再趴一趴(爬)
验证码的学习
通过爬虫实现登录指定用户并且爬取相应的信息
看的视频里面搞得识别验证码的方法需要利用,自动识别验证码的软件来使用,由于该软件已经倒闭,就没进行实操
但是具体的方法还是可以记录一下
第一步就是获取识别验证码的账户信息,并且进行一个登录操作,然后利用那里面的操作方法来识别
识别的图片是通过爬虫获取该页面的验证码的src,将其下载到pycharm里面进行读取的
看着视频里面爬取人人网里面的验证码,不晓得两年过去了,人人网有没有增加一点防爬措施
爬都不晓得爬哪,哈哈
猛然发现基本所有的网站都找不到验证码了,大概这就是发展吧
咳咳~但是基本的处理方法我还是写一下
首先和正常的爬取网页的操作一致,获取url,在网站上打开该网站,爬取网站的相关的信息,再对网站进行一个分析操作,将其中的放验证码的区域单独获取并且以图片的形式保存
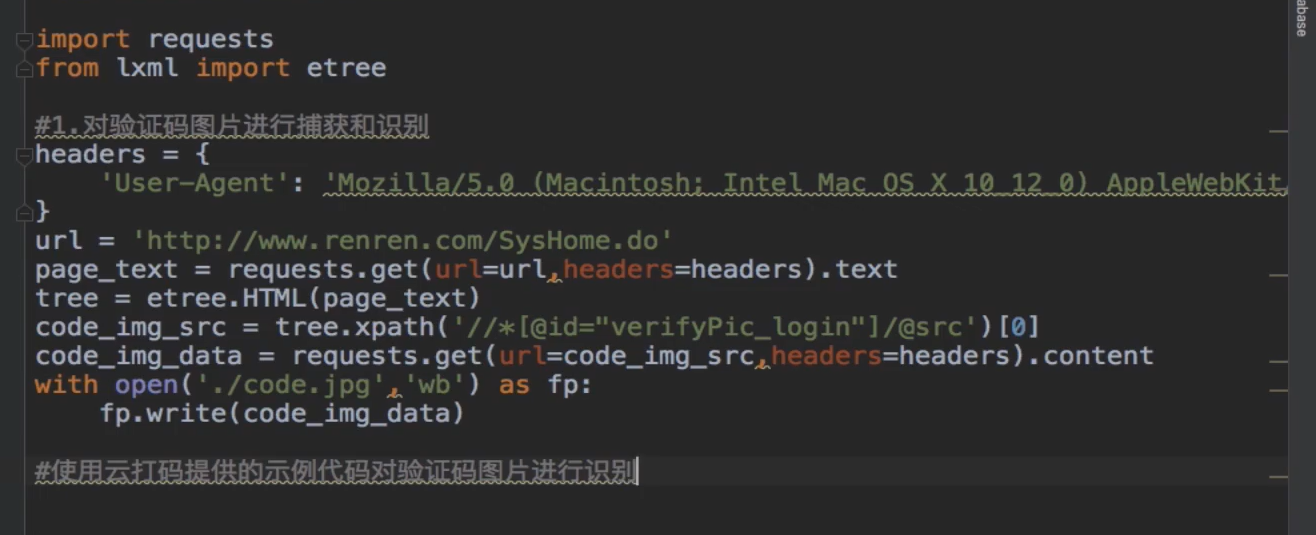
最后再通过验证码处理,解读

 浙公网安备 33010602011771号
浙公网安备 33010602011771号