
论《数据落地》的方案总结
序言
作为一个游戏服务端研发人员,从业10余年,被问及最多的话题是什么?
1,你们怎么处理高并发, 2,你们的吞吐量是多少? 3,你们数据怎么落地,服务器有状态还是无状态。 4,xxxxxxxxxxx
做如此类的问题,我相信这几个典型在被同行,领导,运营方,提出和问到最多的问题了。
今天我们重点是讲解数据落地方案。比如吞吐量啊,高并发啊在前面的文章也提到过,有兴趣的小伙伴可以自行查看哦
如果有什么问题就提出来,

言归正传
在此我先描述一下,游戏服务器的有状态和无状态区别,这是本人的描述好理解或许和你们不太一样别太介意就行;
我所说的无状态是指类似http服务器一样,没有数据缓存,所有的数据操作流程是
-> read db -> use -> save db;
有状态是指数据缓存在程序内部变量,第一次需要的时候发现缓冲池中没有加载到
-> memory cache -> read cache -> use -> save db(异步定时落地) -> 长时间未使用 memory delect;
本人在这么多年的游戏服务端研发中,都是做的有状态服务,
其实不管是有状态还是无状态都会牵涉一个问题,那就是数据落地;
一般来讲我们的数据落地都分为,同步落地和异步落地两个大类,
同时还有两个分支方案,就是全量落地和增量落地;
也就是说分为:
同步全量落地,同步增量落地,
异步全量落地,异步增量落地,
具体方案其实都是根据你的业务需求来,如果要保证万无一失,那么肯定是同步落地最为保险,比如TB,JD订单系统,但是带来的效果就是响应慢,
我们知道不管是秒杀还是双十一的血拼抢购,你是不是总感觉抢不到?或者提交订单慢的要死?《当然这不在本次讨论的范围》
我们今天讲解的是在游戏内如何做到数据落地;
我们先来建立一个实体模型类
1 package com.ty.backdata; 2 3 import java.io.Serializable; 4 5 /** 6 * @program: com.ty.minigame 7 * @description: 数据测试项 8 * @author: Troy.Chen(失足程序员 , 15388152619) 9 * @create: 2020-08-27 09:04 10 **/ 11 public class DataModel implements Serializable { 12 13 private static final long serialVersionUID = 1L; 14 15 private long id; 16 private String name; 17 private int level; 18 private long exp; 19 20 public long getId() { 21 return id; 22 } 23 24 public void setId(long id) { 25 this.id = id; 26 } 27 28 public String getName() { 29 return name; 30 } 31 32 public void setName(String name) { 33 this.name = name; 34 } 35 36 public int getLevel() { 37 return level; 38 } 39 40 public void setLevel(int level) { 41 this.level = level; 42 } 43 44 public long getExp() { 45 return exp; 46 } 47 48 public void setExp(long exp) { 49 this.exp = exp; 50 } 51 52 @Override 53 public String toString() { 54 return "DataModel{" + 55 "id=" + id + 56 ", name='" + name + '\'' + 57 ", level=" + level + 58 ", exp=" + exp + 59 '}'; 60 } 61 }
通常情况下我们怎么做数据落地
通常情况下的同步全量更新

这就是说,每一次操作都需要把数据完全写入到数据库,不管属性是否有变化;
这样一来全量更新就有一个性能问题,如果我的模型有很多属性(这里排除设计问题就是有很多属性),而且某些属性内容特别多,
然后这时候我们只是修改了其中一个不重要的数据,比方说
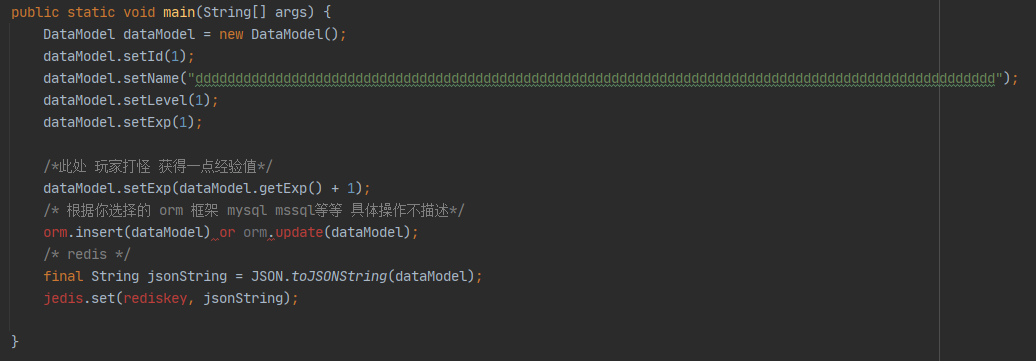
玩家通过打怪获得一点经验值,修改了经验值属性之后,需要save data;
这里只能全量更新;这样实际上浪费了很多 io 性能,因为数据根本没变化但是依然 save to db;
那么我们在这个时候我们是否就应该考虑,如何抛弃掉没有变化的属性值呢?
这里我们就需要考虑如何做到增量更新方案;
首先我们在考虑一点,增量更新就得有数据标识状态,
可能我们首先考虑到的第一方案是这样的
我们修改一下datamodel类
首先我们新增一个Map 属性对象来存储有变化的值
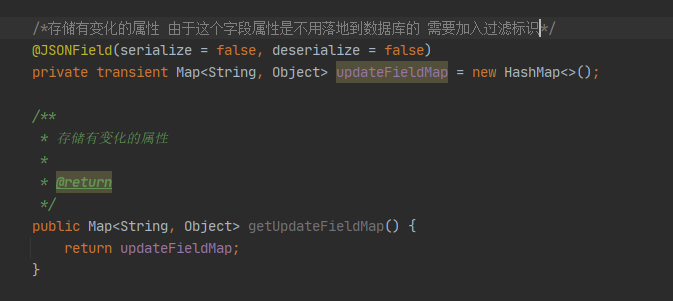
接下来是重点了,我们来修改属性的set方法
改造后的模型类就是这样的,


1 package com.ty.backdata; 2 3 import com.alibaba.fastjson.annotation.JSONField; 4 5 import java.io.Serializable; 6 import java.util.HashMap; 7 import java.util.Map; 8 9 /** 10 * @program: com.ty.minigame 11 * @description: 数据测试项 12 * @author: Troy.Chen(失足程序员 , 15388152619) 13 * @create: 2020-08-27 09:04 14 **/ 15 public class DataModel implements Serializable { 16 17 private static final long serialVersionUID = 1L; 18 19 /*存储有变化的属性 由于这个字段属性是不用落地到数据库的 需要加入过滤标识*/ 20 @JSONField(serialize = false, deserialize = false) 21 private transient Map<String, Object> updateFieldMap = new HashMap<>(); 22 23 /** 24 * 存储有变化的属性 25 * 26 * @return 27 */ 28 public Map<String, Object> getUpdateFieldMap() { 29 return updateFieldMap; 30 } 31 32 private long id; 33 private String name; 34 private int level; 35 private long exp; 36 37 public long getId() { 38 return id; 39 } 40 41 public void setId(long id) { 42 this.id = id; 43 /*我们考虑数据库的属性映射就用属性名字做为映射名*/ 44 this.updateFieldMap.put("id", id); 45 } 46 47 public String getName() { 48 return name; 49 } 50 51 public void setName(String name) { 52 this.name = name; 53 /*我们考虑数据库的属性映射就用属性名字做为映射名*/ 54 this.updateFieldMap.put("name", name); 55 } 56 57 public int getLevel() { 58 return level; 59 } 60 61 public void setLevel(int level) { 62 this.level = level; 63 /*我们考虑数据库的属性映射就用属性名字做为映射名*/ 64 this.updateFieldMap.put("level", level); 65 } 66 67 public long getExp() { 68 return exp; 69 } 70 71 public void setExp(long exp) { 72 this.exp = exp; 73 /*我们考虑数据库的属性映射就用属性名字做为映射名*/ 74 this.updateFieldMap.put("exp", exp); 75 } 76 77 @Override 78 public String toString() { 79 return "DataModel{" + 80 "id=" + id + 81 ", name='" + name + '\'' + 82 ", level=" + level + 83 ", exp=" + exp + 84 '}'; 85 } 86 }
测试一下看看效果
public static void main(String[] args) { DataModel dataModel = new DataModel(1, "失足程序员", 1, 1); System.out.println("查看属性值1:" + JSON.toJSONString(dataModel)); /*获得一点经验*/ dataModel.setExp(dataModel.getExp() + 1); /*等级提示一级*/ dataModel.setLevel(dataModel.getLevel() + 1); System.out.println("查看属性值2:" + JSON.toJSONString(dataModel)); System.out.println("查看有变化的属性:" + JSON.toJSONString(dataModel.getUpdateFieldMap())); // /* 根据你选择的 orm 框架 mysql mssql等等 具体操作不描述*/ // orm.insert(dataModel) or orm.update(dataModel); // /* redis */ // final String jsonString = JSON.toJSONString(dataModel); // jedis.set(rediskey, jsonString); }
输出结果
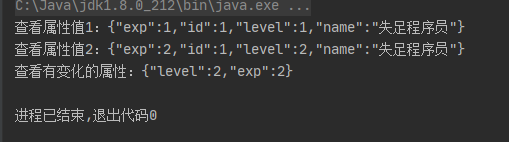
这样我们通过更改set方法,得到更新的属性字段来进行增量更新;
可能看到此处你是不是有疑问?这就完了?
当然没有,这样的方案虽然能得到有变化的属性值,
但是别忘记了一点,我们的程序可不止这一个数据模型,可不止这几个字段,并且我们开发人员可以不止只有一个。
这样的方案虽然可以解决问题,但是对研发规则苛刻。并且工作量非常大。
那么我们做架构的应该如何解决这样的问题?
首先来讲讲,我们上面提到的异步定时落地,
我们再次改造一下 DataModel 类 把原始的map存储改为 json 字符串 hashcode 值存储, 其实你可以直接存字符串,但是如果数据比较大的话,全部存储字符串比较耗内存,所有考虑hashcode
/*存储有变化的属性 由于这个字段属性是不用落地到数据库的 需要加入过滤标识*/ @JSONField(serialize = false, deserialize = false) private transient int oldJsonHashCode = 0; /** * 历史json字符串 hash code * * @return */ public int getOldJsonHashCode() { return oldJsonHashCode; } /** * 历史json字符串 hash code * * @param oldJsonHashCode */ public void setOldJsonHashCode(int oldJsonHashCode) { this.oldJsonHashCode = oldJsonHashCode; }
修改测试方案
package com.ty.backdata; import com.alibaba.fastjson.JSON; import java.util.HashMap; import java.util.Map; import java.util.Objects; /** * @program: com.ty.minigame * @description: 数据备份 * @author: Troy.Chen(失足程序员 , 15388152619) * @create: 2020-08-27 09:03 **/ public class BackDataMain { private static final long serialVersionUID = 1L; /*定义为缓存数据*/ private static Map<Long, DataModel> cacheDataMap = new HashMap<>(); public static void main(String[] args) { /*初始化测试数据*/ initData(); System.out.println("\n======================================================================\n"); /*先进行一次检查*/ for (Map.Entry<Long, DataModel> modelEntry : cacheDataMap.entrySet()) { checkData(modelEntry.getValue()); } System.out.println("\n======================================================================\n"); /*获取 id = 1 数据做修改*/ DataModel cacheData = cacheDataMap.get(1L); /*获得一点经验*/ cacheData.setExp(cacheData.getExp() + 1); /*等级提示一级*/ cacheData.setLevel(cacheData.getLevel() + 1); /*先进行一次检查*/ for (Map.Entry<Long, DataModel> modelEntry : cacheDataMap.entrySet()) { checkData(modelEntry.getValue()); } // /* 根据你选择的 orm 框架 mysql mssql等等 具体操作不描述*/ // orm.insert(dataModel) or orm.update(dataModel); // /* redis */ // final String jsonString = JSON.toJSONString(dataModel); // jedis.set(rediskey, jsonString); } /*初始化测试数据*/ public static void initData() { DataModel model1 = new DataModel(1, "失足程序员", 1, 1); String oldJsonString = JSON.toJSONString(model1); int code = Objects.hashCode(oldJsonString); model1.setOldJsonHashCode(code); System.out.println("原始:" + code + ", " + oldJsonString); cacheDataMap.put(model1.getId(), model1); DataModel model2 = new DataModel(2, "策划AA", 1, 1); oldJsonString = JSON.toJSONString(model2); code = Objects.hashCode(oldJsonString); model2.setOldJsonHashCode(code); System.out.println("原始:" + code + ", " + oldJsonString); cacheDataMap.put(model2.getId(), model2); } public static void checkData(DataModel model) { /*存储原始 json 值*/ String jsonString = JSON.toJSONString(model); int code = Objects.hashCode(jsonString); System.out.println("查看:" + code + ", " + jsonString); System.out.println("属性对比是否有变化:" + (model.getOldJsonHashCode() != code)); /*重新赋值hashcode*/ model.setOldJsonHashCode(code); } }
效验一下输出结果
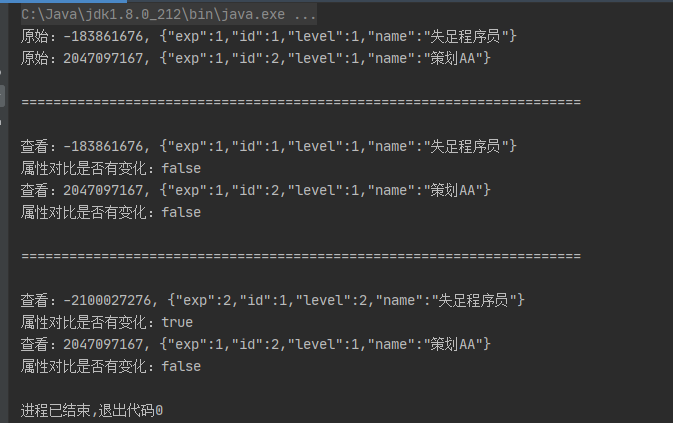
清晰的看到,这样,在这样的架构下,对于研发人员的编码格式要求就不在那么严谨;
也就是说不用怕他忘记修改set方法
但是我们可能依然发现其实这样的依然不是你想要的, 可能会问有没有更好的办法,既能增量更新,也能对研发人员少一些苛刻的严谨需求;
有当然有,既然你需求了,我们怎么能不满足你呢?
那么最好的方案啥呢?
反射,通过反射初始化模型属性为map对象,就和第一次的方案差不多类似;
但是这里是求差集;
也就是存储一次原始的模型对象所有属性的mao值,然后在下一次轮询的时候在获取一次属性的map值,来对比属性的值是否相等
继续修改 DataModel
/*存储有变化的属性 由于这个字段属性是不用落地到数据库的 需要加入过滤标识*/ @FieldAnn(alligator = true)/*自定义的注解,标识反射的时候是忽律字段*/ @JSONField(serialize = false, deserialize = false) private transient Map<String, String> oldFieldMap = new HashMap<>(); public Map<String, String> getOldFieldMap() { return oldFieldMap; } public void setOldFieldMap(Map<String, String> oldFieldMap) { this.oldFieldMap = oldFieldMap; }
引用测试关键点在于反射获取map对象,本文不标注,因为不是本文的重点,
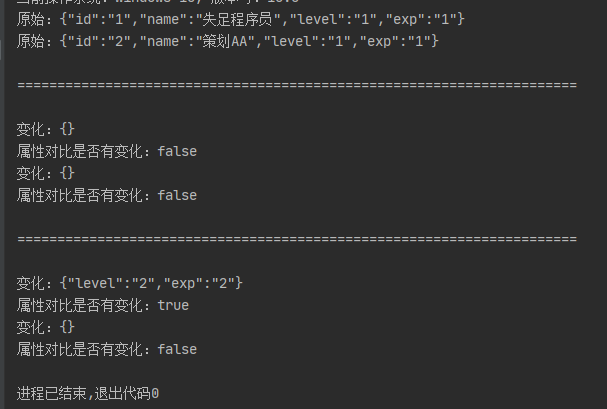
1 package com.ty.backdata; 2 3 import com.alibaba.fastjson.JSON; 4 import com.ty.tools.utils.FieldUtil; 5 6 import java.util.HashMap; 7 import java.util.Map; 8 9 /** 10 * @program: com.ty.minigame 11 * @description: 数据备份 12 * @author: Troy.Chen(失足程序员 , 15388152619) 13 * @create: 2020-08-27 09:03 14 **/ 15 public class BackDataMain { 16 17 private static final long serialVersionUID = 1L; 18 19 /*定义为缓存数据*/ 20 private static Map<Long, DataModel> cacheDataMap = new HashMap<>(); 21 22 public static void main(String[] args) { 23 /*初始化测试数据*/ 24 initData(); 25 System.out.println("\n======================================================================\n"); 26 /*先进行一次检查*/ 27 for (Map.Entry<Long, DataModel> modelEntry : cacheDataMap.entrySet()) { 28 checkData(modelEntry.getValue()); 29 } 30 System.out.println("\n======================================================================\n"); 31 /*获取 id = 1 数据做修改*/ 32 DataModel cacheData = cacheDataMap.get(1L); 33 /*获得一点经验*/ 34 cacheData.setExp(cacheData.getExp() + 1); 35 /*等级提示一级*/ 36 cacheData.setLevel(cacheData.getLevel() + 1); 37 /*先进行一次检查*/ 38 for (Map.Entry<Long, DataModel> modelEntry : cacheDataMap.entrySet()) { 39 checkData(modelEntry.getValue()); 40 } 41 // /* 根据你选择的 orm 框架 mysql mssql等等 具体操作不描述*/ 42 // orm.insert(dataModel) or orm.update(dataModel); 43 // /* redis */ 44 // final String jsonString = JSON.toJSONString(dataModel); 45 // jedis.set(rediskey, jsonString); 46 System.exit(0); 47 } 48 49 /*初始化测试数据*/ 50 public static void initData() { 51 DataModel model1 = new DataModel(1, "失足程序员", 1, 1); 52 Map<String, String> objectFieldMap = FieldUtil.getObjectFieldMap(model1); 53 model1.setOldFieldMap(objectFieldMap); 54 System.out.println("原始:" + JSON.toJSONString(objectFieldMap)); 55 cacheDataMap.put(model1.getId(), model1); 56 57 DataModel model2 = new DataModel(2, "策划AA", 1, 1); 58 objectFieldMap = FieldUtil.getObjectFieldMap(model2); 59 model2.setOldFieldMap(objectFieldMap); 60 System.out.println("原始:" + JSON.toJSONString(objectFieldMap)); 61 cacheDataMap.put(model2.getId(), model2); 62 } 63 64 public static void checkData(DataModel model) { 65 /*存储原始 json 值*/ 66 Map<String, String> objectFieldMap = FieldUtil.getObjectFieldMap(model); 67 68 final Map<String, String> oldFieldMap = model.getOldFieldMap(); 69 Map<String, String> tmp = new HashMap<>(); 70 /*求出差集*/ 71 for (Map.Entry<String, String> stringStringEntry : objectFieldMap.entrySet()) { 72 final String key = stringStringEntry.getKey(); 73 final String value = stringStringEntry.getValue(); 74 final String oldValue = oldFieldMap.get(key); 75 if (oldValue == null || !value.equals(oldValue)) { 76 /*如果原来没有这个属性值 或者属性发生变更*/ 77 tmp.put(key, value); 78 } 79 } 80 System.out.println("变化:" + JSON.toJSONString(tmp)); 81 System.out.println("属性对比是否有变化:" + (tmp.size() > 0)); 82 /*重新赋值最新的*/ 83 model.setOldFieldMap(objectFieldMap); 84 } 85 86 }
重点代码是下面的求差集获取map增量更新代码
public static void checkData(DataModel model) { /*存储原始 json 值*/ Map<String, String> objectFieldMap = FieldUtil.getObjectFieldMap(model); final Map<String, String> oldFieldMap = model.getOldFieldMap(); Map<String, String> tmp = new HashMap<>(); /*求出差集*/ for (Map.Entry<String, String> stringStringEntry : objectFieldMap.entrySet()) { final String key = stringStringEntry.getKey(); final String value = stringStringEntry.getValue(); final String oldValue = oldFieldMap.get(key); if (oldValue == null || !value.equals(oldValue)) { /*如果原来没有这个属性值 或者属性发生变更*/ tmp.put(key, value); } } System.out.println("变化:" + JSON.toJSONString(tmp)); System.out.println("属性对比是否有变化:" + (tmp.size() > 0)); /*重新赋值最新的*/ model.setOldFieldMap(objectFieldMap); }
输出结果
总结
本文提供了四种落地方案,
全量落地和增量落地
不同实现的四种方案,
第一种全量更新
优点就是代码少,坑也少, 缺点就是性能不是很高;
第二种全量更新
优点:提升了落地性能,也不用考虑开发人员的行为规范问题, 缺点:在架构初期就要考虑进去,代码实现量有所增加。
第一种增量更新
优点:解决了性能消耗问题,不用反射也不用第三方格式化判断等, 缺点:对开发人员的行为规范要求比较严格,如果遗漏了很可能出现数据问题;
第二种增量更新
优点:不考虑开发人员的行为规范,也实现了增量更新,减少数据交付导致的io瓶颈 缺点:增加了代码量和判断量,但是这样的量对比数据交互io,微不足道;
不知道各位是否还有其他更加优化的方案!!!!
期待你的点评;
跪求保留标示符 /** * @author: Troy.Chen(失足程序员, 15388152619) * @version: 2021-07-20 10:55 **/ C#版本代码 vs2010及以上工具可以 java 开发工具是netbeans 和 idea 版本,只有项目导入如果出现异常,请根据自己的工具调整 提供免费仓储。 最新的代码地址:↓↓↓ https://gitee.com/wuxindao 觉得我还可以,打赏一下吧,你的肯定是我努力的最大动力


 浙公网安备 33010602011771号
浙公网安备 33010602011771号