阿里巴巴Java开发手册
六、工程结构
应用分层
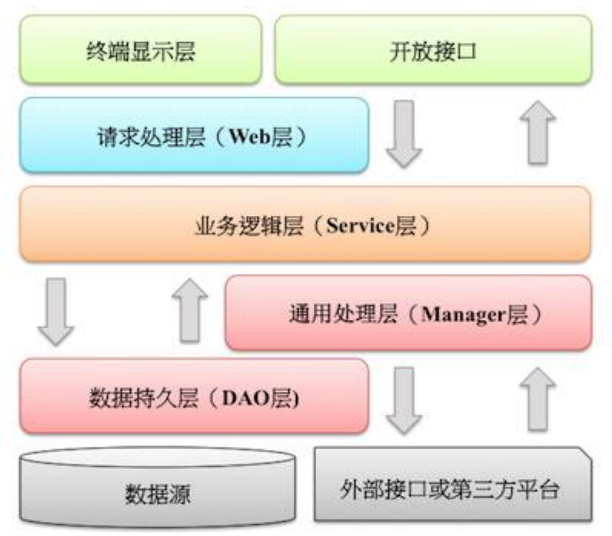
- 开放API层:可直接封装Service接口暴露成HSF接口;通过Web封装成http接口;网关控制层等。
- 终端显示层:各个端的模板渲染并执行显示层。当前主要是velocity渲染,JS渲染,JSP渲染,移动端展示层等。
- Web层:主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理等。
- Service层:相对具体的业务逻辑服务层。
- Manager层:通用逻辑处理层,它有如下特征:
1) 对第三方平台封装的层,预处理返回结果及转化异常信息,适配上层接口;
2) 对Service层通用能力的下沉,如缓存方案、中间件通用处理;
3) 与DAO层交互,对DAO的业务通用能力的封装。 - DAO层:数据访问层,与底层MySQL、Oracle、Hbase、OB进行数据交互。
- 第三方服务:包括其它部门HSF服务接口,基础平台,其它公司的HTTP接口,如IC、美杜莎、支付宝接口等。
- 外部数据接口:外部(应用)数据存储服务提供的接口,多见于数据迁移场景中。
典型场景 (https://cloud.tencent.com/developer/article/1521713)
经常听很多人在Review别人代码的时候有如下的评论:“你在设计的时候这些类之间怎么能有循环依赖呢?你这样会报错的!”。
其实这句话前半句当然没有错,出现循环依赖的确是设计上的问题,理论上应当将循环依赖进行分层,抽取公共部分,然后由各个功能类再去依赖公共部分。
但是在复杂代码中,各个manager类互相调用太多,总会一不小心出现一些类之间的循环依赖的问题。可有时候我们又发现在用Spring进行依赖注入时,虽然Bean之间有循环依赖,但是代码本身却大概率能很正常的work,似乎也没有任何bug。
很多敏感的同学心里肯定有些犯嘀咕,循环依赖这种触犯因果律的事情怎么能发生呢?没错,这一切其实都并不是那么理所当然。
【manager层是个什么鬼 http://smartadmin.1024lab.net/doc/1/61】
不用manager层的弊端
因为特色,所以在分层这块,最终还是选择阿里的架构:分为四层,如下:
- controller
- service
- manager
- dao
传统的SpringMVC架构,分为Controller,Service,DAO三层。Controller控制页面逻辑,业务逻辑和事务在Service层,数据库操作通过编写sql在DAO层。
其实这样的架构非常简洁也容易上手,但是无法对DAO层的sql进行控制,弊端如下:
- service层代码臃肿
- service层事务嵌套,导致问题狠多
- dao层参杂业务
- dao层sql语句复杂,关联查询比较多
- dao层经常改来改去
引自《阿里规约》:
Manager 层:通用业务处理层,它有如下特征:
- 对第三方平台封装的层,预处理返回结果及转化异常信息;
- 对 Service 层通用能力的下沉,如缓存方案、中间件通用处理;
- 与 DAO 层交互,对多个 DAO 的组合复用。
其他:
4. 复杂业务,service提供数据给Manager层,然后把事务下层到Manager层,Manager层不允许相互调用,不会出现事务嵌套。
5. 专注于不带业务sql语言,也可以在manager层进行通用业务的dao层封装。
6. 避免复杂的join查询,数据库压力比java大很多,所以要严格控制好sql,所以可以在manager层进行拆分,比如复杂查询
但按照图中的分层结构,如果业务逻辑拆分为Serivce层对应业务逻辑、Manger层对应通用逻辑,那么Manger层就不建议相互调用,也没必要(因为每个Manger都处理一个子领域的问题)。那么复杂的业务逻辑,都在Service层解决,那么Service之间相互调用是合理的。】
在Service层出现异常时,必须记录日志信息到磁盘,尽可能带上参数信息,相当于保护案发现场。
Manager层与Service同机部署,日志方式与DAO层处理一致,如果是单独部署,则采用与Service一致的处理方式。
Web层绝不应该继续往上抛异常,因为已经处于顶层,无继续处理异常的方式,如果意识到这个异常将导致页面无法正常渲染,那么就应该直接跳转到友好错误页面,尽量加上友好的错误提示信息。
开放接口层要将异常处理成错误码和错误信息方式返回。
- DO(Data Object):与数据库表结构一一对应,通过DAO层向上传输数据源对象。
- DTO(Data Transfer Object):数据传输对象,Service或Manager向外传输的对象。
- BO(Business Object):业务对象。可以由Service层输出的封装业务逻辑的对象。
- Query:数据查询对象,各层接收上层的查询请求。额外规定:【强制】超过2个参数的查询封装,禁止使用Map类来传输。
- VO(View Object):显示层对象,通常是Web向模板渲染引擎层传输的对象。
二方库规约
-
【推荐】工具类二方库已经提供的,不要在本应用中编程实现。
- json操作: fastjson
- md5操作:commons-codec
- 工具集合:Guava包
- 数组操作:ArrayUtils(org.apache.commons.lang3.ArrayUtils)
- 集合操作:CollectionUtils(org.apache.commons.collections4.CollectionUtils)
- 除上面以外还有NumberUtils、DateFormatUtils、DateUtils等优先使用org.apache.commons.lang3这个包下的,不要使用org.apache.commons.lang包下面的。原因是commons.lang这个包是从JDK1.2开始支持的所以很多1.5/1.6的特性是不支持的,例如:泛型。
2.【推荐】所有pom文件中的依赖声明放在<dependencies>语句块中,实际在工程中引入的版本号由<dependencyManagement>明确指定。
说明:<dependencyManagement>里只是声明版本,并不实现引入,因此子项目需要显式的声明依赖,version和scope都读取自父pom。而<dependencies>所有声明在主pom的 <dependencies>里的依赖都会自动引入,并默认被所有的子项目继承
二、异常日志
异常处理
发
-
【强制】异常捕获后不要用来做流程控制,条件控制。
说明:异常设计的初衷是解决程序运行中的各种意外情况,且异常的处理效率比条件判断方式要低很多。 -
【强制】catch时请分清稳定代码和非稳定代码,稳定代码是本机运行且执行结果确定性高的代码。对于非稳定代码的catch尽可能进行区分异常类型,再做对应的异常处理。
说明:对大段代码进行try-catch,使程序无法根据不同的异常做出正确的应激反应,也不利于定位问题,这是一种不负责任的表现。 - 【强制】在调用RPC、二方包、或动态生成类的相关方法时,捕捉异常必须使用Throwable类来进行拦截。
说明:通过反射机制来调用方法,如果找不到方法,抛出NoSuchMethodException。什么情况会抛出NoSuchMethodError呢?二方包在类冲突时,仲裁机制可能导致引入非预期的版本使类的方法签名不匹配,或者在字节码修改框架(比如:ASM)动态创建或修改类时,修改了相应的方法签名。这些情况,即使代码编译期是正确的,但在代码运行期时,会抛出NoSuchMethodError。
-
【推荐】对于公司外的http/api开放接口必须使用“错误码”;跨应用间HSF调用优先考虑使用Result方式,封装isSuccess()方法、“错误码”、“错误简短信息”;而应用内部推荐异常抛出。
说明:关于HSF方法返回方式使用Result方式的理由:
1)中间件平台基本上使用ResultDTO来封装,由于中间件的普及,本身就有标准的引导含义。
2)使用抛异常返回方式,调用方如果没有捕获到就会产生运行时错误。
3)如果不加栈信息,只是new自定义异常,加入自己的理解的error message,对于调用端解决问题的帮助不会太多。如果加了栈信息,在频繁调用出错的情况下,数据序列化和传输的性能损耗也是问题。
日志规约
-
【强制】日志打印时禁止直接用JSON工具将对象转换成String。
说明:如果对象里某些get方法中直接抛出异常,则JSON工具调用其get方法时被迫中断而影响正常业务流程的执行。
正例:打印日志时仅打印出业务相关属性值或者调用其对象的toString()方法。
-
【强制】应用中不可直接使用日志系统(Log4j、Logback)中的API,而应依赖使用日志框架(SLF4J、JCL--Jakarta Commons Logging)中的API。什么是日志框架和日志系统,请参考webx作者宝宝的文章,文章里也详细说明了为什么不能直接依赖使用日志系统而是日志框架,以及应用的pom中如何做dependencyManagement。
说明:日志框架(SLF4J、JCL--Jakarta Commons Logging)的使用方式(推荐使用SLF4J):
使用SLF4J:import org.slf4j.Logger; import org.slf4j.LoggerFactory; private static final Logger logger = LoggerFactory.getLogger(Test.class);使用JCL:
import org.apache.commons.logging.Log; import org.apache.commons.logging.LogFactory; private static final Log log = LogFactory.getLog(Test.class);
一、编程规约
编程规约
-
【强制】POJO类必须写toString方法。使用工具类source> generate toString时,如果继承了另一个POJO类,注意在前面加一下super.toString。
说明:在方法执行抛出异常时,可以直接调用POJO的toString()方法打印其属性值,便于排查问题。 -
【强制】禁止在POJO类中,同时存在对应属性xxx的isXxx()和getXxx()方法。
说明:框架在调用属性xxx的提取方法时,并不能确定哪个方法一定是被优先调用到,神坑之一。
反例:珍爱生命,远离有毒getter -
【推荐】使用索引访问用String的split方法得到的数组时,需做最后一个分隔符后有无内容的检查,否则会有抛IndexOutOfBoundsException的风险。
说明:String str = "a,b,c,,"; String[] ary = str.split(","); // 预期大于3,结果是3 System.out.println(ary.length); -
多线程
-
【强制】线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
说明:使用线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源不足的问题。如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。 -
【强制】线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors返回的线程池对象的弊端如下:
1)FixedThreadPool和SingleThreadPool:
允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。(例如:假如我们设置了核心线程数和最大线程数都为5之后,如果线程一直被占用而没有释放,同时又有很多任务向线程池申请线程使用,这时我们会将任务放入队列中保存,生产者的速度远大于消费者,堆积的请求处理队列可能会耗费非常大的内存,甚至OOM);LinkedBlockingQueue是一个用链表实现的有界阻塞队列,容量可以选择进行设置,不设置的话,将是一个无边界的阻塞队列,最大长度为Integer.MAX_VALUE。2)
CachedThreadPool:
允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM。一、编程规约
1 public ThreadPoolExecutor(int corePoolSize, 2 int maximumPoolSize, 3 long keepAliveTime, 4 TimeUnit unit, 5 BlockingQueue<Runnable> workQueue, 6 ThreadFactory threadFactory, 7 RejectedExecutionHandler handler) { 8 if (corePoolSize < 0 || 9 maximumPoolSize <= 0 || 10 maximumPoolSize < corePoolSize || 11 keepAliveTime < 0) 12 throw new IllegalArgumentException(); 13 if (workQueue == null || threadFactory == null || handler == null) 14 throw new NullPointerException(); 15 this.corePoolSize = corePoolSize; 16 this.maximumPoolSize = maximumPoolSize; 17 this.workQueue = workQueue; 18 this.keepAliveTime = unit.toNanos(keepAliveTime); 19 this.threadFactory = threadFactory; 20 this.handler = handler; 21 }
参数列表
| 参数名 | 释义 |
|---|---|
| corePoolSize | 池中保存的核心线程数(包括空闲线程) |
| maximumPoolSize | 池中可保存的最大线程数 |
| keepAliveTime | 线程数大于corePoolSize时,空闲线程等待新任务的最长时间 |
| unit | keepAliveTime时间单位 |
| workQueue | 任务在执行之前,保持任务的队列。队列仅会被运行的执行方法提交 |
| threadFactory | 创建新线程时触发的factory |
| handler | 由于超出线程范围和队列容量而使执行被阻塞时所使用的处理程序 |
处理流程
分为四个"当":
1. 当池子中线程数小于corePoolSize就创建新线程,并处理请求的任务
2. 当池子中的线程数大小等于corePoolSize时,新的请求会被放入workQueue队列中,当池子里的线程完成任务空闲时会去队列里取任务去处理
3. 当workQueue容纳不下新请求的任务时,会新建线程并处理请求
4. 当池子内的线程数达到maximumPoolSize就会启用RejectedExecutionHandler进入拒绝处理
流程如下所示: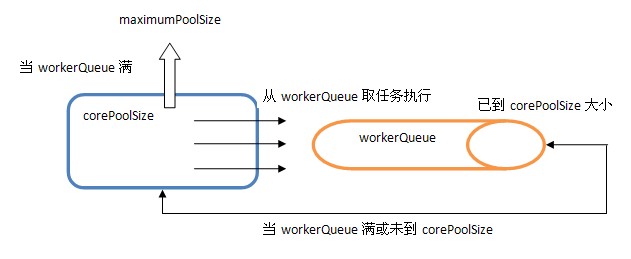
从中可以发现ThreadPoolExecutor就是依靠BlockingQueue的阻塞机制来维持线程池,当池子里的线程无事可干的时候就通过workQueue.take()阻塞住。
-
多线程


 浙公网安备 33010602011771号
浙公网安备 33010602011771号