矩阵理论-1范数、2范数、无穷范数的通俗理解?
引言
很多人学完了矩阵理论或者数值分析,脑海里还是蒙的,有些比较基础的东西至今还没有一个深刻的理解,就比如矩阵理论中1范数、2范数,以及无穷范数代表什么含义呢?
范数的理解
我们来讲个故事,保证大家能够明白,这里主要是以向量范数为例。假设小花要选男朋友,她想在小强和小刚之间选。
第1种情况,小花的选择标准只有一个,即身高。
那么,小强的身高是1.7米,小刚的身高是1.8米,所以她会选小刚(这里假如女孩子喜欢高一点的男孩子)。
第2种情况,小花的择偶标准有两个,即身高和月收入。
假如小强的月收入为2万,小刚为1万。那么在小花的眼中,小强={1.7,2},小刚={1.8,1}。
可是,这怎么比呢?
于是,小花想出了一个办法,更方便度量,就是综合收入和身高的平均值,她的办法是画出坐标系,看最终谁的点离原点点更远。
所以通过勾股定理,可以求得小强更远,所以她选择了小强。
换句话也就是说,范数可以等于点到坐标零点的距离。
是不是很清新,是不是很明了?
所以通俗的说,范数就是为了方便度量而定义出的一个概念,主要就是面对复杂空间和多维数组时,选取出一个统一的量化标准,以方便度量和比较。请务必记住,范数是人为定义的一种度量方法。
那么,如果一个向量里元素更多。例如,小花的择偶标准里再加上性格评分,以及身体素质评分,就变成了(1.7, 2.0, 4.0, 5.8 )这样形式的向量,维度又增加了。
所以,我们还可以定义更多的统一度量标准。
1范数、2范数、无穷范数(向量范数)
这三种不同的范数都是不同的度量方法。
0范数
向量中非零元素的个数,这里不解释)
1范数:所有元素绝对值的和。
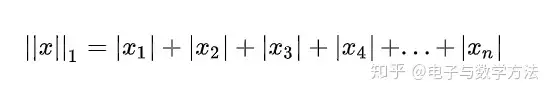
matlab调用函数norm(x, 1) 。
2范数:所有元素平方和的开方。
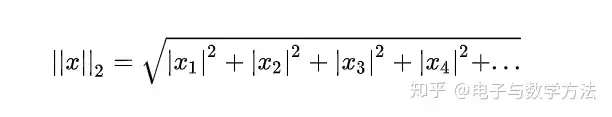
matlab调用函数norm(x, 2)。
p范数
![]()
p-范数:即向量元素绝对值的p次方和的1/p次幂,matlab调用函数norm(x, p)。
无穷范数
正无穷范数:所有元素中绝对值最大的,matlab调用函数norm(x, inf)。负无穷范数:所有元素中绝对值最小的,matlab调用函数norm(x, -inf)。
║x║∞=max(│x1│,│x2│,…,│xn│)
生动解释
《武林外传》里一段台词用来解释这几个范数或许是最生动的了。
佟湘玉有一天在同福客栈说:“额滴神呐,展堂,你说隔壁的赛貂蝉有什么好。”
老白:“她没没你温柔,没你贤惠,没你大气,没你端庄。”
佟湘玉:“那为啥你们总往她那跑呢?”老白:“因为他的相貌是满分啊”。
看到没有?
如果用2范数来衡量赛貂蝉和佟湘玉,那么可以说佟湘玉并不占下风,但是压不住人家赛貂蝉有一个满分啊,也就是说,从无穷范数的角度来看,赛貂蝉的稳稳超过佟湘玉的。
再看一个辩题“当今社会更需要通才还是专才”。通才是1范数2范数比较大,而专才就是无穷范数比较大。
是不是一下子就整明白了,最后,记住,范数是比较向量/矩阵是否“优秀”的一种标准而已。为了加深印象大家还可以使用MATLAB去编程计算一下。
最后我们讲一下范数对于数学的意义,范数其实就是从数学本质上描述了“什么叫空间”,它不再是我们日常生活对话里的“空间”了。它从更深刻的角度来洞察我们这个世界,下次你一看到空间,你一给你家装修,搞空间艺术,你是不是马上就会想到,我们搞的是范数2空间。
我们可以想象一下会不会在那么一个平行宇宙,那里的人搞空间艺术,要考虑的却是范数3的空间呢?
向量范数和矩阵范数
链接:https://www.zhihu.com/question/20473040/answer/25599737
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
你是问向量范数还是矩阵范数?
要更好的理解范数,就要从函数、几何与矩阵的角度去理解,我尽量讲的通俗一些。
我们都知道,函数与几何图形往往是有对应的关系,这个很好想象,特别是在三维以下的空间内,函数是几何图像的数学概括,而几何图像是函数的高度形象化,比如一个函数对应几何空间上若干点组成的图形。
但当函数与几何超出三维空间时,就难以获得较好的想象,于是就有了映射的概念,映射表达的就是一个集合通过某种关系转为另外一个集合。通常数学书是先说映射,然后再讨论函数,这是因为函数是映射的一个特例。
为了更好的在数学上表达这种映射关系,(这里特指线性关系)于是就引进了矩阵。这里的矩阵就是表征上述空间映射的线性关系。而通过向量来表示上述映射中所说的这个集合,而我们通常所说的基,就是这个集合的最一般关系。于是,我们可以这样理解,一个集合(向量),通过一种映射关系(矩阵),得到另外一个几何(另外一个向量)。
那么向量的范数,就是表示这个原有集合的大小。
而矩阵的范数,就是表示这个变化过程的大小的一个度量。
那么说到具体几几范数,其不过是定义不同,一个矩阵范数往往由一个向量范数引出,我们称之为算子范数,其物理意义都如我上述所述。
以上符合知乎回答问题的方式。
接下来用百度回答方式:
0范数,向量中非零元素的个数。
1范数,为绝对值之和。
2范数,就是通常意义上的模。
从机器学习正则化的视角理解
作者:凌空
链接:https://www.zhihu.com/question/20473040/answer/175915374
不同范数对应的曲线如下图:

上图中,可以明显看到一个趋势,即q越小,曲线越贴近坐标轴,q越大,曲线越远离坐标轴,并且棱角越明显。那么 q=0 和 q=oo 时极限情况如何呢?猜猜看。

上图中,蓝色的圆圈表示原问题可能的解范围,橘色的表示正则项可能的解范围。而整个目标函数(原问题+正则项)有解当且仅当两个解范围相切(???)。从上图可以很容易地看出,由于2范数解范围是圆,所以相切的点有很大可能不在坐标轴上(感谢评论区@临熙指出表述错误),而由于1范数是菱形(顶点是凸出来的),其相切的点更可能在坐标轴上,而坐标轴上的点有一个特点,其只有一个坐标分量不为零,其他坐标分量为零,即是稀疏的。所以有如下结论,1范数可以导致稀疏解,2范数导致稠密解。那么为什么不用0范数呢,理论上它是求稀疏解最好的规范项了。然而在机器学习中,特征的维度往往很大,解0范数又是NP-hard问题,所以在实际中不可行。但是用1范数解是可行的,并且也可以得到稀疏解,所以实际稀疏模型中用1范数约束。
至此,我们总结一下,在机器学习中,以0范数和1范数作为正则项,可以求得稀疏解,但是0范数的求解是NP-hard问题; 以2范数作为正则项可以得到稠密解,并且由于其良好的性质,其解的定义很好,往往可以得到闭式解,所以用的很多。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 记一次.NET内存居高不下排查解决与启示
2016-09-18 Java 位运算(移位、位与、或、异或、非)
2016-09-18 负数的二进制表示方法(正数:原码、负数:补码)