- 有一种结合查准率和召回率的不同方式叫 F Score(F值 或 F1 Score),公式为 F1 Score = 2PR / (P+R),F1 Score大 这个算法就好;
- 它的定义会考虑一部分查准率和召回率的平均值,但是它会给查准率和召回率中较低的值更高的权重。因此,你可以看到F1 Score的分子是查准率和召回率的乘积,因此如果查准率等于0(或者召回率等于0),F1 Score也会等于0。因此,它结合了查准率和召回率,对于一个较大的F Score,查准率和召回率都必须较大

3.3.3 AUC
虽然通过PR曲线能够有效地观察同一模型在不同阈值下 精确率和召回率的变化情况,但是在不同模型之间却很难进行比较。此时,在基于PR曲线的基础上,可以通过计算曲线下面积(Area Under the Curve, AUC)来得到一个整体的评估值,
同时,由于Precision和Recall的取值范围均为[0,1],因此PR AUC的取值范围同样也是[0,1]。
3.4 机器学习的数据
【假设】特征值有足够的信息来预测y值,假设我们使用一种需要大量参数的学习算法,它们有很多参数,这些参数可以拟合非常复杂的函数,我将把这些算法想象成低偏差算法(low bias algorithm)
现在假设我们使用了非常非常大的训练集,在这种情况下,如果我们有一个庞大的训练集,那么尽管我们希望有很多参数,但是如果训练集比参数的数量更多,那么这些算法就不太可能会过度拟合(unlikely to overfit,低方差),也就是说 训练误差 接近 测试误差 ( J train(𝚹) ≈ J test(𝚹))
因此这给我们提出了一些可能的条件,一些对于问题的理解,如果你有大量的数据,而且你训练了一种带有很多参数的学习算法,那么这将会是一个很好的方式来提供一个高性能的学习算法,我觉得关键的测试我常常问自己的是:
- 首先,一个人类专家看到了特征值x,能很有信心的预测出y值吗,因为这可以证明y可以根据特征值x被准确地预测出来。
- 其次,我们是否能得到一组庞大的训练集,并且在这个训练集中训练一个有很多参数的学习算法。
如果你不能做到这两者,更多时候,你也可以得到一个性能很好的学习算法。
4. 无监督学习
4.1 聚类和K-means
聚类问题中,给定一组无标签的数据集,希望有一个算法自动将这些数据分成有紧密关系的子集或是簇。K-meas算法是当前最热门、最为广泛运用的聚类算法
K-meas算法用图像说明最合适不过了,假设我有一个无标签的数据集如图所示,并且我想将其分为两个簇。现在我执行K-meas算法,具体操作如下:
- 随机生成两点(因为我想分成两个簇),这两点就叫做聚类中心(cluster centroids),下图中的X(叉);
- K-meas是一个迭代算法,每次循环它会做两件事;
- (2.1)第一个是簇分配(cluster assignment):我要遍历每个样本(也就是图上的每个绿点),然后根据每一个点 是与红色聚类中心更近 还是与蓝色聚类中心更近,来将每个数据点分配给两个聚类中心之一 (具体的讲,就是遍历数据集,然后将每个点进行染色(红色或蓝色),取决于该点更接近于红色聚类中心 还是 更接近于蓝色聚类中心)
- (2.2)第二个是移动聚类中心:将红色的X 和 蓝色的X 移动到同色的均值处; 移动后,接近进行下一次簇分配
- 找出所有红色的点,然后算出它们的均值,然后把红色的X 移到这里
- 找出所有蓝色的点,然后算出它们的均值,然后把蓝色的X 移到这里
直到之后,聚类中心(X)位置不再变化,并且点的颜色也不会改变了。此时,我们可以说k-means已经收敛了(converged)。
该算法在找出数据中两个簇的方面做的相当好。

4.2 降维和PCA
4.2.1 降维的两个应用
这个视频,我想开始谈论第二种类型的无监督学习问题,称为降维(dimensionality reduction)。这里有一些你想要使用降维的原因,一是数据压缩(Data Compression),在之后的视频中我们可以看到,数据压缩不仅能让我们对数据进行压缩使得数据占用较少的内存或硬盘空间,它还能让我们对学习算法进行加速。
降维的第二个应用——可视化数据。假如我们收集了许多统计数据的大数据集,这是全世界各个国家的情况,所以类似于第一个特征 x1 是 GDP,x2是人均GDP,x3是人类发展指数,x4是平均寿命,x5、x6等等。假如有一个这样的巨大数据集,每一个国家有50个特征 即 x ∈ ℝ^50,而且我们有很多国家。所以有什么方法,能够使我们更好的理解这些数据呢?通过这么庞大的数据,你如何可视化这些数据,如果你有50个特征,你很难绘制一个50维的数据。
如果使用降维方法,我们能做的就是相比每个国家都使用50维的特征向量x^(i)来表示(如加拿大),我们最好是用一个不同的特征如向量z来表示它,z ∈ ℝ^2,这样的话我们能只用一对数字z1、z2来概述这50个数字,我们能做的就是把这些国家在2维平面上表示出来。用这种方法,来理解这些不同国家特征将会更好。所以,你需要做的是将这些数据从50维降低到2维,这样你就可以画一个2维图来表示它。你这么做了以后,你会发现当你观察降维算法的输出时,z通常不是你所期望的具有物理意义的特征,我们常常需要弄清楚这些特征大致意味着什么。这样做的问题在于,降维的算法只负责减少维数,新产生的特征的意义就必须由我们自己去发现了。比如
z1大概是国家的总体规模(overall country size)/ GDP,z2大概对应于人均GDP/每个人的幸福度/每个人的经济活跃度(per person GDP / per person well-being / economic activity)
4.2.2 降维是什么
不过首先,我们先来谈谈降维是什么。
举个例子,假设我们收集了一个数据集,它有很多很多的特征,我只在这里画出了其中两个特征。假如对我们来说,这两个特征实际上是 一个x1是某物体的厘米长度,另一个特征x2同一物体的英寸长度,这实际上是一种高度冗余的表示。
还有一个例子,看起来不是那么牵强。这几年来我一直在和直升机飞行员一同工作,假如你想对这些飞行员做一个测试,你可能会有一个特征x1(飞行员的技能 pilot skill)、x2(飞行员享受飞行的程度 pilot enjoyment),那么这两个特征可能是高度相关的。不过你真正关心的可能是这个方向上的一个不同的,用来真正测量飞行员能力的特征(pilot aptitude),如果特征高度相关,那么你可能真的需要降低维度。
不过如果你有成百上千个特征,你很容易就会迷失
4.2.3 降维的直观理解
2维降到1维(左图):我想再多说几句,如果我们将数据从二维降低到一维,究竟意味着什么?现在我把不同的样本,用不同的颜色标出来。在这时,通过降维,我的意思是我想找出这条线(这条大多数样本所在的线),所有的数据都投影到了我刚画的线上,通过这种做法我能够测量出每个样本在线上的位置。现在我能做的就是建立新特征 z1,只需要一个数就能确定z1所在的位置,也就是说z1是一个新特征,它能够指定绿线上每一个点的位置。意思就是,之前我在这里的样本是 x^(1),为了表示这个x^(1),我需要一个二维的向量来表示 即 x^(1)∈ ℝ^2,现在我可以用 z^(1)来表示它,来表示我的第一个样本 即 z^(1)∈ ℝ;第二个样本 x^(2)∈ ℝ^2,则如果我计算黑色的X( x^(2))在线上的投影的话,我只需要一个实数就行 即 z^(2)∈ ℝ。以此类推,直到x^(m0—->z^(m);
3维降到2维(右图):假设我们有如图所示的数据集,我有一系列的样本,它们是三维空间中的点 即 x^(i)∈ ℝ^3。大概看出来,这些数据大概都分布在一个平面内(或周围),所以现在我们的降维方法就是把所有数据都投影到一个二维平面上,强迫使得所有的数据都在同一个平面上,降至二维的特征向量。最后,为了指定这些点在平面中的位置,我们需要2个数字 绿色的两个轴 称为z1、z2,来指定这个平面中点的位置。


4.2.4 PCA主成分分析-降维方法
- PCA做的就是它会找一个低维平面(这个例子是条橙色直线),然后将数据投影在上面,使这些蓝色小线段长度平方(投影误差)最小
- 为了对比,这是画的另一条直线(洋红),这时候的投影误差(蓝色的线段)会非常大,因此这些点就不得不移动很长的距离才能投影到这条洋红色的直线上,是个糟糕的选择
投影误差:样本到低维平面的距离(想象3->2,2->1);
最优化:接着要,尝试着找一个低维子空间,对数据进行投影,为了最小化平方投影,最小化投影误差的平方和。

4.3 异常检测
4.3.1 异常检测问题及应用
我将向大家介绍异常检测(Anomaly detection)问题。这是机器学习算法的一个常见应用。这种算法的一个有趣之处在于:它虽然主要用于非监督学习问题,但从某些角度看,它又类似于一些监督学习问题。
什么是异常检测呢?为了解释这个概念,让我举一个例子吧:
假想你是一个飞机引擎制造商,当你生产的飞机引擎从生产线上流出时,你需要进行QA(质量控制测试),而作为这个测试的一部分,你测量了飞机引擎的一些特征变量,比如引擎运转时产生的热量x1,或者引擎的振动x2等等。
这样一来,你就有了一个数据集,从x^(1)到x^(m),如果你生产了m个引擎的话,你将这些数据绘制成图表,看起来就是这个样子:

这里的每个点、每个叉,都是你的无标签数据。
这样,异常检测问题可以定义如下:我们假设后来有一天,你有一个新的飞机引擎从生产线上流出,而你的新飞机引擎有特征变量x_test。所谓的异常检测问题就是:我们希望知道这个新的飞机引擎是否有某种异常,或者说,我们希望判断这个引擎是否需要进一步测试。因为,如果它看起来像一个正常的引擎,那么我们可以直接将它运送到客户那里,而不需要进一步的测试。
【正式地定义异常检测问题】:
给定数据集x^(1), x^(2),…,x^(m) ,我们假定数据集是正常的,我们需要一个算法告诉我们新的数据 x_test 是不是异常的。
【异常检测方法】
我们采取的办法是,给定训练集(无标签的,正常的样本),我们将对数据建模即p(x),也就是说我们对x的分布概率建模(如下是特征x1、x2的联合分布)。因此在我们看到一个新的引擎x_test,在我们根据训练数据得到的p(x)模型中这个点出现的概率非常低时(p(x_test) < 𝜀(某一阈值),就说它是异常的;反过来 如果 p(x_test) >= 𝜀,我们认为它是正常的。

【异常检测算法有下面这些应用案例】
- 最常见的应用是 欺诈检测,
- 你看到某个用户在网站上行为的特征变量是这样的,也许x1是用户登录的频率,x2是用户访问某个页面的次数(或是交易的次数),x3是用户在论坛上发帖的次数,x4是用户的打字速度,因此你可以根据这些建立一个模型p(x)。
- 最后你将得到你的模型p(x),然后你可以用它来发现你网站上的行为奇怪的用户:你只需要看哪些用户的p(x) < 𝜀;
- 第2个应用是 工业生产领域,类似于我们前面已经提到过的异常飞机引擎的问题
- 数据中心的计算机监控:当前这种技术,实际上被各大数据中心用来监测大量计算机可能发生的异常
4.3.1 应用高斯分布开发异常检测算法
高斯分布也称为正态分布,下一视频中 我们将应用高斯分布来推导异常检测算法。
(左图)假设x是一个实数的随机变量,如果x的概率分布服从高斯分布,均值为𝜇,方差为𝛔^2;记为x ~ N(𝜇, 𝛔^2) (N其实就是normal distribution的简称, 𝜇决定了高斯密度函数的中心位置,𝛔标准差决定了高斯密度函数的宽度),概率密度函数类似于钟形的曲线,x靠近𝜇的概率密度函数很大,x取远处的值时,概率将逐渐降低直至消失。
(右图)参数估计问题就是,假设我猜测这些样本(共有m个样本 { x^(1), x^(2),…, x^(m) },假设它们都是实数(如下图中的横轴)) 来自一个高斯分布的总体(假设每一个样本服从正态分布,即 x^(i)~N(𝜇, 𝛔^2) ),但是我不知道这些参数的值是多少,参数估计问题就是:给定数据集,我希望能够估算出𝜇, 𝛔^2。


【异常检测算法为】
假定我们有m个样本的无标签训练集,训练集的每个样本都是一个ℝ^n维的特征向量,即 x^(i) ∈ ℝ^n。
要用数据集建立起概率模型p(x),我们试图解出哪些特征向量出现的概率比较高,哪些特征向量出现的概率比较低。因此,x就是一个向量,然后我们就要建立模型p(x) = p(x1 )p(x2 )…p(xn ) —— 理论上,这个公式需要x1、x2、… xn独立的假设,实际上无论它们是否近乎独立 并且即使这个独立假设不成立,这个算法也能正常运行
那我们如何对这些项建模呢, p(x1 )、 p(x2 )等,我们假定特征x1是分散的,它服从高斯分布,即 x1~N(𝜇1, 𝛔_1^2) ),那 p(x1 ) 就可以写成 p(x1; 𝜇1, 𝛔_1^2 );同样假设x2、…xn。
那么,p(x) = p(x1; 𝜇1, 𝛔_1^2)p(x2; 𝜇2, 𝛔_2^2)…p(x_n; 𝜇_n, 𝛔_n^2) = ∏p(x_j; 𝜇_j, 𝛔_j^2) (j=1…n),然后利用参数估计公式估计出这些参数值;
5 推荐系统
5.1 讲推荐系统原因:重要应用+自动学习特征
我想讲推荐系统有两个原因:
第一、仅仅因为它是机器学习中的一个重要的应用。这些推荐系统,根据浏览你过去买过什么书,或过去评价过什么电影来判断。这些系统会带来很大一部分收入。
第二个原因是:对机器学习来说,特征是很重要的,你所选择的特征,将对你学习算法的性能有很大的影响。因此,在机器学习中有一种大思想,它针对一些问题,可能并不是所有的问题,而是一些问题,有些算法可以为你自动学习一系列合适的特征。因此,对比试图手动设计特征,这是目前为止我们常干的。有一些设置,你可以有一个算法,仅仅学习其使用的特征,推荐系统就是类型设置的一个例子。还有很多其它的,但是通过推荐系统,我们将领略一小部分特征学习的思想(learning the features)
5.2 推荐系统问题定义
接下来的例子中,我将讲一个预测电影评分的问题。下面是题干。
假设你有一个网站或者公司,出售或者出租电影和其他东西的像亚马逊、netflix、iTunes等。假设你让你的用户评价不同的电影,用1到5星评级,为了让这个例子更好理解一些我将允许评级为0到5星,因为这会使数学运算更加简单。如下表格有5部电影(前3部为爱情片,后2部为动作片),并且有4个用户,评分如下表,问号?代表没看过未评分。几个重要符号:
- n_u:no. users,此处n_u=4
- n_m:no. movies,此处n_m=5
- r(i,j) = 1,代表用户j给了电影i进行了评价(问号?的就是未评价的)
- y^(i, j):用户j对电影i的具体评分,范围0-5 (前提 r(i,j) = 1)
因此,【推荐系统的问题是】:给定r(i,j)、y^(i, j)的数据,然后去查找那些没有评分的电影(问号处),并试图预测这些电影的评价星级。
在这个例子中,问号?是少量,因此大多数用户都对大多数电影进行了评价;但在现实情况中,每个用户可能仅评价所有电影中的一小部分。
观察这些数据,如果Alice和Bob都喜欢爱情片,就可以假设Alice会给这部电影评价5星(第一列问号),Bob会给这个评价4.5星或更高(第二列问号);并且我们认为Carol和Dave可能给爱情片非常低的评价,如果Dave真的喜欢动作片那么他可能会给Swords vs. karate评价4星火5星。
因此,如果我想开发一个推荐系统,我们的工作是想出一个学习算法,一个能自动为我们填补这些缺失值的算法,这样我们就可以看下该用户还有哪些电影没看过并推荐新电影给该用户。你可以去预测什么是用户会感兴趣的内容

5.3 算法
5.3.1:算法1:基于内容的推荐方法
还用之前的例子,我们怎么预测出这些未知量的值呢?假设对每一部电影,我都有一个对应的特征集(已知),特别地我们假设对每一个电影都有两个特征 x1(电影为爱情片的程度)、x2(电影为动作片的程度),如第二行 有少量动作成分(0.01);如果我们有类似这样的特征,那么每部电影就可以用一个特征向量来表示,比如说第1部电影两个特征值为0.9、0,像往常一样我加一个截距x0=1,那么第一部电影的特征向量 x^(1) = [1 0.9 0]^T,特征数量n=2
现在为了做出预测,我们可以这么做,我们可以把每个用户的评价预测值看做是一个线性回归问题。特别规定,已知每一部电影i的特征向量x^(i),对于每一个用户j,我们要学习参数向量𝚹^(j) ∈ ℝ^3(通常来说,𝚹^(j) ∈ ℝ^(n+1)),然后我们要预测用户j评价电影i的值,也就是参数向量 𝚹^(j)与特征向量x^(i)的内积。
举一个特殊的例子,比如说用户1(即Alice),是某个参数向量𝚹^(1);假如我们想预测Alice对第3部电影的评价,那么那部电影就会有某个特征向量x^(3),我们令x^(3)=[1 0.99 0]^T,在这个例子中我们 𝚹^(1) = [0 5 0]^T,我们是怎么得到这个参数向量的,后面再介绍,我们先假设我们用某个学习算法学习了参数向量𝚹^(1),所以我们对于这一项的预测为 (𝚹^(1))^T x^(3) = 5*0.99 = 4.95。

5.3.2 算法2:协同过滤(思想,非真正的算法)
我们先换一个问题,假如我们有一个数据集,但我们不知道这些电影特征的值是多少,比如我们得到一些关于电影的数据,不同用户对电影的评分,也不知道每部电影的爱情指数 以及 动作指数,所以我把这些东西都换成问号(?)。现在我们稍微改变一下这个假设,假设我们采访了每一位用户,而且每一位用户都告诉我们他们喜欢爱情电影 以及 动作电影的程度,这样Alice就有了对应的参数𝚹^(1),其它人依次为𝚹^(2)、、𝚹^(4),并且假如说Alice告诉我们,她十分喜欢爱情电影(即特征值x1对应的值为5),十分讨厌动作电影(则第3个分量为0),理论上可以听取每个用户的意见,他们告诉我他们各自的𝚹^(j)是什么,这就向我们指明了他们对不同题材电影的喜欢程度。 𝚹^(1) = [ 0 5 0] 喜欢爱情电影,讨厌动作电影
如果我们能从用户那里得到这些参数𝚹^(j)的值,那么理论上我们就能推测出每部电影的x1以及x2的值(学习出特征)
举例来说,假如我们观察电影1(样本x^(1)),这部电影的名字叫什么不重要(所以我们可以假装不知道它的名字),
- 我们只知道(评分)——Alice喜欢这部电影、Bob喜欢这部电影、Carol、Dave不喜欢它,那么我们能推断出什么呢?
- 我们能从用户特征向量(or用户参数向量更准确)𝚹^(j)中知道(如下左图),Alice和Bob喜欢爱情电影,Carol、Dave不喜欢爱情电影,但喜欢动作电影; 同时,由于我们知道Alice和Bob喜欢电影1,而Carol、Dave不喜欢,由此我们可以推断 电影1(样本x^(1))可能是部爱情片,而不太可能是动作片(第一行最右两列:即 x^(1) 的第一个分量为1、第二个分量为0)。
这个例子在数学上可能某种程度上简化了,但我们真正需要的是 特征向量x^(1)应该是什么,才能让 (𝚹^(1))^T x^(1) ≈ 5(5是Alice对电影1的评分)、(𝚹^(2))^T x^(1) ≈ 5(5是Bob对电影1的评分)、(𝚹^(3))^T x^(1) ≈ 0(0是Carol对电影1的评分)、(𝚹^(4))^T x^(1) ≈ 0(0是Dave对电影1的评分);因此可知, x^(1) = [1 1.0 0.0]^T,这样才能得出四个人对第一部电影的评分;一般来说,我们可以继续进行列举,并试着弄明白第二、三、部电影有什么合适的特征
所以,总结一下。这一阶段要做的就是选择特征x^(i),让所有已经评价过电影i的用户j会预测出一个值,这个预测值要尽量接近用户实际的评分;和之前一样,也要加上一个正则化项,来防止特征变得太大。这就是我们如何从一部特定的电影中,学习到特征的方法,但我们要做的是学习出所有电影的特征 ,所以前面还要加上一个求和项。如果你将它最小化,就就能得到系列合适的所有电影的特征。


所以,总结一下(最优化的目标)。这一阶段要做的就是选择特征x^(i),让所有已经评价过电影i的用户j会预测出一个值(预测的用户评分),这个预测值要尽量接近用户实际的评分;和之前一样,也要加上一个正则化项,来防止特征变得太大。这就是我们如何从一部特定的电影中,学习到特征的方法,但我们要做的是学习出所有电影的特征 ,所以前面还要加上一个求和项。如果你将它最小化,就就能得到系列合适的所有电影的特征。

5.3.2.1 基本的协同过滤算法
【协同过滤算法 思想,不是真正的算法】𝚹—>x—>𝚹—>x…
- 你能做的就是随机猜取一些𝚹值(用户特征参数,对电影的喜爱),在有了这些随机初始化的𝚹值以后,你就能继续下去,用我们刚刚讲到的方法来学习出x(即不同电影的特征);
- 然后在有些初始化的特征后,你就能运用上述第一种方法来得到一个更好的𝚹,
- 不断迭代——通过这个更好的𝚹,又可以得到更好的x,以此类推,不断迭代得到更好的𝚹和x,并且效果确实很好,如果你不断迭代这个过程,那么你的算法将会收敛到一组合理的电影特征 以及 一组合理的对不同用户的参数的估计,这就是基本的协同过滤算法。
5.3.2.2 协同的意思
- 协同过滤算法指的是,当你执行算法时,要观察大量的用户,观察这些用户的实际行为,来协同得到更佳的每个人对电影的评分值,因为如果每个用户都对一部分电影作出了评价,那么每个用户都在帮助算法学习出更合适的特征。也就是说,通过自己对几部电影进行评分,我就能帮助这个系统更好地学习特征(电影的特征),然后这些学习出的特征又可以被用来更好地预测其它用户的评分;
- 协同的另一层意思是说每位用户都在帮助算法更好地进行特征学习,这就是协同过滤。
5.3.3 算法1、2:总结
总结一下,把之前视频讨论的算法,以及我们刚刚讲的算法都总结一下,以及我们刚刚讲的算法都总结一下。
- 基于内容(电影特征x)的推荐方法:上一个视频中,我们讲的是,如果你有所有电影评分的集合即 r(i, j)和y^(i,j),于是根据不同电影的特征x^(i),可以学习不同用户的参数𝚹^(j);
- x^(1) = [0.9 0], x^(2) = [1.0 0.01]
- 协同过滤推荐:该视频讲的是:如果你有所有电影评分的集合即 r(i, j)和y^(i,j),如果你的用户愿意为你提供这些参数𝚹^(j),你就能估计各种电影的特征值x^(i)
- 用户j喜欢 爱情电影,根本不喜欢动作电影,那 𝚹^(j) = [ 0 5 0]^T (第一个分量为对应x的截距)
但是这有点像鸡和蛋的问题,先有鸡还是先有蛋?如果已知𝚹,能学习出x;如果已知x,也能学习出𝚹;
5.3.4 协同过滤的高效计算
随机初始化𝚹,那么你可以做的事是不停地重复这些计算𝚹—>x—>𝚹—>x…,然后解出最优的x和𝚹;但实际上,存在一个更有效率的算法,让我们不再需要这样不停地计算x和𝚹,而是能够将x和𝚹同时计算出来,下面就是这种算法。
我们要做是将这两个优化目标函数,结合为一个:所以我要定义这个新的优化目标函数J(代价函数),J(x^(1), …, x^(n_m), 𝚹^(1),…,𝚹^(n_u)),视为电影特征x和用户参数𝚹的函数;它是一个代价函数,是关于特征x和参数𝚹的函数,它其实就是上面两个目标优化函数,但我将他们结合在一起 (左图)。
把所有讲的这些结合起来就是我们的【高效的--协同过滤算法】(右图):
- 把 x 和 𝚹初始化为小的随机值(这有点像神经网络训练,也是把所有参数用小的随机数来初始化)
- 接下来我们要用梯度下降 或者 其它高级优化算法,把这个代价函数最小化;如果你求导的话,发现写出来的更新式是这样的
- 没有x0和𝚹_0,在J(x,,,𝚹,,,)里面我们将所有x和𝚹正则化(且不存在x0和𝚹_0),这是为什么更新式子没有分出k=0的特殊情况
- 最后,给你一个用户,这个用户具有一些参数𝚹,以及 给你一部电影 带有已知的特征x,我们可以预测该用户给这部电影的评分 𝚹^(T)x (实际是 用户j对电影i的评分,即(𝚹^(j))^(T)(x^(i))


5. 强化学习
6. 大模型
https://blog.csdn.net/qq_37756660/article/details/135949450
https://blog.csdn.net/qq_37756660/category_12570409.html
6.1 模块结构
第一个模块:基础知识篇。这里,我会带你探究大型语言模型的基本能力。通过提示语(Prompt)和嵌入式表示(Embedding)这两个核心功能,看看大模型能帮我们解决哪些常见的任务。通过这一部分,你会熟悉OpenAI的API,以及常见的分类、聚类、文本摘要、聊天机器人等功能,能够怎么实现。
第二个模块:提高篇。我们会开始进入真实的应用场景。要让AI有用,不是它能简单和我们闲聊几句就可以的。我们希望能够把自己系统里面的信息,和AI系统结合到一起去,以解决和优化实际的业务问题。比如优化传统的搜索、推荐;或者进一步让AI辅助我们读书读文章;乃至于让AI自动根据我们的代码撰写单元测试;最后,我们还能够让AI去决策应用调用什么样的外部系统,来帮助客户解决问题。
第三个模块:重点关注语音与视觉。光有文本对话的能力是不够的,我会进一步让你体验语音识别、语音合成,以及唇形能够配合语音内容的数字人。我还会教会你如何利用现在最流行的Stable Diffusion这样的开源模型,去生成你所需要的图片。并在最后,把聊天和画图结合到一起去,为你提供一个“美工助理”。
大型语言模型的接口其实非常简单。像OpenAI就只提供了Complete和Embedding两个接口,其中,
- Complete可以让模型根据你的输入进行自动续写(补全);
- Embedding可以将你输入的文本 转化成向量。
- 其它接口:如 moderate 的接口返回的是一个 JSON,里面包含是否应该对输入的内容进行标记的 flag 字段,也包括具体是什么类型的问题的 categories 字段,以及对应每个 categories 的分数的 category_scores 字段。https://openai.xiniushu.com/docs/guides/moderation
6.2 入门认知: Completion 接口
6.2.1 Completion应用1
这段代码里面,我们调用了 OpenAI 的 Completion 接口,然后向它提了一个需求,也就是为一个我在 1688 上找到的中文商品名称做三件事情。
1. 为这个商品写一个适合在亚马逊上使用的英文标题。
2. 给这个商品写 5 个卖点。
3. 估计一下,这个商品在美国卖多少钱比较合适。
同时,我们告诉 OpenAI,我们希望返回的结果是 JSON 格式的,并且上面的三个事情用 title、selling_points 和 price_range 三个字段返回。
1 from openai import OpenAI 2 import os 3 4 client = OpenAI( 5 api_key=os.environ['OPENAI_API_KEY'], 6 ) 7 COMPLETION_MODEL = "text-davinci-003" 8 9 prompt = """ // 提示语 10 Consideration proudct : 工厂现货PVC充气青蛙夜市地摊热卖充气玩具发光蛙儿童水上玩具 11 1. Compose human readale product title used on Amazon in english within 20 words. 12 2. Write 5 selling points for the products in Amazon. 13 3. Evaluate a price range for this product in U.S. 14 Output the result in json format with three properties called title, selling_points and price_range 15 """ 16 17 def get_response(prompt): 18 completions = client.completions.create ( 19 model=COMPLETION_MODEL, // 参数1:第一个参数是 engine,也就是我们使用的是 Open AI 的哪一个引擎,这里我们使用的是 text-davinci-003,也就是现在可以使用到的最擅长根据你的指令输出内容的模型。当然,也是调用成本最高的模型。 20 prompt=prompt, // 参数2:我们输入的提示语 21 max_tokens=512, // 参数3:也就是调用生成的内容允许的最大 token 数量。你可以简单地把 token 理解成一个单词。实际上,token 是分词之后的一个字符序列里的一个单元。有时候,一个单词会被分解成两个 token。比如,icecream 是一个单词,但是实际在大语言模型里,会被拆分成 ice 和 cream 两个 token。这样分解可以帮助模型更好地捕捉到单词的含义和语法结构。一般来说,750 个英语单词就需要 1000 个 token。我们这里用的 text-davinci-003 模型,允许最多有 4096 个 token。需要注意,这个数量既包括你输入的提示语,也包括 AI 产出的回答,两个加起来不能超过 4096 个 token。比如,你的输入有 1000 个 token,那么你这里设置的 max_tokens 就不能超过 3096。不然调用就会报错。
22 n=1, // 参数4:代表你希望 AI 给你生成几条内容供你选择 23 stop=None, // 参数5:代表你希望模型输出的内容在遇到什么内容的时候就停下来。这个参数我们常常会选用 "\n\n"这样的连续换行,因为这通常意味着文章已经要另起一个新的段落了,既会消耗大量的 token 数量,又可能没有必要 24 temperature=0.0, 25 ) 26 message = completions.choices[0].text 27 return message 28 29 print(get_response(prompt))
返回结果:
{
"title": "Glow-in-the-Dark Inflatable PVC Frog Night Market Hot Selling Water Toy for Kids",
"selling_points": [
"Made of durable PVC material",
"Glow-in-the-dark design for night play",
"Inflatable design for easy storage and transport",
"Perfect for water play and outdoor activities",
"Great gift for kids"
],
"price_range": "$10 - $20"
}
神奇的是,OpenAI 真的理解了我们的需求,返回了一个符合我们要求的 JSON 字符串给我们。在这个过程中,它完成了好几件不同的事情。
第一个是翻译,我们给的商品名称是中文的,返回的内容是英文的。
第二个是理解你的语义去生成文本,我们这里希望它写一个在亚马逊电商平台上适合人读的标题,所以在返回的英文结果里面,AI 没有保留原文里有的“工厂现货”的含义,因为那个明显不适合在亚马逊这样的平台上作为标题。下面 5 条描述也没有包含“工厂现货”这样的信息。而且,其中的第三条卖点 “Inflatable design for easy storage and transport”,也就是作为一个充气的产品易于存放和运输,这一点其实是从“充气”这个信息 AI 推理出来的,原来的中文标题里并没有这样的信息。
第三个是利用 AI 自己有的知识给商品定价,这里它为这个商品定的价格是在 10~20 美元之间。而我用 “Glow-in-the-Dark frog” 在亚马逊里搜索,搜索结果的第一行里,就有一个 16 美元发光的青蛙。
最后是根据我们的要求把我们想要的结果,通过一个 JSON 结构化地返回给我们。而且,尽管我们没有提出要求,但是 AI 还是很贴心地把 5 个卖点放在了一个数组里,方便你后续只选取其中的几个来用。返回的结果是 JSON,这样方便了我们进一步利用返回结果。比如,我们就可以把这个结果解析之后存储到数据库里,然后展现给商品运营人员。
6.2.2 Completion应用2
在第 03 讲里,已经看了如何通过 Completion 的接口,实现一个聊天机器人的功能。在那个时候,我们采用的是自己将整个对话拼接起来,将整个上下文都发送给 OpenAI 的 Completion API 的方式。不过,在 3 月 2 日,因为 ChatGPT 的火热,OpenAI 放出了一个直接可以进行对话聊天的接口。这个接口叫做 ChatCompletion,对应的模型叫做 gpt-3.5-turbo,不但用起来更容易了,速度还快,而且价格也是我们之前使用的 text-davinci-003 的十分之一,可谓是物美价廉了。
原文链接:https://blog.csdn.net/qq_37756660/article/details/135955682
6.3 Embedding的应用
6.3.1 Embedding应用例子1
通过大语言模型来进行情感分析,最简单的方式就是利用它提供的 Embedding 这个 API。这个 API 可以把任何你指定的一段文本,变成一个大语言模型下的向量,也就是用一组固定长度的参数来代表任何一段文本。
我们需要提前计算“好评”和“差评”这两个字的 Embedding。而对于任何一段文本评论,我们也都可以通过 API 拿到它的 Embedding。那么,我们把这段文本的 Embedding 和“好评”以及“差评”通过余弦距离(Cosine Similarity)计算出它的相似度。然后我们拿这个 Embedding 和“好评”之间的相似度,去减去和“差评”之间的相似度,就会得到一个分数。如果这个分数大于 0,那么说明我们的评论和“好评”的距离更近,我们就可以判断它为好评。如果这个分数小于 0,那么就是离差评更近,我们就可以判断它为差评。
—— 余弦相似度:就是计算两个向量间的夹角的余弦值。
——余弦距离:就是用1减去这个获得的余弦相似度(= 1- 余弦相似度)。
下面我们就用这个方法分析一下两条在京东上购买了 iPhone 用户的评论。
1 from openai import OpenAI 2 import numpy as np 3 import os 4 5 client = OpenAI(api_key=os.environ['OPENAI_API_KEY']) 6 7 EMBEDDING_MODEL = "text-embedding-ada-002" 8 9 def get_embedding(text, model=EMBEDDING_MODEL): 10 text = text.replace("\n", " ") 11 return client.embeddings.create(input = [text], model=model).data[0].embedding 12 13 def cosine_similarity(vector_a, vector_b): 14 dot_product = np.dot(vector_a, vector_b) 15 norm_a = np.linalg.norm(vector_a) 16 norm_b = np.linalg.norm(vector_b) 17 epsilon = 1e-10 18 cosine_similarity = dot_product / (norm_a * norm_b + epsilon) 19 return cosine_similarity 20 21 positive_review = get_embedding("好评") 22 negative_review = get_embedding("差评") 23 24 positive_example = get_embedding("买的银色版真的很好看,一天就到了,晚上就开始拿起来完系统很丝滑流畅,做工扎实,手感细腻,很精致哦苹果一如既往的好品质") 25 negative_example = get_embedding("随意降价,不予价保,服务态度差") 26 27 def get_score(sample_embedding): 28 return cosine_similarity(sample_embedding, positive_review) - cosine_similarity(sample_embedding, negative_review) 29 30 positive_score = get_score(positive_example) 31 negative_score = get_score(negative_example) 32
// 正如我们所料,京东上的好评通过 Embedding 相似度计算得到的分数是大于 0 的,京东上面的差评,这个分数是小于 0 的。 33 print("好评例子的评分 : %f" % (positive_score)) // 好评例子的评分 : 0.070963 34 print("差评例子的评分 : %f" % (negative_score)) // 差评例子的评分 : -0.081472
这一讲,我们利用不同文本在大语言模型里 Embedding 之间的距离,来进行情感分析(分类)。这种使用大语言模型的技巧,一般被称做零样本分类(Zero-Shot Classification)。
所谓零样本分类,也就是我们不需要任何新的样本来训练机器学习的模型,就能进行分类。我们认为,之前经过预训练的大语言模型里面,已经蕴含了情感分析的知识。我们只需要简单利用大语言模型里面知道的“好评”和“差评”的概念信息,就能判断出它从未见过的评论到底是好评还是差评。
这个方法,在一些经典的数据集上,轻易就达到了 95% 以上的准确度。同时,也让一些原本需要机器学习研发经验才能完成的任务变得更加容易,从而大大降低了门槛。
如果你所在的公司今天想要做一个文本分类的应用,通过 OpenAI 的 API 用几分钟时间就能得到想要的结果。
传统方法的挑战:特征工程与模型调参
但这些传统的机器学习算法,想要取得好的效果,还是颇有门槛的。除了要知道有哪些算法可以用,还有两方面的工作非常依赖经验。
第一个是特征工程。对于很多自然语言问题,如果我们只是拿一段话里面是否出现了特定的词语来计算概率,不一定是最合适的。比如“这家餐馆太糟糕了,一点都不好吃”和 “这家餐馆太好吃了,一点都不糟糕”这样两句话,从意思上是完全相反的。但是里面出现的词语其实是相同的。在传统的自然语言处理中,我们会通过一些特征工程的方法来解决这个问题。
比如,我们不只是采用单个词语出现的概率,还增加前后两个或者三个相连词语的组合,也就是通过所谓的 2-Gram(Bigram 双字节词组)和 3-Gram(Trigram 三字节词组)也来计算概率。在上面这个例子里,第一句差评,就会有“太”和“糟糕”组合在一起的“太糟糕”,以及“不”和“好吃”组合在一起的“不好吃”。而后面一句里就有“太好吃”和“不糟糕”两个组合。有了这样的 2-Gram 的组合,我们判断用户好评差评的判断能力就比光用单个词语是否出现要好多了。
这样的特征工程的方式有很多,比如去除停用词,也就是“的地得”这样的词语,去掉过于低频的词语,比如一些偶尔出现的专有名词。或者对于有些词语特征采用 TF-IDF(词频 - 逆文档频率)这样的统计特征,还有在英语里面对不同时态的单词统一换成现在时。
第二个就是你需要有相对丰富的机器学习经验。除了通过特征工程设计更多的特征之外,我们还需要了解很多机器学习领域里常用的知识和技巧。比如,我们需要将数据集切分成训练(Training)、验证(Validation)、测试(Test)三组数据,然后通过 AUC 或者混淆矩阵(Confusion Matrix)来衡量效果。如果数据量不够多,为了训练效果的稳定性,可能需要采用 K-Fold 的方式来进行训练。
如果没有接触过机器学习,看到这里,可能已经看懵了。没关系,上面的大部分知识你未来可能都不需要了解了,因为我们有了大语言模型,可以通过它提供的 Completion 和 Embedding 这两个 API,用不到 10 行代码就能完成情感分析,并且能获得非常好的效果。
6.3.1.1 Embedding 不就是把文本变成向量吗,为什么OpenAI能这么准确呢?
https://blog.csdn.net/qq_37756660/article/details/135953636
前面两讲,体验了 OpenAI 通过 API 提供的 GPT-3.5 系列模型的两个核心接口。一个是获取一段文本的 Embedding 向量,另一个则是根据提示语,直接生成一段补全的文本内容。我们用这两种方法,都可以实现零样本(zero-shot)或者少样本下的情感分析任务。不过,你可能会提出这样两个疑问。
1. Embedding 不就是把文本变成向量吗?我也学过一些自然语言处理,直接用个开源模型,比如 Word2Vec、Bert 之类的就好了呀,何必要去调用 OpenAI 的 API 呢?
给出一段文本,OpenAI 就能返回给你一个 Embedding 向量,这是因为它的背后是 GPT-3 这个超大规模的预训练模型(Pre-trained Model)。事实上,GPT 的英文全称翻译过来就是“生成式预训练 Transformer(Generative Pre-trained Transformer)”。
- 生成式:这意味着模型能够根据已学习到的语言规律和模式创造新的、之前未见过的文本序列。不同于分类或回归等任务中的判别式模型(Discriminative Models),专注于区分不同类别或预测单一输出,生成式模型侧重于模拟数据的生成过程,能够生成连贯的句子、段落乃至文章,适用于文本创作、对话系统、摘要生成等多种应用场景。
- 预训练(Pre-training):这是指模型首先在一个大规模的无标注文本语料库上进行训练,学习语言的一般知识和结构,而不针对特定任务。这一阶段的目的是让模型捕捉语言的统计规律和上下文依赖关系,获得对语言的深入理解。所谓预训练模型,就是虽然我们没有看过你想要解决的问题,比如这里我们在情感分析里看到的用户评论和评分。但是,我可以拿很多我能找到的文本,比如网页文章、维基百科里的文章,各种书籍的电子版等等,作为理解文本内容的一个学习资料。
- Transformer:这是一种先进的神经网络架构,最初由“Attention Is All You Need”论文提出,它摒弃了传统的循环网络结构,完全依赖于自注意力(Self-Attention)机制来处理输入序列,使得模型能够并行处理信息,大大提高了训练速度和处理长序列的能力。
我们不需要对这些数据进行人工标注(用Transfomer模型),只根据这些文本前后的内容,来习得文本之间内在的关联。比如,网上的资料里,会有很多“小猫很可爱”、“小狗很可爱”这样的文本。小猫和小狗后面都会跟着“很可爱”,那么我们就会知道小猫和小狗应该是相似的词,都是宠物。同时,一般我们对于它们的情感也是正面的。这些隐含的内在信息,在我们做情感分析的时候,就带来了少量用户评论和评分数据里缺少的“常识”,这些“常识”也有助于我们更好地预测。
比如,文本里有“白日依山尽”,那么模型就知道后面应该跟“黄河入海流”。文本前面是“今天天气真”,后面跟着的大概率是“不错”,小概率是“糟糕”。这些文本关系,最后以一堆参数的形式体现出来。对于你输入的文本,它可以根据这些参数计算出一个向量,然后根据这个向量,来推算这个文本后面的内容。
可以这样来理解:用来训练的语料文本越丰富,模型中可以放的参数越多,那模型 能够学到的关系也就越多。类似的情况在文本里出现得越多,那么将来模型猜得也就越准。
——这里的参数:比如“1.76万亿参数”指的是GPT-4模型自身的规模,即该人工智能模型内部的权重和偏置等参数的数量(神经网络的参数数量)。这些参数是模型学习过程中形成的数据结构,决定了模型如何处理输入并生成相应的输出。
——而OpenAI Completion API接口的参数,如前所述,包括model、prompt、max_tokens等,是用来指定如何使用模型(比如GPT系列模型)进行文本生成的具体设置和选项。
预训练模型在自然语言处理领域并不是 OpenAI 的专利。早在 2013 年,就有一篇叫做 Word2Vec 的经典论文谈到过。它能够通过预训练,根据同一个句子里一个单词前后出现的单词,来得到每个单词的向量。而在 2018 年,Google 关于 BERT 的论文发表之后,整个业界也都会使用 BERT 这样的预训练模型,把一段文本变成向量用来解决自己的自然语言处理任务。在 GPT-3 论文发表之前,大家普遍的结论是,BERT 作为预训练的模型效果也是优于 GPT 的(参数多后--即模型变大,大模型,效果好)。
6.3.1.2 编码器-解码器模型(Encoder-Decoder)
https://blog.csdn.net/qq_39297053/article/details/136544028
Encoder-Decoder算法是一种深度学习模型结构,广泛应用于自然语言处理(NLP)、图像处理、语音识别等领域。它主要由两部分组成:编码器(Encoder)和解码器(Decoder)。如图1所示,这种结构能够处理序列到序列(Seq2Seq)的任务,如机器翻译、文本摘要、对话系统、声音转化等。

图1 编码器-解码器结构
框架是一种广泛应用于序列到序列(Seq2Seq)任务的模型结构,比如机器翻译、文本摘要、对话系统等。下面我将简单解释编码器和解码器的角色,并通过一个例子帮助您更好地理解。
编码器(Encoder)
角色:编码器负责理解并压缩输入的文本信息。它读取一段可变长度的文本序列(如一句话或一段话),然后将其转换为一个固定长度的向量,这个向量被称为上下文向量或者编码向量。这个过程就像是将文本的含义浓缩到一个高维空间中的一个点,其中包含了输入文本的语义信息。
举例:假设我们有一个简单的句子“我喜欢吃冰淇淋”。编码器读取这个句子后,通过词嵌入将每个词转化为向量,然后通过循环神经网络(RNN)、长短时记忆网络(LSTM)或Transformer层等技术,逐步融合每个词的信息,最终产生一个总结整个句子意义的向量。
解码器(Decoder)
角色:解码器的任务是基于编码器产生的向量,生成新的输出序列。它从编码器得到的向量开始,逐步生成目标语言或目标格式的文本。解码器不仅要生成合理的序列,还要保持序列间的连贯性和语法正确性。
举例:继续上面的例子,如果我们的任务是将中文翻译成英文,编码器处理了“我喜欢吃冰淇淋”后,解码器将从这个上下文向量开始,一步一步地预测并生成英文翻译的序列,比如"我喜欢吃冰淇淋"可能被翻译为"Ice cream is my favorite."。解码器首先生成"I",然后基于"I"和编码向量预测下一个词是"ce",接着是"cream",一步步直到生成完整的句子,并可能在句末加上结束标记"[EOS]"。
训练过程
在训练Encoder-Decoder模型时,目标是最小化模型预测的输出序列与实际输出序列之间的差异。这通常通过计算损失函数(如交叉熵损失)来实现,并使用反向传播和梯度下降等优化算法进行参数更新。
总结
在机器翻译任务中,编码器把源语言文本(如中文)编码成一个紧凑的向量形式,保留原始文本的主要信息。解码器则根据这个向量解码生成目标语言文本(如英文)。这一框架不仅限于翻译,还广泛应用于任何需要将一种序列转换为另一种序列的任务中。
6.3.1.3 Transformer模型是如何工作的
当然,让我们以一个简化版的例子来说明Transformer模型是如何工作的。想象一下,我们要让一个Transformer模型翻译一句英文 "I love coding" 成中文。
Transformer的基本组件
Transformer模型主要分为两部分:编码器(Encoder) 和 解码器(Decoder),它们通过自注意力(Self-Attention)和位置编码(Positional Encoding)等机制协同工作。
简化步骤说明:
-
输入编码:
- 首先,将英文句子拆分成单词:"I", "love", "coding"。
- 每个单词通过词嵌入(Lookup)转换成一个向量,假设每个向量有5个维度,那么"I"可能对应[0.1, 0.2, 0.3, 0.4, 0.5]这样的向量。
- 添加位置编码,告诉模型单词在句子中的相对位置。
-
编码器工作:
- 自注意力层:模型会计算每个单词向量与其他所有单词向量的关系,以此来决定在编码时如何加权它们。例如,在说"I love coding"时,"love"可能更关注于"I",因为它直接跟随其后。
- 前馈网络层:接着,每个单词向量会经过一个前馈神经网络,进一步提炼信息。
-
解码器工作:
- 解码器同样开始于中文的起始标记,比如"[START]"的词嵌入,并且同样应用位置编码。我的意思是,在进行中文翻译时,解码器的输入会以一个特殊的标记开始,这个标记用来指示翻译序列的起始。尽管我在描述中使用了英文的"[START]"作为示例,但实际上在处理中文翻译任务时,我们会用一个专为中文设定的起始标记,可以是类似"[开始]"或者更通用的"[CLS]"、"[BOS]"(Begin Of Sentence)这样的特殊标记,具体取决于所使用的数据集和预训练模型的约定。
- 自注意力层:解码器不仅关注自己的输入(逐渐构建的中文序列),还会通过“编码器-解码器注意力”关注编码器的输出,理解已翻译内容的上下文。
- 前馈网络层:之后也是通过前馈网络进一步处理信息。
-
逐词生成:
- 解码器逐步生成中文翻译,比如先预测出"我",然后基于"我"和英文句子的信息预测出"喜欢",接着是"编程",最后生成"[END]"标记结束翻译。
注意力机制的关键作用:
在整个过程中,注意力机制让模型能够动态地决定在处理每个单词时应重点关注输入序列的哪些部分,这使得Transformer能够理解和生成长距离依赖的复杂文本,而无需像RNN那样按顺序处理输入。
这个过程虽然简化了很多细节(实际Transformer模型还包括多头注意力、残差连接、LayerNorm等复杂结构),但它基本展示了Transformer如何通过并行处理和注意力机制高效地完成序列到序列的转换任务。
6.3.2 Embedding应用例子2(embedding向量->传统机器学习分类)
上一讲里我们看到大模型的确有效。在进行情感分析的时候,我们通过 OpenAI 的 API 拿到的 Embedding,比 T5-base 这样单机可以运行的小模型,效果还是好很多的。
不过,我们之前选用的问题的确有点太简单了。我们把 5 个不同的分数分成了正面、负面和中性,还去掉了相对难以判断的“中性”评价,这样我们判断的准确率高的确是比较好实现的。但如果我们想要准确地预测出具体的分数呢?
利用 Embedding,训练机器学习模型
最简单的办法就是利用我们
(1)通过大模型拿到的文本 Embedding 的向量。这一次,我们不直接用向量之间的距离,而是使用传统的机器学习的方法来进行分类。毕竟,如果只是用向量之间的距离作为衡量标准,就没办法最大化地利用已经标注好的分数信息了。
(2)利用拿到的 Embedding,简单调用一下 scikit-learn,通过机器学习的方法,进行更准确的分类。我们最终把 Embedding 放到一个简单的逻辑回归模型里,就取得了很不错的分类效果。
——sklearn,全称scikit-learn,是一个开源的基于python语言的机器学习工具包。它通过numpy、scipy、matplotlib、pandas等python库实现高效的算法应用,涵盖了几乎所有主流机器学习算法。
在工程中,用python的基础库来搭建机器学习算法非常低效(但还是推荐在学习阶段使用基础库去搭建机器学习算法,可以进一步深入算法),且还容易出错,而在机器学习中经常大部分时间(70%)是在对数据进行处理,构建合格的数据集,只有少部分时间在构建模型代码,直接调用成熟算法工具包,可以在实现工程应用效率和效果之间找到一个平衡,这也正是sklearn带给我们的优势。
6.3.3 Embedding应用例子3(embedding向量->传统机器学习聚类,大模型对聚类类型取名字)
https://blog.csdn.net/qq_37756660/article/details/135956673
通过 Embedding 拿到的向量进行文本聚类。对于聚类的结果,我们不用再像以前那样人工看成百上千条数据,然后拍个脑袋给这个类取个名字。我们直接利用了 Completion 接口可以帮我们总结内容的能力,给分类取了一个名字
6.3.3.1 多轮对话:AI总结历史对话加入到新对话的提示词
而类似的技巧,也可以用在多轮的长对话中。我们将历史对话,让 AI 总结成一小段文本放到提示语里面。这样既能够让 AI 记住过去的对话内容,又不会因为对话越来越长而超出模型可以支持的 Token 数量。这个技巧也是使用大语言模型的一种常见模式。
6.3.4 Embedding应用例子4(利用Embedding优化你的搜索功能)
原文链接:https://blog.csdn.net/qq_37756660/article/details/135958019
Embedding 向量适合作为一个中间结果,用于传统的机器学习场景,比如分类、聚类。而 Completion 接口,一方面可以直接拿来作为一个聊天机器人,另一方面,你只要善用提示词,就能完成合理的文案撰写、文本摘要、机器翻译等一系列的工作。
不过,很多同学可能会说,这个和我的日常工作又没有什么关系。的确,日常我们的需求里面,最常使用自然语言处理(NLP)技术的,是搜索、广告、推荐这样的业务。那么,今天我们就来看看,怎么利用 OpenAI 提供的接口来为这些需求提供些帮助。
这一讲里,主要想教会你三件事情。
- 第一,是在没有合适的测试数据的时候,我们完全可以让 AI 给我们生成一些数据。既节约了在网上找数据的时间,也能根据自己的要求生成特定特征的数据。比如,我们就可以要求在商品标题里面有些促销相关的信息。
- 第二,是如何利用 Embedding 之间的余弦相似度作为语义上的相似度,优化搜索。通过 Embedding 的相似度,我们不要求搜索词和查询的内容之间有完全相同的关键字,而只要它们的语义信息接近就好了。
传统搜索引擎往往是使用 Elasticsearch 这个开源项目(除了大公司自研),Elasticsearch 背后的搜索原理,则是先分词,然后再使用倒排索引。
简单来说,就是把上面的“气质小清新拼接百搭双肩斜挎包”这样的商品名称,拆分成“气质”“小清新”“拼接”“百搭”“双肩”“斜挎包”。每个标题都是这样切分。然后,建立一个索引,比如“气质”这个词,出现过的标题的编号,都按编号顺序跟在气质后面。其他的词也类似。
然后,当用户搜索的时候,比如用户搜索“气质背包”,也会拆分成“气质”和“背包”两个词。然后就根据这两个词,找到包含这些词的标题,根据出现的词的数量、权重等等找出一些商品。
但是,这个策略有一个缺点,就是如果我们有同义词,那么这么简单地去搜索是搜不到的。比如,我们如果搜“自然淡雅背包”,虽然语义上很接近,但是因为“自然”“淡雅”“背包”这三个词在这个商品标题里都没有出现,所以就没有办法匹配上了。为了提升搜索效果,你就得做更多的工程研发工作,比如找一个同义词表,把标题里出现的同义词也算上等等。
不过,有了 OpenAI 的 Embedding 接口,我们就可以把一段文本的语义表示成一段向量。而向量之间是可以计算距离的,这个我们在之前的情感分析的零样本分类里就演示过了。那如果我们把用户的搜索,也通过 Embedding 接口变成向量。然后把它和所有的商品的标题计算一下余弦距离,找出离我们搜索词最近的几个向量。那最近的几个向量,其实就是语义和这个商品相似的,而并不一定需要相同的关键词。
- 第三,是如何通过 Faiss 这样的 Python 库,或者其他的向量数据库来快速进行向量之间的检索。而不是必须每一次搜索都和整个数据库计算一遍余弦相似度。
不过,上面的示例代码里面,还有一个问题。那就是每次我们进行搜索或者推荐的时候,我们都要把输入的 Embedding 和我们要检索的数据的所有 Embedding 都计算一次余弦相似度。例子里,我们检索的数据只有 100 条,但是在实际的应用中,即使不是百度、谷歌那样的搜索引擎,搜索对应的内容条数在几百万上千万的情况也不在少数。如果每次搜索都要计算几百万次余弦距离,那速度肯定慢得不行。
这个问题也有解决办法。我们可以利用一些向量数据库,或者能够快速搜索相似性的软件包就好了。比如,我比较推荐你使用 Facebook 开源的 Faiss 这个 Python 包,它的全称就是 Facebook AI Similarity Search,也就是快速进行高维向量的相似性搜索。
我们把上面的代码改写一下,先把 DataFrame 里面计算好的 Embedding 向量都加载到 Faiss 的索引里,然后让 Faiss 帮我们快速找到最相似的向量,来看看效果怎么样。
Faiss 这个库能够加载的数据量,受限于我们的内存大小。如果你的数据量进一步增长,就需要选用一些向量数据库来进行搜索。比如 OpenAI 就推荐了 Pinecone 和 Weaviate,周围也有不少团队使用的是 Milvus 这个国人开源的产品。
6.4 prompt的应用
在这一波 AIGC 浪潮之前,我也做过一个智能客服的产品。我发现智能客服的回答,往往是套用固定的模版。这个的缺点,就是每次的回答都一模一样。当然,我们可以设计多个模版轮换着表达相同的意思,但是最多也就是三四个模版,整体的体验还是相当呆板。
不过,有了 GPT 这样的生成式的语言模型,我们就可以让 AI 自动根据我们的需求去写文案了。只要把我们的需求提给 Open AI 提供的 Completion 接口,它就会自动为我们写出这样一段文字。
6.4.1 AI客服
from openai import OpenAI import os client = OpenAI(api_key = os.environ.get("OPENAI_API_KEY")) COMPLETION_MODEL = "text-davinci-003" prompt = '请你用朋友的语气回复给到客户,并称他为“亲”,他的订单已经发货在路上了,预计在3天之内会送达,订单号2021AEDG,我们很抱歉因为天气的原因物流时间比原来长,感谢他选购我们的商品。' def get_response(prompt, temperature = 1.0, stop=None): completions = client.completions.create ( model=COMPLETION_MODEL, prompt=prompt, max_tokens=1024, n=1, stop=stop, temperature=temperature, // 参数: temperature。这个参数的输入范围是 0-2 之间的浮点数,代表输出结果的随机性或者说多样性。 若为0,则每次输出一致; ) message = completions.choices[0].text return message
print(get_response(prompt)) // 第一次调用
亲,您的订单已经顺利发货啦!订单号是 2021AEDG,预计在 3 天之内会寄到您指定的地址。不好意思,给您带来了不便,原计划到货时间受天气原因影响而有所延迟。期待您收到衣服后给我们反馈意见哦!谢谢你选购我们的商品!
print(get_response(prompt)) // 第二次调用—— 连续调用两次之后,给到了含义相同、遣词造句不同的结果亲,您的订单 2021AEDG 刚刚已经发出,预计 3 天之内就会送达您的手中。抱歉由于天气的原因造成了物流延迟,但我们会尽快将订单发到您的手中。感谢您对我们的支持!
6.4.2 AI聊天机器人
上面我们知道了怎么用一句提示语让 AI 完成一个任务,就是回答一个问题。不过,我们怎么能让 AI 和人“聊起来”呢?特别是怎么完成多轮对话,让 GPT 能够记住上下文。比如,当用户问我们,“iPhone14 拍照好不好”,我们回答说“很好”。然后又问“它的价格是多少的时候”,我们需要理解,用户这里问的“它”就是指上面的 iPhone。
对于聊天机器人来说,只理解当前用户的句子是不够的,能够理解整个上下文是必不可少的。而 GPT 的模型,要完成支持多轮的问答也并不复杂。我们只需要在提示语里增加一些小小的工作就好了:
- 想要实现问答,我们只需要在提示语里,在问题之前加上 “Q :” 表示这是一个问题,
- 然后另起一行,加上 “A :” 表示我想要一个回答
那么 Completion 的接口就会回答你在 “Q : ” 里面跟的问题。比如下面,我们问 AI “鱼香肉丝怎么做”。它就一步一步地列出了制作步骤。
question = """ Q : 鱼香肉丝怎么做? A : """ print(get_response(question)) // question就是prompt提示词;
而要完成多轮对话其实也不麻烦,我们只要把之前对话的内容也都放到提示语里面,把整个上下文都提供给 AI。AI 就能够自动根据上下文,回答第二个问题。比如,你接着问“那蚝油牛肉呢?”。我们不要只是把这个问题传给 AI,而是把前面的对话也一并传给 AI,那么 AI 自然知道你问的“那蚝油牛肉呢?”是指怎么做,而不是去哪里买或者需要多少钱。
question = """ Q : 鱼香肉丝怎么做? A : 1.准备好食材:500克猪里脊肉,2个青椒,2个红椒,1个洋葱,2勺蒜蓉,3勺白糖,适量料酒,半勺盐,2勺生抽,2勺酱油,2勺醋,少许花椒粉,半勺老抽,适量水淀粉。 2.将猪里脊肉洗净,沥干水分,放入料酒、盐,抓捏抓匀,腌制20分钟。 3.将青红椒洗净,切成丝,洋葱洗净,切成葱花,蒜末拌入小苏打水中腌制。 4.将猪里脊肉切成丝,放入锅中,加入洋葱,炒制至断生,加入青红椒,炒匀,加入腌制好的蒜末,炒制至断生。 5.将白糖、生抽、酱油、醋、花椒粉、老抽、水淀粉倒入锅中,翻炒匀,用小火收汁,调味即可。 Q : 那蚝油牛肉呢? A : """ print(get_response(question))
6.4.2.1 多轮对话:为什么要把之前的聊天记录给OpenAI?
我们每次都要发送一大段之前的聊天记录给到 OpenAI。这是由 OpenAI 的 GPT-3 系列的大语言模型的原理所决定的。GPT-3 系列的模型能够实现的功能非常简单,它就是根据你给他的一大段文字去续写后面的内容。而为了能够方便地为所有人提供服务,OpenAI 也没有在服务器端维护整个对话过程自己去拼接,所以就不得不由你来拼接了。
即使 ChatGPT 的接口是把对话分成了一个数组,但是实际上,最终发送给模型的还是拼接到一起的字符串。
6.4.2.2 HuggingFace
我们通过 Gradio 这个库开发了一个聊天机器人界面。最后,我们将这个简单的聊天机器人部署到了 HuggingFace 上,让你可以分享给自己的朋友使用。
1.HuggingFace是什么
可以理解为对于AI开发者的GitHub,提供了模型、数据集(文本|图像|音频|视频)、类库(比如transformers|peft|accelerate)、教程等。
2.为什么需要HuggingFace
不同于项目的代码文件只有几个KB或几个MB的大小,AI的神经网络模型权重往往都是几百MB或者几个GB的大小,虽然一直有人把模型权重进行网络共享,但是往往都是使用网络云盘的方式来实现,基本采用了项目代码和权重文件分开的方式,而且由于神经网络权重往往需要较大的存储空间(几百MB甚至几个GB),因此更多的人不选择公开神经网络权重的方式而只公开项目代码。世界上第一个选择为众多神经网络项目建立一个权重共享的网站的是美国的huggingface,但是由于中美贸易战的问题我们国家是无法直接访问该网站的。
主要是HuggingFace把AI项目的研发流程标准化,即准备数据集、定义模型、训练和测试,如下所示:

3. 使用HuggingFace实践
了解了如何利用 HuggingFace 以及开源模型,来实现各类大模型应用的推理任务。最简单的方式,是使用 Transformers 这个 Python 开源库里面的 Pipeline 模块,只需要指定 Pipeline 里的 model 和 task,然后直接调用它们来处理我们给到的数据,就能拿到结果。我们不需要关心模型背后的结构、分词器,以及数据的处理方式,也能快速上手使用这些开源模型。Pipeline 的任务,涵盖了常见的自然语言处理任务,同时也包括了音频和图像的功能。
Pipeline 是 Transformers 库里面的一个核心功能,它封装了所有托管在 HuggingFace 上的模型推理预测的入口。你不需要关心具体每个模型的架构、输入数据格式是什么样子的。我们只要通过 model 参数指定使用的模型,通过 task 参数来指定任务类型,运行一下就能直接获得结果。
而如果模型比较大,单个的 GPU 不足以加载这个模型,可以尝试通过 HuggingFace 免费提供的 Inference API 来试用模型。只需要一个简单的 HTTP 请求,你就可以直接测试像 flan-t5-xxl 这样 110 亿参数的大模型。
而如果想要把这样的大模型应用到你的生产环境里,就可以通过 Inference Endpoint 这个功能来把大模型部署到云端。当然,这需要花不少钱。
在了解了 Pipeline、Inference API 以及 Inference Endpoint 之后,相信你已经充分掌握利用 Huggingface 来完成各种常见的文本、音频任务的方法了。后面需要的就是多多实践。
1 from transformers import pipeline 2 3 # task指定任务类型 4 classifier = pipeline(task="sentiment-analysis", device=0) # 情感分析分类器 5 preds = classifier("I am really happy today!") 6 print(preds) # 结果:[{'label': 'POSITIVE', 'score': 0.9998762607574463}] 7 8 9 # model指定模型,就能换用另一个模型来进行情感分析了 10 classifier = pipeline(model="uer/roberta-base-finetuned-jd-binary-chinese", task="sentiment-analysis", device=0) 11 preds = classifier("这个餐馆太难吃了。") 12 print(preds) 13 14 15 translation = pipeline(task="translation_en_to_zh", model="Helsinki-NLP/opus-mt-en-zh", device=0) 16 17 text = "I like to learn data science and AI." 18 translated_text = translation(text) 19 print(translated_text) # [{'translation_text': '我喜欢学习数据科学和人工智能'}]

6.4.2 让 AI 帮我解决情感分析问题
我们能不能用同样的方式,来解决上一讲我们说到的情感分析问题呢?毕竟,很多人可能没有学习过任何机器学习知识,对于向量距离之类的概念也忘得差不多了。那么,我们能不能不用任何数学概念,完全用自然语言的提示语,让 AI 帮助我们判断一下用户评论的情感是正面还是负面的呢?
prompts = """判断一下用户的评论情感上是正面的还是负面的 评论:买的银色版真的很好看,一天就到了,晚上就开始拿起来完系统很丝滑流畅,做工扎实,手感细腻,很精致哦苹果一如既往的好品质 情感:正面 评论:随意降价,不予价保,服务态度差 情感:负面 """ good_case = prompts + """ 评论:外形外观:苹果审美一直很好,金色非常漂亮 拍照效果:14pro升级的4800万像素真的是没的说,太好了, 运行速度:苹果的反应速度好,用上三五年也不会卡顿的,之前的7P用到现在也不卡 其他特色:14pro的磨砂金真的太好看了,不太高调,也不至于没有特点,非常耐看,很好的 情感: """ print(get_response(good_case))
大模型输出:
情感:正面
该评论中用户对产品的外观、拍照效果、运行速度和其他特色等方面给出了积极的评价,明显体现出用户的满意和赞扬态度,因此情感上判断为正面。
bad_case = prompts + """ 评论:信号不好电池也不耐电 情感 """ print(get_response(bad_case))
情感:负面
该评论中用户抱怨“信号不好”和“电池不耐电”,这两项都是对产品性能的负面评价,表达了用户的不满意和失望,因此情感上判断为负面。

6.4.2.1 少(小)样本学习(Few-Shots Learning)
而上面这个“给一个任务描述、给少数几个例子、给需要解决的问题”这样三个步骤的组合,也是大语言模型里使用提示语的常见套路。一般我们称之为 Few-Shots Learning(少样本学习),也就是给一个或者少数几个例子,AI 就能够举一反三,回答我们的问题。
提示词工程
如何更好地向大模型提问? https://sspai.com/post/82322
1.上下文提示(In-context Prompt)是使用大模型时最入门的技巧,指的是在提出问题之前先向大模型提供背景或情境信息。
2.思维链提示(CoT):我们一步步进行提问,然后让它按照它写的执行逻辑一步步给你一个可用的示例代码,然后你再根据需求微调每一步中代码就可以了;最后再让它输出完整的代码
3.客制化指令(Custom Instruction):我在客制化指令说设定了一些我几乎在每次提问中都会提到的前置条件,比如我所在的城市,我的学习阶段和我擅长使用的编程语言,这样ChatGPT在回答问题时就会针对我的情况做定制化的回答。
4.结构化提示词(Structured prompts)是目前被验证过的一种性能较好的一种撰写提示词的模式
检索增强RAG-例子1
https://www.aneasystone.com/archives/2024/01/prompt-engineering-notes.html
实验表明,大型语言模型能够从海量数据中学习到广泛的世界知识,这些知识以参数的形式存储在模型中,经过适当的微调就能在下游任务中取得 SOTA 表现。但是模型容量再大,也很难记住所有知识,这类通用语言模型在处理 知识密集型(knowledge-intensive) 任务时仍旧存在一定的局限性,比如知识更新不及时、生成虚假信息以及对不存在来源的引用等问题,也就是我们所说的 幻觉(hallucination)。
治理幻觉的方式有很多,比如:在训练时提供更高质量的数据,对模型进行微调补充领域知识,在 RLHF 时给予奖励模型对数据真实性更高的倾向性,通过 Prompt 引导大模型避免生成缺乏依据的信息,以及这一节所介绍的 检索增强生成(RAG,Retrieval Augment Generation)。
大模型的幻觉并非一无是处,有研究者指出幻觉是让大模型产出创意的基础。
RAG 早在 GPT 等大模型出来之前就有了相关的研究,例如 Facebook 在 2020 年 的研究提出,将模型知识分为 参数记忆(parametric memory) 和 非参数记忆(nonparametric memory),也就是内部信息和外部信息,同时结合这两类信息来回答用户问题可以提供更准确的回复,而且可以减少模型的幻觉。这里的外部信息可以是文档、数据库、网页、笔记、日志、图片、视频、甚至可以是从 API 获取的数据等等,通常我们将这些外部信息切块后保存在向量数据库中,然后基于用户输入的问题做检索。
一个典型的 RAG 包含两个主要的部分:
- 索引构建:首先准备和加载数据,将数据划分成小的数据块,然后对每个小数据块做向量表征存储,方便后续做语义检索;
- 检索和生成:基于用户输入的问题,尽可能地检索出最相关的数据块,将检索出的数据块作为上下文和用户问题一起组合成 prompt 让大模型生成回答。
检索增强RAG-例子2
我们先来尝试问 ChatGPT 一个人尽皆知的常识,“鲁迅先生去日本学习医学的老师是谁”,结果它给出的答案是鲁迅的好友,内山书店的老板内山完造,而不是大家都学习过的藤野先生。
之所以会出现这样的情况,和大模型的原理以及它使用训练的数据集是有关的。大语言模型的原理,就是利用训练样本里面出现的文本的前后关系,通过前面的文本 对接下来出现的文本进行概率预测。如果类似的前后文本出现得越多,那么这个概率在训练过程里会收敛到少数正确答案上,回答就准确。如果这样的文本很少,那么训练过程里就会有一定的随机性,对应的答案就容易似是而非。而在 GPT-3 的模型里,虽然整体的训练语料很多,但是中文语料很少。只有不到 1% 的语料是中文的,所以如果问很多中文相关的知识性或者常识性问题,它的回答往往就很扯。
当然,你可以说我们有一个解决办法,就是多找一些高质量的中文语料训练一个新的模型。或者,对于我们想让 AI 能够回答出来的问题,找一些数据。然后利用 OpenAI 提供的“微调”(Fine-tune)接口,在原来的基础上训练一个新模型出来。
RAG例子3:Bing 的解法——先搜索,后组装提示词
不过对这个领域比较关注的朋友可能就要问了。之前微软不是在 Bing 这个搜索引擎里,加上了 ChatGPT 的问答功能吗?效果似乎也还不错,那 Bing 是怎么做到的呢,是因为他们用了更加厉害的语言模型吗?
虽然我并没有什么内幕消息,不了解 Bing 是怎么做的。但是如果是我的话,会用这样一个解决办法——那就是先搜索,后提示(Prompt)。
1. 我们先通过搜索的方式,找到和询问的问题最相关的语料。这个搜索过程中,我们既可以用传统的基于关键词搜索的技术,也可以用第 9 讲我们刚刚介绍过的使用 Embedding 的相似度进行语义搜索的技术。
2. 然后,我们将和问题语义最接近的前几条内容,作为提示语的一部分给到 AI。然后请 AI 参考这些内容,再来回答这个问题。
这也是利用大语言模型的一个常见模式。因为大语言模型其实内含了两种能力。
第一种,是海量的语料中,本身已经包含了的知识信息。比如,我们前面问 AI 鱼香肉丝的做法,它能回答上来就是因为语料里已经有了充足的相关知识。我们一般称之为“世界知识”。
第二种,是根据你输入的内容,理解和推理的能力(就是广义RAG)。这个能力,不需要训练语料里有一样的内容。而是大语言模型本身有“思维能力”,能够进行阅读理解。这个过程里,“知识”不是模型本身提供的,而是我们找出来,临时提供给模型的。如果不提供这个上下文,再问一次模型相同的问题,它还是答不上来的。
RAG例子4: 使用llama-index来进行RAG
原文链接:https://blog.csdn.net/qq_37756660/article/details/135960055
我给上面这种先搜索、后提示的方式,取了一个名字,叫做 AI 的“第二大脑”模式。因为这个方法,需要提前把你希望 AI 能够回答的知识,建立一个外部的索引,这个索引就好像 AI 的“第二个大脑”。每次向 AI 提问的时候,它都会先去查询一下这个第二大脑里面的资料,找到相关资料之后,再通过大模型自己的思维能力来回答问题。
实际上,你现在在网上看到的很多读论文、读书回答问题的应用,都是通过这个模式来实现的。那么,现在我们就来自己实现一下这个“第二大脑”模式。
不过,我们不必从 0 开始写代码。因为这个模式实在太过常用了,所以有人为它写了一个开源 Python 包,叫做 llama-index。
好了,相信经过这一讲,已经能够上手使用 llama-index 这个 Python 包了。通过它,你可以快速将外部的资料库变成索引,并且通过它提供的 query 接口快速向文档提问,也能够通过将文本分片,并通过树状的方式管理索引并进行小结。
llama-index 还有很多其他功能,这个 Python 库仍然在发展过程中,不过已经非常值得拿来使用,加速你开发大语言模型类的相关应用了。相关的文档,可以在官网看到。对应的代码也是开源的,遇到问题也可以直接去源代码里一探究竟。
llama-index 其实给出了一种使用大语言模型的设计模式,我称之为“第二大脑”模式。通过先将外部的资料库索引,然后每次提问的时候,先从资料库里通过搜索找到有相关性的材料,然后再通过 AI 的语义理解能力让 AI 基于搜索到的结果来回答问题。

提示词组装:上下文context_str,原始问题query_str
——补充:什么是 llama-index?
大型语言模型(LLMs)为人类与数据之间提供了一种自然语言交互接口。广泛可用的模型已经在大量公开可用的数据上进行了预训练,例如维基百科、邮件列表、教科书、源代码等等。 然而,尽管LLMs在大量数据上进行了训练,它们并没有针对你的数据进行训练,这些数据可能是私有的或者特定于你试图解决的问题。这些数据可能隐藏在API接口后面,存储在SQL数据库中,或者被困在PDF文档和幻灯片中。
LlamaIndex通过连接到这些数据源并将这些数据添加到LLMs已有的数据中来解决这个问题。这通常被称为检索增强生成(Retrieval-Augmented Generation, RAG)。RAG使你能够使用LLMs查询你的数据、转换它,并产生新的洞见。你可以询问有关你数据的问题,创建聊天机器人,构建半自主代理等等。
概括为:LlamaIndex 是一个数据框架,用于基于大型语言模型(LLM)的应用程序来摄取、构建和访问私有或特定领域的数据。 最初的功能:是一个基于Python的全文搜索工具,它提供了构建、管理和查询大规模索引的功能
例子:
我们先来尝试问 ChatGPT 一个人尽皆知的常识,“鲁迅先生去日本学习医学的老师是谁”,结果它给出的答案是鲁迅的好友,内山书店的老板内山完造,而不是大家都学习过的藤野先生。
使用llama-index来进行RAG
把从网上找到的《藤野先生》这篇文章变成了一个 txt 文件,放在了 data/mr_fujino 这个目录下。我们的代码也非常简单,一共没有几行。
《藤野先生》是中国现代文学奠基人鲁迅于1926年在厦门大学时创作的回忆性散文。作者在文中回忆了在日本仙台医学专门学校(今日本东北大学)的留学生活
1 import openai, os 2 from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader 3 4 openai.api_key = os.environ.get("OPENAI_API_KEY") 5 6 /* 7 [构建索引] 1. 首先,我们通过一个叫做 SimpleDirectoryReader 的数据加载器,将整个./data/mr_fujino 的目录给加载进来。这里面的每一个文件,都会被当成是一篇文档。 8 */ 9 documents = SimpleDirectoryReader('./data/mr_fujino').load_data() 10 11 /* 12 [构建索引] 2. 然后,我们将所有的文档交给了 GPTSimpleVectorIndex 构建索引。顾名思义,它会把文档分段转换成一个个向量,然后存储成一个索引。 13 */ 14 index = GPTSimpleVectorIndex.from_documents(documents) 15 16 /* 17 [构建索引] 3. 最后,我们会把对应的索引存下来,存储的结果就是一个 json 文件。 18 */ 19 index.save_to_disk('index_mr_fujino.json') 20 21 22 / * 23 [使用] 例子1:我们就可以用这个索引来进行相应的问答。 24 那么,我们搜索到的内容,在这个过程里面是如何提交给 OpenAI 的呢?我们就来看看下面的这段代码就知道了。 25 注:日志中会打印出来我们通过 Embedding 消耗了多少个 Token。 26 */ 27 index = GPTVectorStoreIndex.load_from_disk('index_mr_fujino.json') 28 response = index.query("鲁迅先生在日本学习医学的老师是谁?") 29 print(response) 30 31 32 /* 33 [使用] 例子2:把搜索找到的相关内容以及问题,组合到一起变成一段提示语,让 AI 能够按照我们的要求来回答问题 34 35 这段代码里,我们定义了一个 QA_PROMPT 的对象,并且为它设计了一个模版。 36 37 1. 这个模版的开头,我们告诉 AI,我们为 AI 提供了一些上下文信息(Context information)。 38 39 2. 模版里面支持两个变量,一个叫做 上下文信息context_str,另一个叫做 query_str。context_str 的地方,在实际调用的时候,会被通过 Embedding 相似度找出来的内容填入。而 query_str 则是会被我们实际提的问题替换掉。 40 41 3. 实际提问的时候,我们告诉 AI,只考虑上下文信息,而不要根据自己已经有的先验知识(prior knowledge)来回答问题。 42 */ 43 from llama_index import QuestionAnswerPrompt 44 query_str = "鲁迅先生去哪里学的医学?" 45 DEFAULT_TEXT_QA_PROMPT_TMPL = ( 46 "Context information is below. \n" 47 "---------------------\n" 48 "{context_str}" 49 "\n---------------------\n" 50 "Given the context information and not prior knowledge, " 51 "answer the question: {query_str}\n" 52 ) 53 QA_PROMPT = QuestionAnswerPrompt(DEFAULT_TEXT_QA_PROMPT_TMPL) 54 55 response = index.query(query_str, text_qa_template=QA_PROMPT) 56 print(response)
这一次 AI 还是正确地回答出了鲁迅先生是去仙台的医学专门学校学习的。我们再试一试,问一些不相干的问题,会得到什么答案,比如我们问问红楼梦里林黛玉和贾宝玉的关系。它会回答“不知道”。
补充新版llama-index自定义提示词:定义自定义提示就像 创建格式字符串 一样简单
https://blog.csdn.net/lovechris00/article/details/137782020
1 from llama_index.core import PromptTemplate 2 3 template = ( 4 "We have provided context information below. \n" 5 "---------------------\n" 6 "{context_str}" 7 "\n---------------------\n" 8 "Given this information, please answer the question: {query_str}\n" 9 ) 10 qa_template = PromptTemplate(template) 11 12 # you can create text prompt (for completion API) 13 prompt = qa_template.format(context_str=..., query_str=...) 14 15 # or easily convert to message prompts (for chat API) 16 messages = qa_template.format_messages(context_str=..., query_str=...)
注意:您可能会看到对旧提示子类的引用,例如QuestionAnswerPrompt、RefinePrompt。
这些已被弃用(现在是 的类型别名PromptTemplate)。
现在您可以直接指定PromptTemplate(template)构建自定义提示。
但在替换默认问题答案提示时,您仍然必须确保模板字符串包含预期的参数(例如{context_str}和)。
{query_str}
RAG例子5:通过 llama_index 对于文章进行小结
还有一个常见的使用 llama-index 这样“第二大脑”的 Python 库的应用场景,就是生成文章的摘要。在前面教你如何进行文本聚类的时候,我们已经看到了可以通过合适的提示语(Prompt)做到这一点。不过,如果要总结一篇论文、甚至是一本书,每次最多只能支持 4096 个 Token 的 API 就不太够用了。
要解决这个问题也并不困难,我们只要进行分段小结,再对总结出来的内容再做一次小结就可以了。我们可以把一篇文章,乃至一本书,构建成一个树状的索引。每一个树里面的节点,就是它的子树下内容的摘要。最后,在整棵树的根节点,得到的就是整篇文章或者整本书的总结了。

RAG例子6:引入多模态,让 llama-index 能够识别小票(OCR)
llama_index 不光能索引文本,很多书里面还有图片、插画这样的信息。llama_index 一样可以索引起来,供你查询,这也就是所谓的多模态能力。当然,这个能力其实是通过一些多模态的模型,把文本和图片能够联系到一起做到的。在整个课程的第三部分,我们也会专门来看看这些图像的多模态模型是怎么样的。
要能够索引图片,我们引入了 ImageParser 这个类,这个类背后,其实是一个基于 OCR 扫描的模型 Donut。它通过一个视觉的 Encoder 和一个文本的 Decoder,这样任何一个图片能够变成一个一段文本,然后我们再通过 OpenAI 的 Embedding 把这段文本变成了一个向量。
6.4.2.2 微调(Fine-tunning)
https://openai.xiniushu.com/docs/guides/fine-tuning
GPT-3 已经在来自开放互联网的大量文本上进行了预训练。当给出仅包含几个示例的提示(prompt)时,它通常可以凭直觉判断出您要执行的任务并生成合理的补全(completion)。这通常称为“小样本学习”。
微调通过训练 比提示(prompt)中更多的示例来改进小样本学习,让您在大量任务中取得更好的结果。对模型进行微调后,您将不再需要在提示(prompt)中提供示例。这样可以节省成本并实现更低延迟的请求。
在高层次上,微调涉及以下步骤:
- 准备和上传训练数据
- 训练新的微调模型
- 使用您的微调模型
微调可让您从 API 提供的模型中获得更多收益:
- 比即时设计更高质量的结果
- 能够训练比提示(prompt)中更多的例子
- 由于更短的提示(prompt)而节省了 tokens
- 更低的延迟请求
6.6 transformer和cnn的区别
Transformer和CNN是两种不同的深度学习模型,它们在处理序列数据和图像数据方面各有优势和局限性。以下是它们之间的一些主要区别:
- 模型结构不同。
- Transformer模型的核心是Self-Attention机制(自注意力机制),它通过计算不同数据点之间的相似性来学习数据中的相关性,这种机制使得Transformer能够捕捉长距离的依赖关系,适用于自然语言处理(NLP)任务,如机器翻译和文本摘要;
- CNN模型则基于卷积和池化操作,它通过局部连接的过滤器来提取和学习图像特征,这些过滤器可以视为对输入数据的固定大小窗口的概括,适用于图像处理。
- 计算复杂性和并行性不同。
- Transformer模型的计算复杂性通常更高,因为它需要对序列中的每个元素进行自注意力计算,这可能导致训练和推理过程中的计算成本较高;
- 相比之下,CNN模型的计算复杂度一般更低,因为它利用了参数共享和局部连接,这使得模型在处理大规模数据时更加高效,同时,CNN模型在理论上可以并行处理输入数据的各个部分。
- 特征提取方式不同。
- Transformer模型通过自注意力机制提取特征,这种方式可以捕捉到输入序列中的全局上下文关系,适用于需要全局理解的NLP任务;
- 而CNN模型通过卷积操作提取特征,这种方式更关注于输入数据的局部特征,适用于需要从局部特征中学习信息的图像处理任务。
综上所述,Transformer和CNN模型在处理不同类型数据时各有优势,选择哪种模型通常取决于具体任务的需求。
6.7 常用工具
6.7.1 Jupyter notebook
应该使用哪个 IDE/环境/工具?这是人们在做数据科学项目时最常问的问题之一。可以想到,我们不乏可用的选择——从 R Studio 或 PyCharm 等语言特定的 IDE 到 Sublime Text 或 Atom 等编辑器——选择太多可能会让初学者难以下手。
如果说有什么每个数据科学家都应该使用或必须了解的工具,那非 Jupyter Notebooks 莫属了(之前也被称为 iPython 笔记本)。Jupyter Notebooks 很强大,功能多,可共享,并且提供了在同一环境中执行数据可视化的功能。
Jupyter Notebooks 允许数据科学家创建和共享他们的文档,从代码到全面的报告都可以。它们能帮助数据科学家简化工作流程,实现更高的生产力和更便捷的协作。由于这些以及你将在下面看到的原因,Jupyter Notebooks 成了数据科学家最常用的工具之一。
Jupyter Notebook 的本质是一个 Web 应用程序,便于创建和共享程序文档,支持实时代码,数学方程,可视化和 markdown。 用途包括:数据清理和转换,数值模拟,统计建模,机器学习等等 [1]
Jupyter notebook 源于 Fernando Perez 发起的 IPython 项目。
IPython 是一种 交互式 shell,与普通的 Python shell 相似,但具有一些更高级的功能,例如 语法高亮显示 和 代码补全,还有一些 magic 操作(魔术操作),十分方便。
Jupyter notebook 则是将 IPython 做成了一种 Web 应用。

如上图所示,核心为 notebook 服务器。用户通过浏览器连接到该服务器,notebook 呈现为 Web 应用,用户在 Web 应用中编写的代码通过该服务器发送给内核,内核运行代码,并将结果发送回该服务器。然后,任何输出都会返回到浏览器中。保存 notebook 时,它将作为 JSON 文件(文件扩展名为 .ipynb)写入到该服务器中。
————————————————
原文链接:https://blog.csdn.net/qq_24224067/article/details/105263459
6.7.2 Colab
Colaboratory(简称为Colab)是由Google开发的一种基于云端的交互式笔记本环境。它提供了免费的计算资源(包括CPU、GPU和TPU),可让用户在浏览器中编写和执行代码,而无需进行任何配置和安装。
Colab的目标是使机器学习和数据科学的工作更加便捷、灵活和可共享。
下面是Colab的一些主要特点和功能:
1. 免费使用和云端存储:Colab是免费的,并且提供了Google云端硬盘的集成,可以方便地将笔记本保存到云端,并随时访问和共享。
2. 硬件资源:Colab提供了CPU、GPU和TPU等硬件资源,让用户能够处理大规模的数据和执行高性能计算任务。
3. 交互式编程环境:Colab基于Jupyter Notebook,提供了一个交互式的编程环境,可以在笔记本中编写和执行代码,并即时查看结果。
————————————————
原文链接:https://blog.csdn.net/wzk4869/article/details/131108825
7 LangChain
LangChain 是一个开源的框架,它专注于简化和加速基于大型语言模型(LLMs, Large Language Models)的应用程序开发过程。就是一个为了提升构建LLM相关应用效率的一个工具。这些大型语言模型,如OpenAI的GPT系列、阿里云的通义千问、谷歌的LaMDA等,具备强大的语言理解和生成能力,能够执行诸如文本生成、问题解答、代码编写、文本翻译等多种任务。
LangChain 与 OpenAI 等大语言模型的关系主要体现在以下几个方面:
-
集成与访问:LangChain 提供了与 OpenAI 及其他供应商的大语言模型的直接集成接口,使得开发者能够轻松地在自己的应用中调用这些模型的能力,而不需要深入了解模型的具体实现或复杂的API调用细节。
-
模型抽象:通过抽象出如
LLMChain等组件,LangChain 使得开发者可以更加关注于如何使用模型来解决具体业务问题,而不是模型本身的技术细节。这包括如何构造有效的提示(prompts)、处理模型输出以及如何将模型集成到更大的应用逻辑中。 -
工作流与组件化:LangChain 不仅仅是一个模型调用工具,它还提供了一套组件和工作流系统,允许开发者将不同的语言模型、数据处理步骤、逻辑控制等组合在一起,构建复杂的应用逻辑。这包括数据存储、向量搜索、模型选择、输出解析等功能模块,形成了一个完整的应用开发生态。
-
性能优化与扩展:考虑到大语言模型的计算成本和延迟问题,LangChain 支持与技术如Intel的OpenVINO™等加速技术的集成,以提高模型的推理速度和降低运行成本。这使得基于大型语言模型的应用在实际部署中更加可行和高效。
总的来说,LangChain 构建了一个桥梁,将原本复杂难用的大型语言模型技术,转变为开发者可以方便利用的工具,促进了大语言模型技术在实际应用场景中的普及和深化。
7.1 初识LangChain-链式调用
原文链接:https://blog.csdn.net/qq_37756660/article/details/135968014
Langchain 的第一个卖点其实就在它的名字里,也就是链式调用,它可以简化多步提示语。
我们先来看一个使用 ChatGPT 的例子,你就能理解为什么会有链式调用的需求了。我们知道,GPT-3 的基础模型里面,中文的语料很少。用中文问它问题,很多时候它回答得不好。所以有时候,我会迂回处理一下,先把中文问题给 AI,请它翻译成英文,然后再把英文问题贴进去提问,得到一个英文答案。最后,再请 AI 把英文答案翻译回中文。很多时候,问题的答案会更准确一点。比如,下面的截图里,就请它简单介绍一下 Stable Diffusion 的原理是什么。
1 import openai, os 2 from langchain.prompts import PromptTemplate 3 from langchain.llms import OpenAI 4 from langchain.chains import LLMChain 5 6 openai.api_key = os.environ.get("OPENAI_API_KEY") 7 8 /** 9 这里的代码,我们使用了 Langchain 这个库,不过还没有动用它的链式调用过程。我们主要用了 Langchain 的三个包。 10 也可以参照前面的import 11 **/ 12 13 /** 14 1. LLM,也就是我们使用哪个大语言模型,来回答我们提出的问题。在这里,我们还是使用 OpenAIChat,也就是最新放出来的 gpt-3.5-turbo 模型。 15 **/ 16 llm = OpenAI(model_name="text-davinci-003", max_tokens=2048, temperature=0.5) 17 18 /** 19 2. PromptTemplate,和我们在第 11 讲里看到的 llama-index 的 PromptTemplate 是一个东西。它可以定义一个提示语模版,里面能够定义一些可以动态替换的变量。比如,代码里的 question_prompt 这个模版里,我们就定义了一个叫做 question 的变量,因为我们每次问的问题都会不一样。事实上,llamd-index 里面的 PromptTemplate 就是对 Langchain 的 PromptTemplate 做了一层简单的封装。 20 **/ 21 en_to_zh_prompt = PromptTemplate( 22 template="请把下面这句话翻译成英文: \n\n {question}?", input_variables=["question"] 23 ) 24 25 question_prompt = PromptTemplate( 26 template = "{english_question}", input_variables=["english_question"] 27 ) 28 29 zh_to_cn_prompt = PromptTemplate( 30 input_variables=["english_answer"], 31 template="请把下面这一段翻译成中文: \n\n{english_answer}?", 32 ) 33 34 /** 35 3. 主角 LLMChain,它的构造函数接收一个 LLM 和一个 PromptTemplate 作为参数。构造完成之后,可以直接调用里面的 run 方法,将 PromptTemplate 需要的变量,用 K=>V 对的形式传入进去。返回的结果,就是 LLM 给我们的答案; 36 **/ 37 question_translate_chain = LLMChain(llm=llm, prompt=en_to_zh_prompt, output_key="english_question") 38 english = question_translate_chain.run(question="请你作为一个机器学习的专家,介绍一下CNN的原理。") 39 print(english) 40 41 42 qa_chain = LLMChain(llm=llm, prompt=question_prompt, output_key="english_answer") 43 /* 一个 LLMChain 里,所使用的 PromptTemplate 里的输入参数,之前必须在 LLMChain 里,通过 output_key 定义过。不然,这个变量没有值,程序就会报错;如这里的english_question必须在前面的LLMChain的output_key里面定义过 */ 44 english_answer = qa_chain.run(english_question=english) 45 print(english_answer) 46 47 answer_translate_chain = LLMChain(llm=llm, prompt=zh_to_cn_prompt) 48 answer = answer_translate_chain.run(english_answer=english_answer) 49 print(answer)
结果:疑问?——上述第43、44行,如果第38行的返回值定义为 english_question是不是就可以了,即english_question=qa_translate_chain.run(question="xxx"),即37行的output_key和38行run的返回值是相等的?
Please explain the principles of CNN as an expert in Machine Learning. A Convolutional Neural Network (CNN) is a type of deep learning algorithm that is used to analyze visual imagery. It is modeled after the structure of the human visual cortex and is composed of multiple layers of neurons that process and extract features from an image. The main principle behind a CNN is that it uses convolutional layers to detect patterns in an image. Each convolutional layer is comprised of a set of filters that detect specific features in an image. These filters are then used to extract features from the image and create a feature map. The feature map is then passed through a pooling layer which reduces the size of the feature map and helps to identify the most important features in the image. Finally, the feature map is passed through a fully-connected layer which classifies the image and outputs the result. 卷积神经网络(CNN)是一种深度学习算法,用于分析视觉图像。它模仿人类视觉皮层的结构,由多层神经元组成,可以处理和提取图像中的特征。CNN的主要原理是使用卷积层来检测图像中的模式。每个卷积层由一组滤波器组成,可以检测图像中的特定特征。然后使用这些滤波器从图像中提取特征,并创建特征图。然后,将特征图通过池化层传递,该层可以减小特征图的大小,并有助于识别图像中最重要的特征。最后,将特征图传递给完全连接的层,该层将对图像进行分类,并输出结果。
不过如果看上面这段代码,我们似乎只是对 OpenAI 的 API 做了一层封装而已。我们构建了 3 个 LLMChain,然后按照顺序调用,每次拿到答案之后,再作为输入,交给下一个 LLM 调用。感觉好像更麻烦了,没有减少什么工作量呀?
别着急,这是因为我们还没有真正用上 LLMChain 的“链式调用”功能,而用这个功能,只需要加上一行小小的代码。我们用一个叫做 SimpleSequentialChain 的 LLMChain 类,把我们要按照顺序依次调用的三个 LLMChain 放在一个数组里,传给这个类的构造函数。
然后对于这个对象,我们调用 run 方法,把我们用中文问的问题交给它。这个时候,这个 SimpleSequentialChain,就会按照顺序开始调用 chains 这个数组参数里面包含的其他 LLMChain。并且,每一次调用的结果,会存储在这个 Chain 构造时定义的 output_key 参数里。而下一个调用的 LLMChain,里面模版内的变量如果有和之前的 output_key 名字相同的,就会用 output_key 里存入的内容替换掉模版内变量所在的占位符。
这次,我们只向这个 SimpleSequentialChain 调用一次 run 方法,把一开始的问题交给它就好了。后面根据答案去问新的问题,这个 LLMChain 会自动地链式搞定。我在这里把日志的 Verbose 模式打开了,你在输出的过程中,可以看到其实这个 LLMChain 是调用了三次,并且中间两次的返回结果你也可以一并看到。
1 from langchain.chains import SimpleSequentialChain 2 3 chinese_qa_chain = SimpleSequentialChain( 4 chains=[question_translate_chain, qa_chain, answer_translate_chain], input_key="question", 5 verbose=True) 6 answer = chinese_qa_chain.run(question="请你作为一个机器学习的专家,介绍一下CNN的原理。") 7 print(answer)
支持多个变量输入的链式调用
事实上,因为使用变量的输入输出,是用这些参数定义的。所以我们不是只能用前一个 LLMChain 的输出作为后一个 LLMChain 的输入。我们完全可以连续问多个问题,然后把这些问题的答案,作为后续问题的输入来继续处理。下面就看一个例子。
1 from langchain.chains import SequentialChain 2 3 q1_prompt = PromptTemplate( 4 input_variables=["year1"], 5 template="{year1}年的欧冠联赛的冠军是哪支球队,只说球队名称。" 6 ) 7 q2_prompt = PromptTemplate( 8 input_variables=["year2"], 9 template="{year2}年的欧冠联赛的冠军是哪支球队,只说球队名称。" 10 ) 11 q3_prompt = PromptTemplate( 12 input_variables=["team1", "team2"], 13 template="{team1}和{team2}哪只球队获得欧冠的次数多一些?" 14 ) 15 chain1 = LLMChain(llm=llm, prompt=q1_prompt, output_key="team1") 16 chain2 = LLMChain(llm=llm, prompt=q2_prompt, output_key="team2") 17 chain3 = LLMChain(llm=llm, prompt=q3_prompt) 18 19 sequential_chain = SequentialChain(chains=[chain1, chain2, chain3], input_variables=["year1", "year2"], verbose=True) 20 answer = sequential_chain.run(year1=2000, year2=2010) 21 print(answer)
7.2 LangChain的核心模块
https://juejin.cn/post/7270906612339015741
https://juejin.cn/post/7272255616319307811
组件详解:https://blog.csdn.net/Alexa_/article/details/134787140
官网:https://python.langchain.com/v0.2/docs/introduction/,v1.0版本6大核心模块:https://python.langchain.com/v0.1/docs/modules/#memory
- Model I/O:LangChain 中模型输入/输出模块是与各种大语言模型进行交互的基本组件,是大语言模型应用的核心元素。模型 I/O 允许您管理 prompt(提示),通过通用接口调用语言模型以及从模型输出中提取信息。
- Retrieval检索:支持RAG,对于RAG应用,LangChain提供了所有的构建模块(文档加载器:加载不同数据源的文档,文档转换器:一种主要的转换器就是分割,比如将大段文本分割成小块,文本embedding模型:将文本向量化,向量存储,检索:在数据库中进行向量的检索)
- Chains:虽然独立使用大型语言模型能够应对一些简单任务,但对于更加复杂的需求,可能需要将多个大型语言模型进行链式组合,或与其他组件进行链式调用。
- Memory:Memory就是对话的上下文,它记录着当前对话的内容、背景等相关信息
- Agents:大型语言模型(LLMs)非常强大,但它们缺乏“最笨”的计算机程序可以轻松处理的特定能力。LLM 对逻辑推理、计算和检索(时效性强的)外部信息的能力较弱,这与最简单的计算机程序形成对比。例如,语言模型无法准确回答简单的计算问题,还有当询问最近发生的事件时,其回答也可能过时或错误,因为无法主动获取最新信息。这是由于当前语言模型仅依赖预训练数据,与外界“断开”。要克服这一缺陷, LangChain 框架提出了 “代理”( Agent ) 的解决方案。代理作为语言模型的外部模块,可提供计算、逻辑、检索等功能的支持,使语言模型获得异常强大的推理和获取信息的超能力。
- Callbacks:LangChain提供了一个回调系统,允许您连接到LLM应用程序的各个阶段。这对于日志记录、监视、流式处理和其他任务非常有用。Callback 模块扮演着记录整个流程运行情况的角色,充当类似于日志的功能。在每个关键节点,它记录了相应的信息,以便跟踪整个应用的运行情况。例如,在 Agent 模块中,它记录了调用 Tool 的次数以及每次调用的返回参数值。Callback 模块可以将收集到的信息直接输出到控制台,也可以输出到文件,甚至可以传输到第三方应用程序,就像一个独立的日志管理系统一样。通过这些日志,可以分析应用的运行情况,统计异常率,并识别运行中的瓶颈模块以进行优化。
7.2.1 Model I/O
大模型应用最核心当然是大模型本身,而LangChain就是在大模型在基础上,提供了一些基础模块,我们可以通过这些基础模块与大模型进行交互,主要包括:
-
Prompts:通过模版将prompts输入给大模型(Input)。
-
Language models:调用语言模型的一些接口(Model)。
-
Output Parsers:对于大模型输出进行解析(Output)。
这些模块统称为Model I/O,其数据流图如下所示:

7.2.2 Retrieval检索
我们知道LLM需要训练数据去训练它,而且数据质量越好,训练出来的模型效果更好。除了训练数据,很多LLM应用还需要特定的数据,而这些数据的主要是通过RAG(Retrieval Augmented Generation)而来的;在这个过程中,通过检索外部的数据,然后输入给LLM。
对于RAG应用,LangChain提供了所有的构建模块,主要模块如下图所示:

模块有:
- 文档加载器:加载不同数据源的文档
- 文档转换器:一种主要的转换器就是分割,比如将大段文本分割成小块
- 文本embedding模型:将文本向量化
- 向量存储
- 检索:在数据库中进行向量的检索
7.2.3 Chains
Chain简单来说就是:将一系列的调用组件链接在一起,既可以是线性的顺序链,也可以是类似有向图的顺序链。通过链这种方式,我们就可以将多个组件进行组合、协同从而创建一个简单、统一的应用。
LangChain主要的链类型有:
-
LLM链(LLMChain):将LLM和prompt链接在一起。
-
简单顺序链(SimpleSequentialChain):线性的,单个输入单个输出。
-

-
常规顺序链(SequentialChain):类似有向图,可以多个输入,多个输出。
-

-
路由链(RouterChain):包含子链路。
-

7.2.4 Memory
LangChain提供了很多模块,这样我们可以方便地将Memory增加到一个系统中去。Memory系统需要有两个基础的能力:读和写。
-
在收到用户初始输入之后,但在继续执行核心逻辑之前,Chain会先去读取Memory系统,然后将其读取到的信息也作为用户输入的一部分。
-
在执行完核心逻辑之后 ,但在返回结果之前,Chain会将用户输入和当前输出写到Momory系统。

任何一个Memory系统都需要考虑两个核心的设计:
状态怎么存储
状态怎么查询
在LangChain中,主要通过Chat Messages列表的方式来存储,其中Memory模块中有一个关键的部分就是集成Chat Messages存储
7.2.5 Agents

从LangChain的早期开始,社区最大的反馈之一就是定制预构建链和代理的内部结构非常困难。为了委员会,我们去年夏天加入了LCEL,使得创建任意可组合序列变得容易。
直到现在,LangChain中的代理都是基于AgentExecutor这个单一的类,它有固定的逻辑来运行代理。为了支持越来越高级的代理,我们不断地为这个类添加更多的参数,但仍然不是真正的可组合。
几个月前,我们启动了LangGraph,这是LangChain的一个扩展,用于创建代理。您可以将其视为“代理的LCEL”。第二天LCEL增加了两个重要组件:能够轻松定义循环(对于代理来说,但对于链来说不是必需的)和内置的内存功能。
在langchainv0.2中,我们保留了以前的AgentExecutor,但LangGraph正在成为构建代理的推荐方式。我们增加了一个预构建的LangGraph对象,它相当于AgentExecutor,由于它是基于LangGraph构建的,因此更容易定制和修改。想要了解如何迁移到更详细的版本,可以查看这里。
7.2.6 Callbacks
Callback 模块的具体实现包括两个主要功能,对应CallbackHandler 和 CallbackManager 的基类功能:
- CallbackHandler 用于记录每个应用场景(如 Agent、LLchain 或 Tool )的日志,它是单个日志处理器,主要记录单个场景的完整日志信息。
- 而CallbackManager则封装和管理所有的 CallbackHandler ,包括单个场景的处理器,也包括整个运行时链路的处理器。"
在哪里传入回调 ?
该参数可用于整个 API 中的大多数对象(链、模型、工具、代理等),位于两个不同位置::
构造函数回调:在构造函数中定义,例如 LLMChain(callbacks=[handler], tags=[‘a-tag’]) ,它将被用于对该对象的所有调用,并且将只针对该对象,例如,如果你向 LLMChain 构造函数传递一个 handler ,它将不会被附属于该链的 Model 使用。
请求回调:定义在用于发出请求的 call() / run() / apply() 方法中,例如 chain.call(inputs, callbacks=[handler]) ,它将仅用于该特定请求,以及它包含的所有子请求(例如,对 LLMChain 的调用会触发对 Model 的调用,该 Model 使用 call() 方法中传递的相同 handler)。
verbose 参数在整个 API 的大多数对象(链、模型、工具、代理等)上都可以作为构造参数使用,例如 LLMChain(verbose=True),它相当于将 ConsoleCallbackHandler 传递给该对象和所有子对象的 callbacks 参数。这对调试很有用,因为它将把所有事件记录到控制台
7.3 深入Langchain链式调用(几种常见场景)
https://blog.csdn.net/qq_37756660/article/details/135968448
7.3.1 LLMMathChain让AI准确计算
为什么计算是AI的短板?
因为大模型强调的是基于文本的训练,学习的是语言规律和上下文的关联,并不是非常准确和精确的数学逻辑和数值计算规则。所以他建议,如果你想得到准确的计算结果,你可以去用传统的算法,或者一些垂直领域的小模型来实现。
其实这个结果想想也是对的,人工智能是基于神经网络,也就是按照我们人类的思维方式在运行。我们每一个人,如果扫一眼一篇文章就能计算出答案,这种人恐怕也不多,可能只有天才呢,才能够拥有这种能力。哪怕是你数一下数,比方一篇文章里面,一个人名出现多少次,可能对我们每一个人来说,都是一个巨大的挑战。
反倒我们的优势体现在哪里呢?让你浏览一篇文章和大致的内容,和上下文的关联,肯定我觉得每一个人都能掌握的,大差不差。所以这可能就是,人工智能和传统的算法之间的差异。
如果:直接让 OpenAI 帮我们计算一下 352 x 493 等于多少,你会发现,它算得大差不差,但还是算错了;
所以曲线救国:让大模型生成代码,再根据代码计算;
1 multiply_by_python_prompt = PromptTemplate(template="请写一段Python代码,计算{question}?", input_variables=["question"]) 2 math_chain = LLMChain(llm=llm, prompt=multiply_by_python_prompt, output_key="answer") 3 answer_code = math_chain.run({"question": "352乘以493"}) 4 print(result) # result为LLM生成的代码,即为print(352 * 493) 5 6 # 我们不想自己拷贝代码到result为LLM生成的代码到Python 的解释器或者 Notebook 里面,再去手工执行一遍。所以,我们可以在后面再调用一个 Python 解释器REPL,让整个过程自动完成 7 # LangChain 里面内置了一个 utilities 的包,里面包含了 PythonREPL 这个类,可以实现对 Python 解释器的调用。如果你去翻看一下对应代码的源码的话,它其实就是简单地调用了一下系统自带的 exec 方法,来执行 Python 代码。
utilities 里面还有很多其他的类,能够实现很多功能,比如可以直接运行 Bash 脚本,调用 Google Search 的 API 等等 8 9 from langchain.utilities import PythonREPL 10 python_repl = PythonREPL() 11 result = python_repl.run(answer_code) 12 print(result) 13 14 15 # 这其实也是一种链式调用。只不过,调用链里面的第二步,不是去访问 OpenAI 的 API 而已。所以,对于这些工具能力,LangChain 也把它们封装成了 LLMChain 的形式(LLMMathChain,不需要自己去生成代码,再调用 PythonREPL,只要直接调用 LLMMathChain,它就会在背后把这一切都给做好) 16 # LangChain 也把前面讲过的 utilities 包里面的很多功能,都封装成了 Utility Chains。比如,SQLDatabaseChain 可以直接根据你的数据库生成 SQL,然后获取数据 17 18 from langchain import LLMMathChain 19 20 llm_math = LLMMathChain(llm=llm, verbose=True) 21 result = llm_math.run("请计算一下352乘以493是多少?") 22 print(result)

7.3.2 RequestsChain(调用外部API->AI从返回提取内容)->TransformChain结构化
1 from langchain.chains import LLMRequestsChain 2 3 template = """在 >>> 和 <<< 直接是来自Google的原始搜索结果. 4 请把对于问题 '{query}' 的答案从里面提取出来,如果里面没有相关信息的话就说 "找不到" 5 请使用如下格式: 6 Extracted:<answer or "找不到"> 7 >>> {requests_result} <<< 8 Extracted:""" 9 10 11 # 1. 首先,因为我们是简单粗暴地搜索 Google。但是我们想要的是一个有价值的天气信息,而不是整个网页。所以,我们还需要通过 ChatGPT 把网页搜索结果里面的答案给找出来。所以我们定义了一个 PromptTemplate,通过一段提示语,让 OpenAI 为我们在搜索结果里面,找出问题的答案,而不是去拿原始的 HTML 页面。 12 13 PROMPT = PromptTemplate( 14 input_variables=["query", "requests_result"], 15 template=template, 16 ) 17 18 # 2. 然后,我们使用了 LLMRequestsChain,并且把刚才 PromptTemplate 构造的一个普通的 LLMChain,作为构造函数的一个参数,传给 LLMRequestsChain,帮助我们在搜索之后处理搜索结果。 19 20 # 3. 对应的搜索词,通过 query 这个参数传入,对应的原始搜索结果,则会默认放到 requests_results 里。而通过我们自己定义的 PromptTemplate 抽取出来的最终答案,则会放到 output 这个输出参数里面。 21 22 requests_chain = LLMRequestsChain(llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=PROMPT)) 23 question = "今天上海的天气怎么样?" 24 inputs = { 25 "query": question, 26 "url": "https://www.google.com/search?q=" + question.replace(" ", "+") 27 } 28 result=requests_chain(inputs) 29 print(result) # {'query': '今天上海的天气怎么样?', 'url': 'https://www.google.com/search?q=今天上海的天气怎么样?', 'output': '小雨; 10℃~15℃; 东北风 风力4-5级'} 30 print(result['output']) # 小雨; 10℃~15℃; 东北风 风力4-5级

7.3.3 VectorDBQA(内部资料Embedding和索引->LLM)
此外,还有一个常用的 LLMChain,就是我们之前介绍的 llama-index 的使用场景,也就是针对自己的资料库进行问答。
我们预先把资料库索引好,然后每次用户来问问题的时候,都是1. 先到这个资料库里搜索,再 2. 把问题和答案一并交给 AI,让AI去组织语言回答。
在 VectorDBQA 这个 LLMChain 背后,其实也是通过一系列的链式调用,1. 先完成搜索 VectorStore,2. 再向 AI 发起 Completion 请求这样两个步骤的。
1 from langchain.embeddings.openai import OpenAIEmbeddings 2 from langchain.vectorstores import FAISS 3 from langchain.text_splitter import SpacyTextSplitter 4 from langchain import OpenAI, VectorDBQA 5 from langchain.document_loaders import TextLoader 6 7 llm = OpenAI(temperature=0) 8 loader = TextLoader('./data/ecommerce_faq.txt') # 1.通过一个 TextLoader 把文件加载进来 9 documents = loader.load() 10 text_splitter = SpacyTextSplitter(chunk_size=256, pipeline="zh_core_web_sm") 11 texts = text_splitter.split_documents(documents) # 2.通过 SpacyTextSplitter 给文本分段,确保每个分出来的 Document 都是一个完整的句子 12 13 embeddings = OpenAIEmbeddings() # 3.使用 OpenAIEmbeddings 来给文档创建 Embedding 14 docsearch = FAISS.from_documents(texts, embeddings) # 4.通过FAISS把它存储成一个 VectorStore,即构建基于 FAISS 进行向量存储的 docsearch 的索引 15 16 # 5.我们通过VectorDBQA的from_chain_type定义了一个 LLM 17 # 对应的 FAQ 内容,我是请 ChatGPT 为我编造之后放在了 ecommerce_faq.txt 这个文件里。 18 faq_chain = VectorDBQA.from_chain_type(llm=llm, vectorstore=docsearch, verbose=True)
总结
我们可以看到,Langchain 的链式调用并不局限于使用大语言模型的接口。这一讲里,我们就看到四种常见的将大语言模型的接口和其他能力结合在一起的链式调用。
1. LLMMathChain 能够通过 Python 解释器变成一个计算器,让 AI 能够准确地进行数学运算。
2. 通过 RequestsChain,我们可以直接调用外部 API,然后再让 AI 从返回的结果里提取我们关心的内容。
3. TransformChain 能够让我们根据自己的要求对数据进行处理和转化,我们可以把 AI 返回的自然语言的结果进一步转换成结构化的数据,方便其他程序去处理。
4. VectorDBQA 能够完成和 llama-index 相似的事情,只要预先做好内部数据资料的 Embedding 和索引,通过对 LLMChain 进行一次调用,我们就可以直接获取回答的结果。
这些能力大大增强了 AI 的实用性,解决了几个之前大语言模型处理得不好的问题,包括数学计算能力、实时数据能力、和现有程序结合的能力,以及搜索属于自己的资料库的能力。你完全可以定义自己需要的 LLMChain,通过程序来完成各种任务,然后合理地组合不同类型的 LLMChain 对象,来实现连 ChatGPT 都做不到的事情。而 ChatGPT Plugins 的实现机制,其实也是类似的。
7.4 Langchain里的“记忆力”(memory),让AI只记住有用的事儿
https://blog.csdn.net/qq_37756660/article/details/135969439
我们在第 6 讲里做的聊天机器人。在那个里面,为了能够让 ChatGPT 知道整个聊天的上下文,我们需要把历史的对话记录都传给它。但是,因为能够接收的 Token 数量有上限,所以我们只能设定一个参数,只保留最后几轮对话。
7.4.1 BufferWindow,滑动窗口记忆
这个基于一个固定长度的滑动窗口的“记忆”功能,被直接内置在 LangChain 里面了。在 Langchain 里,把对于整个对话过程的上下文叫做 Memory。任何一个 LLMChain,我们都可以给它加上一个 Memory,来让它记住最近的对话上下文。把对应的代码放在了下面。
1 from langchain.memory import ConversationBufferWindowMemory 2 3 template = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求: 4 1. 你的回答必须是中文 5 2. 回答限制在100个字以内 6 {chat_history} 7 Human: {human_input} 8 Chatbot:""" 9 10 prompt = PromptTemplate( 11 input_variables=["chat_history", "human_input"], 12 template=template 13 ) 14 memory = ConversationBufferWindowMemory(memory_key="chat_history", k=3) # k=3 也就是只保留最近三轮的对话内容。 15 llm_chain = LLMChain( 16 llm=OpenAI(), 17 prompt=prompt, 18 memory=memory, 19 verbose=True 20 ) 21 llm_chain.predict(human_input="你是谁?")
7.4.2 SummaryMemory,把小结作为历史记忆
使用 BufferWindow 这样的滑动窗口有一个坏处(轮次限制),就是几轮对话之后,AI 就把一开始聊的内容给忘了。所以在第 7 讲的时候我们讲过,遇到这种情况,可以让 AI 去总结一下前面几轮对话的内容。这样,我们就不怕对话轮数太多或者太长了。
同样的,Langchain 也提供了一个 ConversationSummaryMemory,可以实现这样的功能(不是所有的任务,都适合通过调用一次 ChatGPT 的 API 来解决),我们还是通过一段简单的代码来看看它是怎么用的。
1 from langchain.chains import ConversationChain 2 from langchain.memory import ConversationSummaryMemory 3 llm = OpenAI(temperature=0) 4 5 #我们定义的 ConversationSummaryMemory,它的构造函数也接受一个 LLM 对象。这个对象会专门用来生成历史对话的小结,是可以和对话本身使用的 LLM 对象不同的。 6 memory = ConversationSummaryMemory(llm=OpenAI()) 7 8 prompt_template = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求: 9 1. 你的回答必须是中文 10 2. 回答限制在100个字以内 11 {history} 12 Human: {input} 13 AI:""" 14 prompt = PromptTemplate( 15 input_variables=["history", "input"], template=prompt_template 16 ) 17 18 # 这次我们没有使用 LLMChain 这个对象,而是用了封装好的 ConversationChain。用 ConversationChain 的话,其实我们是可以不用自己定义 PromptTemplate 来维护历史聊天记录的,但是为了使用中文的 PromptTemplate,我们在这里还是自定义了对应的 Prompt。 19 conversation_with_summary = ConversationChain( 20 llm=llm, 21 memory=memory, 22 prompt=prompt, 23 verbose=True 24 ) 25 conversation_with_summary.predict(input="你好") # 每一次 AI 都是把之前的小结和新的对话交给 memory 中定义的 LLM 再次进行小结
7.4.3 两者结合,使用 SummaryBufferMemory
1 from langchain import PromptTemplate 2 from langchain.chains import ConversationChain 3 from langchain.memory import ConversationSummaryBufferMemory 4 from langchain.llms import OpenAI 5 6 # 1. 这个代码显得有些长,这是为了演示的时候让你看得更加清楚一些。我把 Langchain 原来默认的对 Memory 进行小结的提示语模版从英文改成中文的了,不过这个翻译工作我也是让 ChatGPT 帮我做的。 7 # 如果你想了解原始的英文提示语是什么样的,可以去看一下它源码里面的_DEFAULT_SUMMARIZER_TEMPLATE,对应的链接放在这里了。 8 9 SUMMARIZER_TEMPLATE = """请将以下内容逐步概括所提供的对话内容,并将新的概括添加到之前的概括中,形成新的概括。 10 EXAMPLE 11 Current summary: 12 Human询问AI对人工智能的看法。AI认为人工智能是一种积极的力量。 13 New lines of conversation: 14 Human:为什么你认为人工智能是一种积极的力量? 15 AI:因为人工智能将帮助人类发挥他们的潜能。 16 New summary: 17 Human询问AI对人工智能的看法。AI认为人工智能是一种积极的力量,因为它将帮助人类发挥他们的潜能。 18 END OF EXAMPLE 19 Current summary: 20 {summary} 21 New lines of conversation: 22 {new_lines} 23 New summary:""" 24 25 SUMMARY_PROMPT = PromptTemplate( 26 input_variables=["summary", "new_lines"], template=SUMMARIZER_TEMPLATE 27 ) 28 29 # 2. 我们定义了一个 ConversationSummaryBufferMemory,在这个 Memory 的构造函数里面,我们指定了使用的 LLM、提示语,以及一个 max_token_limit 参数。 30 # max_token_limit 参数,其实就是告诉我们,当对话的长度到多长之后,我们就应该调用 LLM 去把文本内容小结一下。 31 memory = ConversationSummaryBufferMemory(llm=OpenAI(), prompt=SUMMARY_PROMPT, max_token_limit=256) 32 33 CHEF_TEMPLATE = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求: 34 1. 你的回答必须是中文。 35 2. 对于做菜步骤的回答尽量详细一些。 36 {history} 37 Human: {input} 38 AI:""" 39 CHEF_PROMPT = PromptTemplate( 40 input_variables=["history", "input"], template=CHEF_TEMPLATE 41 ) 42 43 conversation_with_summary = ConversationChain( 44 llm=OpenAI(model_name="text-davinci-003", stop="\n\n", max_tokens=2048, temperature=0.5), 45 prompt=CHEF_PROMPT, 46 memory=memory, 47 verbose=True 48 ) 49 answer = conversation_with_summary.predict(input="你是谁?") 50 print(answer)

Pinecone 在自己网站上给出了一个数据对比,不同类型的 Memory,随着对话轮数的增长,占用的 Token 数量的变化。你可以去看一看,不同的 Memory 在不同的参数下,占用的 Token 数量是不同的。
比较合理的方式,还是使用这里的 ConversationSummaryBufferMemory,这样既可以在记录少数对话内容的时候,记住的东西更加精确,也可以在对话轮数增长之后,既能够记住各种信息,又不至于超出 Token 数量的上限。
不过,在运行程序的过程里,你应该可以感觉到现在程序跑得有点儿慢。这是因为我们使用 ConversationSummaryBufferMemory 很多时候要调用多次 OpenAI 的 API。在字数超过 max_token_limit 的时候,需要额外调用一次 API 来做小结。而且这样做,对应的 Token 数量消耗也是不少的。
所以,不是所有的任务,都适合通过调用一次 ChatGPT 的 API 来解决。
7.4.4 让AI记住有用的信息:实体识别存储EntityMemory
我们不仅可以在整个对话过程里,使用我们的 Memory 功能。如果你之前已经有了一系列的历史对话,我们也可以通过 Memory 提供的 save_context 接口,把历史聊天记录灌进去。然后基于这个 Memory 让 AI 接着和用户对话。比如下面我们就把一组电商客服历史对话记录给了 SummaryBufferMemory。
1 memory = ConversationSummaryBufferMemory(llm=OpenAI(), prompt=SUMMARY_PROMPT, max_token_limit=40) 2 memory.save_context( 3 {"input": "你好"}, 4 {"ouput": "你好,我是客服李四,有什么我可以帮助您的么"} 5 ) 6 memory.save_context( 7 {"input": "我叫张三,在你们这里下了一张订单,订单号是 2023ABCD,我的邮箱地址是 customer@abc.com,但是这个订单十几天了还没有收到货"}, 8 {"ouput": "好的,您稍等,我先为您查询一下您的订单"} 9 ) 10 memory.load_memory_variables({})
输出结果:
{'history': 'System: \nHuman和AI打招呼,AI介绍自己是客服李四,问Human有什么可以帮助的。Human提供订单号和邮箱地址,AI表示会为其查询订单状态。'}
通过调用 memory.load_memory_variables 方法,我们发现 AI 对整段对话做了小结。但是这个小结有个问题,就是它并没有提取到我们最关注的信息,比如用户的订单号、用户的邮箱。只有有了这些信息,AI 才能够去查询订单,拿到结果然后回答用户的问题。
以前在还没有 ChatGPT 的时代,在客服聊天机器人这样的领域,我们会通过命名实体识别的方式,把邮箱、订单号之类的关键信息提取出来。在有了 ChatGPT 这样的大语言模型之后,我们还是应该这样做。不过我们不是让专门的命名实体识别的算法做,而是直接让 ChatGPT 帮我们做。Langchain 也内置了一个 EntityMemory 的封装,让 AI 自动帮我们提取这样的信息
1 from langchain.chains import ConversationChain 2 from langchain.memory import ConversationEntityMemory 3 from langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE # Langchain 也内置了一个 EntityMemory 的封装 4 5 entityMemory = ConversationEntityMemory(llm=llm) 6 conversation = ConversationChain( 7 llm=llm, 8 verbose=True, 9 prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE, 10 memory=entityMemory 11 ) 12 13 answer=conversation.predict(input="我叫张老三,在你们这里下了一张订单,订单号是 2023ABCD,我的邮箱地址是 customer@abc.com,但是这个订单十几天了还没有收到货") 14 print(answer) 15 16 # 把 memory 里面存储的东西打印出来 17 print(conversation.memory.entity_store.store)
EntityMemory存储结果:
{'张老三': '张老三是一位订单号为2023ABCD、邮箱地址为customer@abc.com的客户。', '2023ABCD': '2023ABCD is an order placed by customer@abc.com that has not been received after more than ten days.', 'customer@abc.com': 'Email address of Zhang Lao San, who placed an order with Order Number 2023ABCD, but has not received the goods more than ten days later.'}
可以看到,EntityMemory 里面不仅存储了这些命名实体的名字,也对应的把命名实体所关联的上下文记录了下来。这个时候,如果我们再通过对话来询问相关的问题,AI 也能够答上来
answer=conversation.predict(input="我刚才的订单号是多少?") print(answer) # 输出结果:您的订单号是2023ABCD。
7.5 Langchain 里面的中介与特工:Agent
https://blog.csdn.net/qq_37756660/article/details/135973486
Langchain 能够便于我们把 AI 对语言的理解和组织能力、外部各种资料或者 SaaS 的 API,以及你自己撰写的代码整合到一起来。通过对这些能力的整合,我们就可以通过自然语言完成更加复杂的任务了,而不仅仅只是能闲聊。
不过,到目前为止。我们所有基于 ChatGPT 的应用,基本都是“单项技能”,比如前面关于“藤野先生”的问题,或者上一讲里查询最新的天气或者通过 Python 算算术。本质上都是限制 AI 只针对我们预先索引的数据,或者实时搜索的数据进行回答。
支持多种单项能力,让 AI 做个选择题
但是,如果我们真的想要做一个能跑在生产环境上的 AI 聊天机器人,我们需要的不只一个单项技能。它应该针对你自己的数据有很多个不同的“单项技能”,就拿我比较熟悉的电商领域来说,我们至少需要这样三个技能。
1. 我们需要一个“导购咨询”的单项技能,能够查询自己商品库里的商品信息为用户做导购和推荐。
2. 然后需要一个“售中咨询”的单项技能,能够查询订单的物流轨迹,对买了东西还没有收到货的用户给出安抚和回复。
3. 最后还需要一个“FAQ”的单项技能,能够把整个电商网站的 FAQ 索引起来,当用户问到退货政策、运费、支付方式等问题的时候,我们可以从 FAQ 里面拿到对应的答案,回复给用户。
同时,对于这三个单项技能,AI 要能够自己判断什么时候该用什么样的技能。而不是需要人工介入,或者写一堆 if…else 的代码。
在学习了这么多讲的内容之后,你可以先想想,你有没有什么办法可以通过 ChatGPT 做到这些呢?直接2. 一次性提供三个“单项技能”,还要在三个单项技能之间选择合适的技能,的确不是靠简单的几行代码或者 LLMChain 能够解决的。
但是我们可以采用一个在写大型系统的时候常用的思路,就是“分而治之”。对于每一个单项技能,我们都可以通过之前几讲学习的内容,把它们变成一个 LLMChain。然后,对于用户问的问题,我们不妨先问问 AI,让它告诉我们应该选用哪一个 LLMChain 来回答问题好了。
我们在下面就写了这样一段代码,1. 通过提示语让 AI 做一个选择题。
7.5.1 让 AI 做个选择题到某个单向能力(具备完整多项能力)
1 # 例子:通过提示语让 AI 做一个选择题 2 import openai, os 3 4 openai.api_key = os.environ.get("OPENAI_API_KEY") 5 6 from langchain.prompts import PromptTemplate 7 from langchain.llms import OpenAIChat 8 from langchain.chains import LLMChain 9 10 llm = OpenAIChat(max_tokens=2048, temperature=0.5) 11 multiple_choice = """ 12 请针对 >>> 和 <<< 中间的用户问题,选择一个合适的工具去回答她的问题。只要用A、B、C的选项字母告诉我答案。 13 如果你觉得都不合适,就选D。 14 >>>{question}<<< 15 我们有的工具包括: 16 A. 一个能够查询商品信息,为用户进行商品导购的工具 17 B. 一个能够查询订单信息,获得最新的订单情况的工具 18 C. 一个能够搜索商家的退换货政策、运费、物流时长、支付渠道、覆盖国家的工具 19 D. 都不合适 20 """ 21 multiple_choice_prompt = PromptTemplate(template=multiple_choice, input_variables=["question"]) 22 choice_chain = LLMChain(llm=llm, prompt=multiple_choice_prompt, output_key="answer") 23 24 question = "我想买一件衣服,但是不知道哪个款式好看,你能帮我推荐一下吗?" 25 print(choice_chain(question)) 26 """ 输出结果为 27 {'question': '我想买一件衣服,但是不知道哪个款式好看,你能帮我推荐一下吗?', 'answer': '\n\nA. 一个能够查询商品信息,为用户进行商品导购的工具。'} 28 """ 29 30 question = "我有一张订单,订单号是 2022ABCDE,一直没有收到,能麻烦帮我查一下吗?" 31 print(choice_chain(question)) 32 """ 输出结果为 33 {'question': '我有一张订单,订单号是 2022ABCDE,一直没有收到,能麻烦帮我查一下吗?', 'answer': '\n\nB. 一个能够查询订单信息,获得最新的订单情况的工具。'} 34 """ 35 36 question = "请问你们的货,能送到三亚吗?大概需要几天?" 37 print(choice_chain(question)) 38 """ 输出结果为 39 {'question': '请问你们的货,能送到三亚吗?大概需要几天?', 'answer': '\n\nC. 一个能够搜索商家的退换货政策、运费、物流时长、支付渠道、覆盖国家的工具。'} 40 """ 41 42 question = "今天天气怎么样?" 43 print(choice_chain(question)) 44 """ 输出结果为 45 {'question': '今天天气怎么样?', 'answer': '\n\nD. 都不合适,因为这个问题需要的是天气预报信息,我们需要提供一个天气预报查询工具或者引导用户去查看天气预报网站或应用程序。'} 46 """
7.5.2 Langchain 里面的中介与特工:Agent
这样一个“分治法”的思路,你在真实的业务场景中一定会遇到的。无论是哪行哪业的客服聊天机器人,其实都会有能够直接通过资料库就回答的用户问题,也会有和用户自己或者公司产品相关的信息,需要通过检索的方式来提供。所以,这样一个“先做一个选择题”的思路,Langchain 就把它发扬光大了,建立起了 Agent 这个抽象概念。
下面我们来看看上面这个例子,我们怎么通过 Langchain 提供的 Agent 直接采取行动来解决问题。
1 from langchain.agents import initialize_agent, Tool 2 from langchain.llms import OpenAI 3 4 llm = OpenAI(temperature=0) 5 6 """ 7 1. 首先,我们定义了三个函数,分别叫做 search_order、recommend_product 以及 faq。它们的输入都是一个字符串,输出是我们写好的对于问题的回答。 8 """ 9 def search_order(input: str) -> str: 10 return "订单状态:已发货;发货日期:2023-01-01;预计送达时间:2023-01-10" 11 12 def recommend_product(input: str) -> str: 13 return "红色连衣裙" 14 15 def faq(intput: str) -> str: 16 return "7天无理由退货" 17 18 """ 19 2. 然后,我们针对这三个函数,创建了一个 Tool 对象的数组,把这三个函数分别封装在了三个 Tool 对象里面。每一个 Tool 的对象,在函数之外,还定义了一个名字,并且定义了 Tool 的 description。这个 description 就是告诉 AI,这个 Tool 是干什么用的。就像这一讲一开始的那个例子一样,AI 会根据问题以及这些描述来做选择题。 20 """ 21 tools = [ 22 Tool( 23 name = "Search Order",func=search_order, 24 description="useful for when you need to answer questions about customers orders" 25 ), 26 Tool(name="Recommend Product", func=recommend_product, 27 description="useful for when you need to answer questions about product recommendations" 28 ), 29 Tool(name="FAQ", func=faq, 30 description="useful for when you need to answer questions about shopping policies, like return policy, shipping policy, etc." 31 ) 32 ] 33 34 """ 35 3. 最后,我们创建了一个 agent 对象,指定它会用哪些 Tools、LLM 对象以及 agent 的类型。在 agent 的类型这里,我们选择了 zero-shot-react-description。这里的 zero-shot 就是指我们在课程一开始就讲过的“零样本分类”,也就是不给 AI 任何例子,直接让它根据自己的推理能力来做决策。而 react description,指的是根据你对于 Tool 的描述(description)进行推理(Reasoning)并采取行动(Action)。 36 这里的这个 ReAct,并不是来自 Facebook 的前端框架的名字,而是来自一篇 Google Brain 的论文 37 """ 38 agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True) 39 40 question = "我想买一件衣服,但是不知道哪个款式好看,你能帮我推荐一下吗?" 41 result = agent.run(question) 42 print(result) 43 44 """ 输出结果 45 # Agent 每一步的操作,可以分成 5 个步骤,分别是 Action、Action Input、Observation、Thought,最后输出一个 Final Answer。 46 > Entering new AgentExecutor chain... 47 I need to recommend a product. 48 Action: Recommend Product # 1. Action,就是根据用户的输入,选择应该选取哪一个 Tool,然后行动。 49 Action Input: Clothes # 2. Action Input,就是根据需要使用的Tool,从用户的输入里提取出相关的内容,可以输入到 Tool 里面。 50 Observation: 红色连衣裙 # 3. Oberservation,就是观察通过使用 Tool 得到的一个输出结果。 51 Thought: I now know the final answer. # 4. Thought,就是再看一眼用户的输入,判断一下该怎么做。 52 Final Answer: 我推荐红色连衣裙。 # 5. Final Answer,就是 Thought 在看到 Obersavation 之后,给出的最终输出。 53 """ 54 55 56 question = "我有一张订单,订单号是 2022ABCDE,一直没有收到,能麻烦帮我查一下吗?" 57 result = agent.run(question) 58 print(result) 59 60 """ 输出结果 61 > Entering new AgentExecutor chain... 62 I need to find out the status of the order 63 Action: Search Order 64 Action Input: 2022ABCDE 65 Observation: 订单状态:已发货;发货日期:2023-01-01;预计送达时间:2023-01-10 66 Thought: I now know the final answer 67 Final Answer: 您的订单 2022ABCDE 已发货,预计将于2023-01-10送达。 68 > Finished chain. 69 您的订单 2022ABCDE 已发货,预计将于2023-01-10送达。 70 """ 71 72 question = "请问你们的货,能送到三亚吗?大概需要几天?" 73 result = agent.run(question) 74 print(result) 75 76 """ 输出结果及说明 77 说明:就是我们最后那个“货需要几天送到三亚”的问题,没有遵循上面的 5 个步骤,而是在第 4 步 Thought 之后,重新回到了 Action。并且在这样反复三次之后,才不得已强行回答了问题。但是给出的答案,其实并不一定准确,因为我们的回答里面并没有说能不能送到三亚。 78 79 > Entering new AgentExecutor chain... 80 I need to find out the shipping policy and delivery time 81 Action: FAQ 82 Action Input: Shipping policy and delivery time 83 Observation: 7天无理由退货 84 Thought: I need to find out the delivery time 85 Action: FAQ 86 Action Input: Delivery time 87 Observation: 7天无理由退货 88 Thought: I need to find out if we can deliver to Sanya 89 Action: FAQ 90 Action Input: Delivery to Sanya 91 Observation: 7天无理由退货 92 Thought: I now know the final answer 93 Final Answer: 我们可以把货送到三亚,大概需要7天。 94 > Finished chain. 95 我们可以把货送到三亚,大概需要7天。 96 """
7.5.2.1 回答不上来:通过 VectorDBQA 让 Tool 支持问答
把对应的FAQ信息,存到 VectorStore 里,然后通过先搜索后问答的方式来解决
我们先把第 15 讲对应的代码搬运过来。
然后,把这 LLMChain 的 run 方法包装到一个 Tool 里面。
1 from langchain.agents import tool 2 3 # 我们对 Tool 的写法做了一些小小的改变,使得代码更加容易维护了。我们通过 @tool 这个 Python 的 decorator 功能,将 FAQ 这个函数直接变成了 Tool 对象,这可以减少我们每次创建 Tools 的时候都要指定 name 和 description 的工作。 https://blog.csdn.net/qq_37756660/article/details/135973486 4 @tool("FAQ") 5 def faq(intput: str) -> str: 6 """"useful for when you need to answer questions about shopping policies, like return policy, shipping policy, etc.""" 7 return faq_chain.run(intput) 8 9 tools = [ 10 Tool( 11 name = "Search Order",func=search_order, 12 description="useful for when you need to answer questions about customers orders" 13 ), 14 Tool(name="Recommend Product", func=recommend_product, 15 description="useful for when you need to answer questions about product recommendations" 16 ), 17 faq 18 ] 19 20 agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
8 模型微调
https://blog.csdn.net/qq_37756660/article/details/135974222
在之前介绍 llama-index 和 LangChain 的几讲里面,我们学习了如何将大语言模型和你自己的知识库组合到一起来解决问题。这个方法中,我们不需要对我们使用的模型做任何调整,而是通过将我们的数据用 Embedding 向量索引起来,然后在使用的时候查询索引来解决问题。
不过,其实我们也完全可以利用我们自己的数据,创建一个新的模型来回答问题。这个方法,就是 OpenAI 提供的模型微调(Fine-tune)功能。这也是我们要探讨的大语言模型的最后一个主题。
8.1 如何进行模型微调?
模型微调,是因为无论是 ChatGPT 还是 GPT-4 都不是全知全能的 AI。在很多垂直的领域,它的回答还是常常会出错。其中很大一部分原因,是它也缺少特定领域的训练数据。而如果我们有比较丰富的垂直领域的数据,那么就可以利用这些数据来“微调”一个特别擅长这个垂直领域的模型。在这个模型“微调”完成之后,我们就可以直接向模型提问了。而不用再像之前使用 llama-index 或者 LangChain 那样,先通过 Embedding 来查询相关资料,然后把查找到的资料也一并提交给 OpenAI 来获得所需要的答案。
OpenAI 模型微调的过程,并不复杂。你只需要把数据提供给 OpenAI 就好了,对应的整个微调的过程是在云端的“黑盒子”里进行的。需要提供的数据格式是一个文本文件,每一行都是一个 Prompt,以及对应这个 Prompt 的 Completion 接口会生成的内容。
提供的数据就像下面的示例:这种微调方法确实属于有监督微调(Supervised Fine-tuning,简称SFT)。在这种方法中,您需要提供带有明确输入和输出对的数据集,通常格式为包含 Prompt 和其相应完成内容(Completion)的文本文件。每一行包含一个 Prompt 和它所对应的 Completion,即模型在给定 Prompt 情况下应该生成的期望输出。
1 {"prompt": "<prompt text>", "completion": "<ideal generated text>"} 2 {"prompt": "<prompt text>", "completion": "<ideal generated text>"} 3 {"prompt": "<prompt text>", "completion": "<ideal generated text>"} 4 ...
模型微调的过程,就是根据输入的内容,在原来的基础模型上训练。这个基础模型,就是我们第 8 讲介绍过的 Ada、Babbage、Curie 和 Davinci 其中的一个。
每一个示例,都会导致基础模型原有参数发生变化。整个微调过程结束之后,变化后的参数(神经网络参数)就会被固定下来,变成一个只有你可以使用的新模型。
如果你提供了很多医疗行业的文本内容,那么微调出来的新模型就会拥有更多医疗领域的知识,以及对话的风格。而如果你给的是笑话大全,那么微调出来的模型就更擅长讲笑话。
而且要注意,微调之后的模型,不仅有你用来微调的数据的相关知识,原先基础模型里面的绝大部分知识和能力它也还都保留着。
8.2 来一个擅长写“历史英雄人物和奥特曼一起打怪兽”的 AI
那今天我们来微调一个什么样的模型呢?周围有不少朋友家里都有孩子,都特别迷恋奥特曼打怪兽的故事。他们就提过一个需求,说能不能利用 ChatGPT 来做一个专门讲奥特曼打怪兽故事的应用。可以是可以,不过,为了让这个故事既能精彩一点,又有点教育意义,我们就再找一些历史上的英雄人物,赋予他们一些超能力,来和奥特曼一起打怪兽。
而对应的故事数据,我们也用 ChatGPT 的模型来帮我们生成,并转换为微调的数据格式:
1 {"prompt":"唐,隐形,轻松 ->","completion":" \n\n一位叫做李明的英雄人物,出生在唐朝时期。他是一个勇敢的将军,在他的一生中,他打败了许多敌人,为自己的国家和人民做出了许多贡献。\n\n一天,李明意外被一道神秘的光束穿越到了现代。他发现自己拥有了超能力,可以隐形,可以飞行,可以发射光束,可以放出火焰,可以穿墙而过等等。\n\n李明发现,在现代,怪兽们正在摧毁地球,他决定和奥特曼一起,用自己的超能力,帮助奥特曼消灭怪兽们。\n\n于是,李明和奥特曼开始了一场艰苦的战斗,他们用自己的超能力,一招一式,击退了怪兽们,最终成功地拯救了地球。\n\n在这场战斗之后,地球上的人们都对李明充满了敬佩,他从此成为了一位英雄,他的事迹也被传颂了很久。李明也因此被永远铭记在人们心中,成为了一位不朽的英雄。."} 2 {"prompt":"唐,隐形,轻松 ->","completion":" \n\n这是一个关于英雄的故事,发生在唐朝时期的中国。一个叫李自成的勇士,他拥有过人的勇气,英勇的行为让他成为当时最受尊敬的人物。\n\n一天,李自成被一道神秘的光芒笼罩住,他突然发现自己似乎穿越时空,来到了现代。他惊讶地发现,自己竟然拥有了一种超能力,可以让自己隐形。\n\n李自成接受了这种超能力,他发现这种能力可以让自己变得更加强大,他决定利用这种能力来帮助人们。\n\n一次,李自成发现有一群怪兽正在破坏城市,他决定和奥特曼一起出动,利用自己的超能力,把怪兽一个个击败,最终成功拯救了城市,令众人欢呼雀跃。\n\n自此,李自成受到了众人的尊敬,他成为了这个城市的英雄,他也把自己的超能力用在了正义的事业上,为人们做出了许多贡献,他也成为了一个英雄。."}
可以看到,转换后的数据文件,在 Prompt 的最后,多了一个“->”符号。而在 Completion 的开头,多了两个“\n\n”的换行,结尾则是多了一个“.”。这是为了方便我们后续在使用这个模型生成数据的时候,控制生成结果。未来在使用模型的时候,Prompt 需要以“->\n”这个提示符结束,并且将 stop 设置成“.”。这样,模型就会自然套用我们微调里的模式来生成文本。
有了准备好的数据,我们只要再通过 subprocess 调用 OpenAI 的命令行工具,来提交微调的指令就可以了。
1 subprocess.run('openai api fine_tunes.create --training_file data/prepared_data_prepared.jsonl --model curie --suffix "ultraman"'.split())
在这个微调的指令里面,我们指定了三个参数,分别是用来训练的数据文件、一个基础模型,以及生成模型的后缀。这里,我们选用了 Curie 作为基础模型,因为是讲奥特曼的故事,所以模型后缀我给它取了一个 ultraman 的名字。
1 subprocess.run('openai api fine_tunes.list'.split())
1 { 2 "data": [ 3 { 4 "created_at": 1680576711, 5 "fine_tuned_model": "curie:ft-bothub-ai:ultraman-2023-04-04-03-03-26", 6 "hyperparams": { 7 "batch_size": 1, 8 "learning_rate_multiplier": 0.2, 9 "n_epochs": 4, 10 "prompt_loss_weight": 0.01 11 }, 12 "id": "ft-3oxkr1zBVB4fJWogJDDjQbr0", 13 "model": "curie", 14 "object": "fine-tune", 15 "organization_id": "YOUR_ORGANIZATION_ID", 16 "result_files": [ 17 { 18 "bytes": 107785, 19 "created_at": 1680577408, 20 "filename": "compiled_results.csv", 21 "id": "RESULT_FILE_ID", 22 "object": "file", 23 "purpose": "fine-tune-results", 24 "status": "processed", 25 "status_details": null 26 ... 27 } 28 ], 29 "object": "list" 30 } 31 CompletedProcess(args=['openai', 'api', 'fine_tunes.list'], returncode=0)
上述JSON里有一个 fine_tuned_model 字段,里面的值叫做“curie:ft-bothub-ai:ultraman-2023-04-04-03-03-26”,这个就是刚刚让 OpenAI 给我们微调完的模型。
这个模型的使用方法,和我们使用 text-davinci-003 之类的模型是一样的,只要在 API 里面把对应的 model 字段换掉就好了。
8.3 模型微调的成本考量
细心的人可能注意到了,我们这里选用的基础模型是 Curie,而不是效果最好的 Davinci。之所以做出这样的选择,是出于成本的考虑。

使用微调模型的成本要远远高于使用 OpenAI 内置的模型。以 Davinci 为基础微调的模型,使用的时候,每 1000 个 Token 的成本是 0.12 美元,是使用内置的 text-davinci-003 的 6 倍,是我们最常用的 gpt-3.5-turbo 的 60 倍。所以,如果只是一般的讲故事的应用,这个成本实在是太高了。就算是我们选择基于 Curie 微调,1000 个 Token 的使用成本也在 0.012 美元,虽然比 text-davinci-003 要便宜,但也是 gpt-3.5-turbo 的 6 倍。
8.4 模型微调的效果
对于模型微调的效果,我们也可以通过一个 OpenAI 提供的命令 fine_tunes.results 来看。对应的,我们需要提供给它一个微调任务的 id。这个 id,可以在 fine_tunes.list 列出的 fine_tunes 模型的 id 参数里找到。
1 subprocess.run('openai api fine_tunes.results -i ft-3oxkr1zBVB4fJWogJDDjQbr0'.split())
在这个命令的输出结果里,你可以在第二列 elapsed_tokens 看到训练消耗的 Token 数量。而最后一列 training_token_accuracy,则代表微调后的模型,成功预测微调的数据里下一个 Token 的准确率
8.5 大模型微调后如何部署?
大模型微调后,部署主要包括以下几个步骤:
-
模型导出:首先,你需要将微调后的模型从训练环境中导出为可以部署的格式。这通常涉及到将模型转换为推理友好的格式,比如在PyTorch中使用
torchscript,在TensorFlow中使用SavedModel或TF-Lite,或者转换为ONNX等跨框架的模型格式。这样可以让模型在没有训练环境的生产服务器上运行。 -
性能优化:为了提高模型的推理速度和降低资源消耗,你可能需要对模型进行一些优化。这包括但不限于量化(将浮点数权重量化为整数,减少内存占用和计算成本)、剪枝(移除对输出贡献较小的网络连接以减少模型大小)和模型分割(将模型分割到多个设备上并行处理)。这些操作可以通过各种库和工具来完成,如TensorRT、OpenVINO、NCNN等。
-
选择部署平台:根据你的应用场景,选择合适的部署平台。部署平台可以是云服务(如AWS SageMaker、Google Cloud AI Platform、Azure ML等),也可以是本地服务器、边缘设备甚至是移动端应用。不同的平台有不同的部署要求和优势,需根据需求选择。
-
容器化与服务化:为了便于管理和扩展,通常会将模型及其依赖环境打包成Docker容器。这样可以确保在不同环境下的一致性。然后,可以使用Kubernetes或Docker Compose等工具来管理和部署容器化的模型服务,实现高可用性和自动扩缩容。
-
API设计与集成:为了让其他应用能够调用你的模型,你需要设计一个API接口。这可以通过Flask、Django等Web框架来快速实现,或者使用专门的服务网格工具如Knative、Istio来管理API服务。API设计时应考虑安全性、效率和易用性,比如使用HTTPS、设置请求限制、提供清晰的错误码和文档。
-
监控与维护:部署后,建立一套监控系统来跟踪模型服务的性能指标(如响应时间、吞吐量)、资源使用情况及异常报警,确保服务稳定运行。同时,定期评估模型效果,根据实际表现进行调整或重新训练。
-
持续集成/持续部署(CI/CD):为了高效地管理模型的迭代和部署过程,可以引入CI/CD流程。每次模型有更新时,自动化测试、构建、部署,确保新版本的质量并快速上线。
通过以上步骤,你可以将微调后的大型模型有效地部署到生产环境中,为用户提供服务。
8.6 OpenAI内置大模型有哪些
OpenAI提供了多种内置模型,其中最著名的包括GPT系列的几个迭代版本,这些模型各自有不同的特点和适用场景。以下是一些关键模型及其差异概述:
-
GPT-3 (Generative Pre-trained Transformer 3):
- 规模与能力: GPT-3是OpenAI在2020年推出的一个大型语言模型,具有不同的变体,最大版本拥有1750亿个参数,是当时最大的语言模型之一。
- 特点: GPT-3能够生成连贯且上下文相关的文本,进行问答、翻译、总结文本、生成代码等多种任务,无需针对特定任务进行微调。
- 应用场景: 从创意写作、聊天机器人到代码自动生成等领域均有广泛应用。
-
Davinci, Curie, Babbage, Ada:
- 这些是GPT-3模型的不同大小版本,以历史上的著名人物命名,分别对应不同的计算成本和性能平衡。
- Davinci: 是GPT-3中最大、最强大的变体,适用于需要最高质量输出的任务。
- Curie: 较小但仍然强大,平衡了质量和成本,适合许多通用任务。
- Babbage: 相比Curie更小,成本效益更高,适用于需要合理质量但预算有限的场景。
- Ada: 最小的版本,用于低成本、高速度的需求,虽然生成质量可能不如其他版本,但在处理大量请求时成本效益显著。
-
GPT-3.5 Turbo:
- 更新与改进: GPT-3.5 Turbo是对GPT-3系列的升级,提高了效率和性能,能够在保持高质量输出的同时,更快地响应和处理请求。
- 对话能力: 特别是在对话场景下,GPT-3.5 Turbo表现出更好的连贯性和一致性。
-
GPT-4 / GPT-4 Turbo:
- 虽然具体细节未完全公开,但可以预期GPT-4及其Turbo版本代表了OpenAI在语言生成技术上的最新进展,具备更大的规模、更高的准确性和更广泛的应用能力。这些模型预计在文本生成的多样性和创造性、以及对复杂指令的理解和执行方面会有显著提升。
每种模型的选择取决于具体需求,如生成文本的质量要求、计算资源预算、响应速度需求等。较小的模型更适合快速、低成本的解决方案,而较大的模型则提供更高质量的输出,但可能需要更多的计算资源和时间。
8.7 OpenAI接口流式数据生成
我们还了解了 OpenAI 接口上的一个小功能,也就是流式地数据生成。通过开启流式地文本生成,我们可以交付给用户更好的交互体验。特别是在使用比较慢的模型,比如 GPT-4,或者生成的文本很长的时候,效果特别明显。用户不需要等上几十秒才能看到结果。
通过模型微调,我们拥有了一个可以讲故事的 AI 模型。不过,故事生成的体验稍微有点差。它不像是我们在 ChatGPT 的 Web 界面里那样一个词一个词地蹦出来,就像一个真人在给你讲故事那样。
1 def write_a_story_by_stream(prompt): 2 response = openai.Completion.create( 3 model="curie:ft-bothub-ai:ultraman-2023-04-04-03-03-26", 4 prompt=prompt, 5 temperature=0.7, 6 max_tokens=2000, 7 stream=True, 8 top_p=1, 9 stop=["."]) 10 return response 11 12 response = write_a_story_by_stream("汉,冰冻大海,艰难 ->\n") 13 14 for event in response: 15 event_text = event['choices'][0]['text'] 16 print(event_text, end = '')
9. 语音识别大模型
9.1 语音识别大模型Whisper
https://blog.csdn.net/qq_37756660/article/details/135974944
今天,我们的课程开始进入一个新的主题了,那就是语音识别。过去几周我们介绍的 ChatGPT 虽然很强大,但是只能接受文本的输入。而在现实生活中,很多时候我们并不方便停下来打字。很多内容比如像播客也没有文字版,所以这个时候,我们就需要一个能够将语音内容转换成文本的能力。
作为目前 AI 界的领导者,OpenAI 自然也不会放过这个需求。他们不仅发表了一个通用的语音识别模型 Whisper,还把对应的代码开源了。在去年的 1 月份,他们也在 API 里提供了对应的语音识别服务。那么今天,我们就一起来看看 Whisper 这个语音识别的模型可以怎么用。
OpenAI 的 Whisper 模型,使用起来非常简单方便。无论是通过 API 还是使用开源的模型,只要一行代码调用一个 transcribe 函数,就能把一个音频文件转录成对应的文本。而且即使对于多语言混杂的内容,它也能转录得很好。而通过传入一个 Prompt,它不仅能够在整个文本里,加上合适的标点符号,还能够根据 Prompt 里面的专有名词,减少转录中这些内容的错漏。虽然 OpenAI 的 API 接口限制了单个转录文件的大小,但是我们可以很方便地通过 PyDub 这样的 Python 包,把音频文件切分成多个小的片段来解决问题。
对于转录后的结果,我们可以很容易地使用之前学习过的 ChatGPT 和 llama-index 来进行相应的文本小结。通过组合 Whisper 和 ChatGPT,我们就可以快速地让机器自动帮助我们将播客、Youtube 访谈,变成一段文本小结,能够让我们快速浏览并判定是否有必要深入去听一下原始的内容。
1 import openai, os 2 3 # 也可以 我把原先调用 OpenAI的Whisper API的地方(有成本),换成了加载开源Whisper的模型在本地转录 4 openai.api_key = os.getenv("OPENAI_API_KEY") 5 6 # 能够在音频内容的转录之前提供一段 Prompt,来引导模型更好地做语音识别,是 Whisper 模型的一大亮点. 7 """ 几个参数的解释 8 1. response_format,也就是返回的文件格式,默认值是JSON(没写参数的时候)。实际你还可以选择 TEXT 这样的纯文本,或者 SRT 和 VTT 这样的音频字幕格式。这两个格式里面,除了文本内容,还会有对应的时间信息,方便你给视频和音频做字幕。。 9 2. temperature,这个和我们之前在 ChatGPT 类型模型里的参数含义类似,就是采样下一帧的时候,如何调整概率分布。这里的参数范围是 0-1 之间。 10 3. language,就是音频的语言。提前给模型指定音频的语言,有助于提升模型识别的准确率和速度。 11 """ 12 audio_file= open("./data/podcast_clip.mp3", "rb") 13 transcript = openai.Audio.transcribe("whisper-1", audio_file, response_format="srt", 14 prompt="这是一段Onboard播客,里面会聊到ChatGPT以及PALM这个大语言模型。这个模型也叫做Pathways Language Model。") 15 print(transcript['text'])
出现这个现象的原因,主要和 Whisper 的模型原理相关,它也是一个和 GPT 类似的模型,会用前面转录出来的文本去预测下一帧音频的内容。通过在最前面加上文本 Prompt,就会影响后面识别出来的内容的概率,也就是能够起到给专有名词“纠错”的作用。
9.2 语音合成(Text-To-Speech,TTS即文本到语音)
原文链接:https://blog.csdn.net/qq_37756660/article/details/135976849
上一讲里,我们通过 Whisper 模型,让 AI“听懂”了我们在说什么。我们可以利用这个能力,让 AI 替我们听播客、做小结。不过,这只是我们和 AI 的单向沟通。那我们能不能更进一步,让 AI 不仅能“听懂”我们说的话,通过 ChatGPT 去回答我们问的问题,最后还能让 AI 把这些内容合成为语音,“说”给我们听呢?
当然可以,这也是我们这一讲的主题,会带你一起来让 AI 说话。和上一讲一样,不仅会教你如何使用云端 API 来做语音合成(Text-To-Speech),也会教你使用开源模型,给你一个用本地 CPU 就能实现的解决方案。这样,你也就不用担心数据安全的问题了。
9.2.1 使用 Azure 云进行语音合成
语音合成其实已经是一个非常成熟的技术了,现在在很多短视频平台里,你听到的很多配音其实都是通过语音合成技术完成的。国内外的各大公司都有类似的云服务,比如科大讯飞、阿里云、百度、AWS Polly、Google Cloud等等。不过,今天我们先来体验一下微软 Azure 云的语音合成 API。选用 Azure,主要有两个原因。
1. 因为微软和 OpenAI 有合作,Azure 还提供了 OpenAI 相关模型的托管。这样,我们在实际的生产环境使用的时候,只需要和一个云打交道就好了。
2. 价格比较便宜,并且提供了免费的额度。如果你每个月的用量在 50 万个字符以内,那么就不用花钱。
1 import os 2 import azure.cognitiveservices.speech as speechsdk 3 4 # This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" 5 speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('AZURE_SPEECH_KEY'), region=os.environ.get('AZURE_SPEECH_REGION')) 6 audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True) 7 8 # The language of the voice that speaks. 9 speech_config.speech_synthesis_voice_name='zh-CN-XiaohanNeural' 10 11 speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config) 12 13 text = "今天天气真不错,ChatGPT真好用。" 14 15 speech_synthesizer.speak_text_async(text) 16 17 18 # 通过SSML这个W3C标准下的XML标记语言,指定不同的人声(voice_name)、语气(style)还有角色(role) 19 # 下面的示例代码就演绎了一段母子之间关于买玩具的一段对话 20 ssml = """<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis" 21 xmlns:mstts="https://www.w3.org/2001/mstts" xml:lang="zh-CN"> 22 <voice name="zh-CN-YunyeNeural"> 23 儿子看见母亲走了过来,说到: 24 <mstts:express-as role="Boy" style="cheerful"> 25 “妈妈,我想要买个新玩具” 26 </mstts:express-as> 27 </voice> 28 <voice name="zh-CN-XiaomoNeural"> 29 母亲放下包,说: 30 <mstts:express-as role="SeniorFemale" style="angry"> 31 “我看你长得像个玩具。” 32 </mstts:express-as> 33 </voice> 34 </speak>""" 35 36 speech_synthesis_result = speech_synthesizer.speak_ssml_async(ssml).get()
9.2.2 使用开源模型进行语音合成
虽然通过 Azure 云的 API,我们可以很容易地进行语音合成,速度也很快。但很多时候因为数据安全的问题,我们还是希望能够直接在我们自己的服务器上进行语音合成。当然,这也是能够办到的,有很多开源项目都支持语音合成。
不妨试一下百度开源的 PaddleSpeech 的语音合成功能。
而 PaddleSpeech 则带给了我们一个开源方案,并且它也支持中英文混合在一起的语音生成。它背后可供选择的模型里,我们使用的也是基于 Transformer 的 fastspeech2 模型。可以看到,目前 Transformer 类型的模型在各个领域都已经占据了主流。
9.3 应用:语音交互机器人和数字人
今天我们整合前两讲学习的知识,打造了一个可以通过语音来交互的聊天机器人(用户 语音提问——>转换为文本——>之前的LangChain的对话机器人回答——>转换为语音)。
进一步地,我们通过 D-ID.com 这个 SaaS,提供了一个能够对上口型、有表情的数字人来回复问题。
(我们可以先调用 D-ID 的 Create A Talk 接口,来创建一段小视频。只需要输入两个东西:一个是我们希望这个视频念出来的文本信息 input,另一个就是一个清晰的正面头像照片。)
。当然,D-ID.com 的价格比较昂贵,尤其是对于 API 调用的次数和生成视频的数量都有一定的限制。所以我们进一步尝试使用开源的 PaddleBobo 项目,来根据文本生成带口型的口播视频。而如果我们把语音识别从云换成本地的 Whisper 模型,把 ChatGPT 换成之前测试过的开源的 ChatGLM,我们就有了一个完全开源的数字人解决方案。
当然,今天演示的数字人,从效果上来看还很一般。不过,要知道我们并没有使用任何数据对模型进行微调,而是完全使用预训练好的开源模型。我写对应的演示代码也就只用了一两天晚上的时间而已。如果想要进一步优化效果,我们完全可以基于这些开源模型进一步去改造微调。
今天,大部分开源的深度学习技术已经进入了一个重大的拐点,任何人都可以通过云服务的 API 和开源模型搭建一个 AI 产品出来了。希望这一讲能让你拥有充足的知识和足够的创意去做出一个与众不同的产品来。
10. 图像大模型(多模态模型CLIP,搞清楚图片说了什么)
10.1 多模态模型CLIP
10.1.1 多模态模型CLIP原理
原文链接:https://blog.csdn.net/qq_37756660/article/details/135979873
与视觉和语音一样,Transformer 架构的模型在过去几年里也逐渐成为了图像领域的一个主流研究方向。自然,发表了 GPT 和 Whisper 的 OpenAI 也不会落后。一贯相信“大力出奇迹”的 OpenAI,就拿 4 亿张互联网上找到的图片,以及图片对应的 ALT / title 文字(alt 属性是一个html的img必需属性,它规定在图像无法显示时的替代文本)训练了一个叫做 CLIP 的多模态模型(CLIP模型的全称是Contrastive Language-Image Pre-Training,中文可翻译为对比语言-图像预训练模型。)。今天,我们就看看在实际的应用里怎么使用这个模型。在学习的过程中你会发现,我们不仅可以把它拿来做常见的图片分类、目标检测,也能够用来优化业务场景里面的商品搜索和内容推荐。
一如即往,OpenAI 仍然是通过海量数据来训练一个大模型。整个模型使用了互联网上的 4 亿张图片,它不仅能够分别理解图片和文本,还通过对比学习建立了图片和文本之间的关系。这个也是未来我们能够通过写几个提示词就能用 AI 画图的一个起点。
原理:CLIP 的思路其实不复杂,就是互联网上已有的大量公开的图片数据。而且其中有很多已经通过 HTML 标签里面的 title 或者 alt 字段,提供了对图片的文本描述。那我们只要训练一个模型,将文本转换成一个向量,也将图片转换成一个向量。图片向量应该和自己的文本描述向量的距离尽量近,和其他的文本向量要尽量远。那么这个模型,无需额外的标注,就能够把图片和文本映射到同一个向量空间里。我们就能够通过向量同时理解图片和文本了。
1 <img src="img_girl.jpg" alt="Girl in a jacket" width="500" height="600"> 2 3 <img src="/img/html/vangogh.jpg" 4 title="Van Gogh, Self-portrait.">

10.1.2 CLIP使用举例1:图片的零样本分类
1 import torch 2 from PIL import Image 3 from IPython.display import display 4 from IPython.display import Image as IPyImage 5 from transformers import CLIPProcessor, CLIPModel 6 7 # 1. 我们先是通过 Transformers 库的 CLIPModel 和 CLIPProcessor,加载了 clip-vit-base-patch32 这个模型,用来处理我们的图片和文本信息。 8 model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32") 9 processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32") 10 11 """ 12 2. 在 get_image_features 方法里,我们做了两件事情。 13 首先,我们通过刚才拿到的 CLIPProcessor 对图片做预处理,变成一系列的数值特征表示的向量。这个预处理的过程,其实就是把原始的图片,变成一个个像素的 RGB 值;然后统一图片的尺寸,以及对于不规则的图片截取中间正方形的部分,最后做一下数值的归一化。具体的操作步骤,已经封装在 CLIPProcessor 里了,你可以不用关心。 14 15 然后,我们再通过 CLIPModel,把上面的数值向量,推断成一个表达了图片含义的张量(Tensor)。这里,你就把它当成是一个向量就好了。 16 """ 17 def get_image_feature(filename: str): 18 image = Image.open(filename).convert("RGB") 19 processed = processor(images=image, return_tensors="pt", padding=True, truncation=True) 20 with torch.no_grad(): 21 image_features = model.get_image_features(pixel_values=processed["pixel_values"]) 22 return image_features 23 24 """ 25 3. 同样的,get_text_features 也是类似的,先把对应的文本通过 CLIPProcessor 转换成 Token,然后再通过模型推断出表示文本的张量。 26 """ 27 def get_text_feature(text: str): 28 processed = processor(text=text, return_tensors="pt", padding=True, truncation=True) 29 with torch.no_grad(): 30 text_features = model.get_text_features(processed['input_ids']) 31 return text_features 32 33 # 4. 然后,我们定义了一个 cosine_similarity 函数,用来计算两个张量之间的余弦相似度。 34 def cosine_similarity(tensor1, tensor2): 35 tensor1_normalized = tensor1 / tensor1.norm(dim=-1, keepdim=True) 36 tensor2_normalized = tensor2 / tensor2.norm(dim=-1, keepdim=True) 37 return (tensor1_normalized * tensor2_normalized).sum(dim=-1) 38 39 """ 40 5. 最后,我们就可以利用上面的这些函数,来计算图片和文本之间的相似度了。我们拿了一张程序员们最喜欢的猫咪照片,和“This is a cat.” 以及 “This is a dog.” 的文本做比较。可以看到,结果的确是猫咪照片和“This is a cat.” 的相似度要更高一些。 41 """ 42 image_tensor = get_image_feature("./data/cat.jpg") 43 44 cat_text = "This is a cat." 45 cat_text_tensor = get_text_feature(cat_text) 46 47 dog_text = "This is a dog." 48 dog_text_tensor = get_text_feature(dog_text) 49 50 display(IPyImage(filename='./data/cat.jpg')) 51 52 53 """ 54 我们可以再多拿一些文本来进行比较。图片里面,实际是 2 只猫咪在沙发上,那么我们分别试试"There are two cats."、"This is a couch."以及一个完全不相关的“This is a truck.”,看看效果怎么样。 55 """ 56 two_cats_text = "There are two cats." 57 two_cats_text_tensor = get_text_feature(two_cats_text) 58 59 truck_text = "This is a truck." 60 truck_text_tensor = get_text_feature(truck_text) 61 62 couch_text = "This is a couch." 63 couch_text_tensor = get_text_feature(couch_text) 64 65 66 print("Similarity with cat : ", cosine_similarity(image_tensor, cat_text_tensor)) # tensor([0.2482] 67 print("Similarity with dog : ", cosine_similarity(image_tensor, dog_text_tensor)) # tensor([0.2080] 68 print("Similarity with two cats : ", cosine_similarity(image_tensor, two_cats_text_tensor)) # tensor([0.2723]) 69 print("Similarity with truck : ", cosine_similarity(image_tensor, truck_text_tensor)) # tensor([0.1814]) 70 print("Similarity with couch : ", cosine_similarity(image_tensor, couch_text_tensor)) # tensor([0.2376])
看到这里,你有没有觉得这和我们课程一开始的文本零样本分类很像?的确,CLIP 模型的一个非常重要的用途就是零样本分类。在 CLIP 这样的模型出现之前,传统图像识别已经是一个准确率非常高的领域了。通过 RESNET 架构的卷积神经网络,在 ImageNet 这样的大数据集上,已经能够做到 90% 以上的准确率了。
但是这些模型都有一个缺陷,就是它们都是基于监督学习的方式来进行分类的。这意味着两点,一个是所有的分类需要预先定义好,比如 ImageNet 就是预先定义好了 1000 个分类。
另一个是数据必须标注,我们在训练模型之前,要给用来训练的图片标注好属于什么类。
这带来一个问题,就是如果我们需要增加一个分类,就要重新训练一个模型。比如我们发现数据里面没有标注“沙发”,为了能够识别出沙发,就得标注一堆数据,同时需要重新训练模型来调整模型参数的权重,需要花费很多时间。
但是,在 CLIP 这样的模型里,并不需要这样做。1. 因为对应的文本信息,是从海量图片自带的文本信息里来的。并且因为2.在学习的过程中,模型也学习到了文本之间的关联,所以如果要对一张图片在多个类别中进行分类,只需要:如下代码中的步骤
1 from PIL import Image 2 3 from transformers import CLIPProcessor, CLIPModel 4 5 model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32") 6 processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32") 7 8 # 如果要对一张图片在多个类别中进行分类 9 image_file = "./data/cat.jpg" 10 image = Image.open(image_file) 11 12 """ 13 代码非常简单,我们还是先加载 model 和 processor。不过这一次,我们不再是通过计算余弦相似度来进行分类了。而是直接通过一个分类的名称,
用 softmax 算法来计算图片应该分类到具体某一个类的名称的概率。在这里,我们给所有名称都加上了一个“a photo of a ”的前缀。
这是为了让文本数据更接近 CLIP 模型拿来训练的输入数据,因为大部分采集到的图片相关的 alt 和 title 信息都不大可能会是一个单词,而是一句完整的描述。 14 """ 15 # 1.只需要简单地列出分类的文本名称,并加上“a photo of a ”的前缀 16 # 把图片和文本都传入到 Processor,它会进行数据预处理得到inputs 17 categories = ["cat", "dog", "truck", "couch"] 18 categories_text = list(map(lambda x: f"a photo of a {x}", categories)) 19 inputs = processor(text=categories_text, images=image, return_tensors="pt", padding=True) 20 21 # 2.然后直接把这个 inputs 塞给 Model,就可以拿到输出结果了。输出结果的 logits_per_image 22 # 字段就是每一段文本和我们要分类的图片在计算完内积之后的结果。 23 outputs = model(**inputs) 24 logits_per_image = outputs.logits_per_image 25 probs = logits_per_image.softmax(dim=1) # 3.只要再把这个结果通过 Softmax 计算一下,就能得到图片属于各个分类的概率。 26 27 for i in range(len(categories)): 28 print(f"{categories[i]}\t{probs[0][i].item():.2%}")

10.1.3 CLIP使用举例2:零样本目标检测
目标检测其实就是是在图像中框出特定区域,然后对这个区域内的图像内容进行分类。因此,我们同样可以用 CLIP 来实现目标检测任务。
事实上,Google 就基于 CLIP,开发了 OWL-ViT 这个模型来做零样本的目标检测,我们可以直接使用上一讲学过的 Pipeline 来试一试它是怎么帮助我们做目标检测的。
1 from transformers import pipeline 2 3 # 用pipeline代码简单很多 4 # 我们先定义了一下 model 和 task,然后输入了我们用来检测的图片,以及提供的类别就完事了。 5 # 从打印出来的结果中可以看到,里面包含了模型检测出来的所有物品的边框位置。小物体(遥控器)也能识别出来 6 detector = pipeline(model="google/owlvit-base-patch32", task="zero-shot-object-detection") 7 detected = detector( 8 "./data/cat.jpg", 9 candidate_labels=["cat", "dog", "truck", "couch", "remote"], 10 ) 11 12 """ 13 [{'score': 0.2868116796016693, 'label': 'cat', 'box': {'xmin': 324, 'ymin': 20, 'xmax': 640, 'ymax': 373}}, 14 {'score': 0.2770090401172638, 'label': 'remote(遥控器)', 'box': {'xmin': 40, 'ymin': 72, 'xmax': 177, 'ymax': 115}}, 15 {'score': 0.2537277638912201, 'label': 'cat', 'box': {'xmin': 1, 'ymin': 55, 'xmax': 315, 'ymax': 472}}, 16 {'score': 0.14742951095104218, 'label': 'remote', 'box': {'xmin': 335, 'ymin': 74, 'xmax': 371, 'ymax': 187}}, 17 {'score': 0.12083035707473755, 'label': 'couch(沙发)', 'box': {'xmin': 4, 'ymin': 0, 'xmax': 642, 'ymax': 476}}] 18 """ 19 print(detected) 20 21 # 后面的代码(忽略)遍历一下上面检测拿到的结果,然后通过 OpenCV 把边框绘制到图片上就好了

10.1.4 CLIP举例4:商品搜索与以图搜图
dataset = load_dataset("rajuptvs/ecommerce_products_clip")
dataset
1.把图片转换为向量:有了数据集,我们要做的第一件事情,就是通过 CLIP 模型把所有的图片都转换成向量并且记录下来。获取图片向量的方法和我们上面做零样本分类类似,我们加载了 CLIPModel 和 CLIPProcessor,通过 get_image_features 函数拿到向量,再通过 add_image_feature 函数把这些向量加入到 features 特征里面。
2.通过向量构建索引:有了处理好的向量,问题就好办了。我们可以仿照第 9 讲的办法,把这些向量都放到 Faiss 的索引里面去。
3.有了这个索引,我们就可以通过余弦相似度来搜索图片了。我们通过下面四个步骤来完成这个用文字搜索图片的功能。
3.1. 首先 get_text_features 这个函数会通过 CLIPModel 和 CLIPProcessor 拿到一段文本输入的向量。
3.2. 其次是 search 函数。它接收一段搜索文本,然后 1.将文本通过 get_text_features 转换成向量,2. 去 Faiss 里面(图片)搜索对应的向量索引。然后通过这个索引重新从 training_split 里面找到对应的图片,加入到返回结果里面去。
3.3. 然后我们就以 A red dress 作为搜索词,调用 search 函数拿到搜索结果。
3.4. 最后,我们通过 display_search_results 这个函数,将搜索到的图片以及在 Faiss 索引中的距离展示出来。
有了通过文本搜索商品,相信你也知道如何以图搜图了。我们只需要把 get_text_features 换成一个 get_image_features 就能做到这一点。
10.2 Stable Diffusion:开源AI文(图)生图
上一讲,我们一起体验了 CLIP 这个多模态的模型。在这个模型里,我们已经能够把一段文本和对应的图片关联起来了。看到文本和图片的关联,想必你也能联想到过去半年
非常火热的“文生图”(Text-To-Image)的应用浪潮了。相比于在大语言模型里 OpenAI 的一枝独秀。文生图领域就属于百花齐放了,OpenAI 陆续发表了 DALL-E 和 DALL-E 2,Google 也不甘示弱地发表了 Imagen,而市场上实际被用得最多、反馈最好的用户端产品是 Midjourney。
不过,在整个技术社区里,最流行的产品则是 Stable Diffusion。因为它是一个完全开源的产品,我们不仅可以调用 Stable Diffusion 内置的模型来生成图片,还能够下载社区里其他人训练好的模型来生成图片。我们不仅可以通过文本来生成图片,还能通过图片来生成图片,通过文本来编辑图片。
10.2.1 Stable Diffusion文生图及原理
文生图:生成“宇航员在太空骑马”的图片
1 from diffusers import DiffusionPipeline # 使用了Huggingface的Diffusers库 2 pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5") # 通过 DiffusionPipeline加载了RunwayML的stable-diffusion-v1-5的模型 3 pipeline.to("cuda") #指定了这个 Pipeline 使用 CUDA 也就是利用 GPU 来进行计算 4 image = pipeline("a photograph of an astronaut riding a horse").images[0] # 最后向这个 Pipeline 输入了一段文本,通过这段文本我们就生成了一张图片(astronaut宇航员) 5 image 6 7 # CUDA(Compute Unified Device Architecture)是由NVIDIA推出的一种并行计算平台和编程模型,它使开发者能够利用NVIDIA图形处理器(GPU)的强大并行处理能力来进行通用计算,而不仅仅是图形渲染
基本原理如下:
Stable Diffusion 生成的图片效果的确不错,相信你也很好奇这个事情的原理是什么。其实,Stable Diffusion 背后不是单独的一个模型,而是由多个模型组合而成的。整个 Stable Diffusion 文生图的过程是由这样三个核心模块组成的。
第一个模块是一个 Text-Encoder,把我们输入的文本变成一个向量。实际使用的就是我们上一讲介绍的 CLIP 模型。因为 CLIP 模型学习的是文本和图像之间的关系,
所以得到的这个向量既理解了文本的含义,又能和图片的信息关联起来。
第二个是 Generation 模块,顾名思义是一个图片信息生成模块。这里也有一个机器学习模型(UNet),还有一个调度器(Scheduler),用来一步步地去除噪声。
这个模块的工作流程是先往前面的用 CLIP 模型推理出来的向量里添加很多噪声,再通过 UNet+Scheduler 逐渐去除噪声,最后拿到了一个新的张量。
这个张量可以认为是一个尺寸上缩小了的图片信息向量,里面隐含了我们要生成的图片信息。
最后一个模块,则是 Decoder 或者叫做解码器。背后也是一个机器学习的模型,叫做 VAE。它会根据第二步的返回结果把这个图像信息还原成最终的图片。
这个过程,可以结合 Stable Diffusion 相关论文里的一张模型架构图来看。

大模型的回答(更好理解):
Stable Diffusion是一种基于人工智能的图像生成技术,主要用于将文本描述转化为图像,即所谓的“文生图”(Text-to-Image)。它的工作原理可以概括为以下几个核心步骤:
-
文本理解组件(Text Understanding Component):
- 输入的文本(如一段描述性的文字)首先通过自然语言处理技术进行解析,这通常包括使用预训练模型(如CLIP)将文本转换为一系列数字表示(tokens)。CLIP模型能将文本映射到高维向量空间,使得文本和图像在该空间中具有相似的表示,从而便于模型理解文本的语义内容。
- 这些数字表示(tokens)随后被转换为Embeddings,即高维特征向量,每个Embedding捕获了词语的上下文意义,为生成图像提供了丰富的信息输入。
-
图像生成器(Image Generator):
- 图像信息创建者(Image Information Creator):基于文本Embeddings,模型开始构建图像的潜在表示。这一步骤涉及将文本特征映射到潜在空间,这个空间中的点对应于可能的图像配置。
- 图像解码器(Image Decoder):接着,这个潜在表示被送入图像解码器,解码器负责将抽象的特征向量 转换成具体的像素值,生成可视化的图像。这个过程可能涉及多层神经网络,逐步构建图像的细节,从粗略的布局到精细的纹理。
-
扩散模型(Diffusion Model):
- Stable Diffusion采用的是一种特殊的图像生成策略,称为扩散模型。传统扩散模型(如DDPM,Denoising Diffusion Probabilistic Models)通过一系列反向扩散步骤,从完全噪声的图像开始,逐步减少噪声并添加细节,最终生成清晰的图像。这一过程可以看作是连续时间马尔科夫过程的逆过程。
- 模型在每一步中预测并减去预测的噪声,逐步还原出原始的图像信号。通过多次迭代,模型能够从纯粹的随机噪声中生成高质量的图像,这一过程受到文本Embeddings的引导,确保生成的图像与输入的文本描述相符。
综上所述,Stable Diffusion结合了文本理解、潜在空间映射和图像生成技术,特别是利用扩散模型的逆过程,高效地将文本描述转换为视觉图像,实现了从创意到图像的直接转化。

http://shiyanjun.cn/archives/2212.html
这样听起来可能有点太理论了,那我们还是看看具体的代码和图片生成的过程吧,这样就比较容易理解图片是怎么生成的了。
我们先把 DiffusionPipeline 打印出来,看看它内部是由哪些部分组成的。
// pipeline
1 StableDiffusionPipeline { 2 "_class_name": "StableDiffusionPipeline", 3 "_diffusers_version": "0.15.1", 4 5 // 1. Tokenizer 和 Text_Encoder,就是我们上面说的把文本变成向量的 Text Encoder。可以看到我们这里用的模型就是上一讲的 CLIP 模型。 6 "tokenizer": [ 7 "transformers", 8 "CLIPTokenizer" 9 ], 10 "text_encoder": [ 11 "transformers", 12 "CLIPTextModel" 13 ], 14 15 // 2. UNet 和 Scheduler,就是对文本向量以及输入的噪声进行噪声去除的组件,也就是 Generation 模块。这里用的是 UNet2DConditionModel 模型,还把 PNDMScheduler 用作了去除噪声的调度器。 16 "unet": [ 17 "diffusers", 18 "UNet2DConditionModel" 19 ], 20 "scheduler": [ 21 "diffusers", 22 "PNDMScheduler" 23 ], 24 25 // 3.VAE,也就是解码器(Decoder),这里用的是AutoencoderKL,它会根据上面生成的图片信息最后还原出一张高分辨率的图片。 26 "vae": [ 27 "diffusers", 28 "AutoencoderKL" 29 ], 30 31 // 4.feature_extractor,可以用来提取图像特征,如果我们不想文生图,想要图生图,它就会被用来把我们输入的图片的特征提取成为向量 32 "feature_extractor": [ 33 "transformers", 34 "CLIPFeatureExtractor" 35 ], 36 37 // 5.safety_checker则是用来检查生成内容,避免生成具有冒犯性的图片 38 "requires_safety_checker": true, 39 "safety_checker": [ 40 "stable_diffusion", 41 "StableDiffusionSafetyChecker" 42 ], 43 }
10.2.2 Stable Diffusion图生图
1 import torch 2 from PIL import Image 3 from io import BytesIO 4 5 """ 6 StableDiffusionImg2ImgPipeline 的生成过程,其实和我们之前拆解的一步步生成图片的过程是相同的。
唯一的一个区别是,我们其实不是从一个完全随机的噪声开始的,而是把对应的草稿图,通过 VAE 的编码器,变成图像生成信息,又在上面加了随机的噪声。
所以,去除噪音的过程中,对应的草稿图的轮廓就会逐步出现了。而在一步步生成图片的过程中,内容又会向我们给出的提示语的内容来学习。 7 """ 8 9 from diffusers import StableDiffusionImg2ImgPipeline 10 11 device = "cuda" 12 model_id_or_path = "runwayml/stable-diffusion-v1-5" 13 pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16) 14 pipe = pipe.to(device) 15 16 image_file = "./data/sketch-mountains-input.jpg" 17 18 init_image = Image.open(image_file).convert("RGB") 19 init_image = init_image.resize((768, 512)) 20 21 prompt = "A fantasy landscape, trending on artstation" 22 23 images = pipe(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images 24 25 display(init_image) 26 display(images[0])
在这个过程中,你可以看到 Stable Diffusion 并不是指某一个特定的模型,而是指一类模型结构。因为 Stable Diffusion 是完全开源的,所以你大可以利用自己的数据去训练一个属于自己的模型。事实上,市面上开源训练出来的 Stable Diffusion 的模型非常多
10.3 ControlNet:控制生成图片的轮廓、姿势
上一讲,我们体验了 Stable Diffusion 这个时下最流行的开源“AI 画画”项目,不知道你有没有试着用它画一些你想要的图片呢?不过,如果仅仅是使用预训练好的模型来画图的话,我们对于画出来的图还是缺少必要的控制。这会出现一个常见的问题:我们只能通过文本描述来绘制一张图片,但是具体的图片很有可能和你脑海中想象的完全不一样。
ControlNet 是在 Stable Diffusion 的基础上进行优化的一个开源项目,它既对原本的模型架构进行了修改,又在此基础上进行了进一步地训练,提供了一系列新的模型供你使用。
通过 ControlNet,我们可以比较精确地控制生成图片的轮廓、姿态。特别是对于姿态的控制,让我们可以从生成图片向生成视频迈进了。如下3点
1.通过边缘检测(轮廓)绘制头像:对原始的图片(如一名女性)调用get_canny_image得到边缘检测图,在有了边缘检测的底图之后,就可以使用 ControlNet 的模型来画图了,对应的 Prompts,我们设置了四位不同年代的知名女星,并且通过负面提示语排除了黑白照片等等。然后,我们再通过 draw_image_grids 函数,把这 4 张图片一一呈现出来。
边缘检测:整个图片的边缘比较准确地被捕捉了出来 根据边缘检测结果图,promt用明星的名字画出来的图


2.通过Open Pose捕捉人体的动作(姿势)并基于姿势来画画。通过OpenposeDetector捕捉图片里面的人物姿势,有了这两个姿势图后,我们再把蝙蝠侠和钢铁侠这两个不同的漫画人物作为了提示词,并且和前面的边缘检测一样,我们也设置了一些负面提示语来避免生成低质量的图片。
有了这个“捕捉动作”的能力之后,我们不仅能让 AI 画画,让 AI 去拍动画片也成为了可能。我们只需要通过 Open Pose 将原本真人动作里每一帧的人体姿势都提取出来,然后通过 Stable Diffusion 为每一帧重新绘制图片,最后把绘制出来的图片再重新一帧帧地组合起来变成动画就好了。实际上,现在你看到的各种 Stable Diffusion 生成的动画和短视频,基本上都是利用了这个原理。
通过OpenposeDetector捕捉图片里面的人物姿势 基于姿势图,增加promt(蝙蝠侠和钢铁侠)生成它们对应紫色的逼真图


3.通过简笔画来画出好看的图片:还有一种常见的 ControlNet 模型叫做 Scribble,它的效果就是能够让你以一个简单的简笔画为基础,生成精美的图片。
我们使用了一张相同的简笔画图片,但是使用了不同的提示语。提示语之间的差别就是设置了小狗在不同的环境下,分别是房间里、湖边、马路上和森林里。对应生成的图片,也体现了我们提示语中指定的环境。

10.4 Visual ChatGPT:边聊边画
原文链接:https://blog.csdn.net/qq_37756660/article/details/135989044
过去三讲里,我们分别体验了 CLIP、Stable Diffusion 和 ControlNet 这三个模型。我们用这些模型来识别图片的内容,或者通过输入一段文本指令来画图。这些模型都是所谓的多模态模型,能够把图片和文本信息联系在一起。
不过,如果我们不仅仅是要随便找几个关键词画两张画玩个票,而是要在实际的工作环境里生成能用的图片,那么现在的体验还是远远不够的。对于画出来的图我们总有各种各样的修改和编辑的需求。比如,我们总是会遇到各个团队的人对着设计师的图指手画脚地提出各种各样的意见:“能不能把小狗移到图片的右边?”“能不能把背景从草地改成森林?”“我想要一个色彩斑斓的黑。”等等。
所以,理想中的 AI 画画的功能,最好还能配上一个听得懂人话的 AI,能够根据我们这些外行的指手画脚来修改生成的图片。针对这个需求,我们就来介绍一下微软开源的 Visual ChatGPT。
10.4.1 例子
比如,上一讲里我们通过 Canny 算法获取了“戴珍珠耳环的少女”画像的轮廓,然后通过 ControlNet 绘制了同样姿势的其他明星的头像。原本这个过程我们是通过一系列的代码来实现的,现在我们完全可以用 Visual ChatGPT,通过一系列的对话向 AI 下达指令来实现。
10.4.2 Visual ChatGPT 的原理
Visual ChatGPT 的效果非常神奇,但是其实内部原理却非常简单。Visual ChatGPT 解决问题的办法就是使用第 17 讲我们介绍过的 LangChain 的 ReAct Agent 模式,它做了这样几件事情。
1. 它把各种各样图像处理的视觉基础模型(Visual Foundation Model)都封装成了一个个 Tool。
2. 然后,将这些 Tool 都交给了一个 conversation-react-description 类型的 Agent。每次你输入文本的时候,其实就是和这个 Agent 在交流。Agent 接收到你的文本,就要判断自己应该使用哪一个 Tool,还有应该从输入的内容里提取什么参数给到这个 Tool。这些输入参数中既包括需要修改哪一个图片,也包括使用什么样的提示语。这里的 Agent 背后使用的就是 ChatGPT。
3. 最后,Agent 会实际去调用这个 Tool,生成一张新的图片返回给你。
10.4.3 MKRL的提示语及其应用
10.4.3.1 MKRL的提示语
MRKL 是一种计算架构,全称为 Modular Reasoning, Knowledge, and Language(模块化推理、知识和语言)。MRKL 结合了模块化推理、知识库和自然语言处理 (NLP),用以开发智能系统。具体来说:
- Modular Reasoning (模块化推理):允许系统通过多个独立但相互协作的模块来处理复杂问题。每个模块专门处理特定类型的任务或知识领域。
- **Knowledge (知识)*:利用丰富的知识库和数据源,系统可获取、存储和检索大量信息,以支持推理过程。
- Language (语言):应用自然语言处理技术,使系统可以理解、生成和与人类语言进行交互。
这种架构常见于大型语言模型和智能系统的构建中,使其能更有效地处理复杂任务,如问题解答、对话生成等。
在MRKL(Modular Reasoning, Knowledge, and Language)架构中的Prompt可以被设计成一种分步流程,使系统在解决复杂任务时可以依据设定的步骤有效地展开。这种分步流程可以用一些指示来引导系统,例如:Thought(思考)、Action(行动)、Action Input(行动输入)、Observation(观察)。如下所述:
-
Thought(思考):
- 用于系统内部的推理过程。这一步骤旨在让系统明白当前任务需要理解或处理的信息。
- 示例:系统分析问题并思考如何解决问题。
-
Action(行动):
- 指示系统具体采取的步骤或调用处理任务所需的模块。这一步骤可以认为是计划或决策的执行。
- 示例:系统决定调用知识检索模块或自然语言生成模块。
-
Action Input(行动输入):
- 提供Action所需的输入数据或参数。这个输入数据通常来自于用户的查询或系统在推理过程中生成的中间结果。
- 示例:如果Action是“调用知识检索模块”,那么Action Input 可能是“厄尔尼诺现象”。
-
Observation(观察):
- 系统对Action带来的结果进行评估或反馈。这一步骤可以是对结果的校验、总结或进一步的推理。
- 示例:系统获取知识检索模块提供的信息并进行分析,判断这个信息是否符合预期回答所需。
综合这些步骤,一个完整的Prompt可以让系统分阶段处理复杂任务,确保每一步骤清晰明了,系统可以逐步执行。
示范性Prompt可能如下:
这种分步流程明确了每一步所需的输入、执行的操作和预期的反馈,确保系统在处理复杂任务时有条不紊地进行。
思考: 当前任务是回答关于厄尔尼诺现象的问题。首先,我需要获取关于厄尔尼诺现象的科学知识。 行动: 调用 知识检索模块。 行动输入: “厄尔尼诺现象” 观察: 知识检索模块返回了关于厄尔尼诺现象的详细描述和影响。 思考: 现在我有了关于厄尔尼诺现象的基础知识,并且需要解释它对全球气候的影响。 行动: 调用 推理模块。 行动输入: 基于当前获取的厄尔尼诺现象的信息,解释其对全球气候的影响。 观察: 推理模块返回了相关推理结果,说明厄尔尼诺现象会导致极端天气情况的增加。 思考: 将获取的知识和推理结果整合,生成最终的回答。 行动: 调用自然语言生成模块。 行动输入: “厄尔尼诺现象是指赤道太平洋东部和中部海域水温异常升高的现象。它会导致全球气候异常,如干旱、洪水、暴风雨等。” 观察: 自然语言生成模块返回了清晰准确的回答。
10.4.3.2 MKRL的提示语在Visual ChatGPT的应用
我们刚才说过,每个 Class 模型拿到的 inputs 输入都是模型“思考”之后根据用户输入提取出来的 Action Inputs。这一点,其实还是要归功于 ChatGPT 强大的逻辑推理能力。我们只要回到代码的开头,看一下对应的 Prompts 其实就能知道 Visual ChatGPT 是怎么做到的了。实际上,每次用户输入的内容,都是通过 VISUAL_CHATGPT_PREFIX、VISUAL_CHATGPT_FORMAT_INSTRUCTIONS 和 VISUAL_CHATGPT_SUFFIX 这三段 Prompts 拼接而成的。
而 AI 的思考过程,其实就是 VISUAL_CHATGPT_FORMAT_INSTRUCTIONS 这一小段。
1 VISUAL_CHATGPT_FORMAT_INSTRUCTIONS = """To use a tool, please use the following format: 2 Thought: Do I need to use a tool? Yes 3 Action: the action to take, should be one of [{tool_names}] 4 Action Input: the input to the action 5 Observation: the result of the action 6 When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format: 7 Thought: Do I need to use a tool? No 8 {ai_prefix}: [your response here] 9 """
这个其实就是在第 17 讲里看过的 MRKL 的提示语模版。AI 通过 Thought、Action、Action Input 和 Observation 这样的四轮循环,完成一次 Tools 的判定与调用。
并且,每次给到 Agent 的输入里,都可以包含多个迭代的 Action 和 Action Input,调用多次模型 Class 来解决问题。
原文链接:https://blog.csdn.net/qq_37756660/article/details/135989044
10.4.4 小结和Task Matrix(任务矩阵)
看完这个代码之后,相信你完全有能力修改代码满足自己的需求了。如果有一天出现了一个更好用的视觉基础模型,你完全可以把这个新的模型 Class 加入到 Visual ChatGPT 中。只需要通过 __init__ 函数加载模型,然后定义好它对应的提示语以及 inference 函数,就能让 Visual ChatGPT 支持一种新的图片编辑和绘制功能了。
回顾整个 Visual ChatGPT 的代码,其实并不复杂。它就是将第 17 讲我们介绍过的 LangChain 的 Agent,和过去 3 讲我们介绍的各种视觉大模型组合起来,通过 ChatGPT 的语言和逻辑推理能力处理用户输入,通过 LangChain 的 Agent 机制来调度推理过程和工具的使用,通过视觉大模型实际来处理图片以及理解图片的内容。
这样的机制其实不仅可以用来处理图片,也可以用在其他机器学习的模型里,比如语音、视频,甚至你还可以利用它再去调用别的大语言模型。而这个机制,后来也被微软进一步扩展到 Task Matrix 这个概念里。Visual ChatGPT 的代码库的名称今天也被改成了 Task Matrix,也就是“任务矩阵”的意思。
10.5 Midjourney
无论从哪个角度来看,Midjourney 都是一个值得研究的 AI 产品。在它所有的产品设计里,我认为有三个要点是今天所有的 AI 应用都应该借鉴的,那就是
1.以用户社区作为入门教程
进入某一个新用户的聊天室里,无论是自己通过提示语去画画,还是其他在聊天室里的用户去画画,都会在聊天室里不停地刷新;
Midjourney 同样也为老用户设置了 general 频道,你在里面一样可以看到老玩家们绘制的优秀画作。
2.给用户即时反馈
(2.1)在通过这样的引导学会了使用 Midjourney 各种好用的提示语之后,相信用户都会愿意多试试不同的提示语,画出漂亮的图画来。而作为一个 AI 内容生成的应用,Midjourney 在产品设计里的第一个挑战,就是响应时间问题。
(2.2)如果你要像 Midjourney 一样,直接面向消费者提供服务,你还会面临一个问题,就是所有的用户请求需要排队。并且,最好能够按照一个批次(Batch)进行处理。
——这是由我们通过 GPU 来生成内容的原理决定的,GPU 不像 CPU 那样可以通过多线程或者时分复用的方式来处理请求,而只适合顺序地处理请求。而为了让显卡的利用率最大化,最好的办法是一个批次能够同时处理多张图片。
——所以我的预测是,你发给 Midjourney 的请求在它服务器端的集群里一样会先去排队。等到其他人的请求和你的请求一起凑满了一个批次,才会去生成图片。这也会使得从我们向 Midjourney 发送提示语,到拿到最终的图片需要更长的时间。而这也会进一步消耗用户的耐心,让用户可能连第一次尝试都等不到完成的时候就走了。
(2.3)Midjourney 解决问题的办法,则是尽可能让用户能在等待过程中看到这个任务是有进展的(不断更新图片生成的中间过程,整个图像会逐渐从模糊变清晰)。
——此外,针对每次你输入的提示语,Midjourney 并不是为你直接生成一张高清晰度的大图,而是生成了 4 张不同的图片。这其实也是为了弥补 Diffusion 类型算法的一个缺陷,就是生成的图像可控性比较差,一次性就能拿到我们满意的图片的概率比较低。
——而且生成小尺寸的图片,GPU 需要的计算时间也比较少。等到我们确定大致图片没有问题了,再通过 Diffusion 的生成算法,把图片放大变成高清大图,需要的总时间也短得多
3.搭建数据飞轮以迭代模型。
如果你用过 Midjourney 的话,应该知道它出的图质量很好,很多人都觉得要比开源的 Stable Diffusion 好上不少。在我看来,这背后有一个很重要的因素,就是它拥有更多高质量的标注数据。你可能要问了,Midjourney 只有不到 20 个人的团队,哪里来的资源去标注数据呢?答案就在 Midjourney 的产品设计流程里。
最直接的一个数据标注,就是在每次生成的高清大图下面,都有一个 Favourite 的按钮。用户可以点击这个按钮表示喜欢并且收藏这个图片。而每次当用户按下这个按钮的时候,Midjourney 的团队其实就获得了一个由用户标注好的优质图片数据,也就是用户输入的提示词和对应图片的配对组合。
但是只要做过一些产品,你也会发现真的会主动点击 Favorite 的用户还是太少了。不过,Midjourney 其实还有更多“隐形”的操作,也帮助他们标注了图片质量的好坏。(如4张图片都满意,点击全部重新生成;或者,对其中一张图片的整体观感还是不错的,但是还不够满意,点击以这张满意的再生成)

