
python正则表达式(\ [ ])(三)
对元字符的转义:
反斜杠\在正则表达式中有多种用途。
比如,我们要在下面的文本中搜索,所有点前面的字符串,也包含点本身。
苹果.是绿色的 橙子.是橙色的 香蕉.是黄色的
如果,我们这样写正则表达式.*.,聪明的你肯定发现不对劲
因为点是一个元字符,直接出现在正则表达式中,表示匹配任意的单字符,不能表示.这个字符本身的意思了
如果我们要搜索的内容本身就包含元字符,就可以使用反斜杠进行转义
这里我们就应使用这样的表达式:.*\.
示例,python程序如下:
content='''
苹果.是绿色的
橙子.是橙色的
香蕉.是黄色的
'''
import re
p=re.compile(r' .*\.')
for one in p.findall(content):
print(one)
匹配某种字符类型
反斜杠后面接一下字符,表示匹配某种类型的一个字符
比如
\d 匹配0-9之间任意一个数字字符,等价于表达式[0-9]
\D 匹配任意一个不是0-9之间的数字字符,等价于表达式[^0-9]
\s 匹配任意一个空白字符,包括 空格,tab,换行符等,等价于表达式[\t\n\r\f\v]
\S 匹配任意一个非空白字符,等价于表达式[^\t\n\r\f\v]
\w 匹配任意一个文字字符,包括大小写字母,数字,下划线,等价于表达式[a-zA-Z0-9_]
\W 匹配任意一个非文字字符,等价于表达式[^a-zA-Z0-9_]
\b:
It's a nice day today.
'I' 占一个位置,'t' 占一个位置,所有的单个字符(包括不可见的空白字符)都会占一个位置,这样的位置我给它取个名字叫“显式位置”。
注意:字符与字符之间还有一个位置,例如 'I' 和 't' 之间就有一个位置(没有任何东西),这样的位置我给它取个名字叫“隐式位置”。
“隐式位置”就是 \b 的关键!通俗的理解,\b 就是“隐式位置”。
此时,再来理解一下这句话:
如果需要更精确的说法,\b 匹配这样的位置:它的前一个字符和后一个字符不全是(一个是,一个不是或不存在) \w。
我用我的话来翻译一下这句话:
“隐式位置” \b,匹配这样的位置:它的前一个“显式位置”字符和后一个“显式位置”字符不全是 \w。
python代码示例:
import re s="i love you not because 12sd 34er 56df e4 54434" content=re.findall(r"\b\d",s) print (content)'''['1', '3', '5', '5']''' import re s="i love you not because 12sd 34er 56df e4 54434" content=re.findall(r"\d",s) print (content) '''['1', '2', '3', '4', '5', '6', '4', '5', '4', '4', '3', '4']'''
反斜杠也可以用在方括号里面,比如[\s,.]表示匹配:任何空白字符,或者逗号,或者点
举例:
source='''
王亚辉
tony
刘文武
'''
import re
p=re.compile(r'\w{2,4}',re.A)
print (p.findall(source))
'''['tony']'''
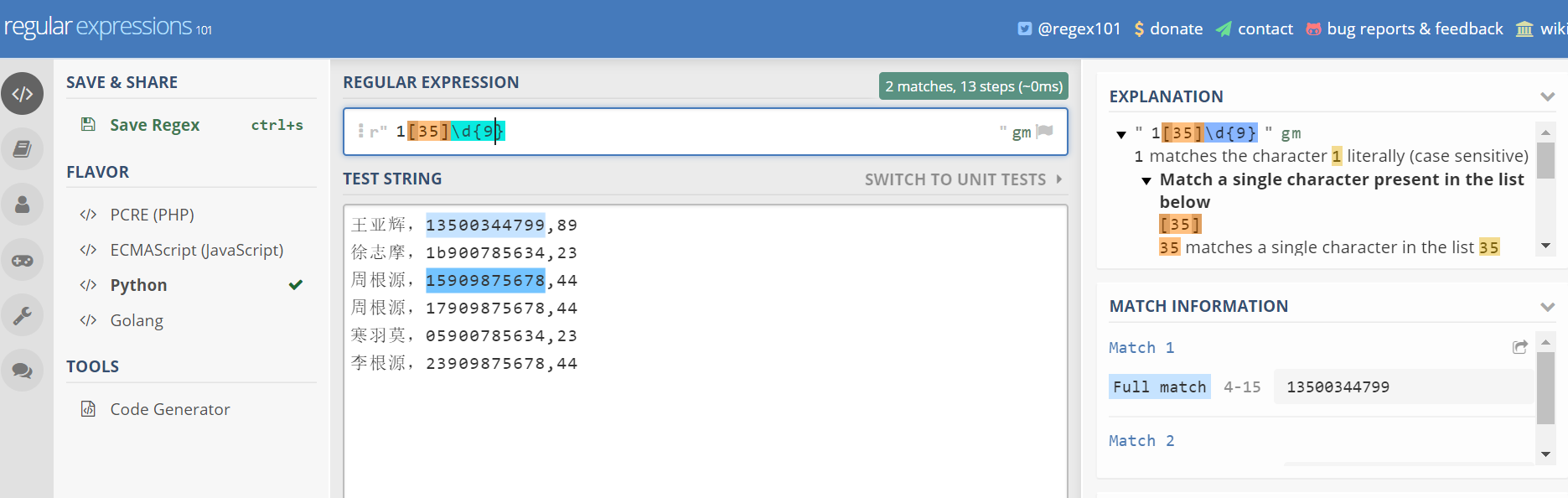
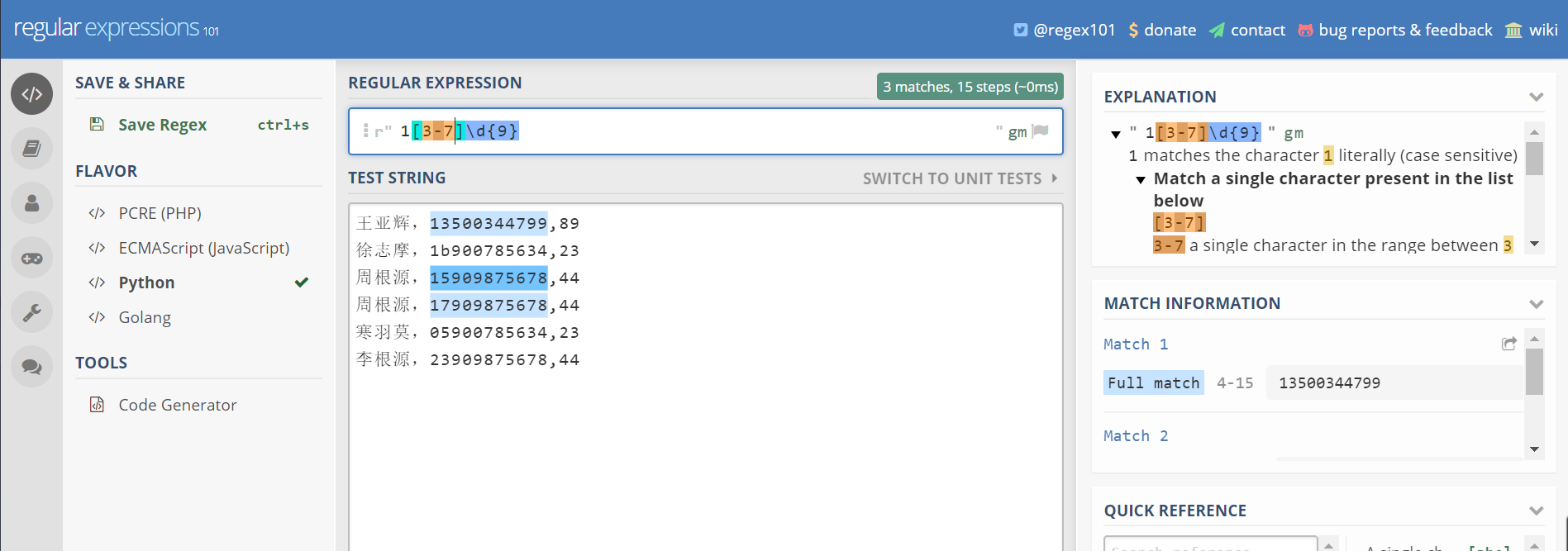
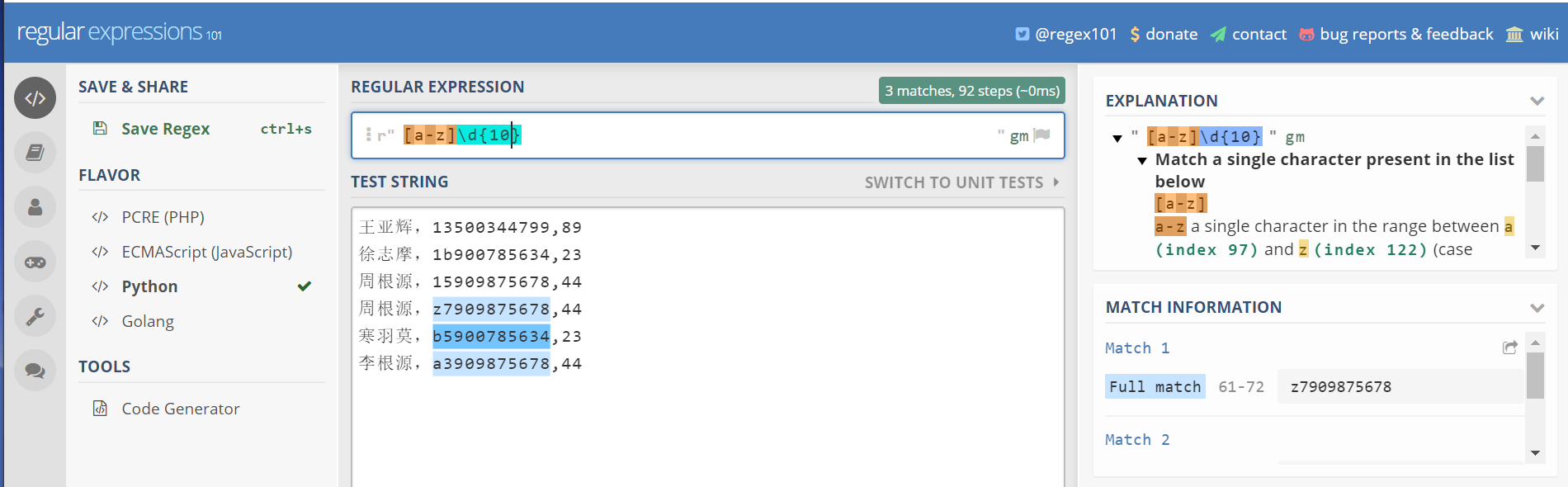
方括号-匹配某几种类型
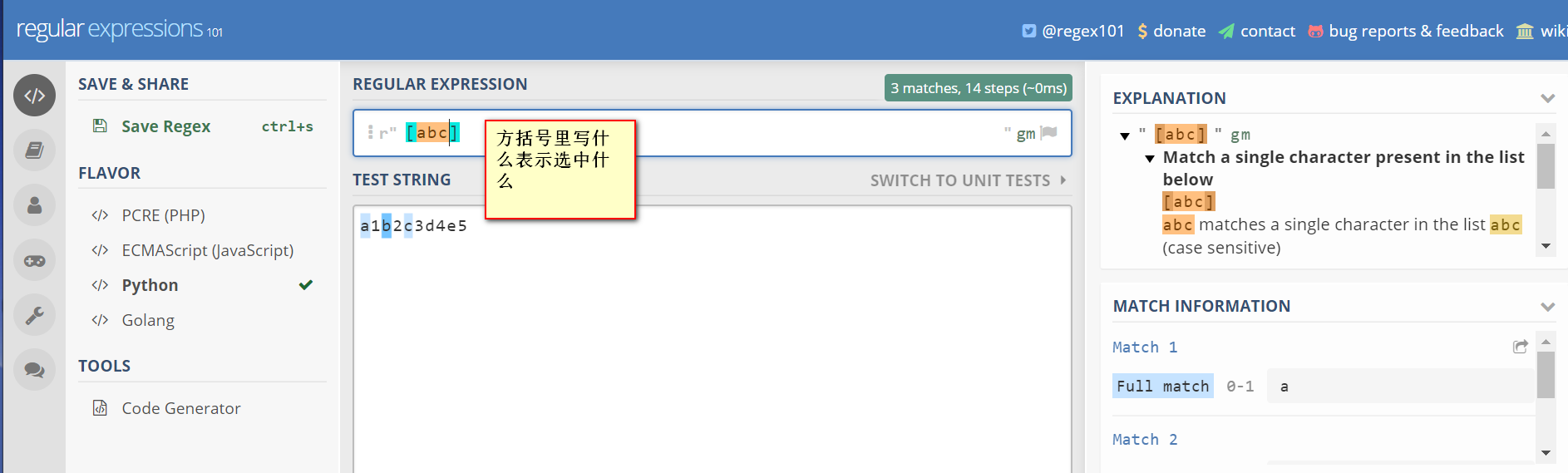
方括号表示要匹配某几种类型的字符
比如
[abc]可以匹配a,b,或者c里面的任意一个字符,等价于[a-c]
[a-c]中间的-表示一个范围从a到c
如果你想匹配所有的小写字母,可以使用[a-z]
一些元字符在方括号内失去了魔法,变得和普通字符一样了
比如,
[akm.]匹配 a k m . 里面任意一个字符
这里 . 在括号里面不在表示匹配任意字符了,而是表示匹配 . 这个字符
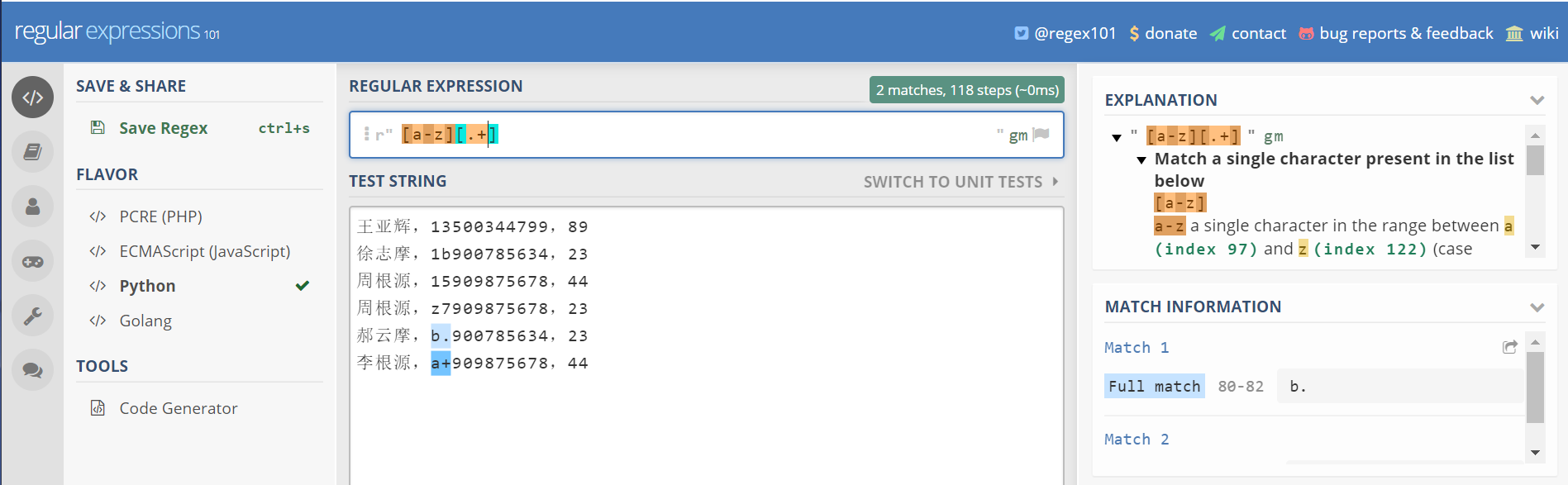
起始位置
^表示匹配文本的起始位置
如果是多行模式,表示匹配文本每行的开头位置
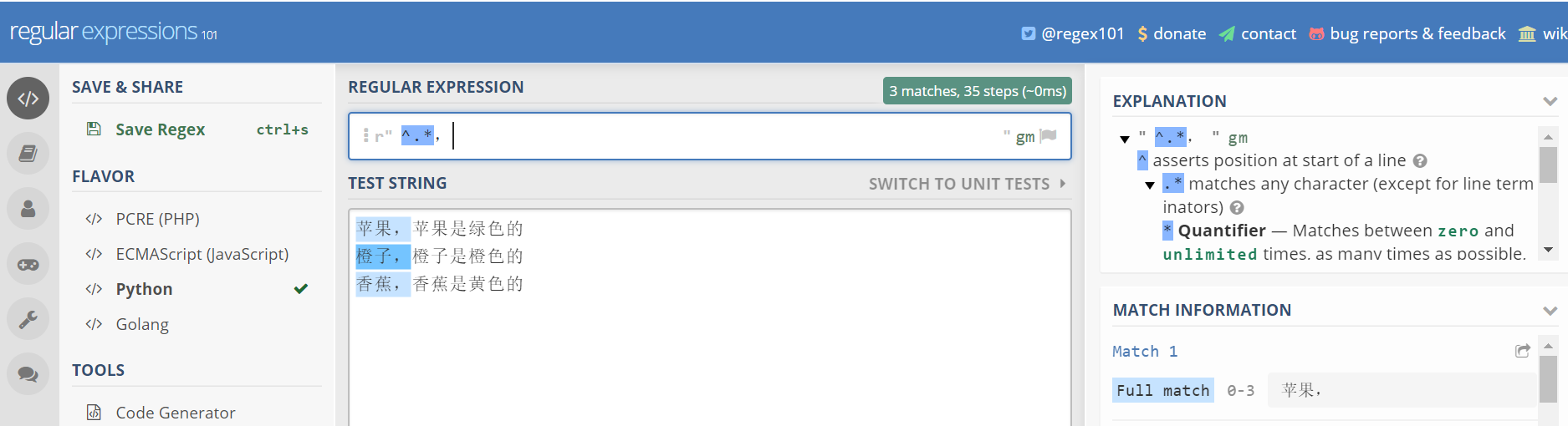
比如,你要从下面的文本中,选择每行逗号前面的字符串,也包括逗号本身
苹果,苹果是绿色的 橙子,橙子是橙色的 香蕉,香蕉是黄色的
就可以这样写正则表达式^.*.
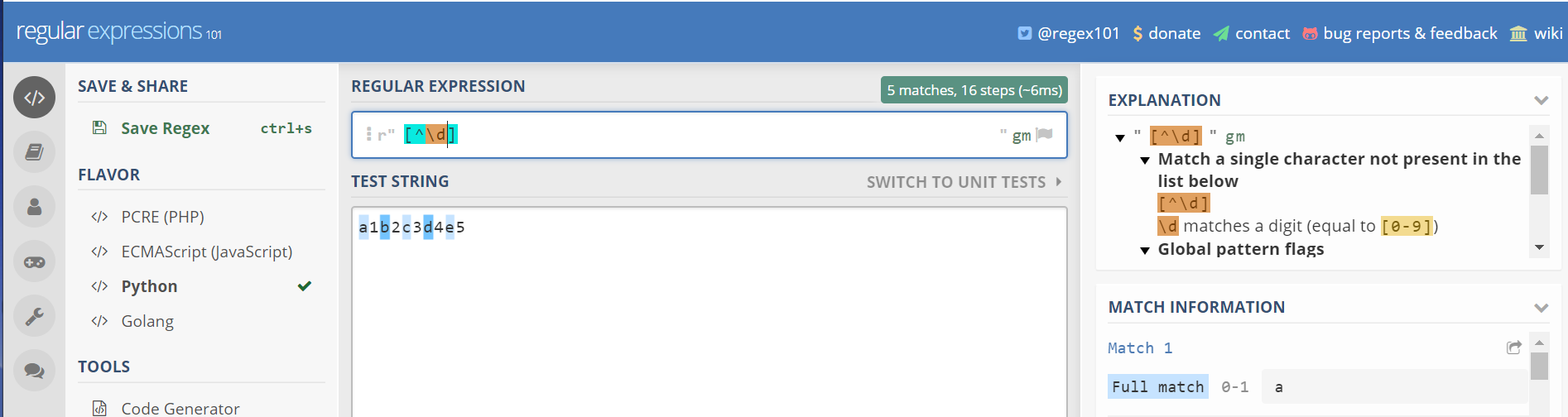
如果在方括号中使用^,表示非 方括号里面的字符集合([^\d],表示,选择非数字的字符)
比如:
content='a1b2c3d4e5'
import re
p=re.compile(r'[^\d]')
for one in p.findall(content):
print(one)
'''
输出结果:
a
b
c
d
e
'''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号