一个超级简单的RNN神经网络
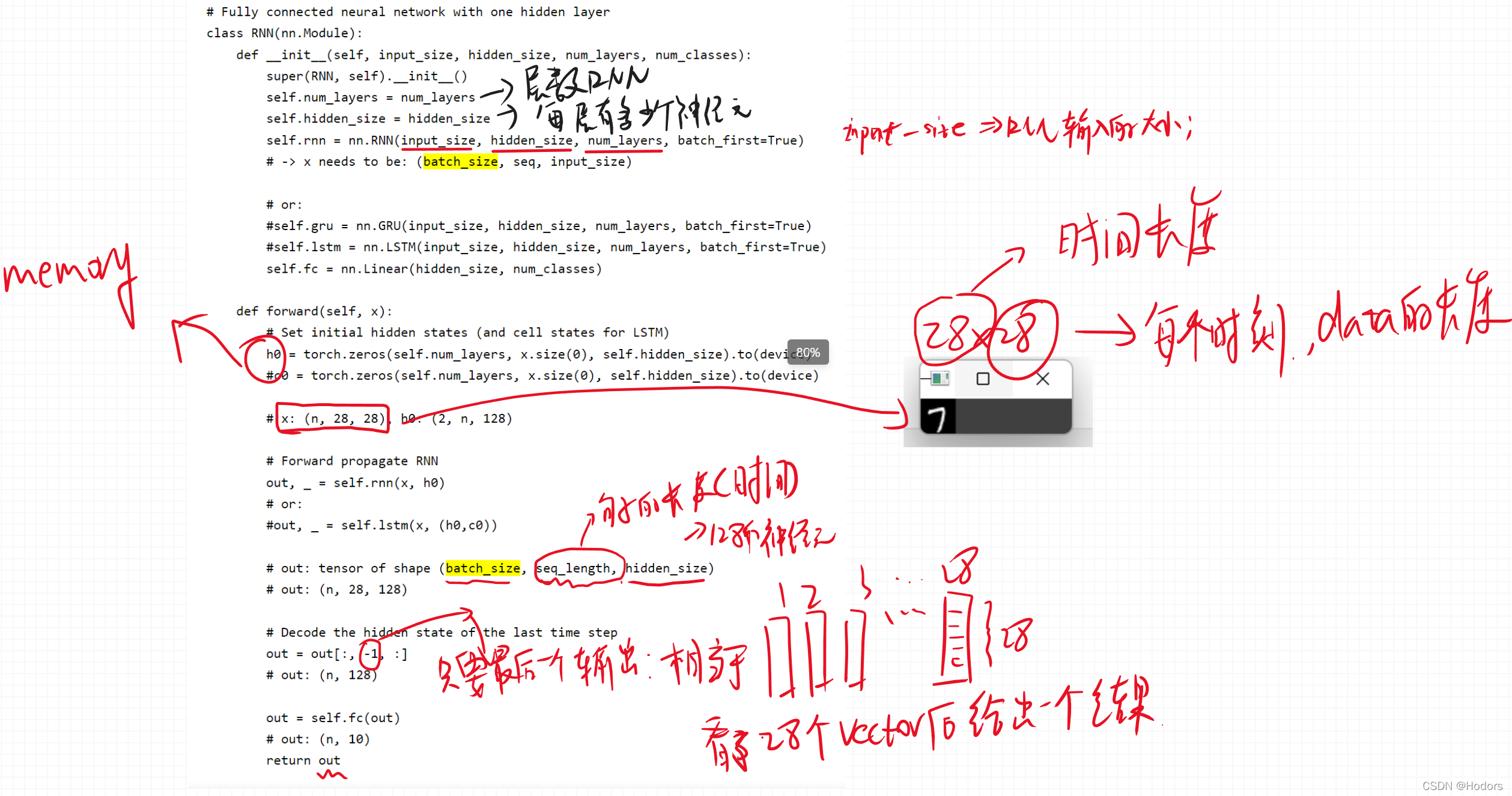
code如下; 地址如下: pytorch-examples/rnn-lstm-gru at master · python-engineer/pytorch-examples · GitHub import torch import torch.nn as nn import torchvision import torchvision.transforms as transforms # Device configuration device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # Hyper-parameters # input_size = 784 # 28x28 num_classes = 10 num_epochs = 2 batch_size = 100 learning_rate = 0.001 input_size = 28 sequence_length = 28 hidden_size = 128 num_layers = 2 # MNIST dataset train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True) test_dataset = torchvision.datasets.MNIST(root='./data', train=False, transform=transforms.ToTensor()) # Data loader train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False) # Fully connected neural network with one hidden layer class RNN(nn.Module): def __init__(self, input_size, hidden_size, num_layers, num_classes): super(RNN, self).__init__() self.num_layers = num_layers self.hidden_size = hidden_size self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True) # -> x needs to be: (batch_size, seq, input_size) # or: #self.gru = nn.GRU(input_size, hidden_size, num_layers, batch_first=True) #self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True) self.fc = nn.Linear(hidden_size, num_classes) def forward(self, x): # Set initial hidden states (and cell states for LSTM) h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device) #c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device) # x: (n, 28, 28), h0: (2, n, 128) # Forward propagate RNN out, _ = self.rnn(x, h0) # or: #out, _ = self.lstm(x, (h0,c0)) # out: tensor of shape (batch_size, seq_length, hidden_size) # out: (n, 28, 128) # Decode the hidden state of the last time step out = out[:, -1, :] # out: (n, 128) out = self.fc(out) # out: (n, 10) return out model = RNN(input_size, hidden_size, num_layers, num_classes).to(device) # Loss and optimizer criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # Train the model n_total_steps = len(train_loader) for epoch in range(num_epochs): for i, (images, labels) in enumerate(train_loader): # origin shape: [N, 1, 28, 28] # resized: [N, 28, 28] images = images.reshape(-1, sequence_length, input_size).to(device) labels = labels.to(device) # Forward pass outputs = model(images) loss = criterion(outputs, labels) # Backward and optimize optimizer.zero_grad() loss.backward() optimizer.step() if (i+1) % 100 == 0: print (f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{n_total_steps}], Loss: {loss.item():.4f}') # Test the model # In test phase, we don't need to compute gradients (for memory efficiency) with torch.no_grad(): n_correct = 0 n_samples = 0 for images, labels in test_loader: images = images.reshape(-1, sequence_length, input_size).to(device) labels = labels.to(device) outputs = model(images) # max returns (value ,index) _, predicted = torch.max(outputs.data, 1) n_samples += labels.size(0) n_correct += (predicted == labels).sum().item() acc = 100.0 * n_correct / n_samples print(f'Accuracy of the network on the 10000 test images: {acc} %')
------------------
代码解析:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号