
第一次个人编程作业
一.https://github.com/w803y/031804129
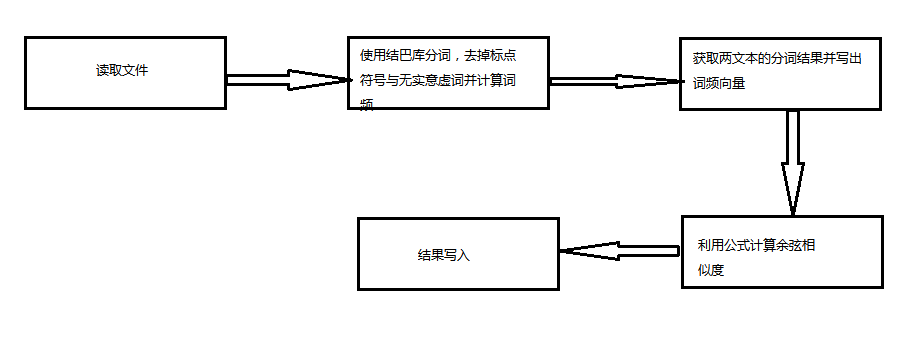
二.计算模块接口的设计与实现过程
利用余弦相似度算法:一个向量空间中两个向量夹角间的余弦值作为衡量两个个体之间差异的大小,余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋90度,表明两个向量越不相似。多维空间余弦函数的计算公式为
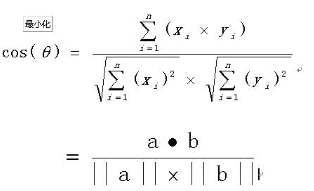
实现过程:
1)使用jieba库分词
2)取出k个关键词频合并成一个集合
3)计算每篇文章对于这个集合中的词的词频;
4)生成两篇文章各自的词频向量;
5)计算两个向量的余弦相似度,值越大就表示越相似
计算词频并得到向量
1 def get_word(original, content): 2 dictionary = {} 3 return_dic = {} 4 key_word = jieba.cut_for_search(content) 5 for x in key_word: 6 if x in dictionary: 7 dictionary[x] += 1 8 else: 9 dictionary[x] = 1 10 topK = 30 11 tfidf = jieba.analyse.extract_tags(content, topK=topK, withWeight=True) 12 stop_keyword = [line.strip() for line in original] 13 for word_weight in tfidf: 14 if word_weight in stop_keyword: 15 continue 16 word_frequency = dictionary.get(word_weight[0], 'not found') 17 return_dic[word_weight[0]] = word_frequency 18 return return_dic 19
计算余弦相似度
def similar(all_keys, original_document_dic, original_document_test_dic): str1_vector = [] str2_vector = [] # 计算词频向量 for i in all_keys: str1_count = original_document_dic.get(i, 0) str1_vector.append(str1_count) str2_count = original_document_test_dic.get(i, 0) str2_vector.append(str2_count) str1_map = map(lambda x: x * x, str1_vector) str2_map = map(lambda x: x * x, str2_vector) str1_mod = reduce(lambda x, y: x + y, str1_map) str2_mod = reduce(lambda x, y: x + y, str2_map) str1_mod = math.sqrt(str1_mod) str2_mod = math.sqrt(str2_mod) vector_multi = reduce(lambda x, y: x + y, map(lambda x, y: x * y, str1_vector, str2_vector)) # 计算余弦值 cosine = float(vector_multi) / (str1_mod * str2_mod)
三.计算模块接口部分的性能改进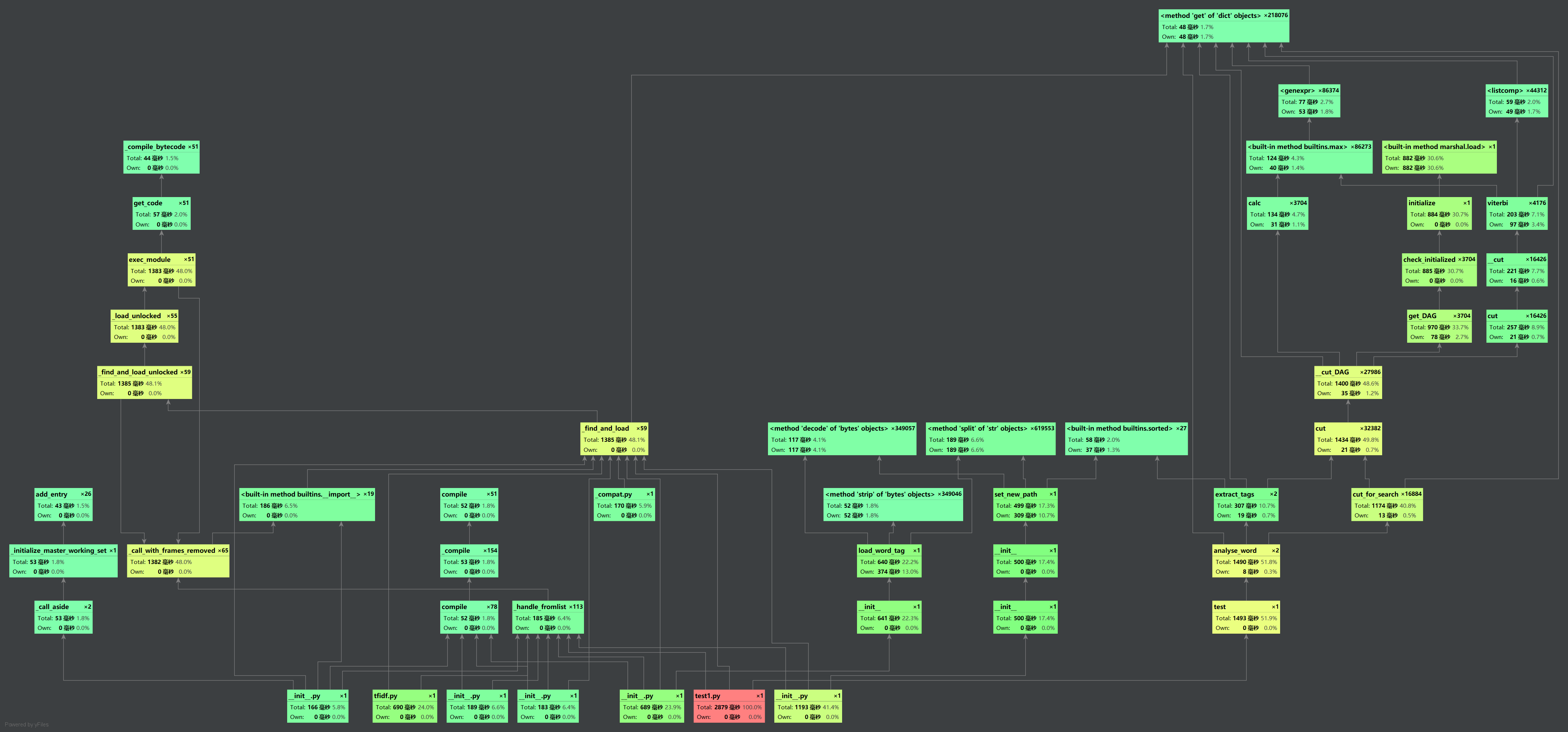
四.单元测试结果
import re import jieba import jieba.analyse import math from functools import reduce def string(file): with open(file, encoding='utf-8') as File: # 读取 lines = File.readlines() line = ''.join(lines) # 去特殊符号 character_string = re.sub(r"[%s]+" % ',$%^*(+)]+|[+——()?【】“”!,。?、~@#¥%……&*():]+', "", line) return character_string def get_word(original, content): dictionary = {} return_dic = {} # 分词 key_word = jieba.cut_for_search(content) for x in key_word: if x in dictionary: dictionary[x] += 1 else: dictionary[x] = 1 topK = 30 # 关键词 比率 tfidf = jieba.analyse.extract_tags(content, topK=topK, withWeight=True) stop_keyword = [line.strip() for line in original] for word_weight in tfidf: if word_weight in stop_keyword: continue word_frequency = dictionary.get(word_weight[0], 'not found') return_dic[word_weight[0]] = word_frequency return return_dic def similar(all_keys, original_document_dic, original_document_test_dic): str1_vector = [] str2_vector = [] # 计算词频向量 for i in all_keys: str1_count = original_document_dic.get(i, 0) str1_vector.append(str1_count) str2_count = original_document_test_dic.get(i, 0) str2_vector.append(str2_count) # 计算各自平方和 str1_map = map(lambda x: x * x, str1_vector) str2_map = map(lambda x: x * x, str2_vector) str1_mod = reduce(lambda x, y: x + y, str1_map) str2_mod = reduce(lambda x, y: x + y, str2_map) # 计算平方根 str1_mod = math.sqrt(str1_mod) str2_mod = math.sqrt(str2_mod) # 计算向量积 vector_multi = reduce(lambda x, y: x + y, map(lambda x, y: x * y, str1_vector, str2_vector)) # 计算余弦值 cosine = float(vector_multi) / (str1_mod * str2_mod) return cosine def test(doc_name): test_file = "C:/Users/Administrator/sim_0.8/"+doc_name original_document_test = test_file all_key = set() original_document = "C:/Users/Administrator/sim_0.8/orig.txt" str_Original_document = string(original_document) str_Original_document_test = string(original_document_test) original_document_dic1 = get_word(original_document, str_Original_document) for k, v in original_document_dic1.items(): all_key.add(k) original_document_dic2 = get_word(original_document, str_Original_document_test) for k, v in original_document_dic2.items(): all_key.add(k) cos = similar(all_key, original_document_dic1, original_document_dic2) print("%s 的相似度 = %.2f" % (doc_name, cos)) test("orig_0.8_add.txt") test("orig_0.8_del.txt") test("orig_0.8_dis_1.txt") test("orig_0.8_dis_3.txt") test("orig_0.8_dis_7.txt") test("orig_0.8_dis_10.txt") test("orig_0.8_dis_15.txt") test("orig_0.8_mix.txt") test("orig_0.8_rep.txt")
异常处理
except Exception as e: print(e)
psp表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Plannning | 计划 | 60 | 70 |
| Estimate | 估计这个任务需要多少时间 | 60 | 60 |
| Development | 开发 | 50 | 60 |
| Analysis | 需求分析 (包括学习新技术) | 400 | 450 |
| Design Spec | 生成设计文档 | 50 | 50 |
| Design Review | 设计复审 | 30 | 45 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 60 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 240 | 300 |
| Code Review | 代码复审 | 120 | 120 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | 70 | 70 |
| Test Repor | 测试报告 | 60 | 60 |
| Size Measurement | 计算工作量 | 20 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 80 | 100 |
| 合计 | 1330 | 1475 |
