
GFS分布式文件系统
目录
一、文件系统简介
1.1 文件系统的组成
1.2 文件系统的作用
1.3 文件系统的挂载使用
二、GFS分布式文件系统
2.1 GFS简介
2.2 GFS的特点
2.3 GFS专业术语
2.4 GFS 工作流程
2.5 服务器详解
三、GFS卷类型
3.1 分布式卷(Distribute volume)
3.2 条带卷 (Stripe volume)
3.3 复制卷(Replica volume)
3.4 分布式条带卷(Distribute Stripe volume)
3.5 分布式复制卷(Distribute Replica volume)
3.6 条带复制卷(Stripe Replica volume)和分布式条带复制卷(Distribute Stripe Replicavolume)
四、部署 GlusterFS 群集
五、总结
一、文件系统简介
1.1 文件系统的组成
- 接口:文件系统接口
- 功能模块(管理、存储的工具):对对象管理里的软件集合
- 对象及属性:(使用此文件系统的消费者
1.2 文件系统的作用
- 从系统角度来看,文件系统时对文件存储设备的空间进行组织和分配,负责文件存储并对存入的文件进行保护和检索的系统
- 主要负责为用户建立文件、存入、读出、修改、转储文件,控制文件的存取
1.3 文件系统的挂载使用
- 除跟文件系统以外的文件系统创建后要使用需要先挂载至挂载点后才可以被访问
- 挂载点即分区设备文件关联的某个目录文件
- 类比NFS(外部的文件系统),使用挂载的方式才可以让本地系统来使用外部的文件系统的功能
- 例如:配置永久挂载时,我们会写入挂载点与挂载目录,还有文件系统的名称(xfs),文件类型格式等。我们在远程跨服务器使用GFS分布式文件系统,挂载时也需要指定其文件格式(GlusterFS)
二、GFS分布式文件系统
2.1 GFS简介
- GFS是一个可扩展、开源的分布式文件系统(可以很好的体现出弹性伸缩的特点),用于大型的、分布式的、对大量数据进行访问的应用,在传统的解决方案中,GFS 能够灵活的结合物理的,虚拟的和云资源去体现高可用和企业级的性能存储
- GFS由三个组件组成
①存储服务器(Brick Server)
② 客户端(不在本地)(且,有客户端,也会有服务端,这点类似于 NFS,但是更为复杂)
③ 存储网关(NFS/Samaba)
1 无元数据服务器:
2 元数据是核心,描述对象的信息,影响其属性;
3 例如NFS,存放数据本身,是一个典型的元数据服务器可能存在单点故障,故要求服务器性能较高,服务器一旦出现故障就会导致数据丢失;
4 反过来看,所以无元数据服务不会有单点故障。
5 那么数据存放在哪里呢?会借用分布式的原则,分散存储,不会有一个统一的数据服务器
2.2 GFS的特点
- 扩展性和高性能:可扩展性,扩展节点,通过多节点提高性能
- 高可用性:不存在单点故障,有备份机制,类似Raid的容灾机制
- 全局同意命名空间:类比 API 的性质/概念,系统里根据他命名所定义的隔离区域,是一个独立空间;统一的名称空间,与客户端交互,把请求存放至后端的块数据服务器
- 弹性卷管理:方便扩容及对后端存储集群的管理与维护,较为复杂
- 基于标准协议:基于标准化的文件使用协议,让 CentOS 兼容 GFS
2.3 GFS专业术语
- Brick 存储服务器:实际存储用户数据的服务器
- Volume:本地文件系统的"分区”
- FUSE:用户 空间的文件系统(类比EXT4),“这是一个伪文件系统”;以本地文件系统为例,用户想要读写一个文件,会借助于EXT4文件系统,然后把数据写在磁盘上;而如果是远端的GFS,客户端的请求则应该交给FUSE(为文件系统),就可以实现跨界点存储在GFS上
- VFS(虚拟端口) :内核态的虚拟文件系统,用户是先提交请求交给VFS然后VFS交给FUSE,再交给GFS客户端,最后由客户端交给远端的存储
- Glusterd(服务):是允许在存储节点的进程
2.4 GFS 工作流程
① 客户端或应用程序通过 GlusterFS 的挂载点访问数据;
② linux系统内核**通过 VFS API 虚拟接口收到请求并处理;
③ VFS 将数据递交给 FUSE 内核文件系统,这是一个伪文件系统,这个伪文件系统主要用来转存,它提供一个虚拟接口,映射出来/dev/fuse这样一个虚拟路径,而 FUSE 文件系统则是将数据通过 /dev/fuse 设备文件递交给了 GlusterFS client 端。可以将 FUSE 文件系统理解为一个代理
④ GlusterFS client 会实时监听/dev/fuse下的数据,一旦数据更新,会把数据拿过来,client 根据配置文件的配置对数据进行处理
⑤ 经过 GlusterFS client 处理后,通过网络将数据传递至远端的 GlusterFS Server,server会先转存到本地的vfs虚拟文件系统中**,然后再通过vfs转存到EXT3上。EXT3指的是各个block块中的EXT3文件系统中。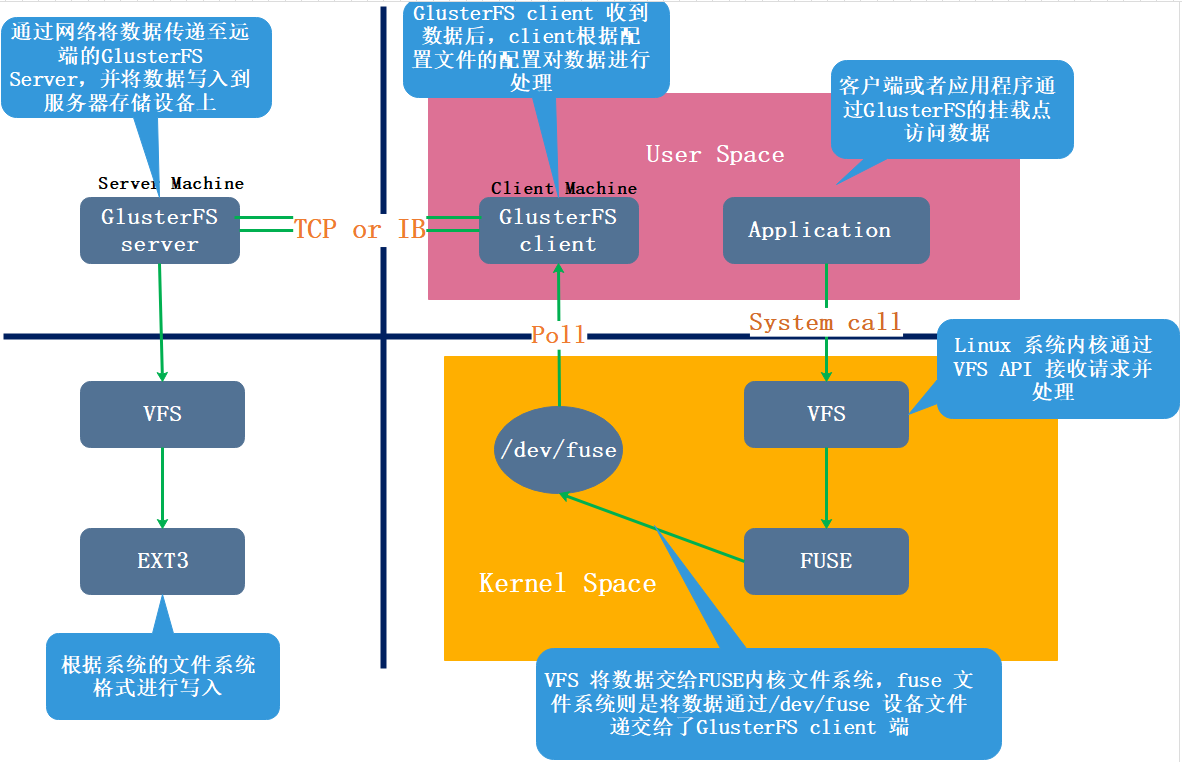
GFS-server 端功能模块的划分:
① 卷的类型(使用分布式、复制、条带)
② 存储管理(卷的创建、启用、关闭)
③ I/O调用(存储后,读取数据,如何读取)
④ 与GFS-client 端对接
GFS-client 端
① 用户通过用户态模式下,存储数据(写入数据)
② 写入的数据,使用GFS挂载的形式完成(网络挂载samba/NFS)
③数据的写入会由GFS-client转存到GFS-server端(对应的卷中)
网络通讯
① Infinlband ——— IB
② RDMA——— 面向连接传输协议—— 数据完整性(丢包率低)
③ TCP/IP
④ RDMA———》以后的服务中可以做为跨节点共享内存资源的协议
2.5 服务器详解
- Application:客户端或应用程序通过GlusterFSync的挂载点访问数据
- VFS:linux系统内核通过VFS的API 收到请求并处理
- FUSE:VFS将数据递交给FUSE内核文件系统,fuse文件系统则是将数据通过/dev/fuse设备文件递交给了GlusterFS
- GlusterFS Client :通过网络将数据传递至远端的GlusterFS Server, 并且写入到服务器存储设备上
三、GFS卷类型
3.1 分布式卷(Distribute volume)
简单来说,就是如果有10个文件,如果不用分布式卷,这是个文件会放在一台服务器上,对于分布式而言,这是个文件是会分布在不同的服务器节点上进行保存。
①特点
文件分布在不同的服务器,不具备冗余性更容易和廉价地扩展卷的大小单点故障会造成数据丢失以来低层的数据保护
②原理
File1 和 File2 存放在 Server1,而 File3 存放在 Server2,文件都是随机存储,一个文件(如 File1)要么在 Server1 上,要么在 Server2 上,不能分块同时存放在 Server1和 Server2 上
③创建分布式卷
创建一个名为dis-volume的分布式卷,文件将根据HASH分布在server1:/dir1、server2:/dir2和server3:/dir3中gluster volume create dis-volume server1:/dir1 server2:/dir2 server3:/dir3
3.2 条带卷 (Stripe volume)
类似 RAID0,文件被分成数据块并**以轮询的方式分布到多个 Brick Server 上**,文件存储以数据块为单位,支持大文件存储, 文件越大,读取效率越高,但是不具备冗余性
①原理
File 被分割为 6 段,1、3、5 放在 Server1,2、4、6 放在 Server2
②特点
根据偏移量将文件分成N块(N个条带点),轮询的存储在每个Brick Serve 节点.分布减少了负载,在存储大文件时,性能尤为突出.没有数据冗余,类似于Raid 0
③创建条带卷
创建了一个名为stripe-volume的条带卷,文件将被分块轮询的存储在Server1:/dir1和Server2:/dir2两个Brick中gluster volume create stripe-volume stripe 2 transport tcp server1:/dir1 server2:/dir2
3.3 复制卷(Replica volume)
将文件同步到多个 Brick 上,比如说我有五个文件,这5个文件是一个整体,放在服务器A上,复制卷会帮我们复制一份复制在服务器B上。属于文件级 RAID 1,具有容错能力。因为数据分散在多个 Brick 中,所以读性能得到很大提升,但写性能下降。复制卷具备冗余性,即使一个节点损坏,也不影响数据的正常使用。但因为要保存副本,所以磁盘利用率较低
①原理
File1 同时存在 Server1 和 Server2,File2 也是如此,相当于 Server2 中的文件是 Server1 中文件的副本
②特点
卷中所有的服务器均保存一个完整的副本。具备冗余性.卷的副本数量可由客户创建的时候决定,但复制数必须等于卷中 Brick 所包含的存储服务器数。至少由两个块服务器或更多服务器。若多个节点上的存储空间不一致,将按照木桶效应取最低节点的容量作为改卷的总容量
③创建复制卷
创建名为rep-volume的复制卷,文件将同时存储两个副本,分别在Server1:/dir1和Server2:/dir2两个Brick中gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir2
3.4 分布式条带卷(Distribute Stripe volume)
Brick Server 数量是条带数(数据块分布的 Brick 数量)的倍数,兼具分布式卷和条带卷的特点。 主要用于大文件访问处理,创建一个分布式条带卷最少需要 4 台服务器
①原理
File1 和 File2 通过分布式卷的功能分别定位到Server1和 Server2。在 Server1 中,File1 被分割成 4 段,其中 1、3 在 Server1 中的 exp1 目录中,2、4 在 Server1 中的 exp2 目录中。在 Server2 中,File2 也被分割成 4 段,其中 1、3 在 Server2 中的 exp3 目录中,2、4 在 Server2 中的 exp4 目录中
②创建分布式条带卷
创建一个名为dis-stripe的分布式条带卷,配置分布式的条带卷时,卷中Brick所包含的存储服务器数必须是条带数的倍数(>=2倍)。Brick 的数量是 4(Server1:/dir1、Server2:/dir2、Server3:/dir3 和 Server4:/dir4),条带数为 2(stripe 2)gluster volume create dis-stripe stripe 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
创建卷时,存储服务器的数量如果等于条带或复制数,那么创建的是条带卷或者复制卷;如果存储服务器的数量是条带或复制数的 2 倍甚至更多,那么将创建的是分布式条带卷或分布式复制卷
3.5 分布式复制卷(Distribute Replica volume)
分布式复制卷(Distribute Replica volume):Brick Server 数量是镜像数(数据副本数量)的倍数,兼具分布式卷和复制卷的特点,主要用于需要冗余的情况下
①原理
File1 和 File2 通过分布式卷的功能分别定位到 Server1 和 Server2。在存放 File1 时,File1 根据复制卷的特性,将存在两个相同的副本,分别是 Server1 中的exp1 目录和 Server2 中的 exp2 目录。在存放 File2 时,File2 根据复制卷的特性,也将存在两个相同的副本,分别是 Server3 中的 exp3 目录和 Server4 中的 exp4 目录
②创建分布式复制卷
建一个名为dis-rep的分布式复制卷,配置分布式的复制卷时,卷中Brick所包含的存储服务器数必须是复制数的倍数(>=2倍)。Brick 的数量是 4(Server1:/dir1、Server2:/dir2、Server3:/dir3 和 Server4:/dir4),复制数为 2(replica 2)gluster volume create dis-rep replica 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
3.6 条带复制卷(Stripe Replica volume)和分布式条带复制卷(Distribute Stripe Replicavolume)
条带复制卷(Stripe Replica volume)类似 RAID 1 0,同时具有条带卷和复制卷的特点。
分布式条带复制卷(Distribute Stripe Replicavolume)三种基本卷的复合卷,通常用于类 Map Reduce 应用
四、部署 GlusterFS 群集
准备环境
Node1节点:192.168.239.5
Node2节点:192.168.239.6
Node3节点:192.168.239.7
Node4节点:192.168.239.8
客户端节点:192.168.226.3

1.关闭防火墙
systemctl stop firewalld
setenforce 0
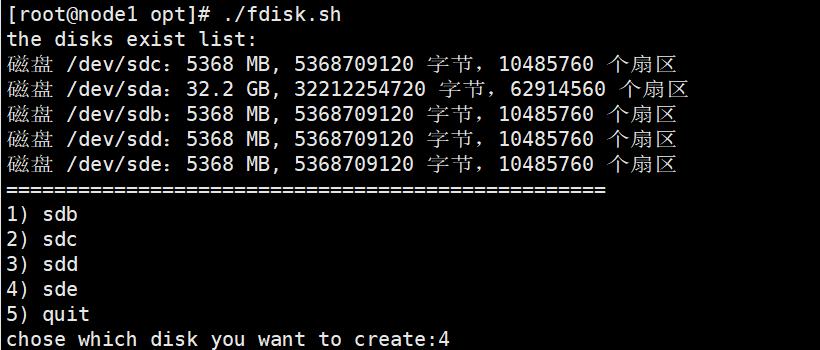
2.磁盘分区,并挂载
vim /opt/fdisk.sh
#! /bin/bash
echo "the disks exist list:"
fdisk -l |grep '磁盘 /dev/sd[a-z]'
echo "=================================================="
PS3="chose which disk you want to create:"
select VAR in `ls /dev/sd*|grep -o 'sd[b-z]'|uniq` quit
do
case $VAR in
sda)
fdisk -l /dev/sda
break ;;
sd[b-z])
#create partitions
echo "n
p
w" | fdisk /dev/$VAR
#make filesystem
mkfs.xfs -i size=512 /dev/${VAR}"1" &> /dev/null
#mount the system
mkdir -p /data/${VAR}"1" &> /dev/null
echo -e "/dev/${VAR}"1" /data/${VAR}"1" xfs defaults 0 0\n" >> /etc/fstab
mount -a &> /dev/null
break ;;
quit)
break;;
*)
echo "wrong disk,please check again";;
esac
done
chmod +x /opt/fdisk.sh
cd /opt/
./fdisk.sh
“友情” 提示:这部分做完后,使用df -hT 确认是否全部分区挂载完成





#修改主机名,配置/etc/hosts文件
1 echo "192.168.239.5 node1" >> /etc/hosts
2 echo "192.168.239.6 node2" >> /etc/hosts
3 echo "192.168.239.7 node3" >> /etc/hosts
4 echo "192.168.239.8 node4" >> /etc/hosts

#安装、启动GlusterFS(所有node节点上操作)
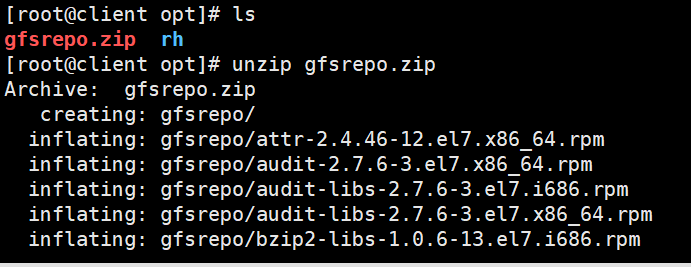
1 #将gfsrepo 软件上传到/opt目录下
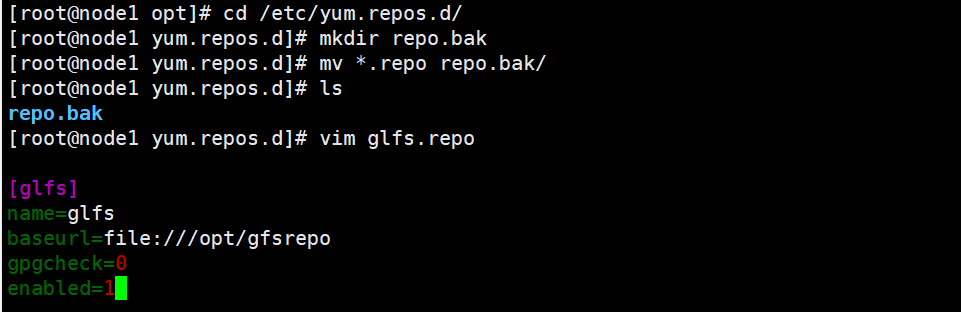
2 cd /etc/yum.repos.d/
3 mkdir repo.bak
4 mv *.repo repo.bak
5
6 unzip gfsrepo.gzip
7
8 vim glfs.repo
9 [glfs]
10 name=glfs
11 baseurl=file:///opt/gfsrepo
12 gpgcheck=0
13 enabled=1
14
15 yum clean all && yum makecache
16
17 #yum -y install centos-release-gluster #如采用官方 YUM 源安装,可以直接指向互联网仓库
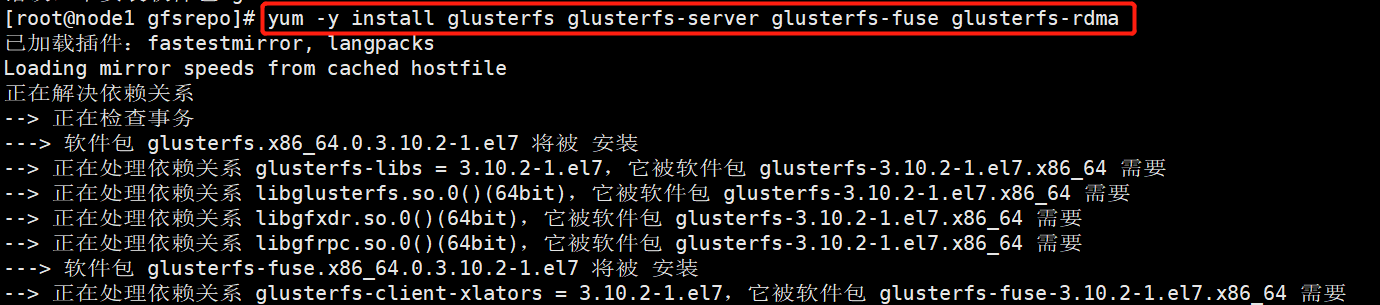
18 yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
19
20 systemctl start glusterd.service
21 systemctl enable glusterd.service
22 systemctl status glusterd.service
23
24 #进行时间同步
25 ntpdate ntp1.aliyun.com



#添加节点到存储信任池中(在 node1 节点上操作)
1 #只要在一台Node节点上添加其它节点即可
2 gluster peer probe node1
3 gluster peer probe node2
4 gluster peer probe node3
5 gluster peer probe node4
6
7 #在每个Node节点上查看群集状态
8 gluster peer status

#创建卷
#根据规划创建如下卷:
卷名称 卷类型 Brick
dis-volume 分布式卷 node1(/data/sdb1)、node2(/data/sdb1)
stripe-volume 条带卷 node1(/data/sdc1)、node2(/data/sdc1)
rep-volume 复制卷 node3(/data/sdb1)、node4(/data/sdb1)
dis-stripe 分布式条带卷 node1(/data/sdd1)、node2(/data/sdd1)、node3(/data/sdd1)、node4(/data/sdd1)
dis-rep 分布式复制卷 node1(/data/sde1)、node2(/data/sde1)、node3(/data/sde1)、node4(/data/sde1)
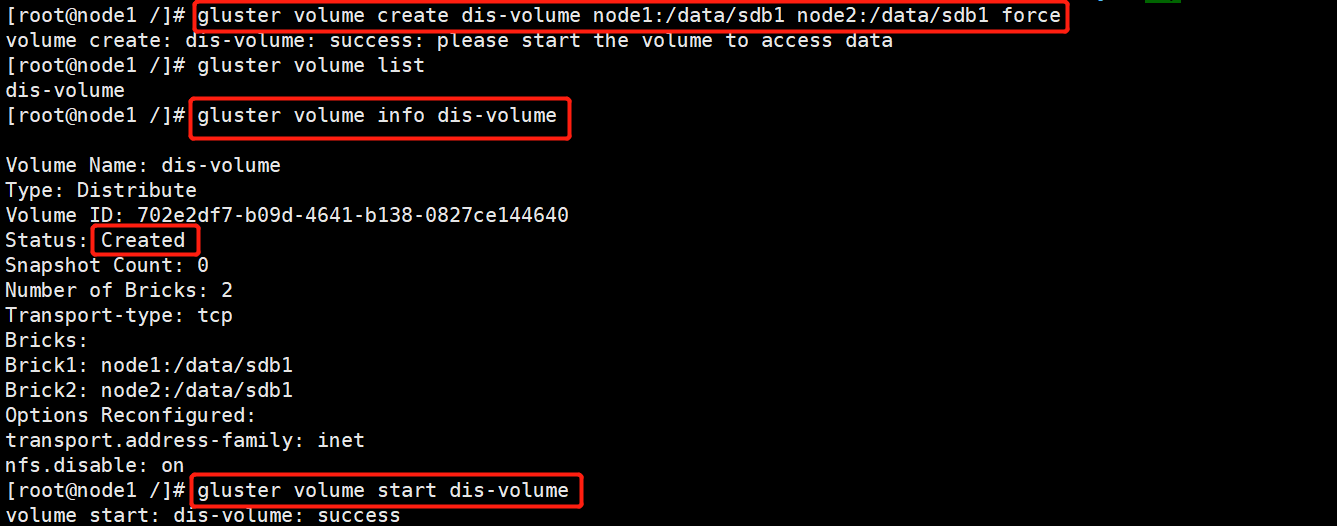
1.创建分布式卷
#创建分布式卷,没有指定类型,默认创建的是分布式卷
gluster volume create dis-volume node1:/data/sdb1 node2:/data/sdb1 force
#查看卷列表
gluster volume list
#启动新建分布式卷
gluster volume start dis-volume
#查看创建分布式卷信息
gluster volume info dis-volume
2.创建条带卷
#指定类型为 stripe,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是条带卷
gluster volume create stripe-volume stripe 2 node1:/data/sdc1 node2:/data/sdc1 force
gluster volume start stripe-volume
gluster volume info stripe-volume
3.创建复制卷
#指定类型为 replica,数值为 2,且后面跟了 2 个 Brick Server,所以创建的是复制卷
gluster volume create rep-volume replica 2 node3:/data/sdb1 node4:/data/sdb1 force
gluster volume start rep-volume
gluster volume info rep-volume
4.创建分布式条带卷
#指定类型为 stripe,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍,所以创建的是分布式条带卷
gluster volume create dis-stripe stripe 2 node1:/data/sdd1 node2:/data/sdd1 node3:/data/sdd1 node4:/data/sdd1 force
gluster volume start dis-stripe
gluster volume info dis-stripe
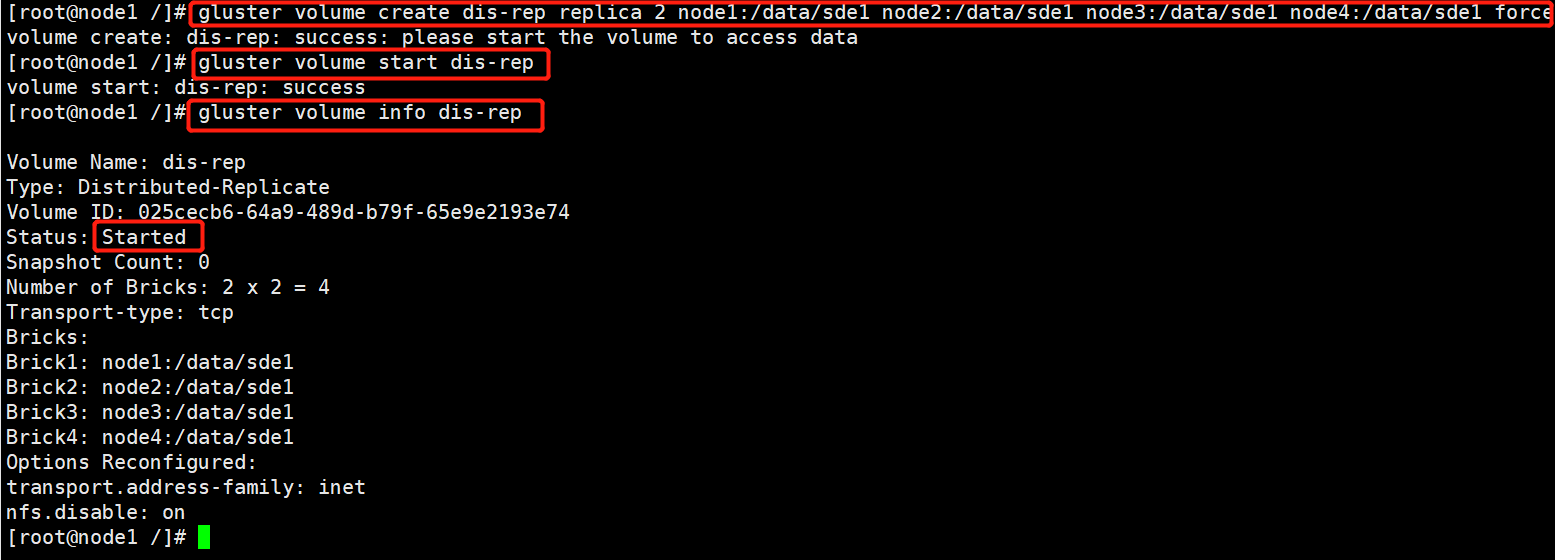
5.创建分布式复制卷
指定类型为 replica,数值为 2,而且后面跟了 4 个 Brick Server,是 2 的两倍,所以创建的是分布式复制卷
gluster volume create dis-rep replica 2 node1:/data/sde1 node2:/data/sde1 node3:/data/sde1 node4:/data/sde1 force
gluster volume start dis-rep
gluster volume info dis-rep
gluster volume list





#部署 Gluster 客户端
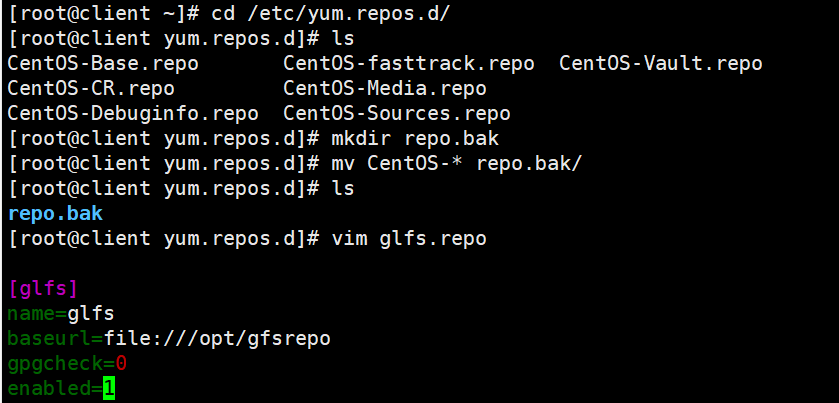
1.安装客户端软件
#将gfsrepo 软件上传到/opt目下
cd /etc/yum.repos.d/
mkdir repo.bak
mv *.repo repo.bak
vim glfs.repo
[glfs]
name=glfs
baseurl=file:///opt/gfsrepo
gpgcheck=0
enabled=1
yum clean all && yum makecache
yum -y install glusterfs glusterfs-fuse
2.创建挂载目录
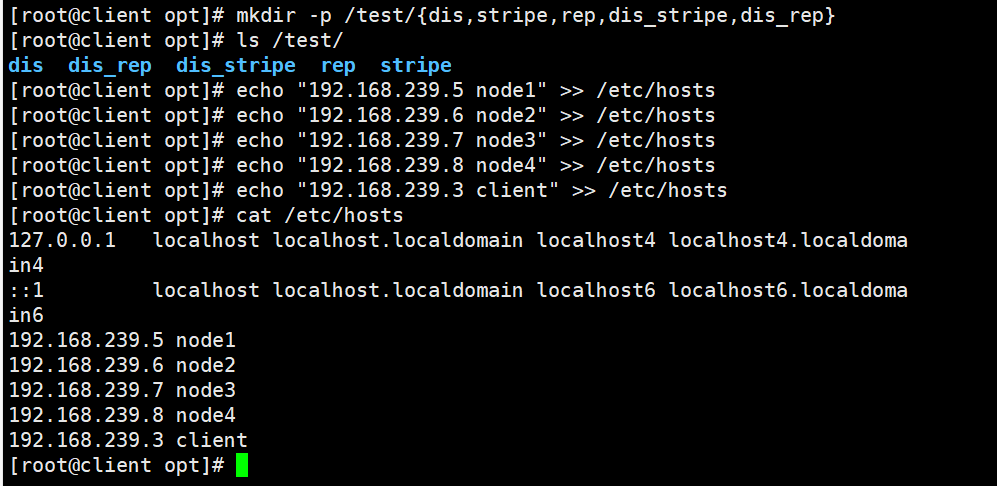
mkdir -p /test/{dis,stripe,rep,dis_stripe,dis_rep}
ls /test
3.配置 /etc/hosts 文件
echo "192.168.239.5 node1" >> /etc/hosts
echo "192.168.239.6 node2" >> /etc/hosts
echo "192.168.239.7 node3" >> /etc/hosts
echo "192.168.239.8 node4" >> /etc/hosts
echo "192.168.239.3 client" >> /etc/hosts
4.挂载 Gluster 文件系统
#临时挂载
mount.glusterfs node1:dis-volume /test/dis
mount.glusterfs node1:stripe-volume /test/stripe
mount.glusterfs node1:rep-volume /test/rep
mount.glusterfs node1:dis-stripe /test/dis_stripe
mount.glusterfs node1:dis-rep /test/dis_rep
df -Th
#永久挂载
vim /etc/fstab
node1:dis-volume /test/dis glusterfs defaults,_netdev 0 0
node1:stripe-volume /test/stripe glusterfs defaults,_netdev 0 0
node1:rep-volume /test/rep glusterfs defaults,_netdev 0 0
node1:dis-stripe /test/dis_stripe glusterfs defaults,_netdev 0 0
node1:dis-rep /test/dis_rep glusterfs defaults,_netdev 0 0


#测试 Gluster 文件系统
1.卷中写入文件,客户端操作
cd /opt
dd if=/dev/zero of=/opt/demo1.log bs=1M count=40
dd if=/dev/zero of=/opt/demo2.log bs=1M count=40
dd if=/dev/zero of=/opt/demo3.log bs=1M count=40
dd if=/dev/zero of=/opt/demo4.log bs=1M count=40
dd if=/dev/zero of=/opt/demo5.log bs=1M count=40
ls -lh /opt
cp demo* /test/dis
cp demo* /test/stripe/
cp demo* /test/rep/
cp demo* /test/dis_stripe/
cp demo* /test/dis_rep/
2.查看文件分布
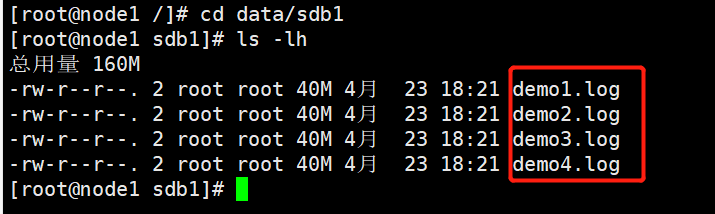
#查看分布式文件分布
[root@node1 ~]# ls -lh /data/sdb1 #数据没有被分片
总用量 160M
-rw-r--r-- 2 root root 40M 12月 18 14:50 demo1.log
-rw-r--r-- 2 root root 40M 12月 18 14:50 demo2.log
-rw-r--r-- 2 root root 40M 12月 18 14:50 demo3.log
-rw-r--r-- 2 root root 40M 12月 18 14:50 demo4.log
[root@node2 ~]# ll -h /data/sdb1
总用量 40M
-rw-r--r-- 2 root root 40M 12月 18 14:50 demo5.log
#查看条带卷文件分布
[root@node1 ~]# ls -lh /data/sdc1 #数据被分片50% 没副本 没冗余
总用量 101M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo4.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo5.log
[root@node2 ~]# ll -h /data/sdc1 #数据被分片50% 没副本 没冗余
总用量 101M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo4.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo5.log
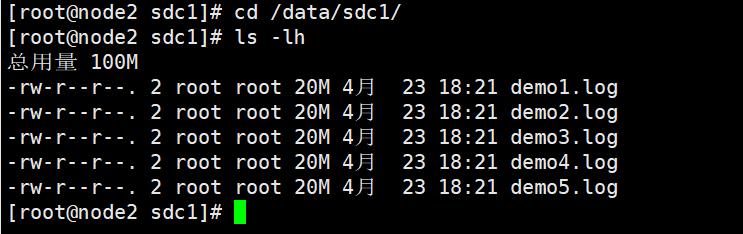
#查看复制卷分布
[root@node3 ~]# ll -h /data/sdb1 #数据没有被分片 有副本 有冗余
总用量 201M
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo4.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo5.log
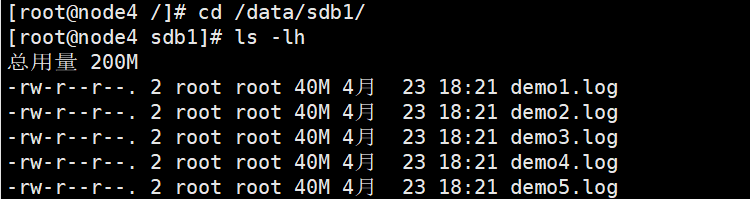
[root@node4 ~]# ll -h /data/sdb1 #数据没有被分片 有副本 有冗余
总用量 201M
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo4.log
-rw-r--r-- 2 root root 40M 12月 18 14:51 demo5.log
#查看分布式条带卷分布
[root@node1 ~]# ll -h /data/sdd1 #数据被分片50% 没副本 没冗余
总用量 81M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo4.log
[root@node2 ~]# ll -h /data/sdd1
总用量 81M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo1.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo2.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo3.log
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo4.log
[root@node3 ~]# ll -h /data/sdd1
总用量 21M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo5.log
[root@node4 ~]# ll -h /data/sdd1
总用量 21M
-rw-r--r-- 2 root root 20M 12月 18 14:51 demo5.log
#查看分布式复制卷分布
#数据没有被分片 有副本 有冗余
[root@node1 ~]# ll -h /data/sde1
总用量 161M
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo1.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo2.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo3.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo4.log
[root@node2 ~]# ll -h /data/sde1
总用量 161M
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo1.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo2.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo3.log
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo4.log
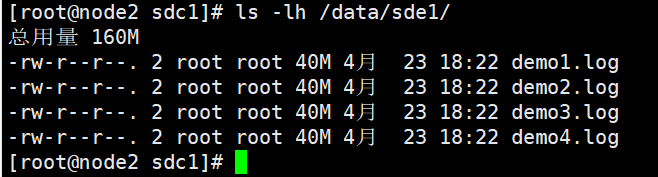
[root@node3 ~]# ll -h /data/sde1
总用量 41M
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo5.log
[root@node3 ~]#
[root@node4 ~]# ll -h /data/sde1
总用量 41M
-rw-r--r-- 2 root root 40M 12月 18 14:52 demo5.log













#破坏性测试
#挂起 node2 节点或者关闭glusterd服务来模拟故障
[root@node2 ~]# systemctl stop glusterd.service
#在客户端上查看文件是否正常
#分布式卷数据查看
[root@localhost dis]# ll #在客户上发现少了demo5.log文件,这个是在node2上的
总用量 163840
-rw-r--r-- 1 root root 41943040 12月 18 14:50 demo1.log
-rw-r--r-- 1 root root 41943040 12月 18 14:50 demo2.log
-rw-r--r-- 1 root root 41943040 12月 18 14:50 demo3.log
-rw-r--r-- 1 root root 41943040 12月 18 14:50 demo4.log
#条带卷
[root@localhost text]# cd stripe/ #无法访问,条带卷不具备冗余性
[root@localhost stripe]# ll
总用量 0
#分布式条带卷
[root@localhost dis_and_stripe]# ll #无法访问,分布条带卷不具备冗余性
总用量 40960
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo5.log
#分布式复制卷
[root@localhost dis_and_rep]# ll #可以访问,分布式复制卷具备冗余性
总用量 204800
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo1.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo2.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo3.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo4.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo5.log
#挂起 node2 和 node4 节点,在客户端上查看文件是否正常
#测试复制卷是否正常
[root@localhost rep]# ls -l #在客户机上测试正常 数据有
总用量 204800
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo1.log
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo2.log
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo3.log
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo4.log
-rw-r--r-- 1 root root 41943040 12月 18 14:51 demo5.log
#测试分布式条卷是否正常
[root@localhost dis_stripe]# ll #在客户机上测试正常 没有数据
总用量 0
#测试分布式复制卷是否正常
[root@localhost dis_and_rep]# ll #在客户机上测试正常 有数据
总用量 204800
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo1.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo2.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo3.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo4.log
-rw-r--r-- 1 root root 41943040 12月 18 14:52 demo5.log
五、总结
GFS数据流向
①mysql服务器——>存储数据到挂载目录中/data
②mysql数据会优先交给内核的文件系统处理——>GFS客户端处理(本地)
③GFS客户端会和GFS服务端进行交互,GFS服务端接收到数据,然后再通过挂载的卷的类型,对应保存在后端block块节点服务器上
分布式条带复制卷(Distribute Stripe Replicavolume)三种基本卷的复合卷,通常用于类 Map Reduce 应用
器——>存储数据到挂载目录中/data
②mysql数据会优先交给内核的文件系统处理——>GFS客户端处理(本地)
③GFS客户端会和GFS服务端进行交互,GFS服务端接收到数据,然后再通过挂载的卷的类型,对应保存在后端block块节点服务器上
分布式条带复制卷(Distribute Stripe Replicavolume)三种基本卷的复合卷,通常用于类 Map Reduce 应用


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律