
python正则表达式(+ {})(二)
加号-重复匹配多次
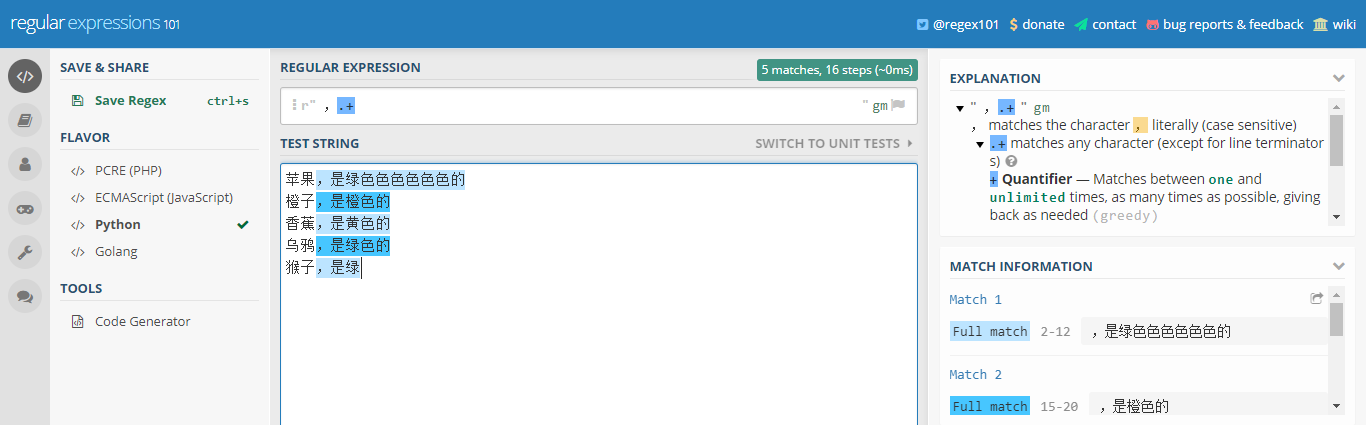
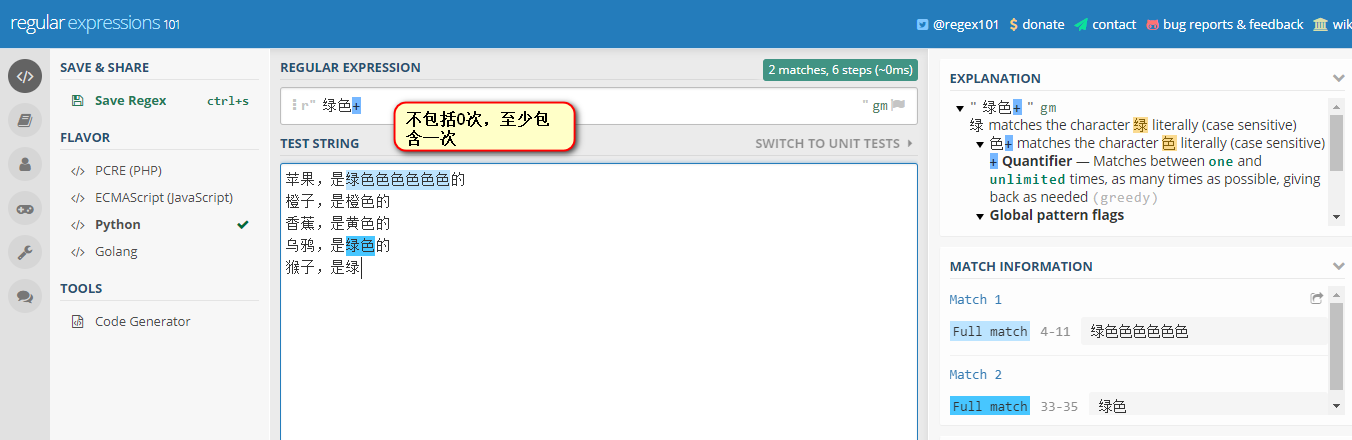
+ 表示匹配前面的子表达式一次或多次,不包括0次
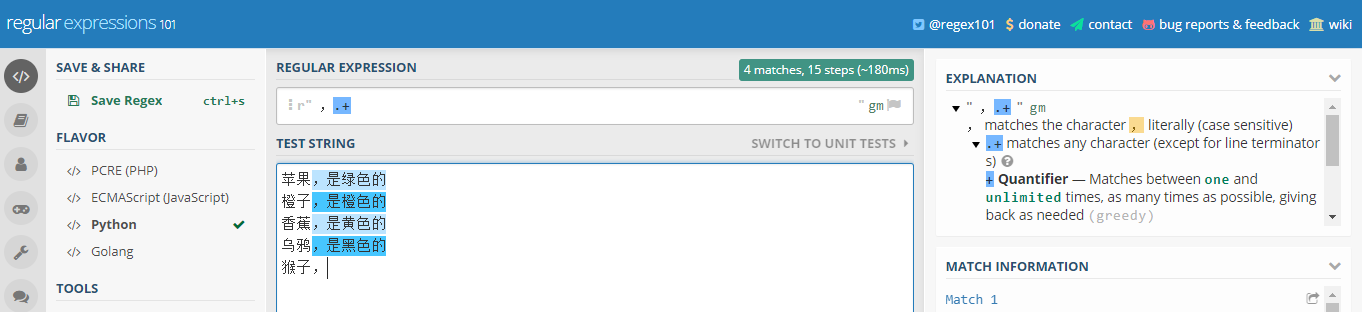
比如,还是上面的例子,你要从文本中,选择每行逗号后面的字符串内容,包括逗号本身
但是,添加一个条件,如果逗号后面没有内容,就不要选择了。
比如,下面的文本中,最后一行逗号后面没有内容了,就不要选择了
苹果,是绿色的 橙子,是橙色的 香蕉,是黄色的 乌鸦,是黑色的 猴子,
就可以这样写正则表达式 ,.+
验证一下如下图所示( + 和 * 的区别就是:不包括0次,所以没有选中最后一行):
,.+
绿色+
.+色
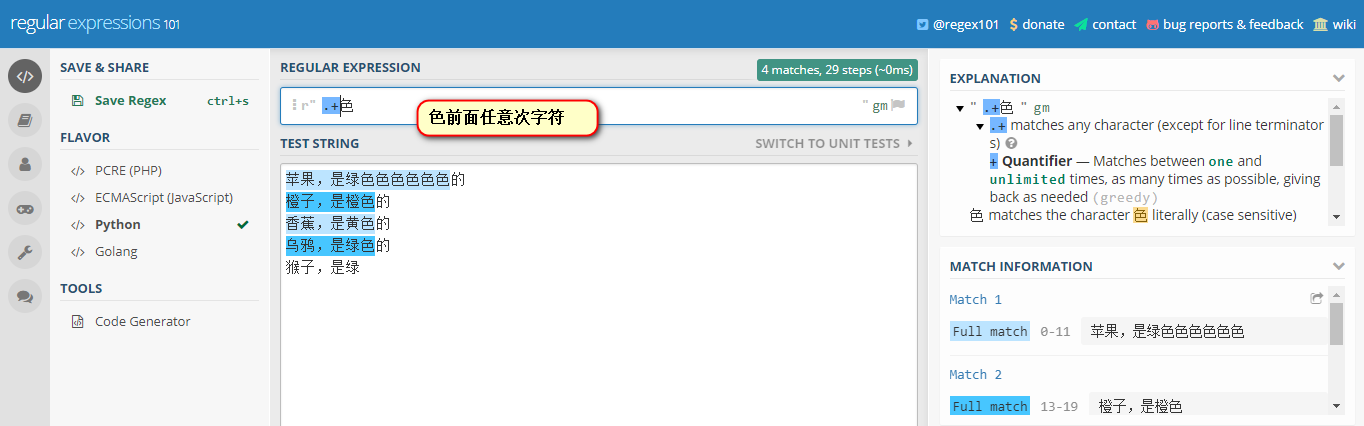
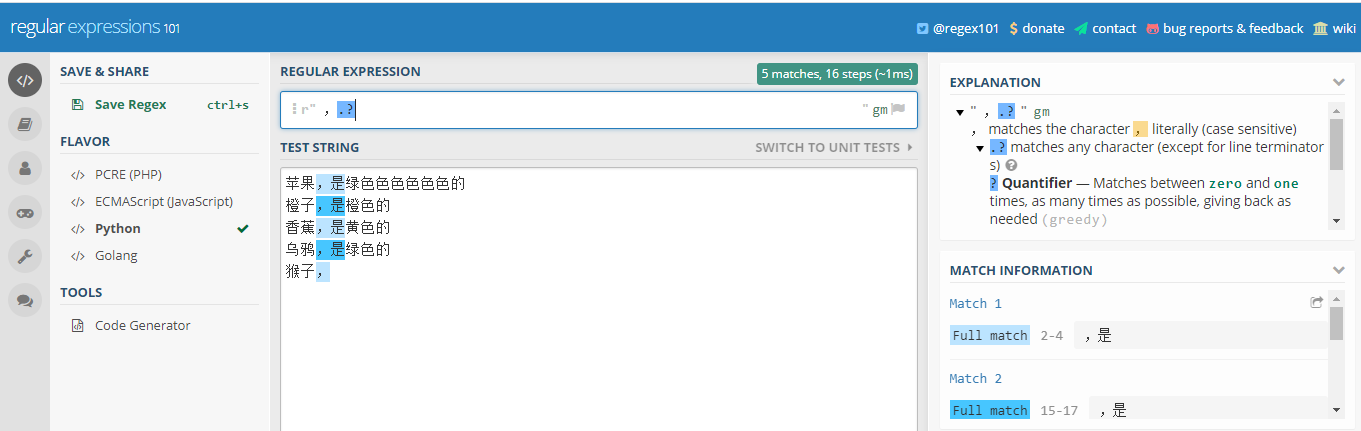
最后一行,猴子逗号后面没有其他字符了,但是?表示匹配一次或0次,所以最后一行也选中了一个逗号字符
,.?
花括号-匹配指定次数
花括号表示前面的字符匹配 指定的次数
比如,下面的文本
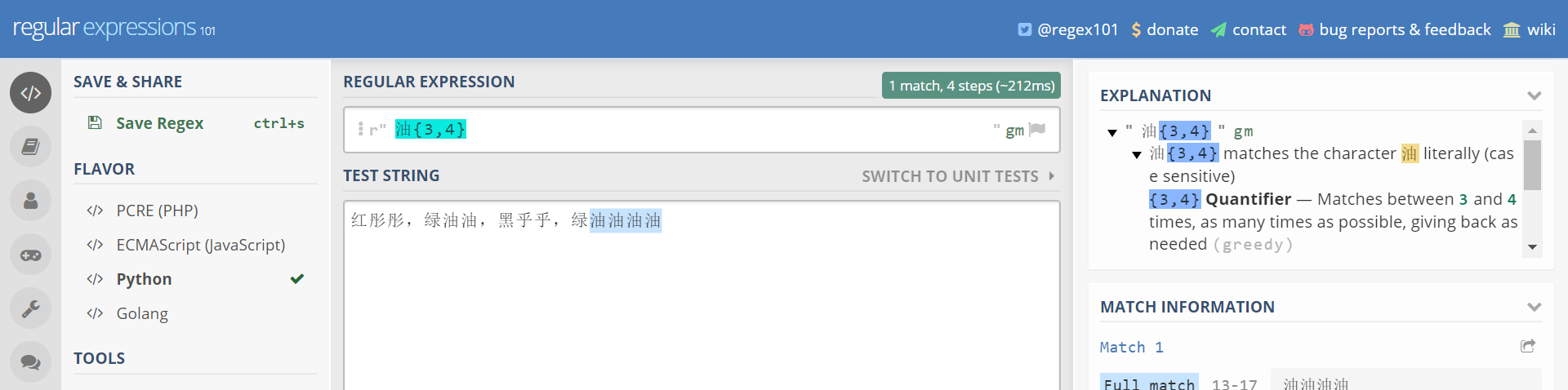
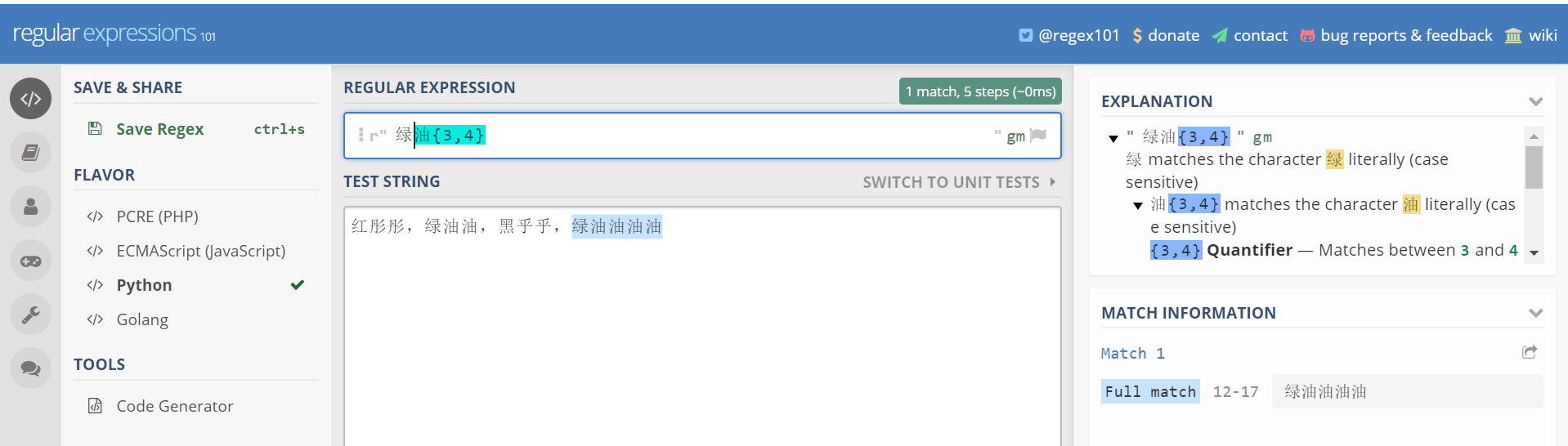
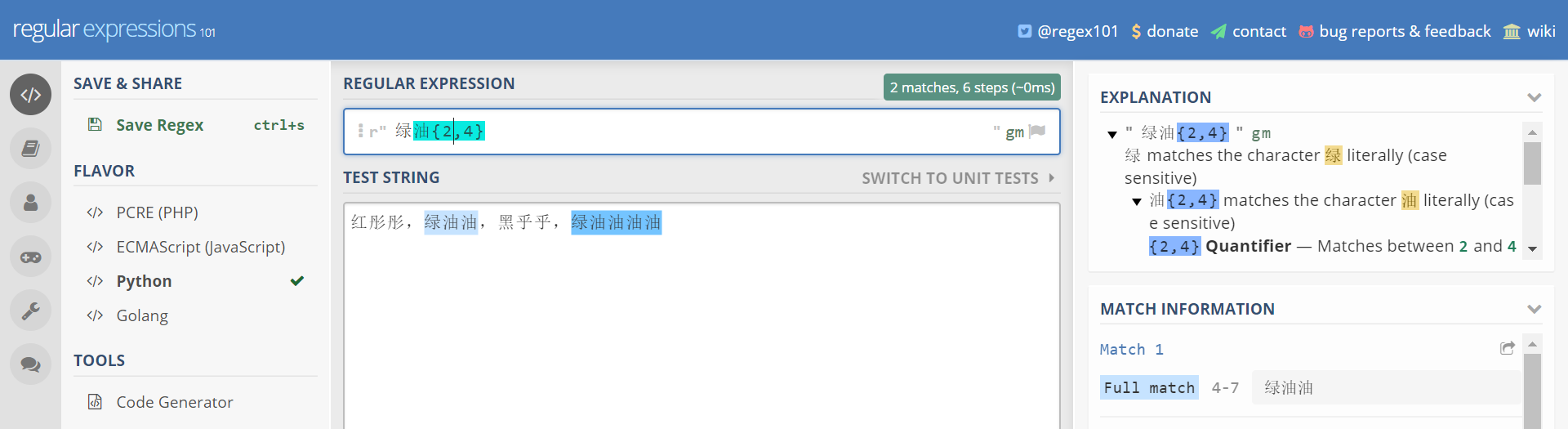
红彤彤,绿油油,黑乎乎,绿油油油油
表达式 油{3,4}就表示匹配连续的油字至少3次,至多4次
实际可以应用于获取手机号:
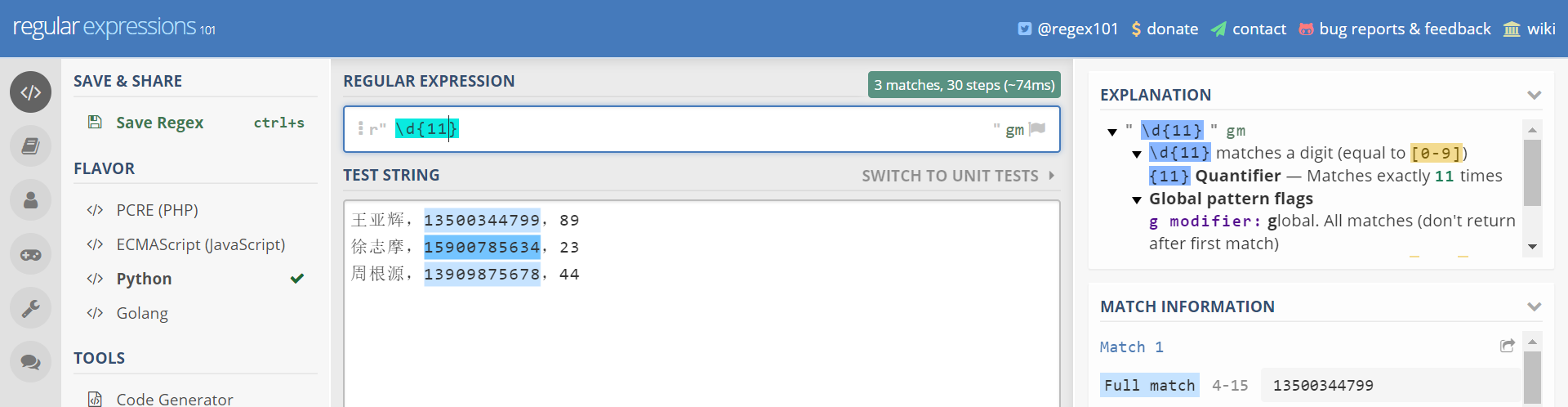
贪婪模式和非贪婪模式
我们要把下面的字符串中所有html标签都提取出来
source='<html><head><title>Title</title>
得到这样的一个列表:
['<html>','<head>','<title>','</title>']
很容易想到使用正则表达式<.*>
写出如下代码
source='<html><head><title>Title</title> imort re p=re.compile(r'<.*>') print(p.findall(source))
运行结果却是:
['<html><head><title>Title</title>']
怎么回事?原来在正则表达式中,' * ',' + ', ' ? '都是贪婪的,使用他们时,会尽可能多的匹配内容
所以,<.*> 中的星号(表示任意次数的重复),一直匹配到了字符串最后的</title>里面的e。
解决这个问题,就需要使用非贪婪模式,也就是在星号后面加上? ,变成这样<.*?>
代码改为:
source='<html><head><title>Title</title>' imort re p=re.compile(r'<.*?>') print(p.findall(source))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号