

Innodb内存结构
聚集索引与非聚集索引:
聚集索引:主键,有序,存储顺序与内存一致
非聚集索引:非主键,无序
聚集索引在叶子节点存储的是表中的数据
非聚集索引在叶子节点存储的是主键和索引列
使用非聚集索引查询出数据时,拿到叶子上的主键再去查到想要查找的数据。(拿到主键再查找这个过程叫做回表)
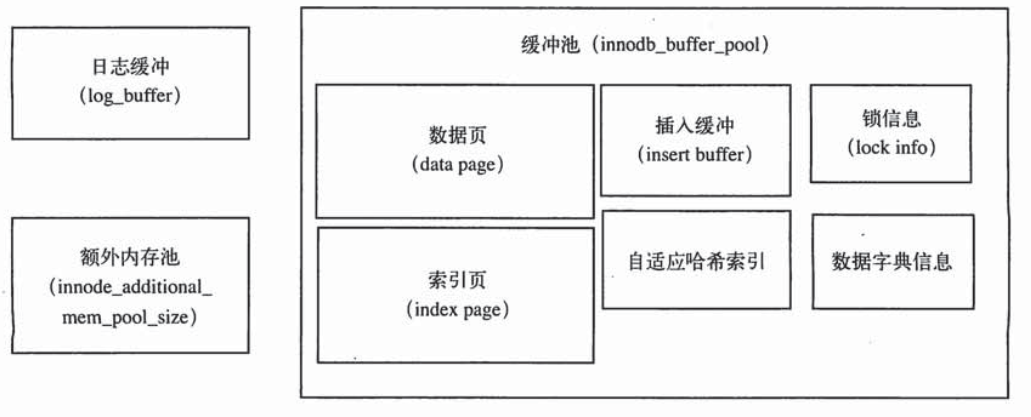
缓冲池:
缓冲池用于存放各种数据的缓存。Innodb总是将磁盘中的数据(数据库文件)按页(16K)读取到缓冲池,然后按最近最少使用算法(LRU)来保存缓冲池中的数据。如果数据库文件需要修改,总是先修改在缓存池中的页(发生修改后,该页为脏页),然后按一定频率刷新到磁盘中。
insert buffer(插入缓冲):
使用条件:1.索引是辅助索引;2.索引不是唯一的。 也就是说,主键索引不使用插入缓冲。主键索引是聚集索引,插入是顺序的,执行效率比较高,就不借助缓冲了。 但是,当表中存在辅助索引(非聚集索引,非主键)时,不一定是顺序的了,这时需要离散的访问,插入性能会降低。 所以,对于非聚集索引的插入和更新操作,不是直接插入到索引页中,而是插入到缓冲中,再以一定频率执行插入缓冲和非聚集索引叶子节点的合并操作。 注:由于非主键索引叶子节点存的是主键和当前列值,所以使用非聚集索引查询时,先查辅助索引的那颗树找到对应的主键,再查主键索引的那颗树,会查两次,效率不高。
redo log(重做日志):
在事务提交的时候,Innodb会先把数据从磁盘中读到内存进行修改,然后把事务日志写到日志缓冲(log buffer),然后再刷新到重做日志文件(redo log file)中进行持久化,然后再定期刷新到磁盘中。
用于在实例故障恢复时,继续那些已经commit但数据尚未完全回写到磁盘的事务。
double write(两次写):
为防止redo log在写的过程中损坏,我们需要留个备份。若出现故障,先从备份中恢复redo log,再进行数据恢复。
undo log:
记录数据修改前的镜像,用于将未提交的事务回滚到事务开始前的状态。
undo操作:当Innodb存储引擎回滚时,它实际上做的是与之前相关的工作,对于insert操作,Innodb会完成一个delete,对于update,则会执行一个相反的update,将修改前的行放回去。
自适应哈希索引:
Innodb会监控表上索引的查找频率,若发现建立哈希索引会提升速度,则自动创建哈希索引。不是对整张表建立索引,而是根据访问频率对某些页建立。
事务提交:
事务进行过程中,每次sql语句执行,都会记录undo log和redo log,然后更新数据形成脏页。然后redo log按照时间或空间等条件进行落盘,undo log和脏页按照checkpoint进行落盘,落盘后相应的redo log就可以删除了。此时,事务还未commit,如果发生崩溃,则首先检查checkpoint记录,使用相应的redo log进行数据和undo log的恢复,然后查看undo log的状态发现事务尚未提交,然后就使用undo log进行回滚。事务执行commit操作时,会将本事务相关的所有redo log都进行落盘,只有所有redo log落盘成功,才算commit成功。然后内存中的数据脏页继续按照checkpoint进行落盘。如果此时发生了崩溃,则只使用redo log恢复数据。
本文来自博客园,作者:wzyy,转载请注明原文链接:https://www.cnblogs.com/wwzyy/p/10818567.html
