难得一爬
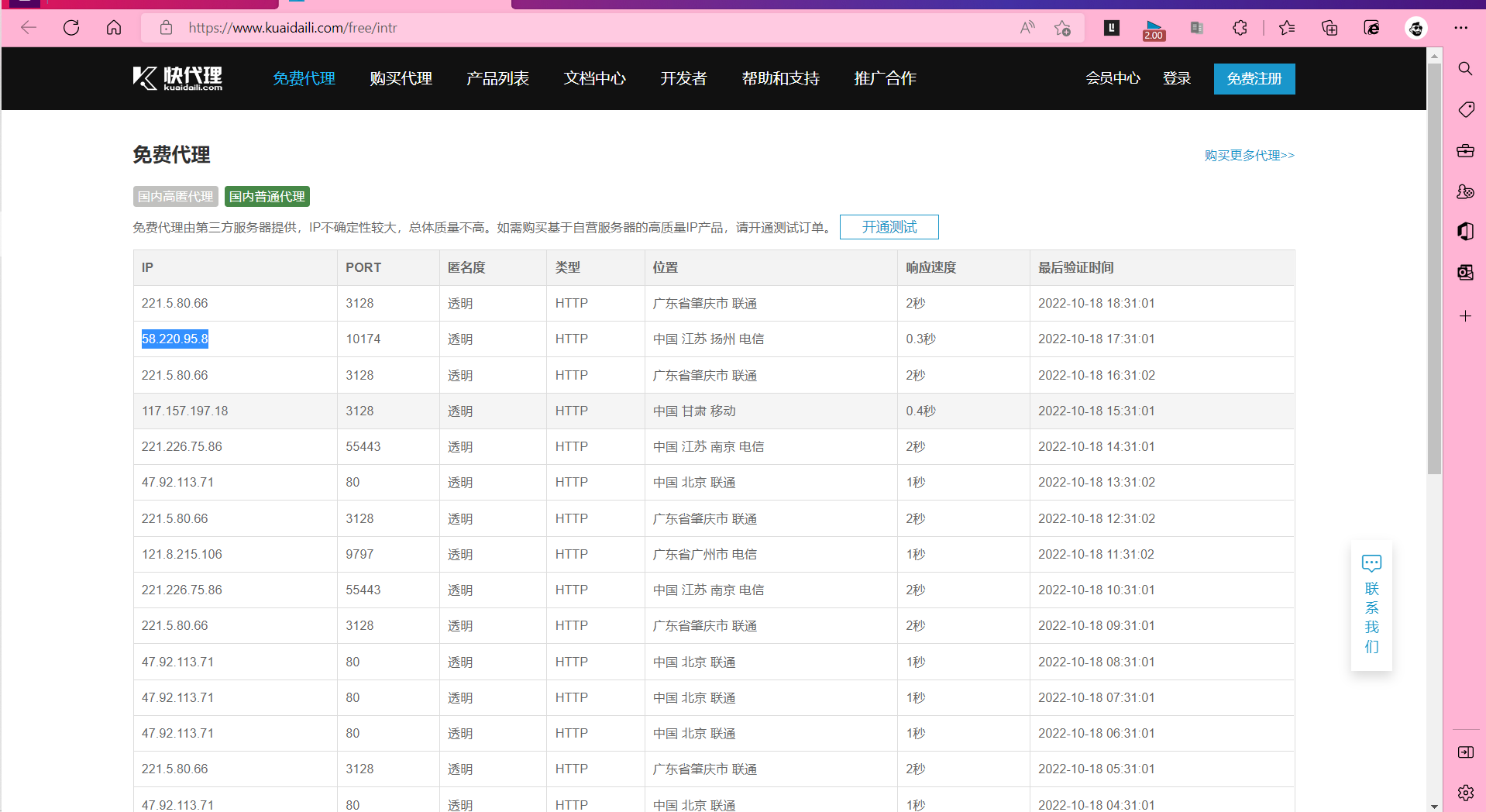
尝试使用代理ip进行爬取
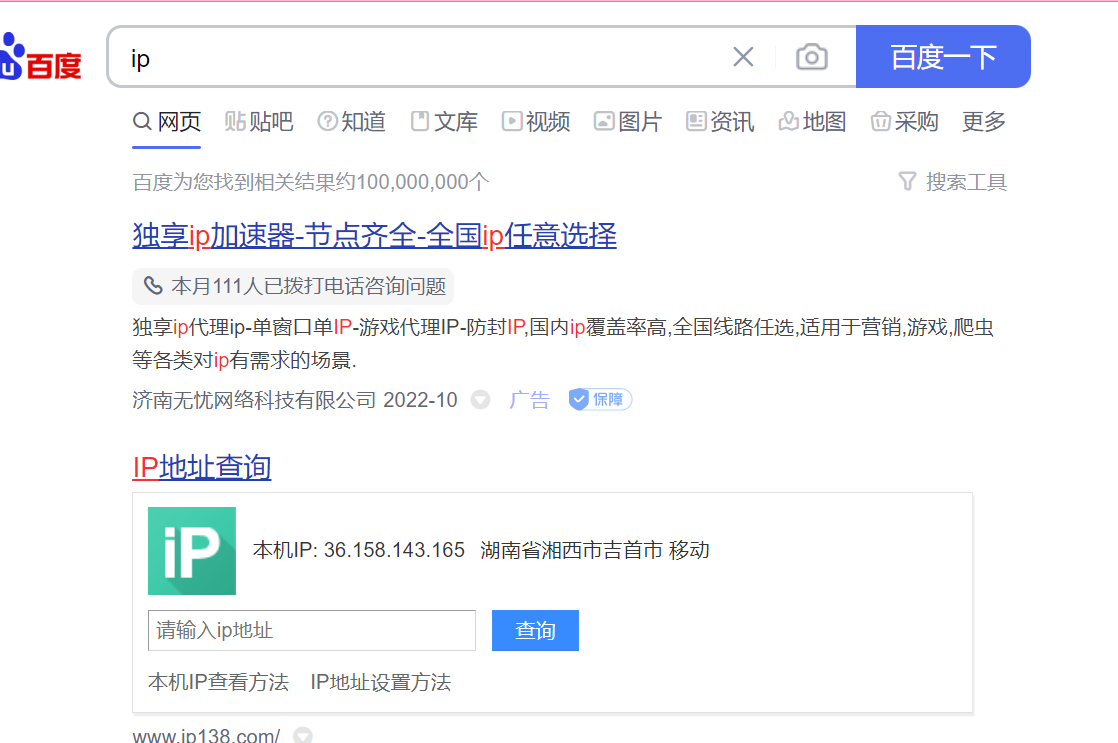
爬完之后显示得就不是你的本机的IP了
具体过程就是主机将请求发给代理服务器,然后代理服务器发送请求,再然后获取请求结果再将结果返给主机
多提一嘴:代理ip要钱了现在
异步爬虫,加快爬取的速度
使用线程池进行爬取
接下来就是知识的回顾
有关xpath的使用


./:代表li标签
下面分享一下我的爬取某网站的视频名称和连接的代码
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 104.0.0.0Safari / 537.36'
}
# 使用线程池处理阻塞且耗时的操作
# 改项目是爬取并且下载梨视频里面的视频
# 获取网站的url
url = "https://www.pearvideo.com/category_1"
# 获取相应的网页html
page_text = requests.get(url = url,headers = headers).text
tree = etree.HTML(page_text)
# 获取视频的url信息
# 定位到标签下所有的li标签
li_url = tree.xpath('//ul[@id="listvideoListUl"]/li')
# 下面打印出来看有多少个相对应的
# print(li_url)
for li in li_url:
#这里面的0代表的是列表中的第一个元素
detail_url = 'https://www.pearvideo.com/'+li.xpath('./div/a/@href')[0]
name = li.xpath('./div/a/div[2]/text()')[0]
print(detail_url,name)
看似很少,但是里面的细节很多
对于正则的使用,首先需要应用ie
43
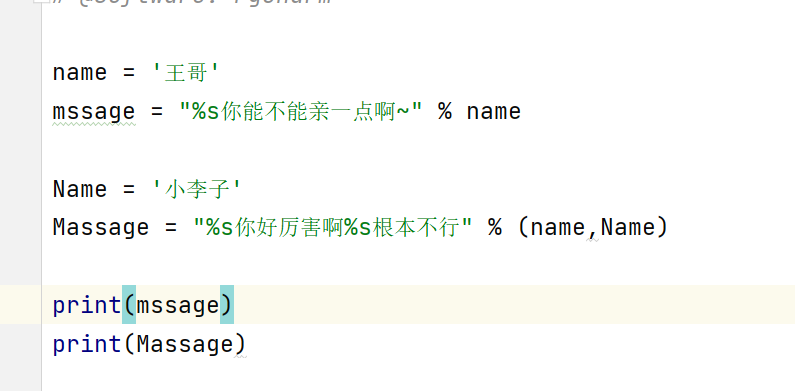
这里插一句关于字符串的使用方法,常用为%d,%s,%f
浮点数,可以使用m.n来设置浮点数的精度
其中我个人感觉最重要的就是获取不同的网站需要爬取的位置的连接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号