

什么是多模态图像融合算法
什么是多模态图像融合算法
参考资料:
《综述:一文详解50多种多模态图像融合方法》
https://arxiv.org/abs/2202.02703
背景:
0、这篇paper里边的两个模态分别是:雷达数据、Camera模态;
1、多模态融合的能用的场景有很多,比如2D/3D的目标检测、语义分割,还有Tracking任务。在这些任务中,重中之中就是模态之间的信息交互融合的工作。
2、
融合的类型:
大多数方法遵循将其分为早期(前)融合、特征融合和后融合三大类的传统融合规则。
现在分类方法:
即强融合和弱融合,以及强融合中的四个小类,即早期(前)融合、深度(特征)融合、后期(后)融合、不对称融合(这个表示两个分支的特征进行相互决策)
这个分类方法相当不错啊:来源《一文读懂自动驾驶多模态传感器融合》
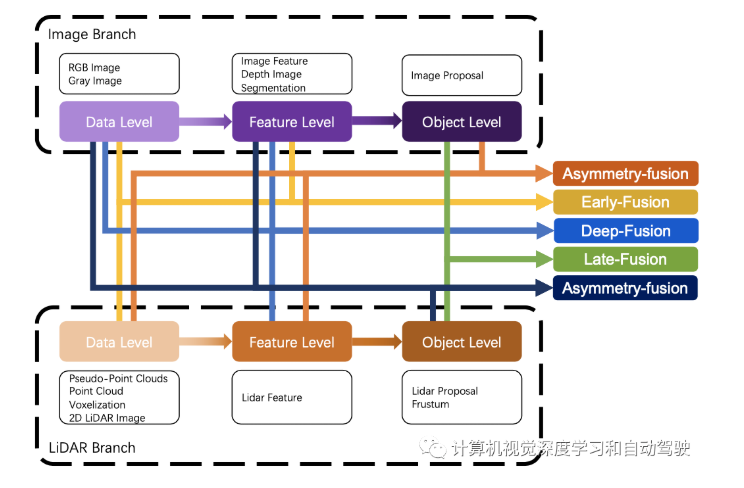
Early Fusion
1、LiDAR这个分支与Image信息的早期信息交互的过程。这种方式在reflectance, voxelized tensor, front-view/ range-view/ BEV,pseudo-point clouds都可以使用
2、数据级别可以不仅仅是图像,也可以是特征图。与传统的早期融合定义相比,文章将相机数据的定义不仅仅局限在image上,也将特征信息纳入其中。有意识的对特征信息进行选择融合
Deep-fusion
LiDAR点图分支和Images分支在经过各自的特征提取器后,得到高维度的特征图,并通过一系列下游模块对两个分支模态进行融合
Late-fusion
LiDAR点云分支和相机图像分支的输出,并通过两种模式的结果进行最终预测。后期融合可以看作是一种利用多模态信息对最终方案进行优化的集成方法
Asymmetry-fusion
而来自其他分支的数据级或功能级信息的方法定义为不对称融合。不对称融合方法至少有一个分支占主导地位,其他分支只是提供辅助信息来完成最后的任务。
Weak-Fusion
利用一种模式中的数据作为监督信号,以指导另一种模式的交互。
一般来说,自动驾驶任务包括了经典:目标检测、语义分割、深度估计和深度预测。
目标检测
2D对象检测通常简单地表示为(x,y,h,w,c),而3D对象检测边界框通常会比2D的标注信息多了深度和方向两个维度的信息,表示为(x,y,z,h,w,l,θ,c)
语义分割
会检测环境中的背景和前景目标,并加以区分,使用语义分割了解物体所在的区域以及区域的细节在自动驾驶任务中也是相当重要的
数据的基本成分(如像素和三维点)聚类到包含特定语义信息的不同区域中去。具体来说,语义分割是指给定一组数据,例如图像像素DI={d1,d2,…,dn}或激光雷达3D点云DL={d1,d2,…,dn},以及一组预定义的候选标签Y={ y1,y2,y3,…,yk},我们使用模型为每个像素或点DI分配k个语义标签并将其放置在一个区域的任务。
文献2:
《多模态特征融合方法总结》
前端融合、中间融合和后端融合
前端融合指的是将多个独立的数据集融合成一个单一的特征向量。然后输入到机器学习分类器中。多模态前端融合方法常常与特征提取方法相结合以剔除冗余信息,如主成分分析(PCA)、最大相关最小冗余算法(mRMR)、自动解码器(Autoencoders)等。
中间融合指的是将不同的模态数据先转化为高维特征表达,再于模型的中间层进行融合。
后端融合指的是将不同模态数据分别训练好的分类器输出打分(决策)进行融合。包括最大值融合(max-fusion)、平均值融合(averaged-fusion)、 贝叶斯规则融合(Bayes’rule based)以及集成学习(ensemble learning)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!