如何理解梯度爆炸和梯度消失
如何理解梯度爆炸和梯度消失
何为梯度消失,产生的原因是什么?
梯度消失的最核心原因是,选择的优化方法不能很好的应对多层结构。在利用链式法则,求导的过程中导致梯度逐层衰减,最后消失。反之如果每次求导之后,梯度的值大于1,通过累乘就会产生爆炸的结果,即梯度爆炸。
梯度消失带来的后果是:较深的神经元中的梯度变为零,或者说,消失了。这就导致神经网络中较深的层学习极为缓慢,或者,在最糟的情况下,根本不学习。神经元进入停滞状态,不再学习新东西;
梯度消失问题在神经网络层数相对较多的时会遇到,梯度消失原因是链式求导,导致梯度逐层递减,我们BP第一节推倒公式时就是通过链式求导把各层连接起来的,但是因为激活函数是sigmod函数,取值在1和-1之间,因此每次求导都会比原来小,当层次较多时,就会导致求导结果也就是梯度接近于0。具体如下所示:

一般解决方法是需要从激活函数或者网络层次着手,如激活函数考虑ReLU函数代替sigmod函数。
1、引入RELU激活函数
缓解梯度消失的首个尝试。当x> 0时,ReLU的梯度为1,x <0时,ReLU的梯度为0。这带来了一些好处:ReLU函数梯度乘积并不收敛于0,因为RELU的梯度要么是0,要么是1。当梯度值为1时,梯度原封不动地反向传播。当梯度值为0时,从这点往后不会进行反向传播。
RELU也有缺陷。如果某个神经元的梯度计算出来是负值,则永远得不到更新,像是被灭活了一样。为了解决这种问题,人们又提出了Leaky ReLU,如下图,即使是负值也得到了缓慢的更新。
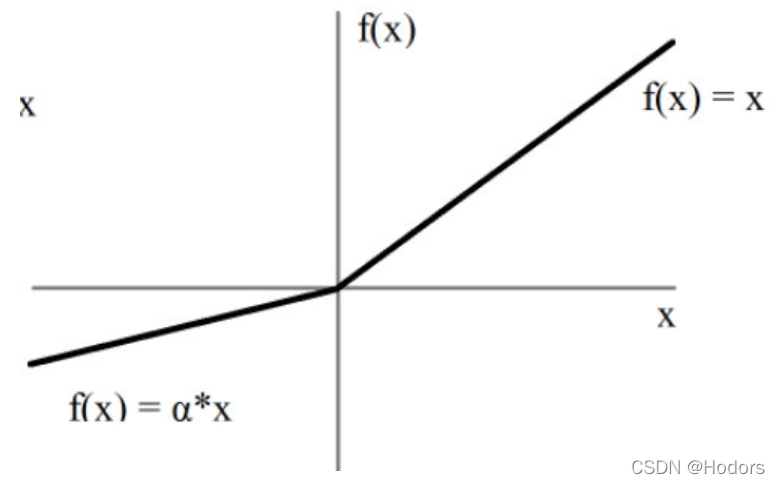
与梯度消失相反的现象称为梯度爆炸,即反向传播中,每层都是大于1,导致最后累乘会很大,梯度爆炸容易解决,
(1)最简单的方法是设定阈值就可以。限制梯度的大小,gradient clipping
(2)重新调整网络结构;比如使用更小的batch size
(3)通过使用长-短期记忆(LSTM)记忆单元和相关的门控型神经元结构来降低。
(4)此外,还可以通过对网络模型的参数进行正则化,来解决梯度爆炸的问题。
可以参考博客:
https://machinelearningmastery.com/exploding-gradients-in-neural-networks/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号