批处理(Batch或离线计算)和流计算(Streaming或实时计算)
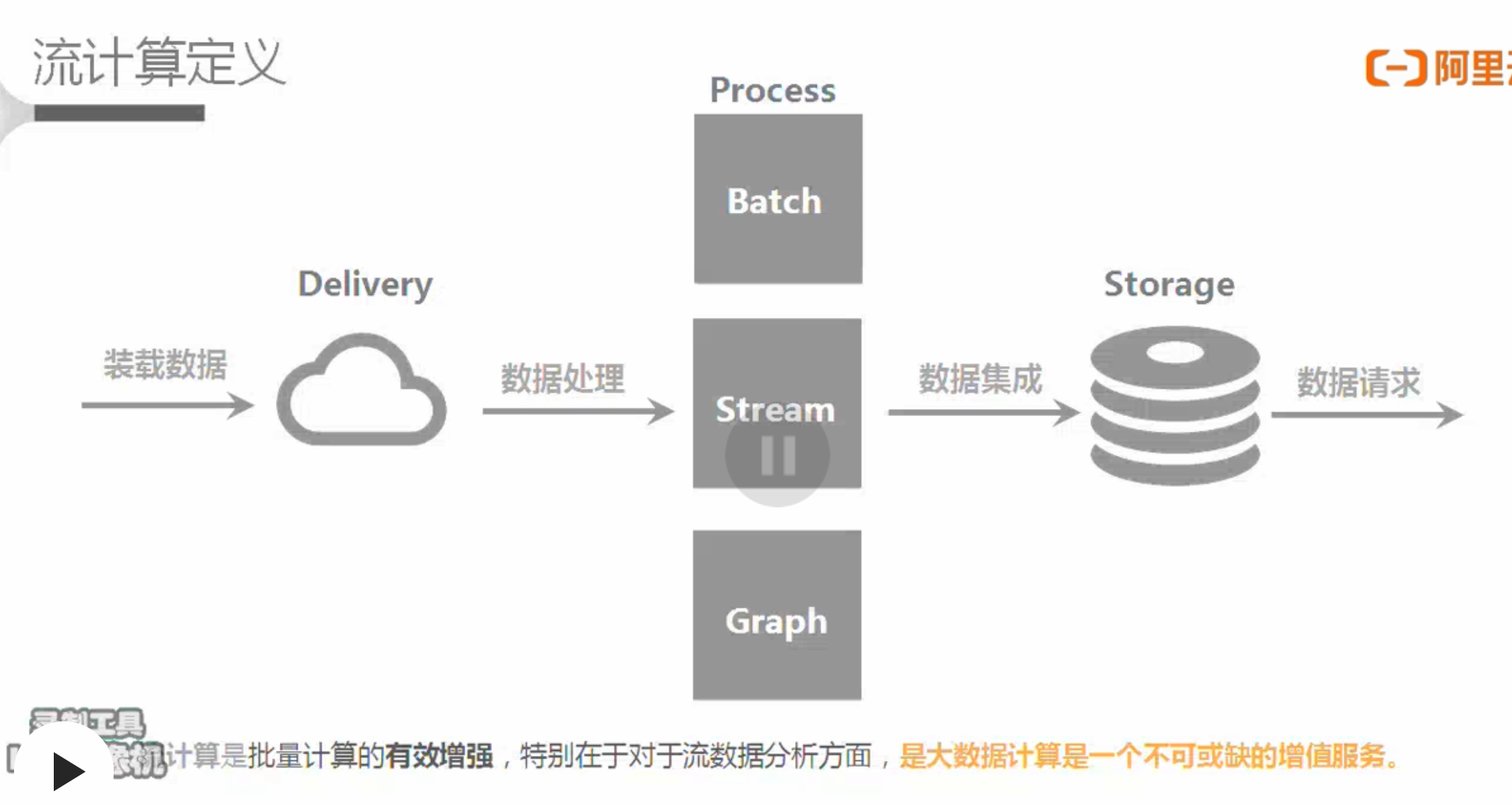
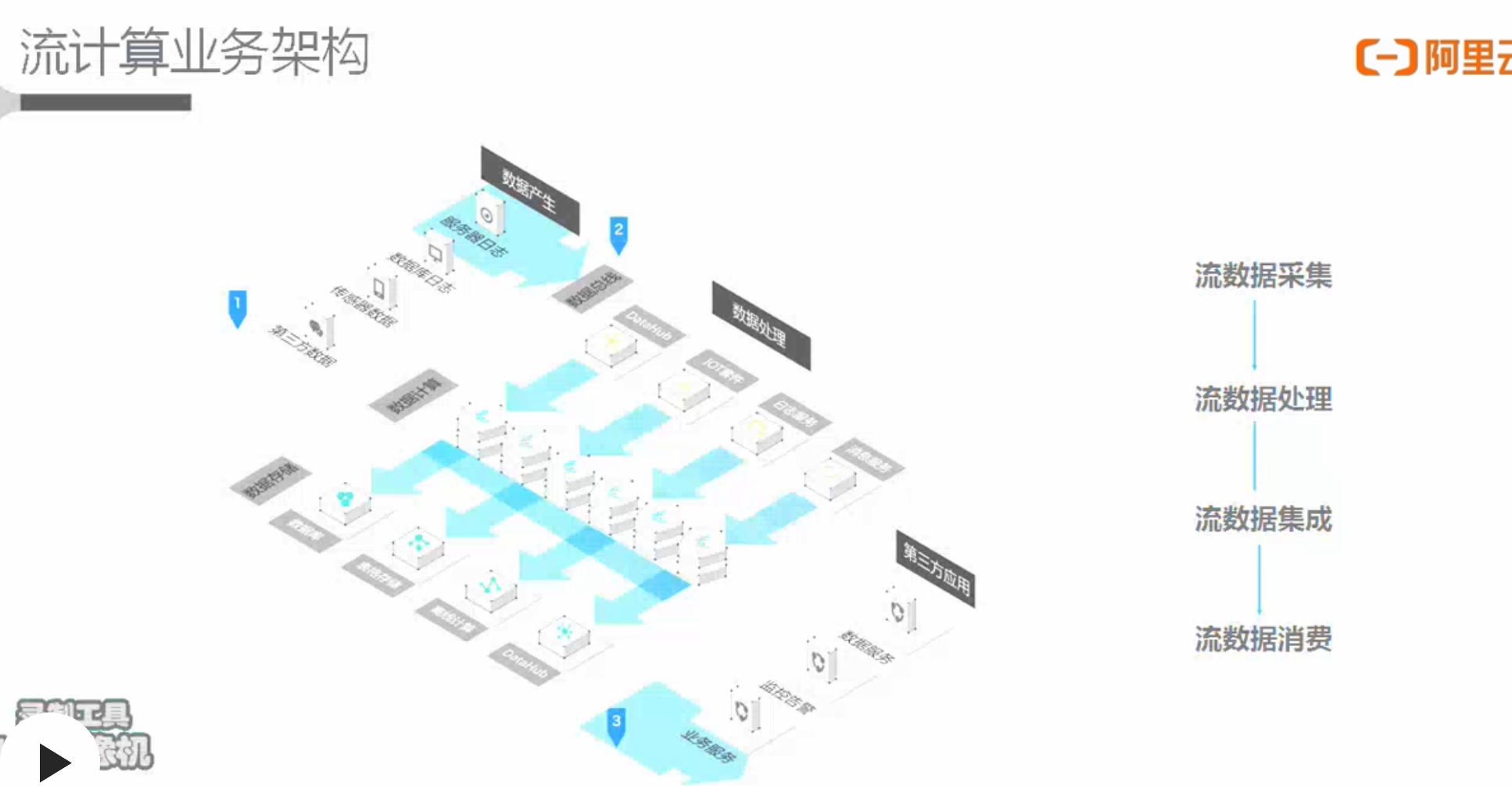
大数据处理流程
- 课程:https://developer.aliyun.com/learning/course/432/detail/5385
- 流程
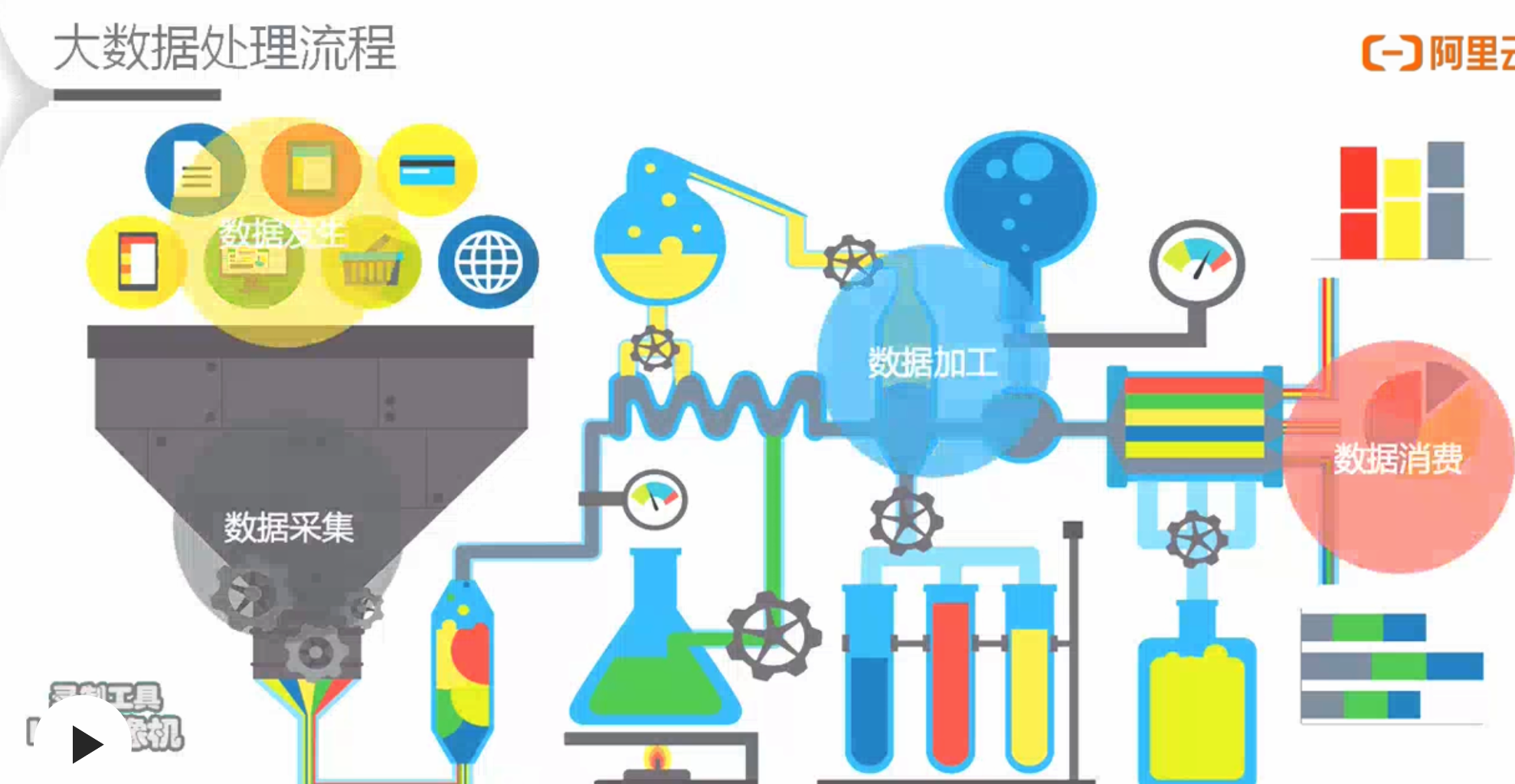

-
- 发
批处理(Batch或离线计算)
- 基础:google的三大论文——论文GFS、MapReduce、BigTable(kv存储)
- 基于上述论文,开发了产品Hadoop:包含存储(HDFS)+计算(MapReduce)两部分
- 基于mapreduce上面长出了HIVE(就是SQL,降低开发门槛)
- 后面2.0阶段 Spark:解决了磁盘的shuffle性能问题,成为业界批处理的主流;但阿里内部一直是ODPS(基于mapreduce)上去做
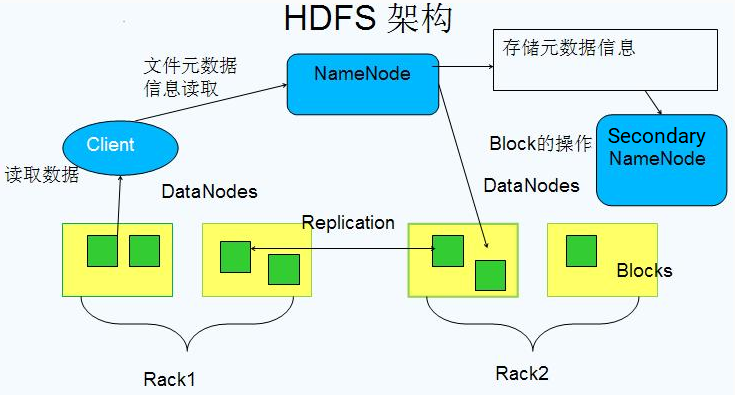
- HDFS架构
- https://www.w3cschool.cn/hadoop/xvmi1hd6.html
- HDFS:Hadoop Distributed File System,分布式文件系统
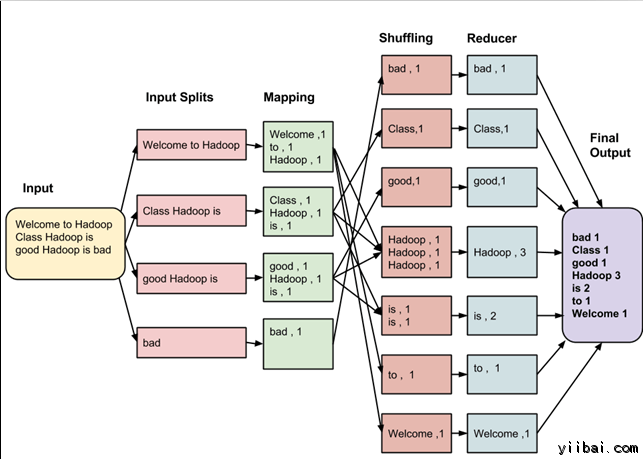
- MapReduce计算
- https://www.yiibai.com/hadoop/intro-mapreduce.html
- 介绍:一种分布式的计算方式指定一个Map(映#x5C04;)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组
- 输入:
Welcome to Hadoop Class
Hadoop is good
Hadoop is bad
- 步骤:
-
输入拆分:input splits
输入到MapReduce工作被划分成固定大小的块叫做 input splits ,输入折分是由单个映射消费输入块。(对于大多数作业,最好是分割成大小等于一个HDFS块的大小(这是64 MB,默认情况下)。
映射 - Mapping
这是在 map-reduce 程序执行的第一个阶段。在这个阶段中的每个分割的数据被传递给映射函数来产生输出值。在我们的例子中,映射阶段的任务是计算输入分割出现每个单词的数量(更多详细信息有关输入分割在下面给出)并编制以某一形式列表<单词,出现频率>
重排 - Shuffling
这个阶段消耗映射阶段的输出。它的任务是合并映射阶段输出的相关记录。在我们的例子,同样的词汇以及它们各自出现频率。
Reducing
在这一阶段,从重排阶段输出值汇总。这个阶段结合来自重排阶段值,并返回一个输出值。总之,这一阶段汇总了完整的数据集。
在我们的例子中,这个阶段汇总来自重排阶段的值,计算每个单词出现次数的总和。
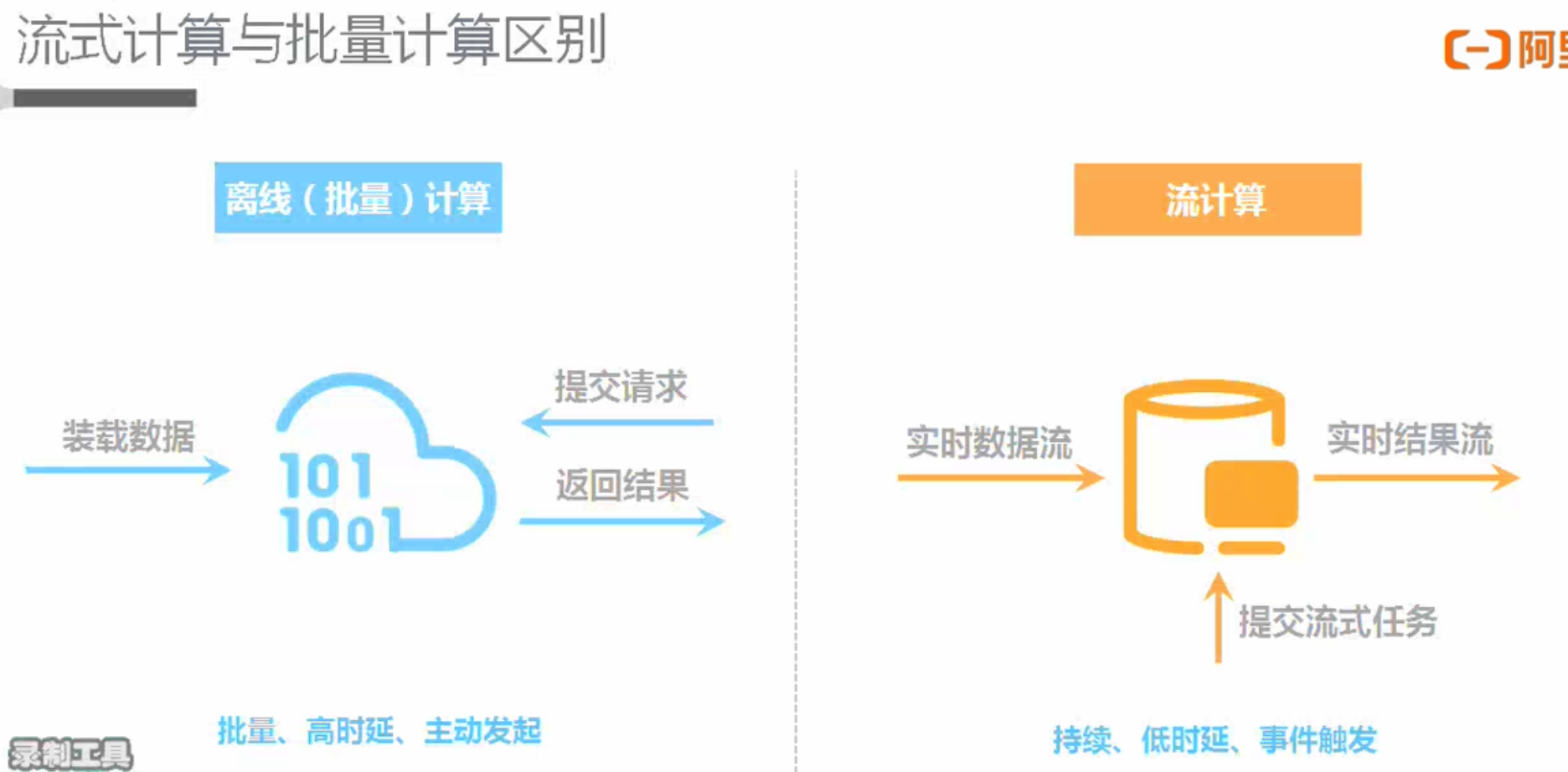
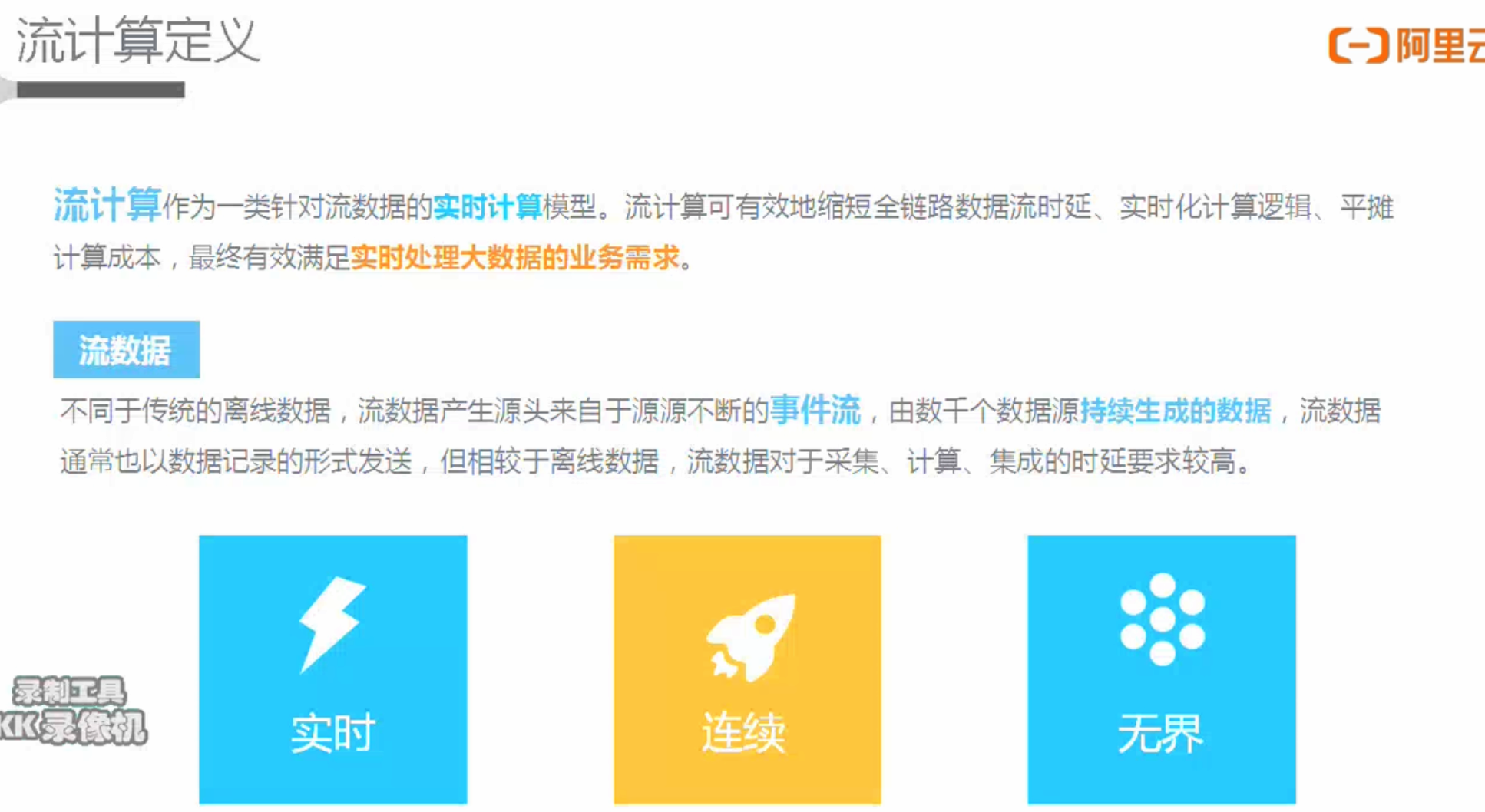
流计算(Streaming或实时计算)
| 批处理Batch | 流处理Streaming | |
| 数据 | 有界数据集(已经落盘的) | 无界数据集(源源不断进来的) |
| 有序数据集(因为已经落盘,可以order by排序等) | 无序数据集(可能后发生的先到) | |
| 运行 | 定时调度 | 启动一次 |
| 数据处理完任务结束 | 任务一直运行 | |
| 时效 | 小时/天 | 秒级/毫秒级 |
| 例子 |
Hadoop的mapreduce spark |
Flink |
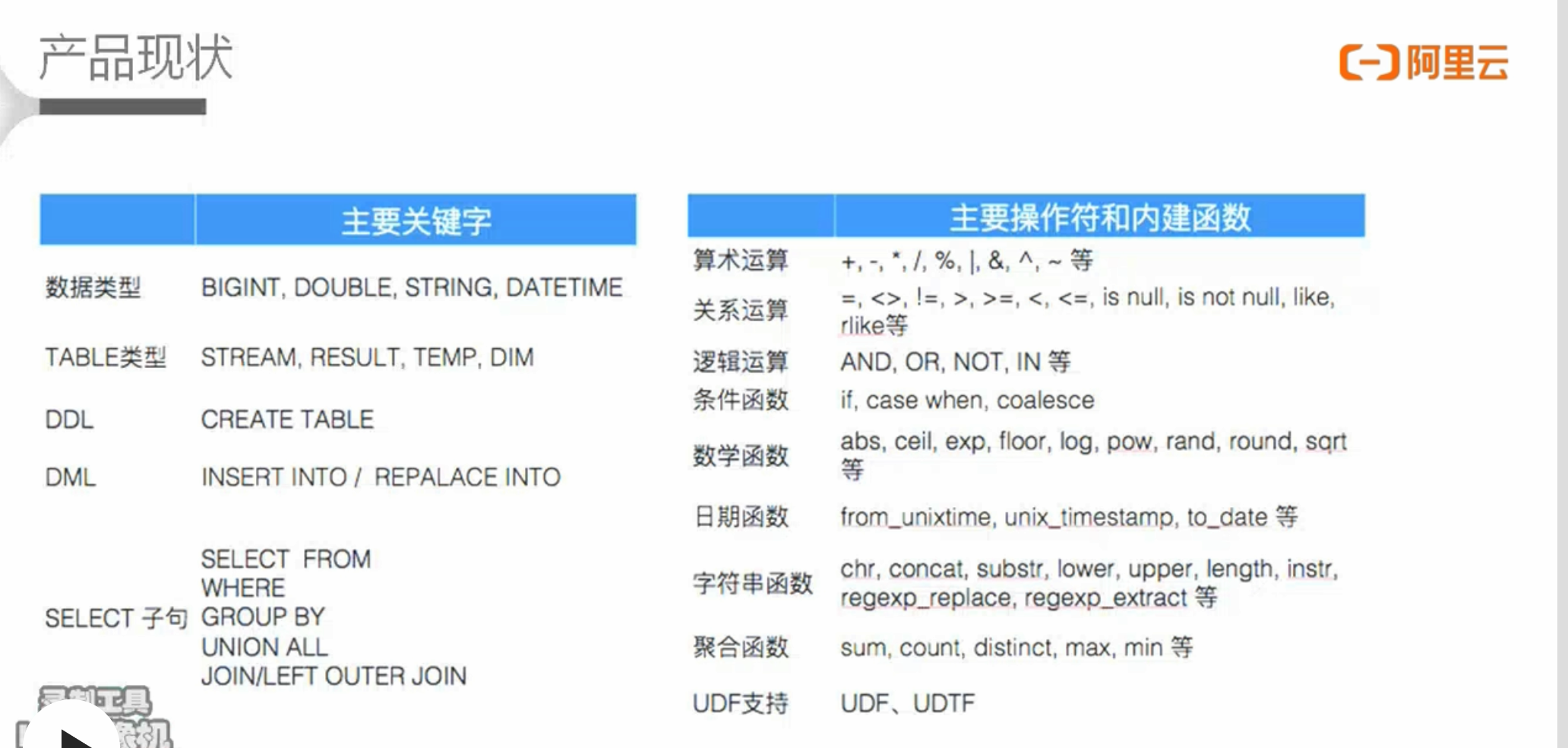
流计算SQL样例1
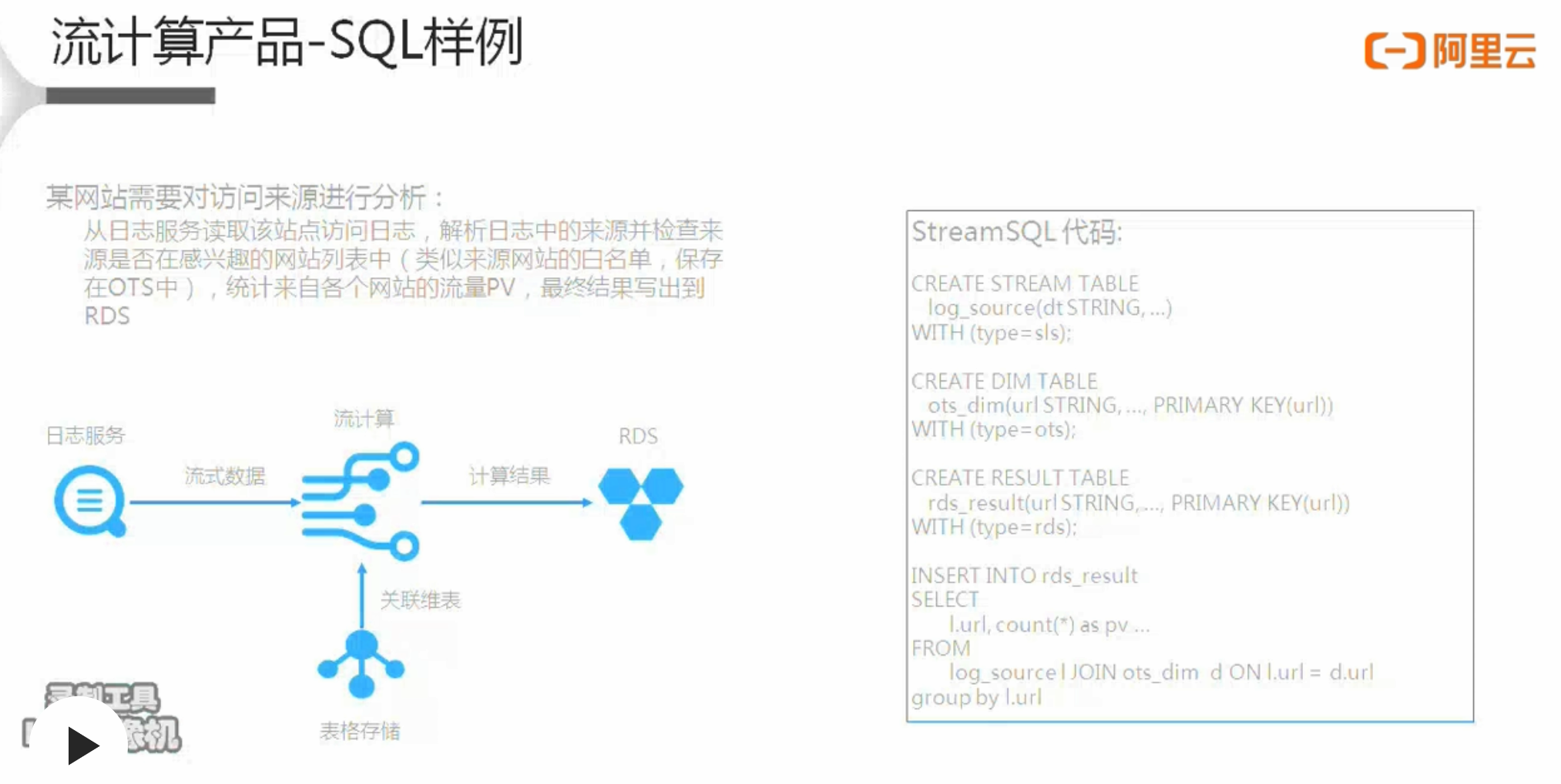
例:
某网站需要对访问来源进行分析:
从日志服务读取该站点访问日志,解析日志中的来源并检查来源是否在感兴趣的网站列表中(类似来源网站的白名单,保存在OTS中),统计来自各个网站的流量PV,最终结果写出到 RDS
流计算SQL样例2
热词统计分析实际上就是一个简单的Word Count任务,而流式实时热词统计分析将Word Count处理逻辑整体转换为流式实时处理,可以做到实时对热词进行统计分析,并可以实时展现。
需要创建源表、创建结果表、计算逻辑。

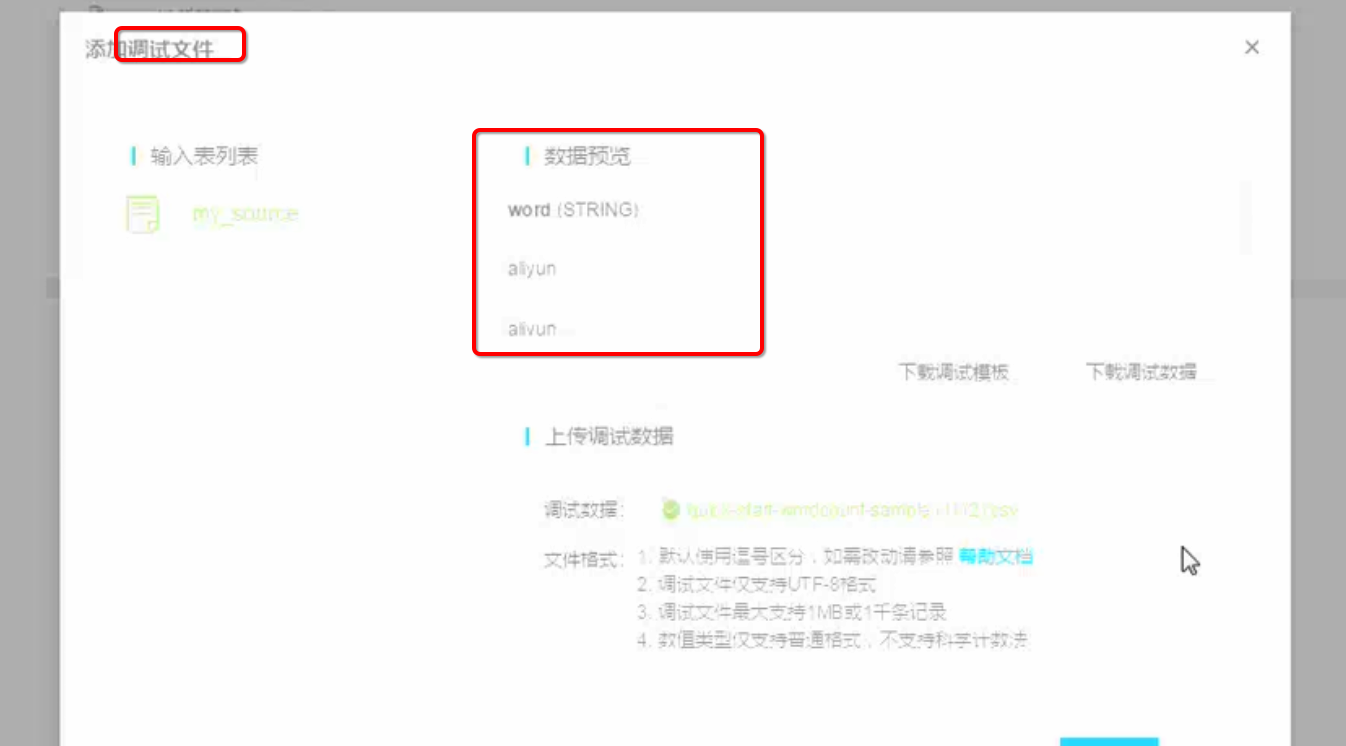
调试数据:3行aiyun,1行alibaba
会把整个运算过程都打印出来,下游做存储的时候,会进行去重,存储的就是aliyun 3, alibaba 1

流计算SQL样例3
要求:按天聚合当天的交易笔数,交易金额


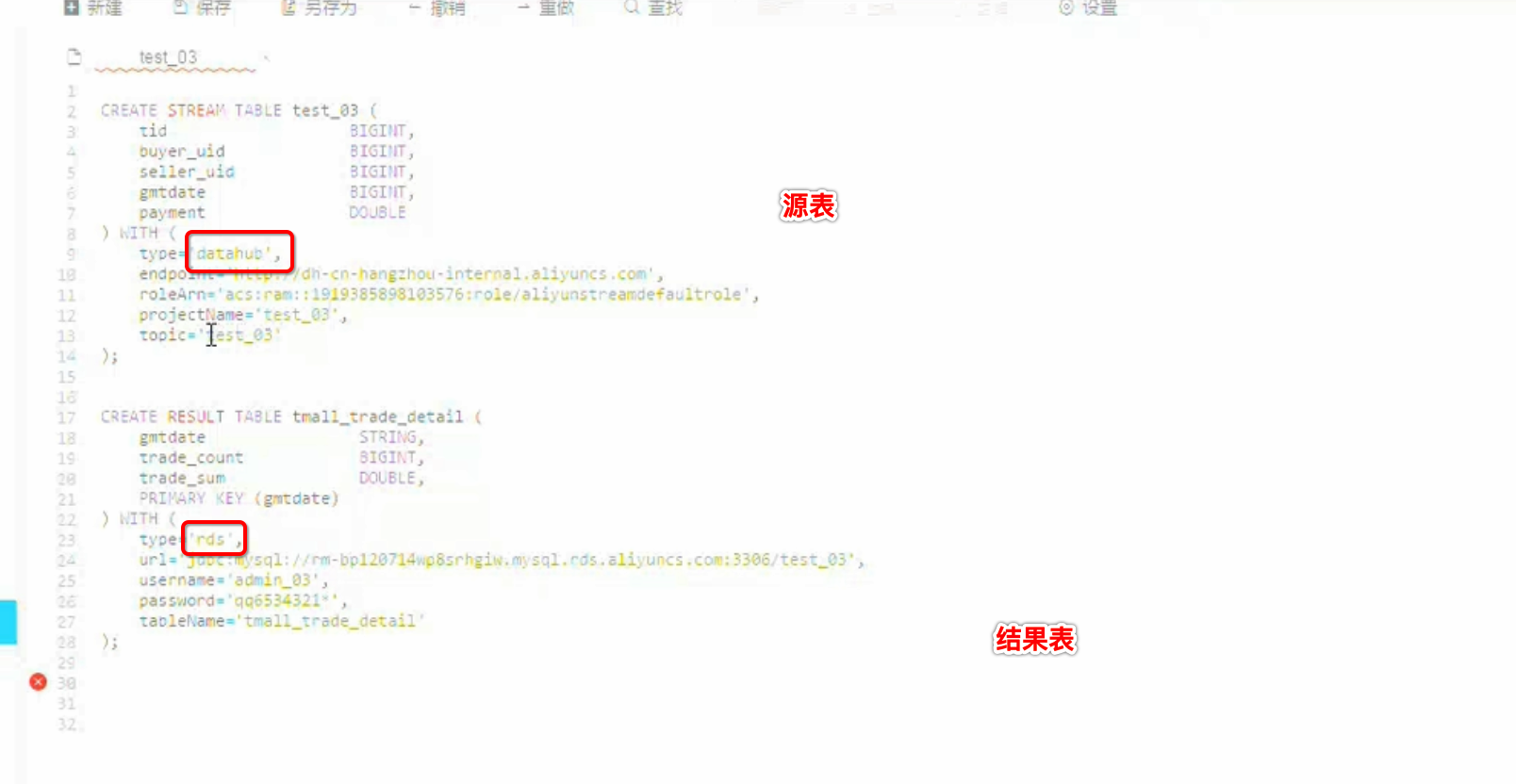
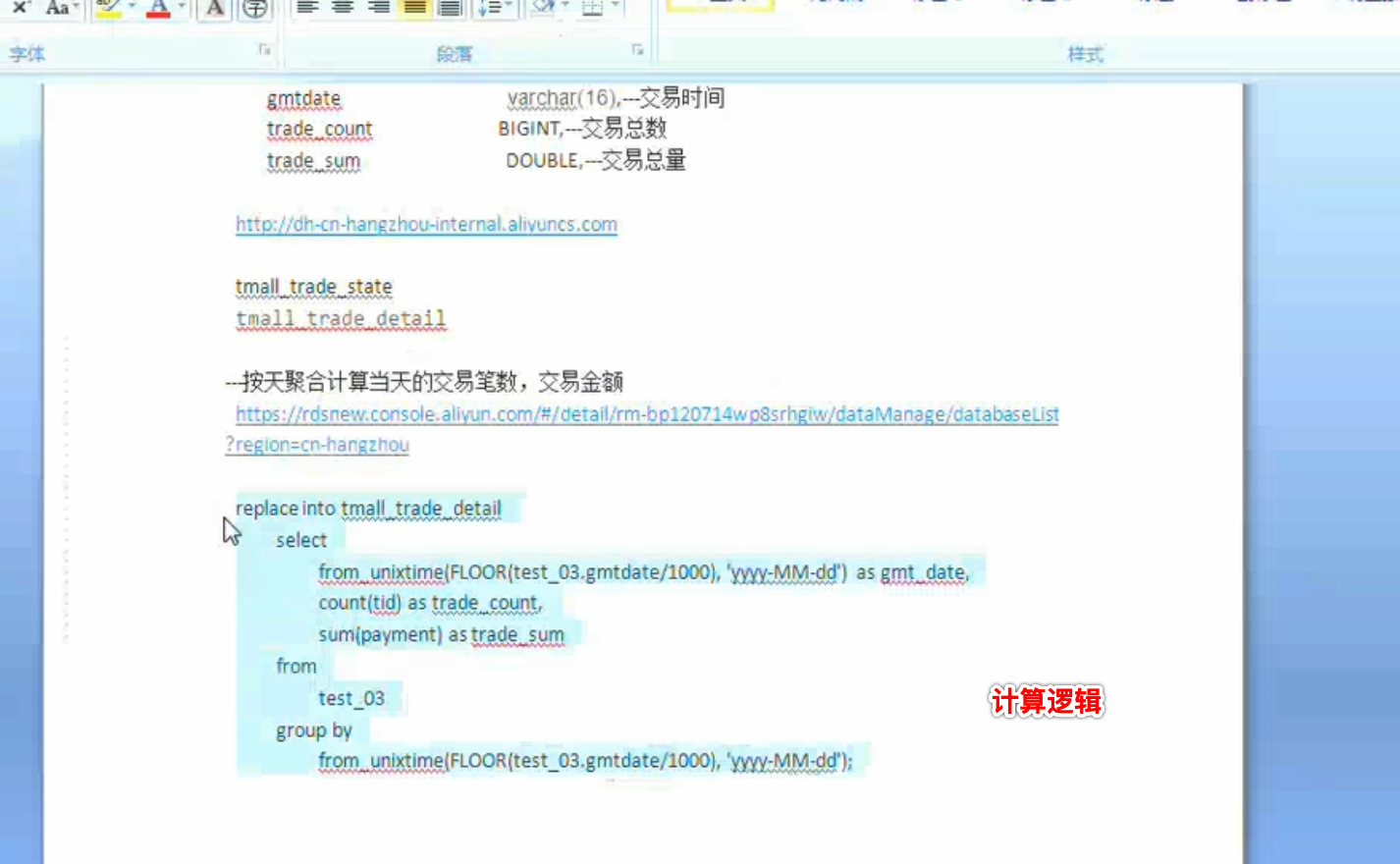
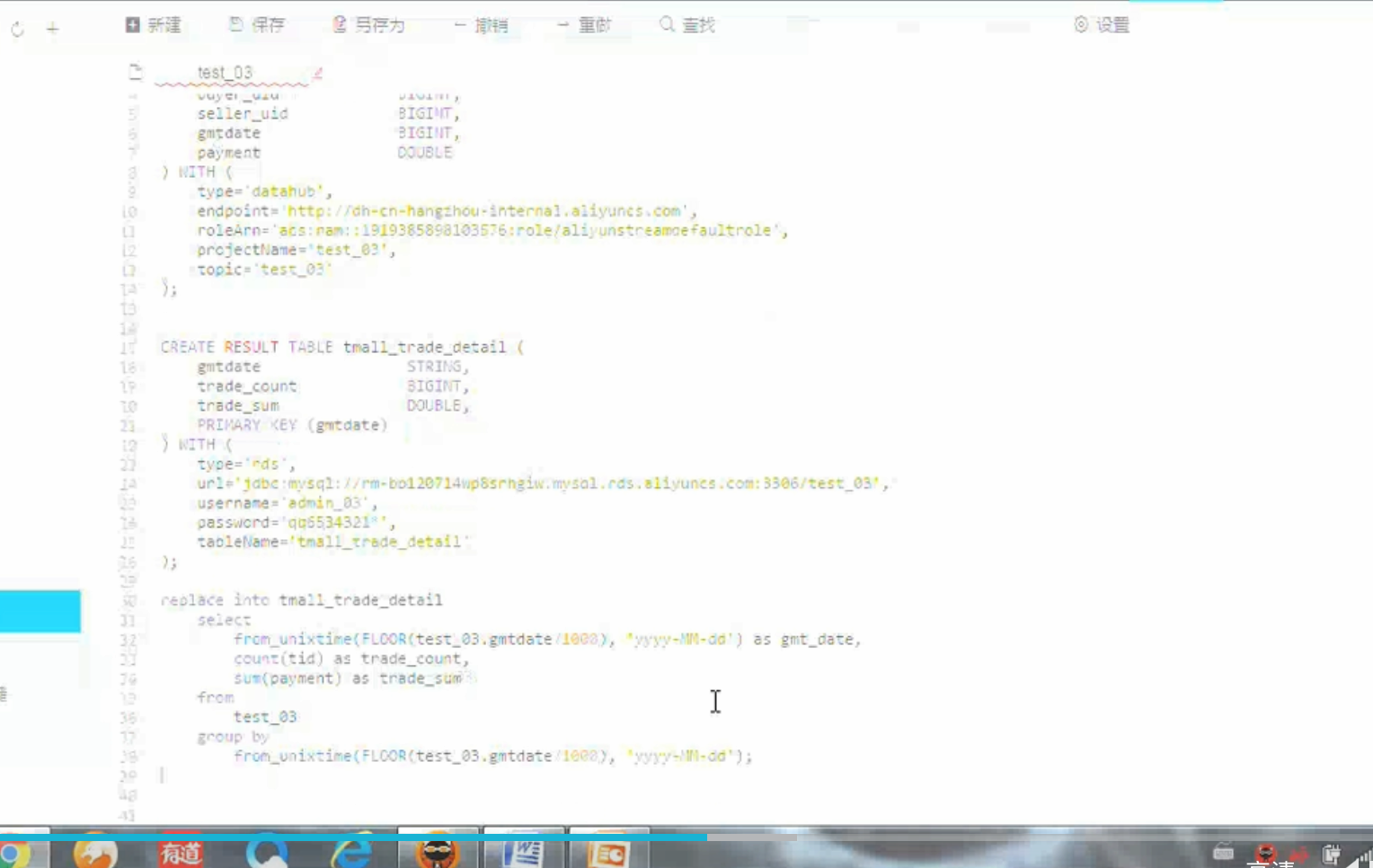
调试数据:

最佳实践





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
2013-12-14 Cookie入门实例
2013-12-14 Session入门实例