
全文检索的基本原理
什么是全文检索?
我们生活中的数据总体分为两种:结构化数据和非结构化数据。
* 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
* 非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等。
当然有的地方还会提到第三种,半结构化数据,如XML,HTML等,当根据需要可按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理。
非结构化数据又一种叫法叫全文数据。
按照数据的分类,搜索也分为两种:
* 对结构化数据的搜索:如对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。
* 对非结构化数据的搜索:如利用windows的搜索也可以搜索文件内容,Linux下的grep命令,再如用Google和百度可以搜索大量内容数据。
非结构化数据搜索方法
顺序扫描法(Serial Scanning)
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。
如利用windows的搜索也可以搜索文件内容,只是相当的慢。如果你有一个80G硬盘,如果想在上面找到一个内容包含某字符串的文件,不花他几个小时,怕是做不到。
Linux下的grep命令也是这一种方式。大家可能觉得这种方法比较原始,但对于小数据量的文件,这种方法还是最直接,最方便的。但是对于大量的文件,这种方法就很慢了。
全文索引
全文检索的基本思路:将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
字典示例
比如字典,字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。
然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。
搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
全文检索的一般过程
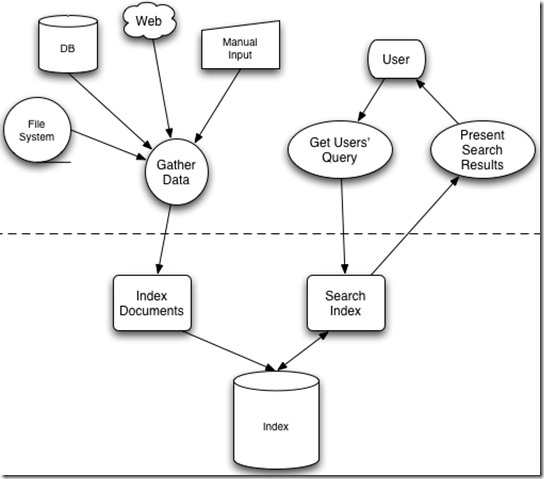
图来自《Lucene in action》
全文检索大体分两个过程,索引创建(Indexing)和搜索索引(Search)。
* 索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
* 搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
于是全文检索就存在三个重要问题:
- 索引里面究竟存些什么?(Index)
- 如何创建索引?(Indexing)
- 如何对索引进行搜索?(Search)
索引存些什么?
为什么顺序扫描的速度慢?是由于要搜索的信息和非结构化数据中所存储的信息不一致造成的。
非结构化数据中所存储的信息是每个文件包含哪些字符串,也即已知文件,欲求字符串相对容易,也即是从文件到字符串的映射。
而我们想搜索的信息是哪些文件包含此字符串,也即已知字符串,欲求文件,也即从字符串到文件的映射。
反向索引
两者恰恰相反。于是如果索引总能够保存从字符串到文件的映射,则会大大提高搜索速度。
由于从字符串到文件的映射是文件到字符串映射的反向过程,于是保存这种信息的索引称为反向索引。
反向索引保存的信息(词典-倒排表)
假设我的文档集合里面有100篇文档,为了方便表示,我们为文档编号从1到100,得到下面的结构

左边保存的是一系列字符串,称为词典。
每个字符串都指向包含此字符串的文档(Document)链表,此文档链表称为倒排表(Posting List)。
有了索引,便使保存的信息和要搜索的信息一致,可以大大加快搜索的速度。
反向索引查询示例
比如说,我们要寻找既包含字符串“lucene”又包含字符串“solr”的文档,我们只需要以下几步:
- 取出包含字符串“lucene”的文档链表。
- 取出包含字符串“solr”的文档链表。
- 通过合并链表,找出既包含“lucene”又包含“solr”的文件。

反向索引的优缺点
- 缺点:加上新建索引的过程,全文检索不一定比顺序扫描快,尤其是在数据量小的时候更是如此。而对一个很大量的数据创建索引也是一个很慢的过程。
- 优点:顺序扫描是每次都要扫描,而全文索引可一次索引,多次使用;检索速度快。
如何创建索引?
全文检索的索引创建过程一般有以下几步:
待索引的原文档(Document)
将原文档(Document)传给分词组件(Tokenizer)
分词组件(Tokenizer)会做以下几件事情(此过程称为Tokenize):
- 将文档分成一个一个单独的单词;
- 去除标点符号;
- 去除停用词(Stop word);
所谓停用词(Stop word)就是一种语言中最普通的一些单词,由于没有特别的意义,因而大多数情况下不能成为搜索的关键词,因而创建索引时,这种词会被去掉而减少索引的大小。
英语中挺词(Stop word)如:“the”,“a”,“this”等。
对于每一种语言的分词组件(Tokenizer),都有一个停词(stop word)集合。
经过分词(Tokenizer)后得到的结果称为词次(Token)。
将词次(Token)传给语言处理组件(Linguistic Processor)
语言处理组件(linguistic processor)主要是对得到的词次(Token)做一些同语言相关的处理。
对于英语,语言处理组件(Linguistic Processor)一般做以下几点:
- 变为小写(Lowercase)。
- 将单词缩减为词根形式,如“cars”到“car”等。这种操作称为:stemming。
- 将单词转变为词根形式,如“drove”到“drive”等。这种操作称为:lemmatization。
语言处理组件(linguistic processor)的结果称为词元(Term)。
将词元(Term)传给索引组件(Indexer)
索引组件(Indexer)主要做以下几件事情:
-
利用得到的词(Term)创建一个字典(Term-DocumentID)
-
对字典按字母顺序进行排序。
-
合并相同的词元(Term)成为文档倒排(Posting List)链表。
在此表中,有几个定义:- Document Frequency 即文档频次,表示总共有多少文件包含此词(Term)。
- Frequency 即词频率,表示此文件中包含了几个此词(Term)。

