监控报警体系:Prometheus和Grafana
总体
-
prometheus全链路监控报警,在当今云原生时代可观测领域,Prometheus + Grafana 成为可观测性事实标准。
-
采集数据:运维团队可以使用 Prometheus 监控云原生 Kubernetes 体系 Node、ApiServer、workload 等基础指标的同时,还可以通过 Prometheus Exporters 采集各种组件(如 Redis、Kafka 等)和业务应用的相关指标,
- 可视化展示:最后通过 Grafana 进行整体可视化展示
- 告警:借助 Prometheus的AlertManager 进行告警,实现云原生时代的指标可观测闭环。
-
Prometheus
Prometheus 是任何一个高级工程师必须要掌握的技能。那么如何从零部署一套 Prometheus 监控系统呢?本篇文章将从 Prometheus 的原理讲起,手把手带你用一个最简单的例子部署一套 Prometheus 监控系统。
基本原理
Prometheus的基本架构如下图所示:
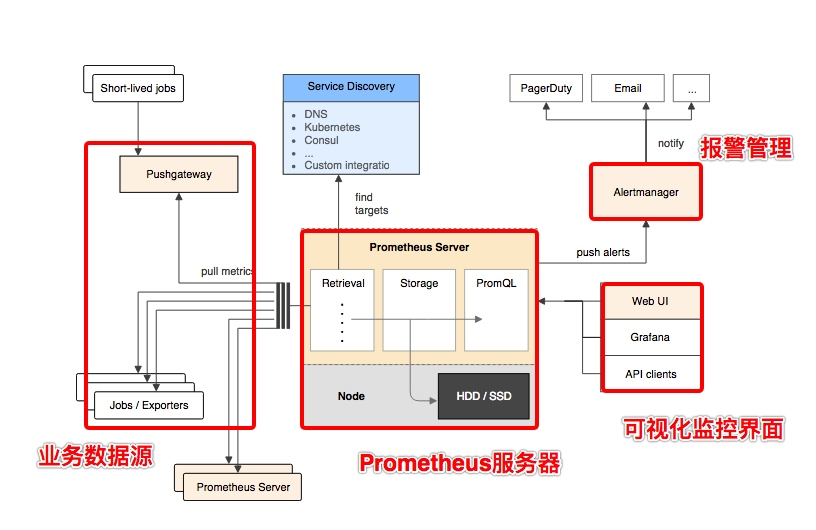

从上图可以看到,整个 Prometheus 可以分为四大部分,分别是:
- Prometheus 服务器
Prometheus Server 是 Prometheus组件中的核心部分,负责实现对监控数据的获取,存储以及查询。
- NodeExporter 业务数据源
业务数据源通过 Pull/Push 两种方式推送数据到 Prometheus Server。
- AlertManager 报警管理器
Prometheus 通过配置报警规则,如果符合报警规则,那么就将报警推送到 AlertManager,由其进行报警处理。
- 可视化监控界面
Prometheus 收集到数据之后,由 WebUI 界面进行可视化图标展示。目前我们可以通过自定义的 API 客户端进行调用数据展示,也可以直接使用 Grafana 解决方案来展示。
简单地说,Prometheus 的实现架构也并不复杂。其实就是收集数据、处理数据、可视化展示,再进行数据分析进行报警处理。 但其珍贵之处在于提供了一整套可行的解决方案,并且形成了一整个生态,能够极大地降低我们的研发成本。

https://www.cnblogs.com/chanshuyi/p/01_head_first_of_prometheus.html
分类:
SRE稳定性 / 监控告警



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
2013-12-14 Cookie入门实例
2013-12-14 Session入门实例