
性能测试之TPS上不去,请求无报错,只是响应时间越来越长问题解决
测试过程中,发现TPS上不去,请求照样发起,断言没有报错,只是响应时间越来越长,
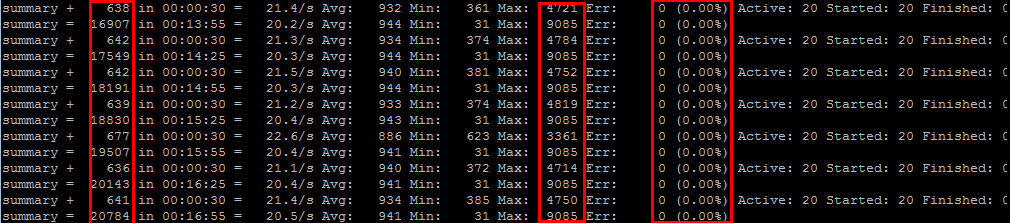
于是排查系统间发送和接收情况。
1.排查压力机,登录压力机,执行:netstat -naop | grep EST,发现发送队列和接收队列都是0,
于是排查请求链条中的第一个服务,即Nginx服务,登录Nginx服务,执行命令:netstat -naop | grep EST,发现发送队列一直处于6000以上,于是查看Grafana的连接情况:
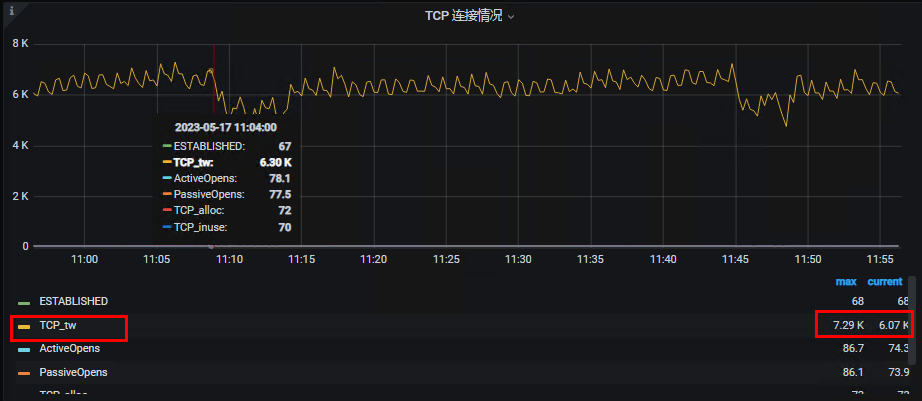
上图中的TCP_tw很高,TCP_tw的意思是TCP_time wait,度娘上找了很多资料,更多的倾向于将Nginx的默认短连接改成长连接。但是在实际业务中,使用长连接会占用很多资源而且不稳定,所以不考虑改成长连接。
2.再细看6000发送队列是压力机到跳板机的请求,因压力机和应用服务是同一局域网内的机器,不存在压力机到跳板机的请求,和架构师讨论后,重新选取响应时间最长的场景(单个请求响应时间达到10s)执行单场景测试,并开启Skywalking查找请求链路中最耗时的部分。
3.在Skywalking中找到最耗时的请求,然后顺着链路查找到是其中一个请求挡板服务器的请求响应时间超长,然后查看挡板服务器,发现挡板服务器的磁盘空间已满。猜测是因为磁盘空间已满,导致请求响应时间超长而不报错。
4.解决:清理挡板服务器的磁盘空间后,再次执行测试,TPS恢复正常,响应时间也回复到正常时间。
本次性能问题的排查和解决到此结束。
在启动skywalking过程中,出现了一个小插曲,因为用的是ES数据库,而ES数据库为了安全不能使用root启动,所以一开始用root启动ES失败,查看日志,发现是无权限,而ES的部分日志文件的权限又是root,所以做了以下处理:
1.将文件的属主和属组是root用户的文件全部改成ES用户
1 2 | cd xxx #定位到root权限的日志文件目录chown -R es:es ./ #es是Elasticsearch的用户 |
再次查询该目录,所有文件的属主和属组都变成了es
2.使用Elasticsearch用户启动Elasticsearch
1 2 3 | su - escd /usr/local/Elasticsearch/bin #定位到Elasticsearch的bin目录./elasticsearch -d #后台启动Elasticsearch |
可以使用ps -ef | grep Elasticsearch查看是否启动成功


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统