
博客作业2---线性表
一、PTA实验作业
1.题目1:线性表元素的区间删除
2. 设计思路
定义整型变量i,j用于循环进行,变量n用于记录顺序表元素的个数;
j与n初始为0;
for i=0 to L->Last
{
if L->Data[i]在需要删除的区间外
重新保存进线性表
else
n++;
}
L指向的最后一个元素的位置减去n;
返回L;
3.代码截图

4.PTA提交列表说明

- 一开始将顺序表和链表的操作弄错了,写成“L->Data[i]=L->Data[i+1]”,导致程序全部错误,后来重新用顺序表的方式处理数据,顺序表的操作类似数组(“编译错误”的原因忘记了)。
1.题目2:链表倒数第m个数
2. 设计思路
定义循环变量i,定义整型变量n记录链表长度;
定义p指针指向L头结点;
while p->next不为空 //计算链表长度
{
n++;
p指向下一节点;
}
if m<=0或n-m+1<=0//位置非法
返回-1;
p=L; //结点位置重置
while i<=n-m且p不为空 //找第n-m个元素
{
i++;
p指向下一节点;
}
if p不为空
返回 p->data;
3.代码截图

4.PTA提交列表说明
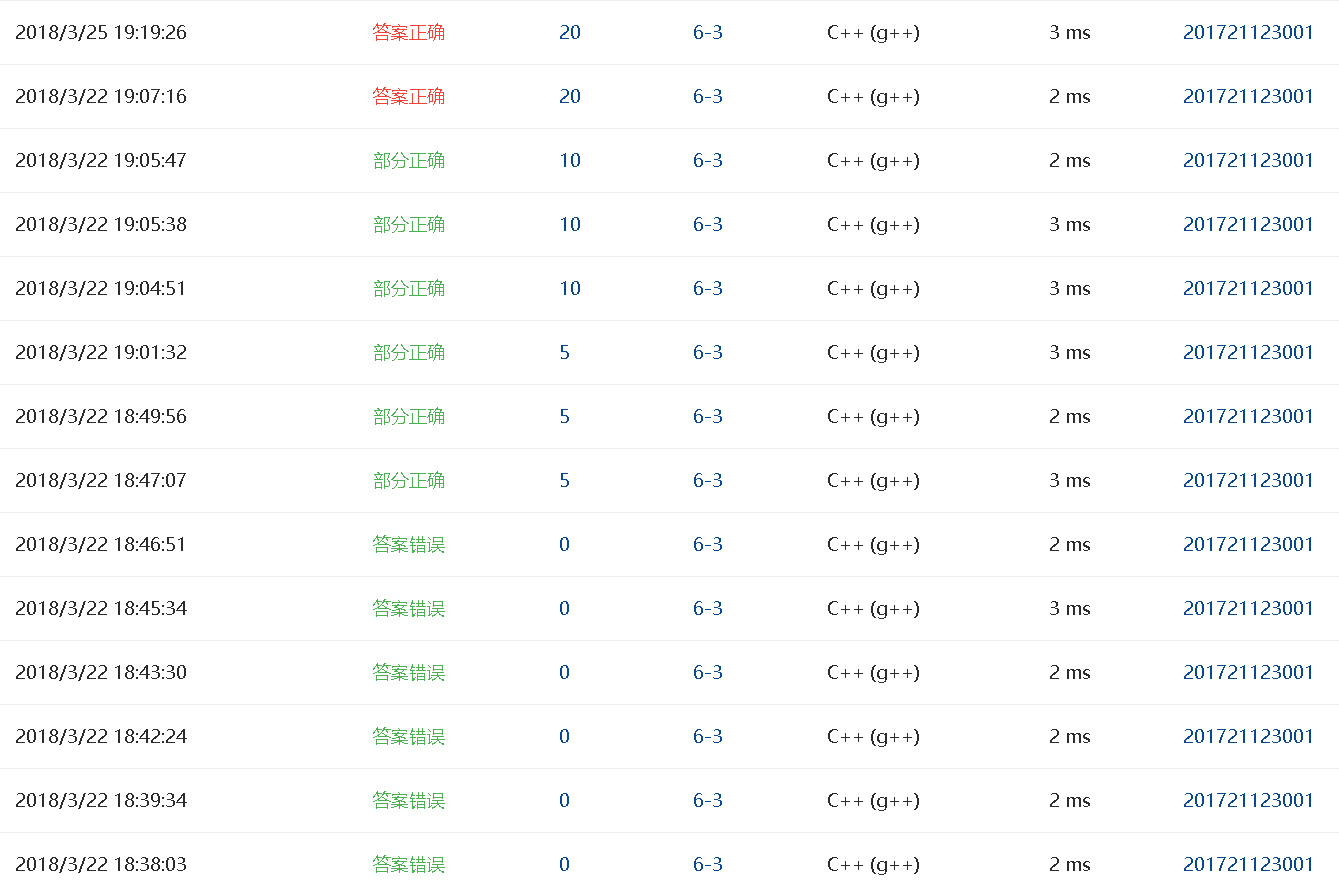
- 在定义p时不确定是“p=L->next”还是“p=L”,以及第一层循环的判断条件在“p->next!=NULL”与“p!=NULL”之间徘徊,还有当输入非法位置时缺少判断,后面不上了这一点,虽然一开始思路是对的,但是一些细节部分没有考虑处理好。
1.题目3:两个有序序列的中位数
2. 设计思路
/*找中位数的函数*/
定义整型变量i=0,mid;
定义指针p指向L1->next,q指向L2->next;
while p不为空且q不为空
{
if p->data小于q->data
{
i++;
if i等于中间位置的序号
那么 mid 等于p所包含的数据;
返回 mid;
else p指向下一节点;
}
else
{
i++;
if i等于中间位置的序号
那么 mid 等于q所包含的数据;
返回 mid;
else q指向下一节点;
}
}
3.代码截图




4.PTA提交列表说明

- 一开始使用的是头插法建表,但发现输出的数据是相反的,于是改成尾插法。
- 运行的时候提醒错误,我没有考虑如果两个链表刚好是首尾衔接的情况,程序运行异常,于是修改了判断条件。
- 最后运行的时候还是提示错误“最大N”和“最小N”,不停地测试数据,在发现输入“1 0 1”却输出为空时以为是这个错了,但是修改后PTA还是报错,实在找不出来了。
二、截图本周题目集的PTA最后排名
本次2个题目集总分:295分
1.顺序表PTA排名
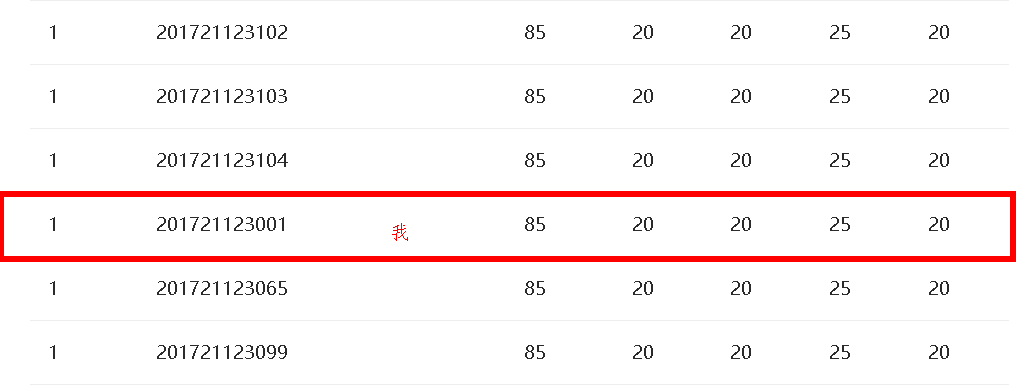
2.链表PTA排名

3.我的总分:176
三、本周学习总结
1.谈谈你本周数据结构学习时间是如何安排,对自己安排满意么,若不满意,打算做什么改变?
这一周因为有两个物理实验再加上晚上和周末还要去上课,课余时间比较少,导致我周三才开始写PTA,到今天还在挣扎着看能不能多做几题(但是真的太难了〒▽〒),尽管是因为时间少,我还是对这周的学习不满意,不能做到各科均衡,这几天忙着写代码又把其他科目给放下了,这样子明显很不行,所以要改变一下学习计划↓
- 每次上课前一定要做好预习,不一定能做到把书上例题看完看懂,但至少要知道这节课要讲什么内容;
- 其实可以拿个本子,在做课堂派、PTA的时候可以随时把自己不懂的、错的点记下来,以及改正的方法--->数据结构学习笔记(〃'▽'〃)
- 还有不能局限于课本的代码,要多看些优秀的代码,有助于自己理解代码写代码,这也是为什么老师一直推荐我们去找代码看,所以计划一天看一个代码,当然不是每天都会记得,所以一周至少看4个代码,对这些看过的代码也要做个记录。
2.谈谈你对线性表的认识?
线性表是一种逻辑结构,而不是某种特定的实现,线性表的实现方式有很多种,如顺序表,单链表,双向链表,循环链表,有序表等,但是都各有各的特点。
-
顺序表:顺序表可以随机存储,对存储空间的利用率高,访问元素也很快,时间复杂度为O(1),但是顺序表的插入需要移动大量的元素,时间复杂度为O(n)。
-
单链表:链表的每一个结点除了保存需要存储的数据外,还需要保存逻辑上相邻的下一个结点的地址。链表由n个类型相同的结点通过指针链接形成线性结构。结点由数据域和指针域组成。数据域用于存储结点代表的数据,指针域存储结点的后继结点地址。链表不支持随机访问。有n个结点的线性表,访问某个结点的平均时间复杂度为O(n/2),最坏为O(n) 。而数组支持随机访问,他的访问时间复杂度为O(1)。
-
插入和删除操作无需移动元素,只需修改结点的指针域。这点恰巧是顺序表(如ArrayList和数组)的缺点。
-
使用链表访问元素时,不支持随机访问。访问第n个数据元素,必须先得到第n-1个元素的地址,因此访问任何一个结点必须从头结点开始向后迭代寻找,直到找到这个目标结点为止。
-
-
循环单链表:最后的一个结点的指针域指向头结点。
-
遍历结束的标志是 p == 【头结点地址】,而不是p==NULL
-
表为空的判断标志是: if( head->next == head )
-
在单循环链表中,从任一结点出发都可访问到表中所有结点
-
-
双向链表:双向链表的结点有2个指针域:prior 和 next。next同样保存下一个结点的指针,而结点新增的成员prior则用来保存前一个结点的地址。
-
双向链表比单链表更占空间,因为每个结点多了一个指针域。
-
操作也更复杂。
-
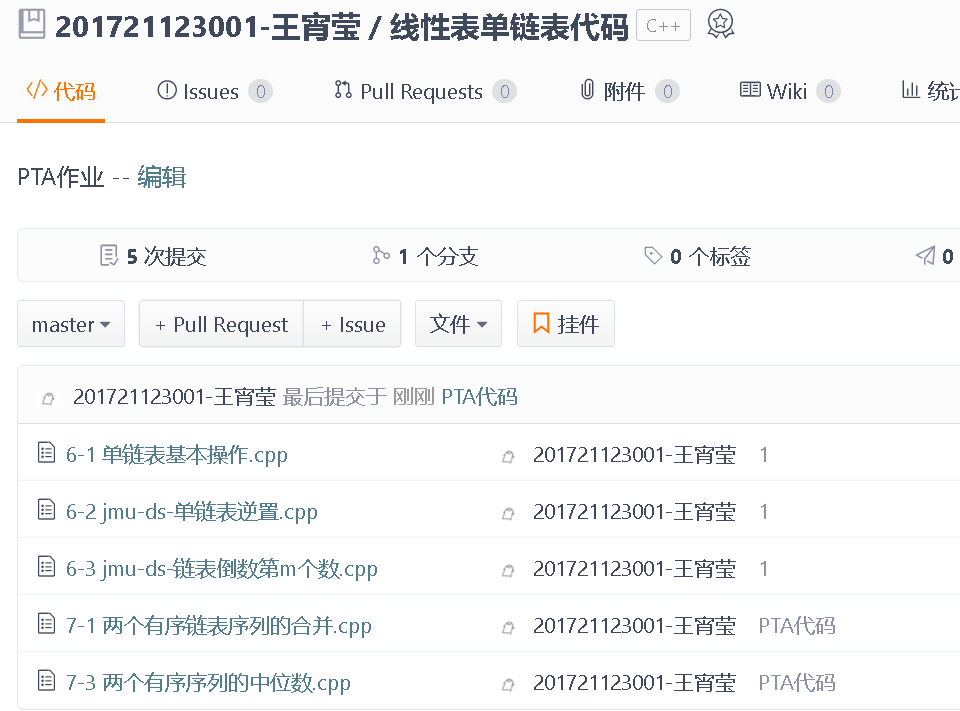
3.代码Git提交记录截图
(弄了好几天才成功= =)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号