吴恩达机器学习 课时1 什么是机器学习、监督学习和无监督学习
机器学习的定义
-
Arthur Samuel(1959): Machine Learning: Field of study that gives computers the ability to learn without being explicitly programmed
在没有明确设置的情况下,使得计算机具有学习能力的研究领域。
这是一个不够严谨,有些陈旧的定义。 -
Tom Mitchell (1998)Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task t and some performance measure p, if its performance on t, as measured by p, improves with experience E.
计算机程序从经验E中学习去解决某一任务T,并且通过性能度量P进行评测。测定P在T上的表现是否因经验E而提高。
例如:计算机通过学习用户给邮件标记为垃圾邮件这件事,可以更好的过滤垃圾邮件。
在这个例子中,经验E是观察你将邮件是否标记为垃圾邮件,任务T为计算机将邮件分为垃圾邮件和非垃圾邮件,性能度量P是计算机分类的准确性。
监督学习(supervised learning)
让我们从一个例子入手:
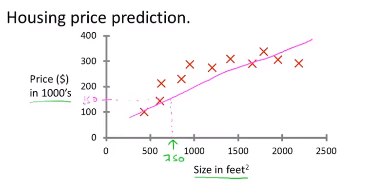
我们想要预测房子的价格,横轴是房子的尺寸,纵轴是不同尺寸的房子对应的价格。
假设你有一栋750英尺的房子,你想要知道这栋房子可以卖多少钱。
学习算法可以用一条直线拟合数据,就像上图所示,根据直线预测房子大概可以卖15万美元。
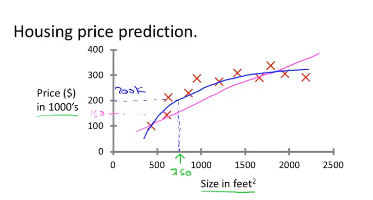
但是这并不只唯一的学习算法,或许我们可以用二次函数更好的拟合数据,就像图上这条蓝色的线。根据这个学习算法,我们预测这间房子大概可以卖出20万美元。在以后的学习中我们将会学习如何选择使用直线还是曲线来拟合数据。
上面这个就是一个监督学习的例子,监督学习是指我们给计算机一个数据集,数据集中包含正确答案,例如在这个例子中给出了多大尺寸的房子对应的价格,通过这些数据集来给出其他数据的正确答案。
这个例子也可以被称为回归问题(regression problem)。回归问题指的是我们将预测连续的数值输出。与分类问题不同,如果预测的不是连续的数值输出,而是离散的结果,这种问题就被称为分类问题。
下面是一个分类问题的例子:
假设某人发现了一个乳腺肿瘤,根据这个肿瘤的大小来预测这个肿瘤是良性的还是恶性的。

横轴表示肿瘤的大小,纵轴0表示良性,1表示恶性。图上面的X对应每个肿瘤和它所对应的结果。假设这个人的肿瘤大小为箭头所示区域,那么他的肿瘤是良性还是恶性的呢?
在这个例子里面,我们要预测的结果只有两种情况,0或1,良性或恶性。但是在其他的例子里面我们或许会预测三种、四种情况,但是只要我们预测的结果不是连续的数值(或者说是离散的),那么这种情况就可以被称为分类问题(classification problem)。
在上面的例子里肿瘤的结果只与肿瘤大小有关,但是在实际的问题中,我们要考虑的特征有很多,例如不仅仅考虑肿瘤的大小,将病人的年龄也考虑范围,我们得到了下面这个图。
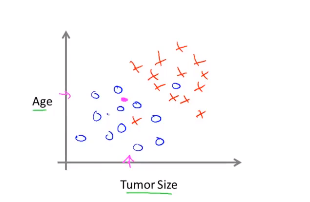
在这个图里面,我们用o表示良性,用X表示恶性,而这个人的肿瘤大小处在图上粉色圆点这个位置。
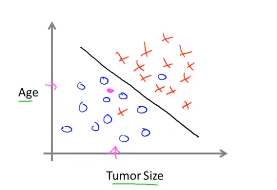
在给定的数据上,学习算法可以在数据上或一条线,试着来分离良性或者恶性,很显然,这种情况下学习算法会认为这个人肿瘤为良性的可能性更大一些。
无监督学习(unsupervised learning)
在癌症的例子中,我们得到的数据已经被告知了肿瘤的结果是良性的还是恶性的,就像下图中用不同的颜色和图案来表示不同的结果,这种数据集中有答案的机器学习方式被称为监督学习。
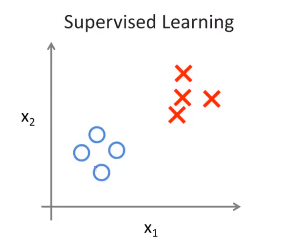
而在有些学习中,只有数据集,不带有任何的标签,就像下图一样。这种学习方式被称为无监督学习。

通过给定的数据集,机器认为该数据集中包含两个不同的簇。这就是聚类算法(clusteringalgprithm)。
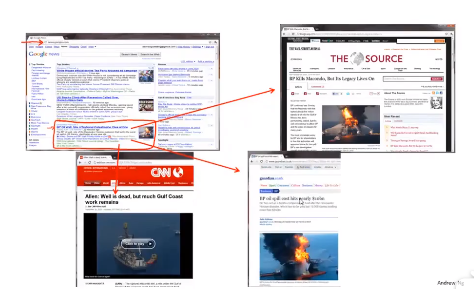
聚类算法实际上有很多用处。例如在谷歌新闻上,谷歌新闻每天会在网上收集数万条或者数十万条新闻,将它们进行分簇,将同一主题的新闻放在一起。
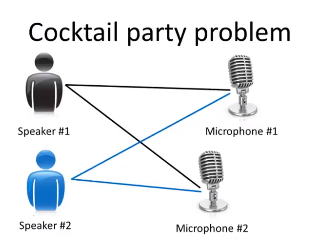
聚类算法只不过是无监督学习中的一种算法。 下面将介绍另一种无监督学习算法,鸡尾酒会问题(Cocktail party problem)
假设在一个鸡尾酒会上有两个麦克风,两个人距离这两个麦克风的位置各不相同,当他们同时说话的时候,这两个麦克风记录了两个说话者重叠的声音。但是由于人距离麦克风的位置不同,他们被每个麦克风记录下的声音也有不同。鸡尾酒会问题就是将这两种被混合的声音进行分离的算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号