


MapReduce Shuffle机制
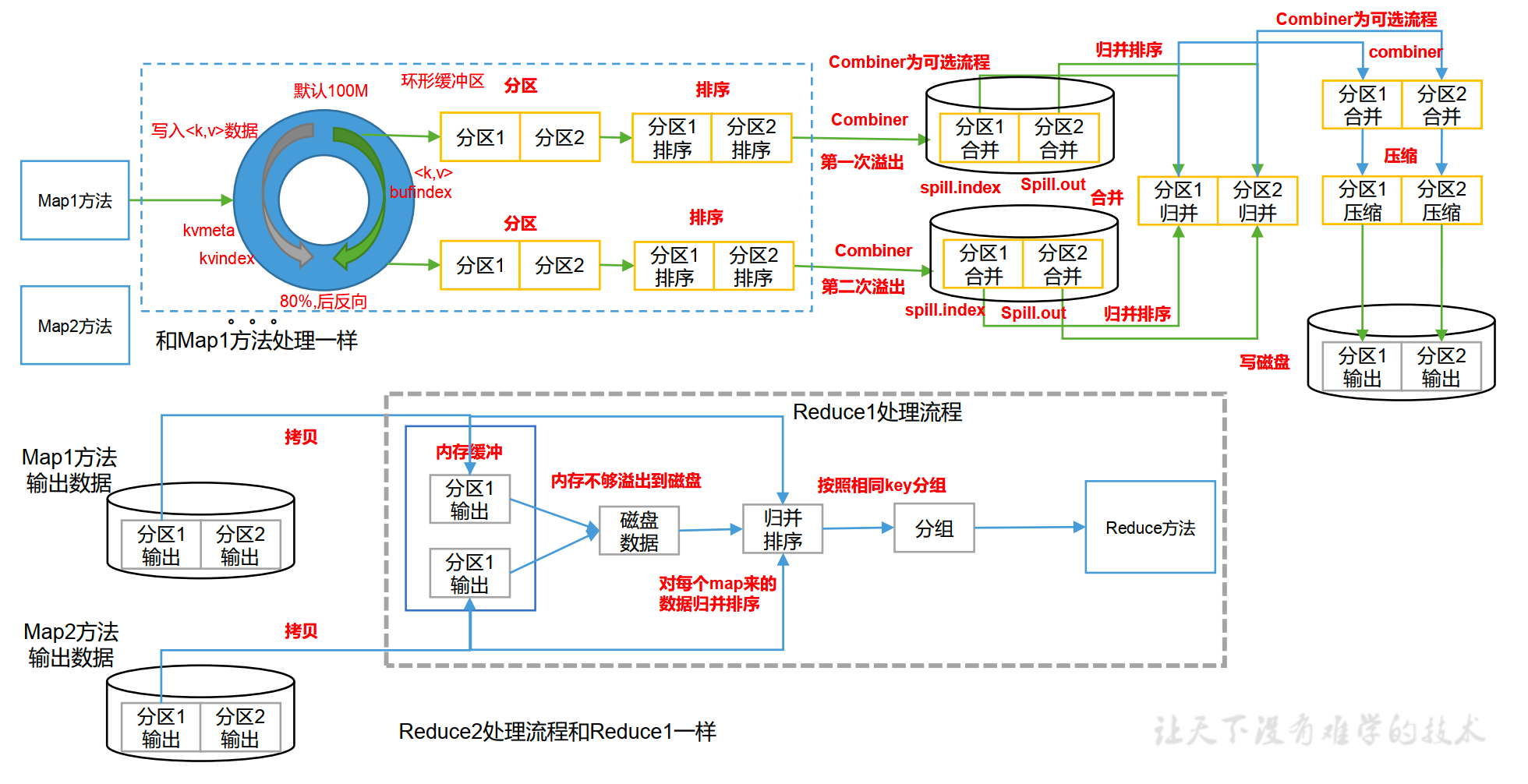
Mapper端:每个mapTask有一个环形缓冲区,用于存储map任务的输出。默认大小100M(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容写到(spill)磁盘的指定目录(mapred.local.dir)下的新建的一个溢写文件。写磁盘前,会在内存里(快排)进行partition, sort, combiner(如果配置了combiner)操作,如果有后续的数据,将会继续写环形缓冲区,最终写入下一个溢出文件中。等最后记录写完,合并(归并排序)全部溢出文件为一个分区且排序的文件。如果在最终合并时,被合并的文件大于等于3个,则合并完再执行一次combiner操作,否则不会。
Reducer端:Reducer通过http方式得到输出文件的分区。NodeManager为分区文件运行Reduce任务,复制阶段把Map输出复制到Reducer的内存或磁盘。一旦Map任务完成,Reducer就开始复制。排序阶段合并map输出,然后走Reduce阶段。
参考资料:http://www.atguigu.com/bigdata_video.shtml#bigdata
本文来自博客园,作者:wzyy,转载请注明原文链接:https://www.cnblogs.com/wwzyy/p/16060255.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2019-03-26 Redis数据结构:链表
2019-03-26 Redis数据结构:SDS