
爬虫笔记:使用python生成词云(八)
什么是词云呢?
词云就是一些关键词组成的一个图片。大家在网上经常看到,下面看一些例子:

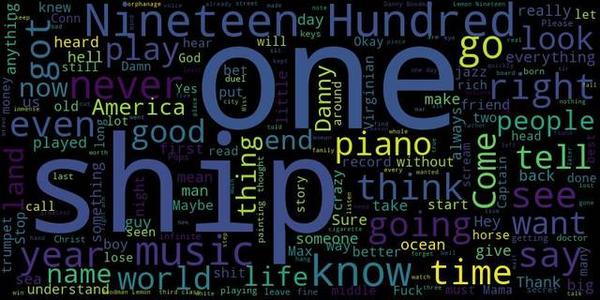
那用python生成一个词云的话怎么办呢,首先要有一些词,随便找个吧,用see you again的歌词好了,放到again.txt里面,放着待会用。
然后呢,咱们用 wrodcloud这个模块,他可以实现分词,生成咱们想要的词云图片,直接使用pip install wordcloud安装即可。
过程呢,就是先读取到歌词,然后给WordCloud,让他帮咱们分词,分词的意思就是把里面的一些关键词提取出来,以及指定图片的大小,背景颜色,字体等等,废话不多说,直接上代码。
from wordcloud import WordCloud #导入词云模块
words = open('again.txt',encoding='utf-8').read()#打开歌词文件,获取到歌词
wordcloud = WordCloud(width=1000, #图片的宽度
height=860, #高度
margin=2, #边距
background_color='black',#指定背景颜色
font_path='C:\Windows\Fonts\Sitka Banner\msyh.ttc'#指定字体文件,要有这个字体文件,自己随便想用什么字体,就下载一个,然后指定路径就ok了
)
wordcloud.generate(words) #分词
wordcloud.to_file('again.jpg')#保存到图片
注意,这个地方可能会报“OSError: cannot open resource”的一个错误,这是由于找不到字体的原因。我上面的字体位置就是系统中字体位置,所以如果报错了,检查一下是否有该字体,更换一下就好。
简单的几行代码就ok拉,下面是生成的效果图

但是wordcloud这个模块对中文分词支持不怎么好,因为英文每个单词都是空格分开的,但是中文每个词语并部署,另外有个模块,对中文分词的比较好,这个模块是jieba,直接pip install jieba即可。
下面咱们再找个歌词,来个中文的,找到一路向北的歌词,保存到ylxb.txt里面,然后先使用wordcloud分词,保存到,ylxb1.jpg里面,再用jiba来分词,保存到ylxb2.jpg里面,看看差别
第一张,wordcloud自带的分词之后的词云

第二张,使用jieba分词之后的词云

明显就能看出来第一个基本就没有分词,使用jieba之后,把歌词里面的一些词语提取了出来,下面是代码。
import jieba
from wordcloud import WordCloud #导入词云模块
words = open('ylxb',encoding='utf-8').read()#打开歌词文件,获取到歌词
new_words = ' '.join(jieba.cut(words))#使用jieba.cut分词,然后把分好的词变成一个字符串,每个词用空格隔开
wordcloud = WordCloud(width=1000, #图片的宽度
height=860, #高度
margin=2, #边距
background_color='black',#指定背景颜色
font_path='C:\Windows\Fonts\Sitka Banner\msyh.ttc'#指定字体文件,要有这个字体文件,自己随便想用什么字体,就下载一个,然后指定路径就ok了;刚才的字体适用于英文字体,用在中文字体上会报错,所以换了一个中文字体
)
wordcloud.generate(new_words) #分词
wordcloud.to_file('ylxb2.jpg')#保存到图片
ok,词云已经生成了,很完美。但是我看到别人的词云,都是各种形状的,为啥咱们都是一个矩形呢。当然是可以解决的了,咱们想让它成什么形状就是什么形状,需要先找到一个有形状的图片,我这里找了一棵树的图片作为例子,然后需要用到PIL模块,处理图片,用numpy把这个图片的各种属性转成数字,这2个模块需要安装,都是用pip安装即可,pip install PIL,pip install numpy。先看下图片
原来的高跟鞋参照物

下面是产生高跟鞋形状的词云

下面直接上代码
import jieba,numpy
from PIL import Image#导入PIL模块处理图片
from wordcloud import WordCloud #导入词云模块
words = open('ylxb.txt',encoding='utf-8').read()#打开歌词文件,获取到歌词
new_words = ' '.join(jieba.cut(words))#使用jieba.cut分词,然后把分好的词变成一个字符串,每个词用空格隔开
alice_mask = numpy.array(Image.open('gaogenxie.jpg'))
#使用pil模块打开这个图片,然后用numpy获取到这个图片各种乱八七糟的属性
wordcloud = WordCloud(width=1000, #图片的宽度
height=860, #高度
margin=2, #边距
mask=alice_mask,
background_color='#d4ff80',#指定背景颜色,这里用的是颜色代码
font_path='C:\Windows\Fonts\Sitka Banner\msyh.ttc'#指定字体文件,要有这个字体文件,自己随便想用什么字体,就下载一个,然后指定路径就ok了
)
wordcloud.generate(new_words) #分词
wordcloud.to_file('ylxb3.jpg')#保存到图片

 浙公网安备 33010602011771号
浙公网安备 33010602011771号