
导师给了个任务,在他所做的Web项目中爬取用户行为信息。
以前只爬取过百度的一些图片,还是比较简单的,一搜索也好多模板,但这次一做这个小任务才发现自己在这方面从来没深深研究过,有很多不足,爬取的内容、网站不一样,所需要的方法也不同。
Talk is cheap,show me the code.
先粘贴代码,然后再介绍:
import json
import requests
from selenium import webdriver
import time
import pandas as pd
from bs4 import BeautifulSoup
from lxml import etree
from PIL import Image
import urllib.request
import re
import os
import html5lib
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
def loadPage(htmler,judge,page,part):
soup = BeautifulSoup(htmler, "lxml")
# 获取table td类型
tables = soup.find_all('table')
# print(tables)
# time_start = time.time()
for i in range(len(tables)):
df_tables = pd.read_html(str(tables[i]))
for j in range(len(df_tables)):
df = df_tables[j]
# 如果还需要对数据进行处理,可以先不输出成表格。先保存下来,最后再遍历一遍再输出成表格
if judge==0 :
csv_name = os.path.join('table', str(page)+ '' +str(part-1)+ '' +str(i) + '' + str(j) + '.csv')
else :
csv_name = os.path.join('table', str(page)+ '' +str(part-1)+ '' +str(i) + '' + str(j) + 'gen'+'.csv')
df.to_csv(csv_name, index=False, header=False)
# time_end = time.time()
# print('time获取数据并生成表格的时间 cost', time_end - time_start, 's')
# 获取table ul类型
count = 0
for li in soup.find_all(name='li'):
count += 1
if (count >= 2 and count <= 6):
df = li.text
print(df)
print('>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>')
登录平台
实例化浏览器对象
driver = webdriver.Firefox()
driver.set_page_load_timeout(5)
访问网页
driver.get('登录页面')
元素定位法
driver.find_element_by_xpath('//[@id="loginName"]').send_keys('账号')
driver.find_element_by_xpath('//[@id="LoginForm"]/div[2]/input[2]').send_keys('密码')
yan=input("输入验证码:")
print(yan)
driver.find_element_by_xpath('//*[@id="validateCode"]').send_keys(yan)
time.sleep(2)
登录首页
driver.find_element_by_xpath('//*[@id="LoginForm"]/div[4]/input').click()
time.sleep(5)
alertObject = driver.switch_to.alert
print(alertObject.text) # 打印提示信息
搞定两个弹窗,点击两次确定按钮
time.sleep(2)
alertObject.accept() # 点击确定按钮
time.sleep(2)
alertObject.accept() # 根据前端js代码逻辑,当点击确定按钮后会再弹出一个提示框,我们再次点击确定
time.sleep(3)
print("两个弹窗已搞定,进入所需爬取的页面")
driver.execute_script("window.stop()")
通过列表ID获取所需信息
driver.get('列表所在的页面url')
点击列表
for j in range(1,5):
print("正在爬取第:{}".format(j)+"页")
for i in range(2, 12):
# time.sleep(30) #//*[@id="test1"]/tbody/tr[2]/td[3]/a
#等元素加载出来后再点击,0.5秒检查一次,设置最多30s超时
WebDriverWait(driver, 30, 0.5).until(EC.presence_of_element_located((By.XPATH, '//*[@id="test1"]/tbody/tr[' + str(i) + ']/td[3]/a')))
time.sleep(1)
driver.find_element_by_xpath('//*[@id="test1"]/tbody/tr[' + str(i) + ']/td[3]/a').click()
print("已经进入第:{}".format(i - 1) + "条")
windows = driver.window_handles
driver.switch_to.window(windows[1])
time.sleep(2)
# 获取源码
htmler = driver.execute_script("return document.documentElement.outerHTML")
loadPage(htmler,0,j,i)
#进入流程跟踪
# loadPage1(j,i)
# windows = driver.window_handles
# driver.switch_to.window(windows[1])
driver.close()
print("已关闭")
driver.switch_to.window(windows[0])
time.sleep(1)
driver.find_element_by_xpath('//*[@id="page_f"]/div[2]/div[1]/span[3]').click()
网站因为涉及到导师的项目,不太方便截图,这里简单介绍一下 ,这是一个管理政务处理流程的网站,我们要做的就是登录进去找到对应的功能块,在功能块中找到表格 在表格中一个个点击链接到新网页去爬取里面的一些流程信息。
这个是两个人一起做的,我的队友称他小李吧,一开始我没参与,小李做完了登录和输入验证码的部分,后来我才参与进来。主要是用selenium库中的函数模拟人进行点击和输入,这样的话比较慢,但是好做。要注意这里用的是火狐浏览器,需要下载对应的geckodriver.exe才能使代码自动启动浏览器,查看它自动点击的过程,账号密码是代码自动填入,验证码是由人工输入的,毕竟也要尊重一下验证码设计的初衷(主要还是懒得去学破解验证码的技术),进入网站后,直接跳转到所要爬取的页面的网址,是个列表,每一行有链接,需要点击链接进去爬里面的信息。爬完这一页,翻页爬取下一页,将信息输出成csv表格。关键点是在源代码中找xpath来定位元素和用selenium模拟点击。
下面有几点说明:
1.因为用的vpn内网进行登录,所以页面加载很慢,在代码中需要用到一些sleep函数,让它睡一会儿,等等网页加载完成后再点击或者操作如果不设置sleep可能会报错。
2.当代码启动火狐浏览器时,它自动禁用所有的加载项,所以当网站中有一些高级点的图,表格需要加载时,加载不来,弹出了弹框需要升级alobe flash player,然而当你升级了之后并没有什么卵用,因为它默认不使用你的alobe flash player。搜索了很多解决方法,都没有用,万幸我们需要爬取的表格可以正常显示,所以,只需要忽略弹窗就可以了,这里用的是模拟点击弹窗中的确定,他就会回到网页中。
3.获取xpath来定位元素,按F12检查元素 ctrl+shift +c点击元素 定位到源码中的位置,然后右键复制xpath,粘到函数中就可以定位元素,如下图 再利用findbyelementbyxpath 找到对应的按钮点击即可
————————————————
版权声明:本文为CSDN博主「热忱a」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_39187593/article/details/109276271
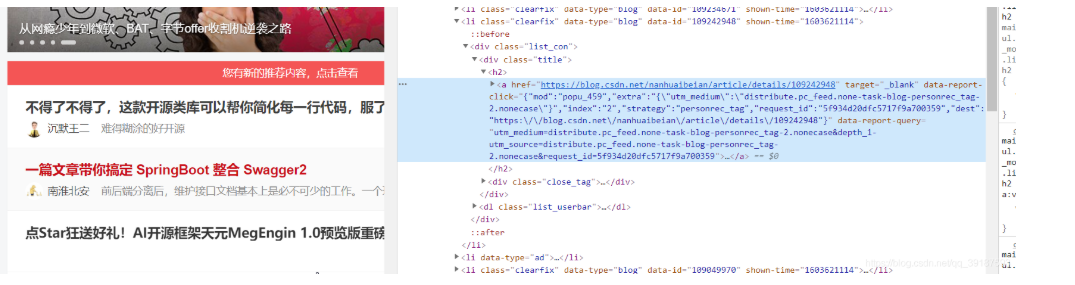
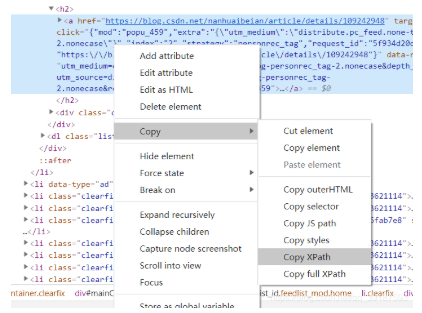
4.当点击弹出新窗口时,driver还是停留在原来的页面中,所以需要获取所有的句柄(handle),选择一个句柄让driver跳转 ,详细的可以看https://jingyan.baidu.com/article/6c67b1d6b849822787bb1e00.html
5.对于爬取table里的数据是获取了源码,然后用beautifulsoup中的方法找到所有table 再遍历tr,td保存信息 ,而有些表格不是tr,td形式的,而是li形式的,再分开弄一下。
6.因为之前爬取要接连进入两个页面,后来老师说不需要第二个页面的数据了 所以这个代码里只有爬取一个页面的,第二个页面删掉了 有一些判断语句和参数是多余的。
代码写出来很简单,也看的很明白,但是却花费了好长时间去探索 ,去试验,就像爱迪生发明灯泡,找了一千多种才找到合适的材料做灯芯 ,但我尝试的次数比他少得多。
谷歌浏览器获取源码不知道为什么我这个网站总是 等待20s才能获取源码,我看了看控制台 ,也写代码验证了,明明加载完了,它就是不获取源码,偏偏等20s ,别的网站没有这种情况。让我头疼了两天,尝试过各种方法,停止加载,sleep,换链接。。。。全都没用,换个思路,换了个浏览器才解决的。
还有一点,差点忘了:启动浏览器需要下载对应的驱动(driver),版本要和自己浏览器的版本一致,放在python.exe这个目录下,还要注意在代码中创建driver时调用Firefox()方法,开头要大写,虽然也有小写的,但是里面get方法用不了。
————————————————
版权声明:本文为CSDN博主「热忱a」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_39187593/article/details/109276271
