
爬虫笔记:下载小说(十四)
1.背景介绍:
小说网站,“新笔趣阁”:
https://www.xsbiquge.com/
“新笔趣阁”只支持在线浏览,不支持小说打包下载。本文就是练习下载一篇名为《药师的宠妃之路》的网络小说。
2、爬虫步骤
爬虫其实很简单,可以大致分为三个步骤:
-
发起请求:我们需要先明确如何发起 HTTP 请求,获取到数据。
-
解析数据:获取到的数据乱七八糟的,我们需要提取出我们想要的数据。
-
保存数据:将我们想要的数据,保存下载。
发起请求,我们就用 requests 就行。
解析数据工具有很多,比如xpath、Beautiful Soup、正则表达式等。本文就用一个简单的经典小工具,Beautiful Soup来解析数据。
保存数据,就是常规的文本保存。
3.Beautiful Soup安装
我们我可以使用pip来安装,在cmd命令窗口中的安装命令如下:
pip安装:pip install beautifulsoup4
安装好后,还需要安装 lxml,这是解析 HTML 需要用到的依赖:pip install lxml
4.开始
我们先看下《药师的宠妃之路》小说的第一章内容。
https://www.xsbiquge.com/94_94355/76936.html

我们先获取 HTML 信息试一试,编写代码如下:
import requests
if __name__=='__main__':
target='https://www.xsbiquge.com/94_94355/76936.html'
req=requests.get(url=target)
req.encoding='utf-8'
print(req.text)
爬虫的第一步“发起请求”,得到的结果如下:
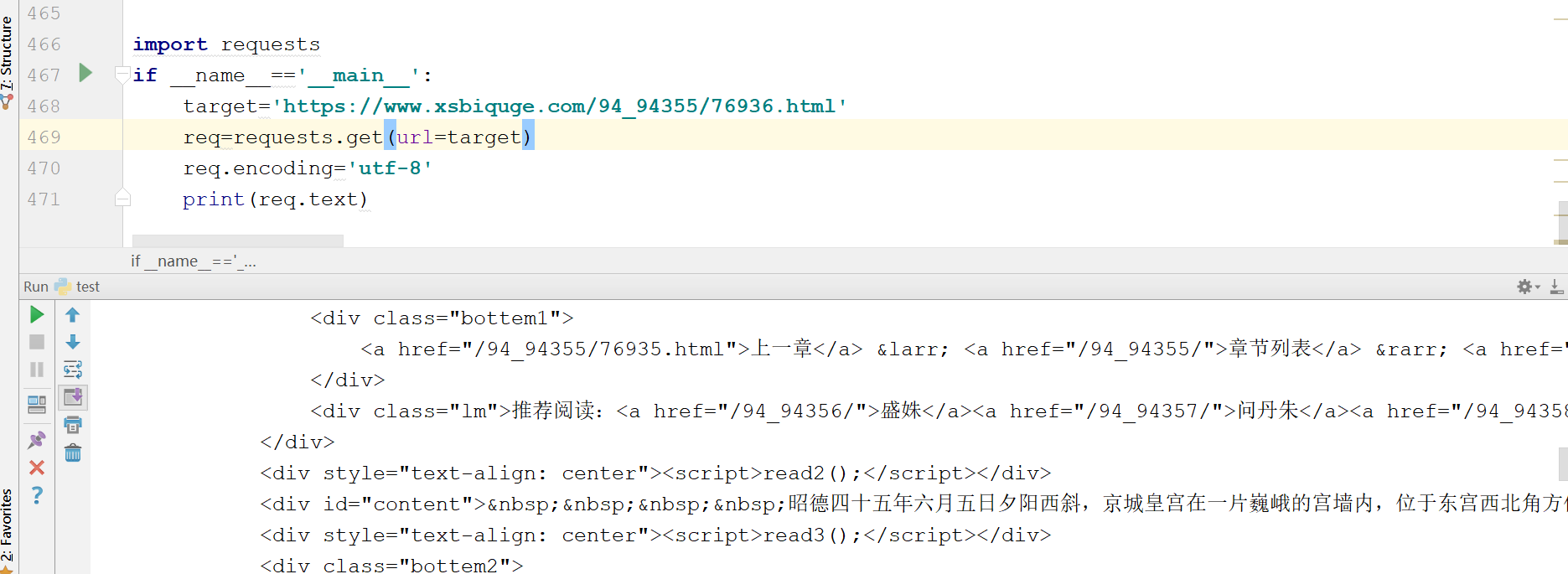
可以看到,我们获取了html信息,里面有我们想要的小说正文内容,但是也包含了一些其他内容,我们不关心div,br这些html标签
如何把正文内容从这些众多的html标签中提取出来?
进入爬虫的第二部“解析数据”,也就是使用Beautiful Soup进行解析
现在,对目标页面进入审查元素,会看到:
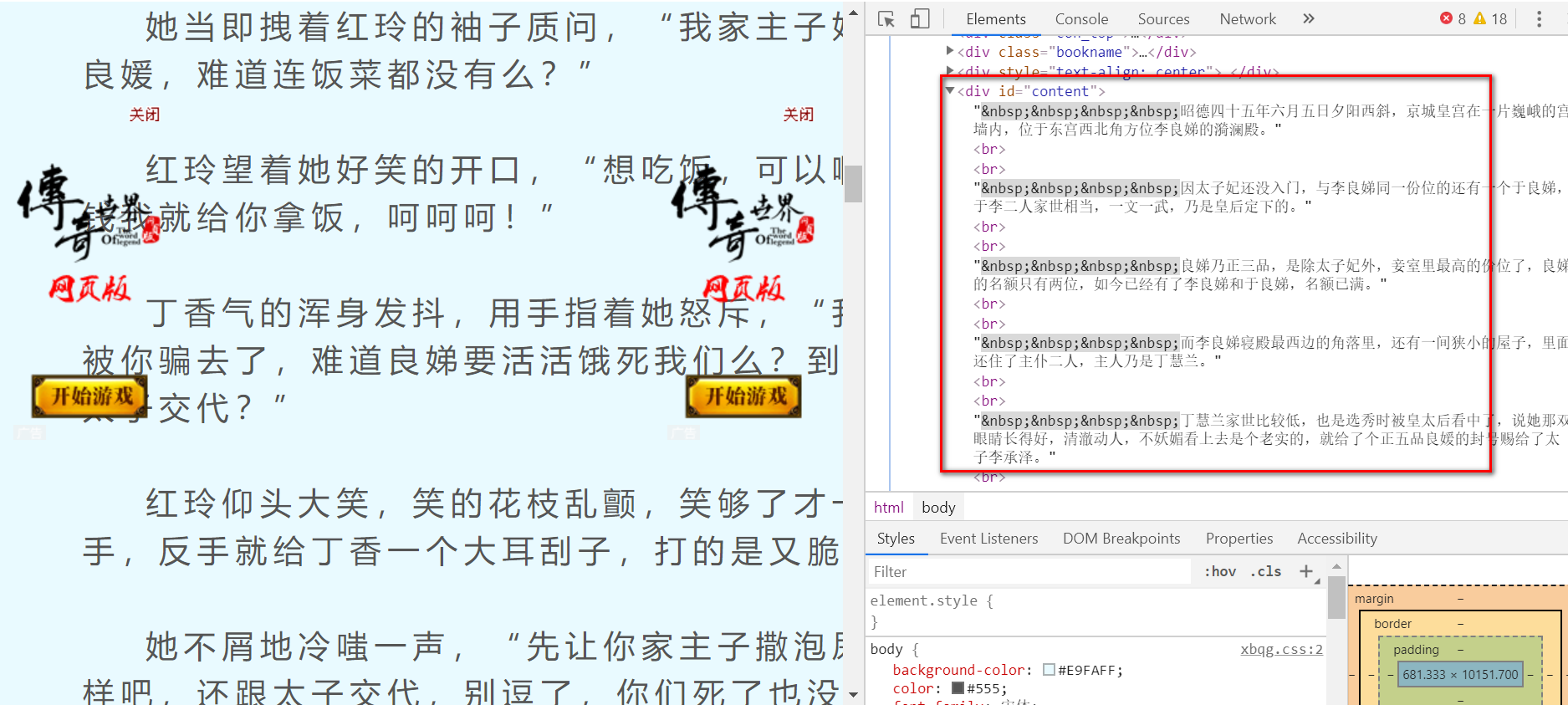
文章的内容存在了id=content的div标签里,可以使用Beautiful Soup提取我们想要的正文内容,代码如下:
import requests
from bs4 import BeautifulSoup
if __name__=='__main__':
target='https://www.xsbiquge.com/94_94355/76936.html'
req=requests.get(url=target)
req.encoding='utf-8'
html=req.text
bs=BeautifulSoup(html,'lxml')
texts=bs.find('div',id='content')
print(texts)
bs.find('div',id='content')的意思就是,找到id属性为content的div标签
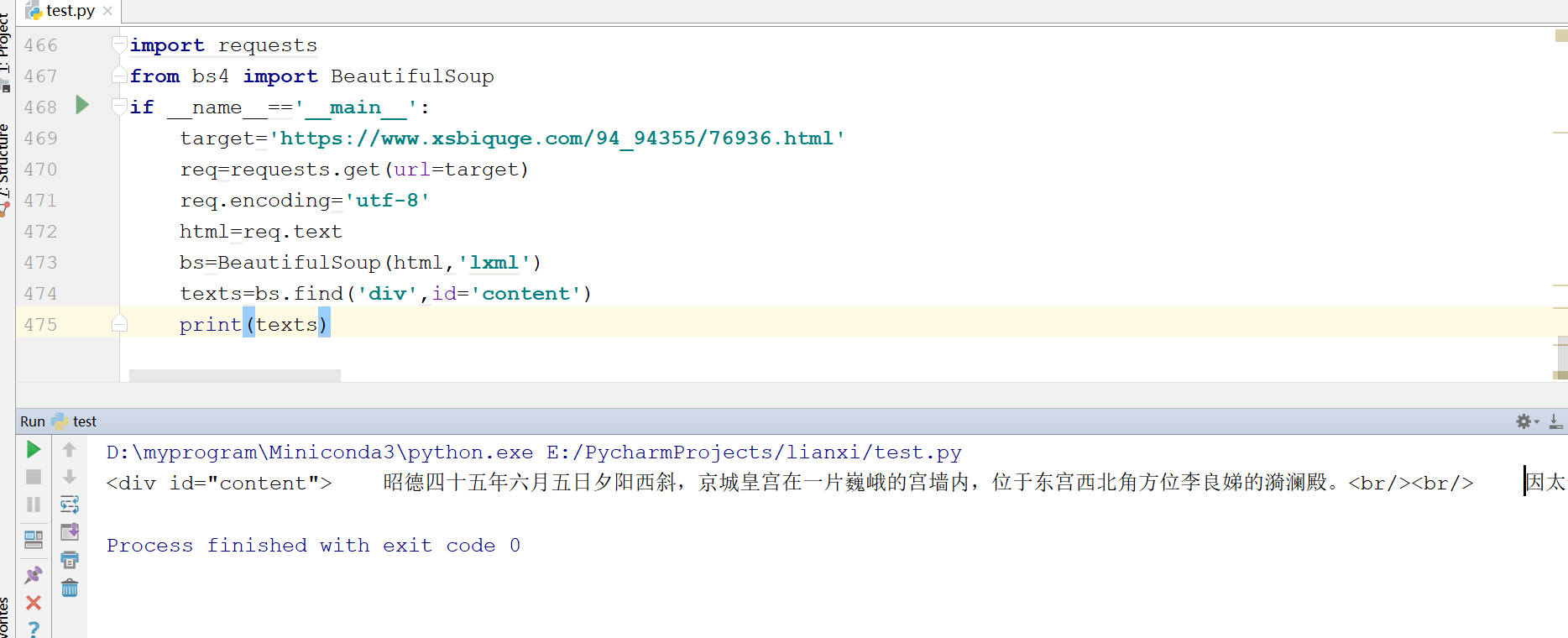
可以看到,正文内容已经顺利提取,但是里面还有一些div和br这类标签,我们需要进一步清洗数据
import requests
from bs4 import BeautifulSoup
if __name__=='__main__':
target='https://www.xsbiquge.com/94_94355/76936.html'
req=requests.get(url=target)
req.encoding='utf-8'
html=req.text
bs=BeautifulSoup(html,'lxml')
texts=bs.find('div',id='content')
print(texts.text.strip().split('\xa0'*4))
texts.text是提取所有文字,然后再使用strip方法去掉回车,最后使用split方式根据\xa0切分数据,因为每一段的开头,都有四个空格
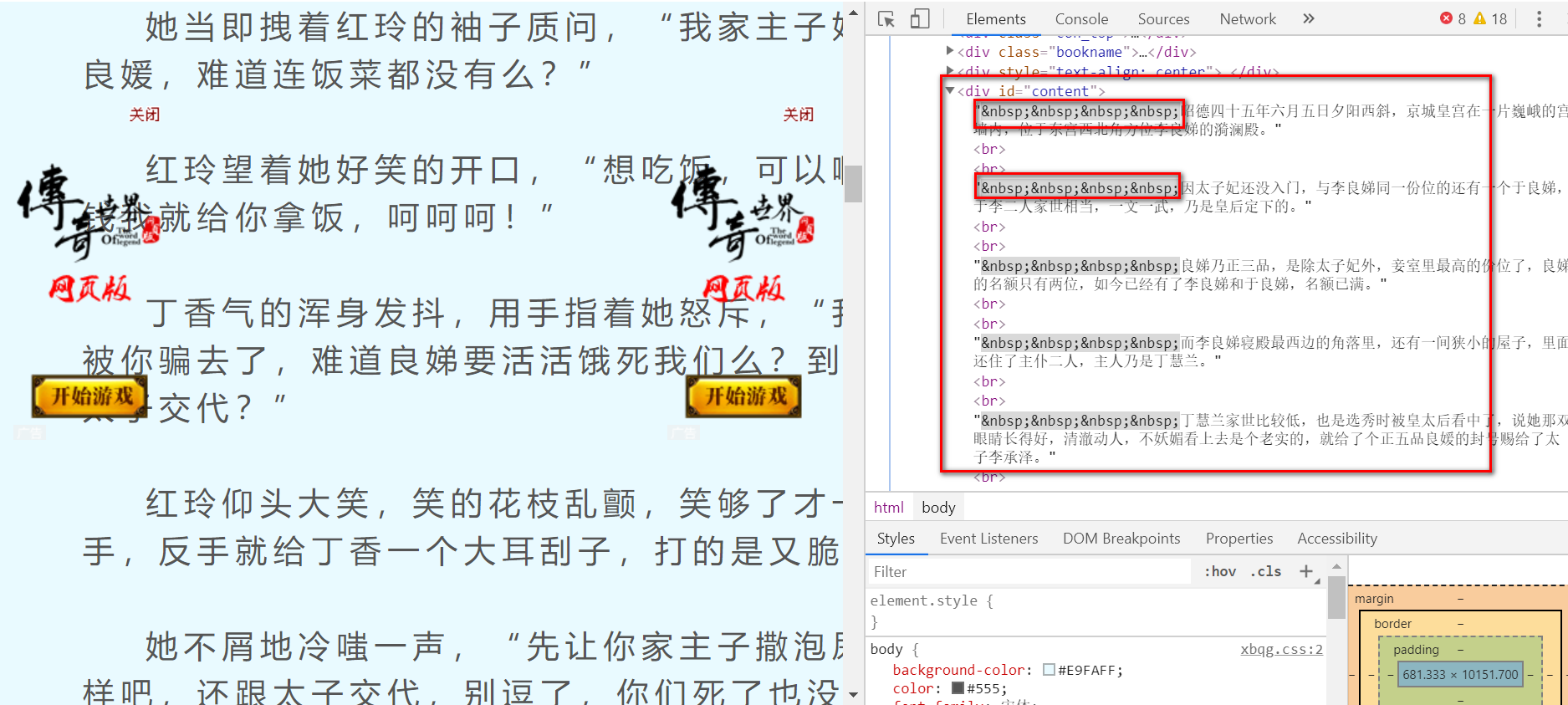
程序运行结果如下:
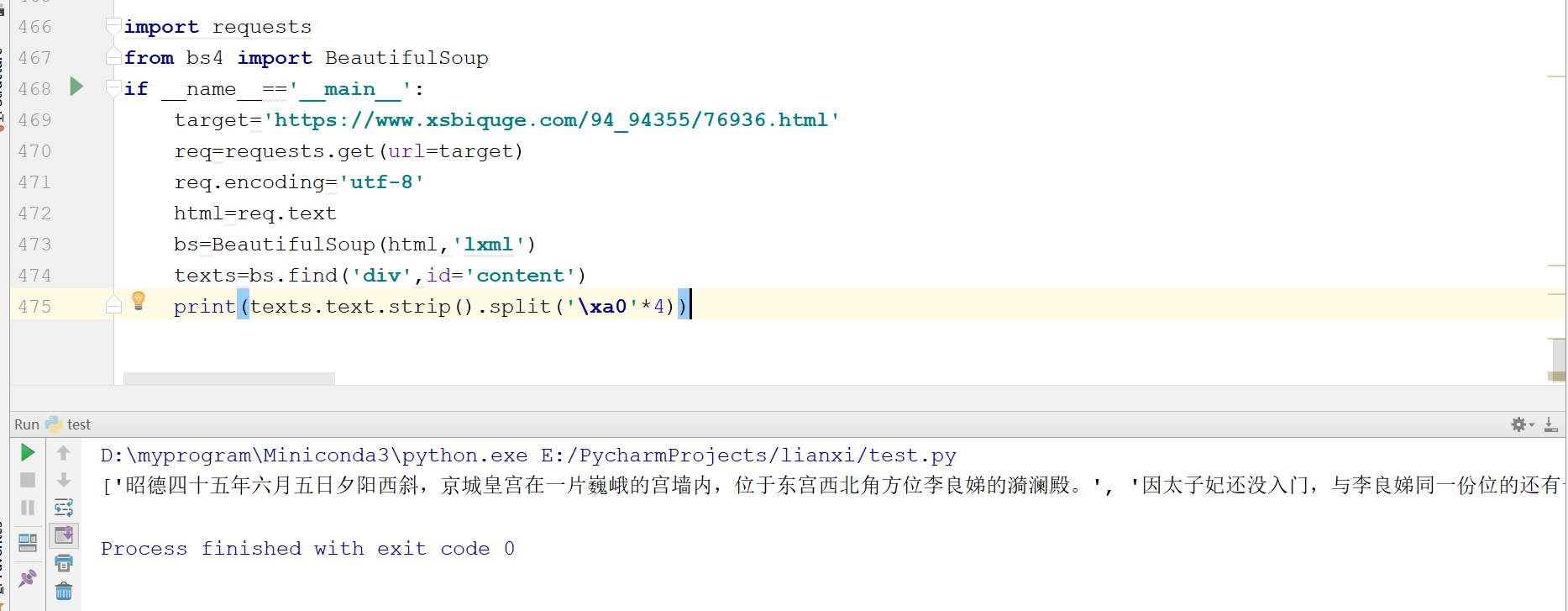
所有的内容,已经清洗干净,保存到一个列表里了
小说正文,已经顺利获取到了。要想下载整本小说,我们就要获取每个章节的连接,我们先分析下小说目录:
https://www.xsbiquge.com/94_94355/
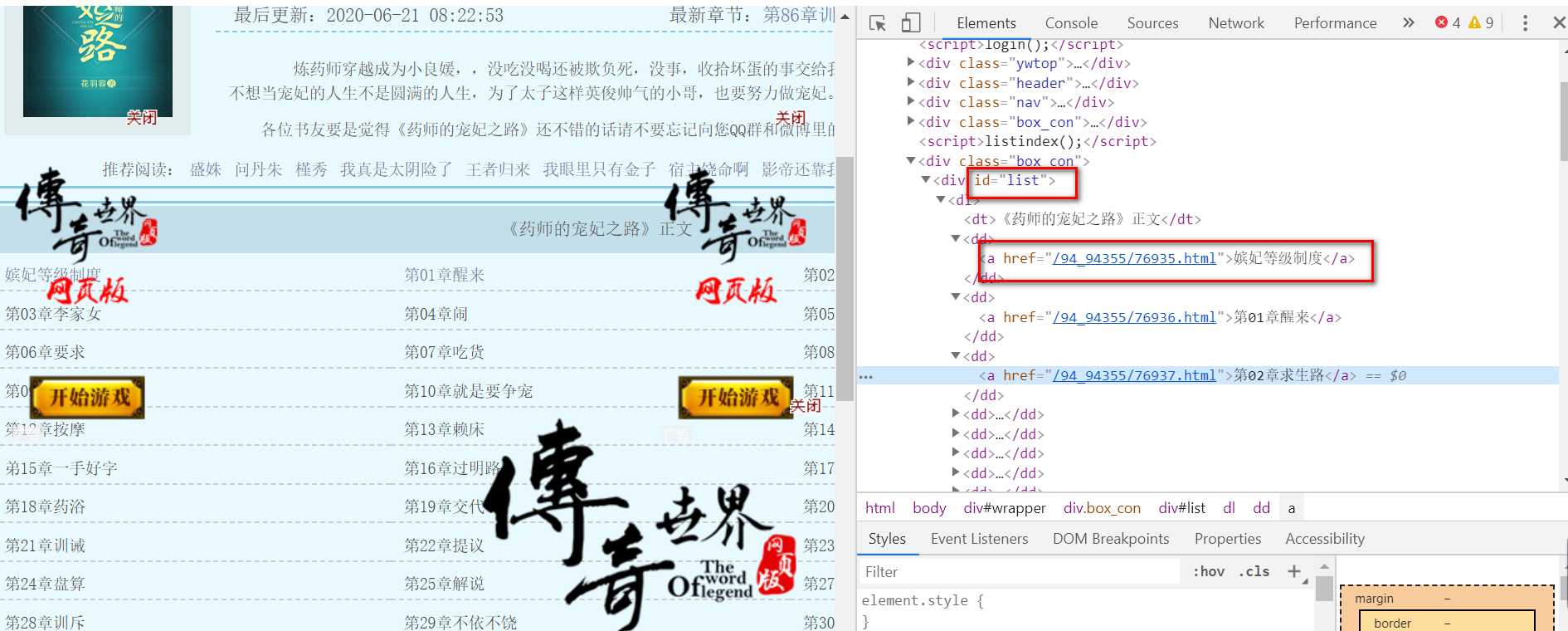
审查元素后发现,所有的章节信息,都存放到了id属性为list的div标签下的a标签内,代码:
import requests
from bs4 import BeautifulSoup
if __name__=='__main__':
target='https://www.xsbiquge.com/94_94355/'
req=requests.get(url=target)
req.encoding='utf-8'
html=req.text
bs=BeautifulSoup(html,'lxml')
chapters=bs.find('div',id='list')
chapters=chapters.find_all('a')
for chapters in chapters:
print(chapters)
bs.find('div',id='list')就是找到id属性为list的div标签,chapters.find_all('a')就是在找到的div标签里,再提取出所有a标签,运行结果:
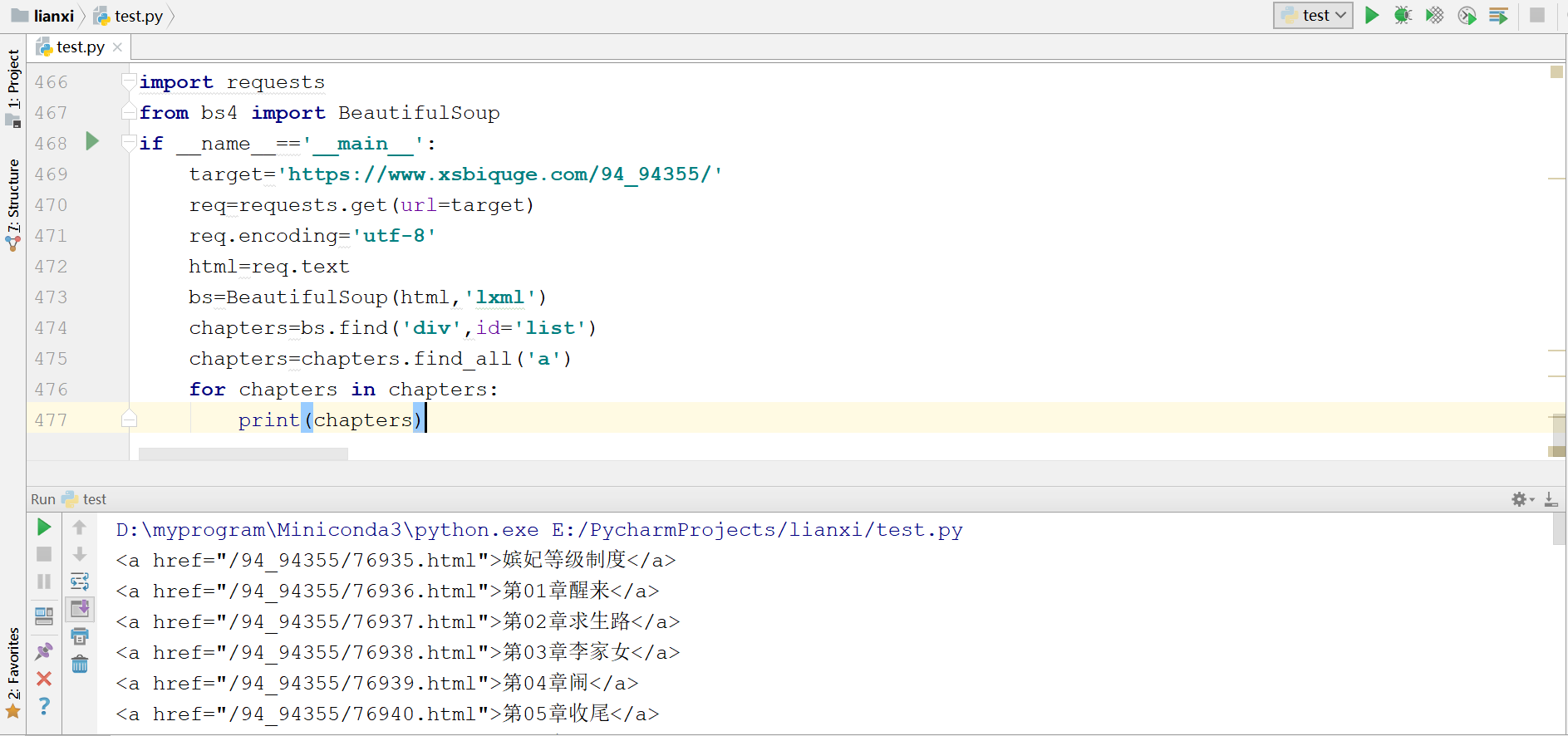
可以看到章节链接和章节名我们已经提取出来,但是还需要进一步解析,代码如下:
import requests
from bs4 import BeautifulSoup
if __name__=='__main__':
server='https://www.xsbiquge.com'
target='https://www.xsbiquge.com/94_94355/'
req=requests.get(url=target)
req.encoding='utf-8'
html=req.text
bs=BeautifulSoup(html,'lxml')
chapters=bs.find('div',id='list')
chapters=chapters.find_all('a')
for chapters in chapters:
url=chapters.get('href')
print(chapters.string)
print(server+url)
chapters.get('href')方法提取了href属性,并拼接出属性url,使用chapters.string方法提取了章节名
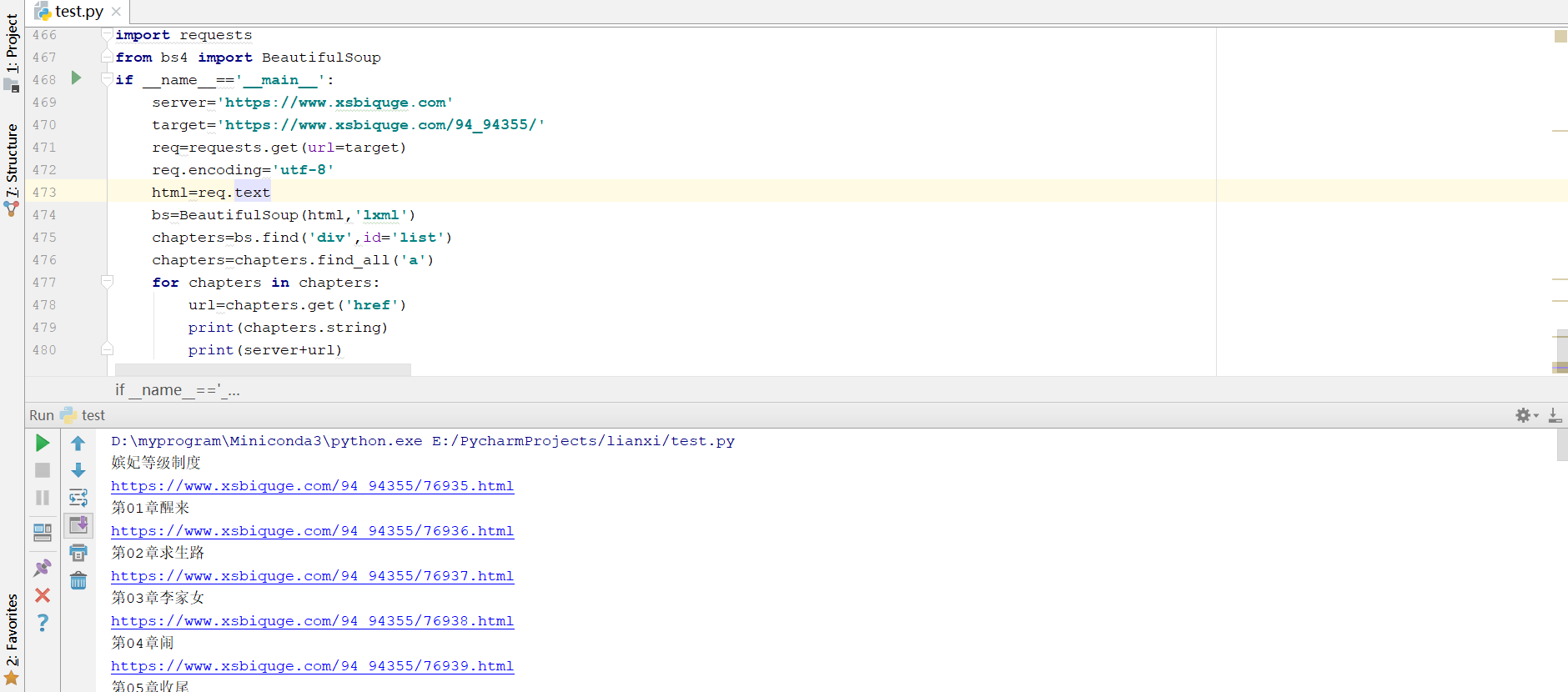
每个章节的链接,章节名,章节内容都有了,接下来就是整合代码,将内容保存到txt即可。代码如下
import requests
import time
from bs4 import BeautifulSoup
def get_content(target):
req=requests.get(url=target)
req.encoding='utf-8'
html=req.text
bs=BeautifulSoup(html,'lxml')
texts=bs.find('div',id='content')
content=texts.text.strip().split('\xa0'*4)
return content
if __name__=='__main__':
server='https://www.xsbiquge.com'
book_name='药师的宠妃之路.txt'
target='https://www.xsbiquge.com/94_94355/'
req=requests.get(url=target)
req.encoding='utf-8'
html=req.text
chapters_bs=BeautifulSoup(html,'lxml')
chapters=chapters_bs.find('div',id='list')
chapters=chapters.find_all('a')
for chapters in chapters:
chapters_name=chapters.string
url=server+chapters.get('href')
content=get_content(url)
with open(book_name,'a',encoding='utf-8') as f:
f.write(chapters_name)
f.write('\n')
f.write('\n'.join(content))
f.write('\n')
这样找到保存的txt文件,就可以看的下载的所有内容了。
参考链接:
https://mp.weixin.qq.com/s/5e2_r0QXUISVp9GdDsqbzg

 浙公网安备 33010602011771号
浙公网安备 33010602011771号