
MySQL高级语句
目录
—、SQL高级语句
1.导入文件至数据库
2.select
3. distinct
4.where
5.and;or
6.in
7.between
8.like通配符
9. order by
10.函数
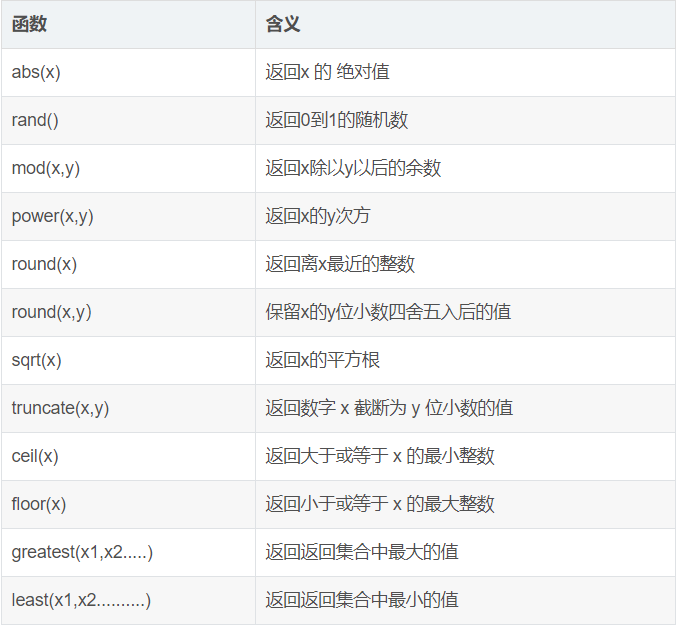
10.1数学函数
10.2聚合函数
10.3字符串函数
11.group by
12.having
13.别名
14.连接查询
① inner join(等值相连)
② left join(左联接)
③ right join(右联接)
15.子查询
16.EXISTS
二、CREATE VIEW(视图)
三、存储过程
3.1存储过程的优点
3.2创建、调用和查看存储的过程
3.2.1创建存储过程
3.2.2调用存储过程
3.2.3查看存储过程
3.2.4删除存储过程
3.3存储过程的参数
—、SQL高级语句
1.导入文件至数据库
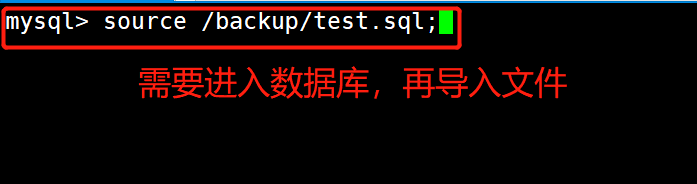
1 #将脚本导入 source 加文件路径
2 mysql> source /backup/test.sql;
2.select
- 显示表格中的一个或者多个字段中所有的信息
1 #语法:
2 select 字段名 from 表名;
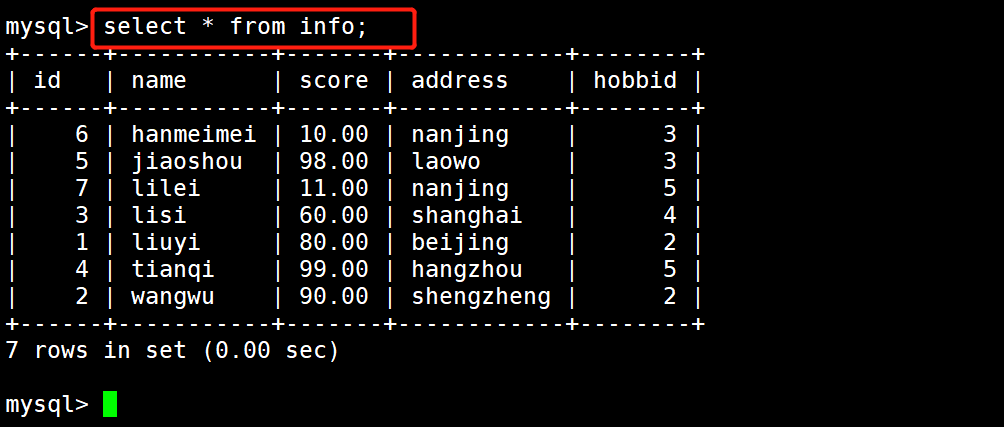
1 示例1:
2 select * from info;
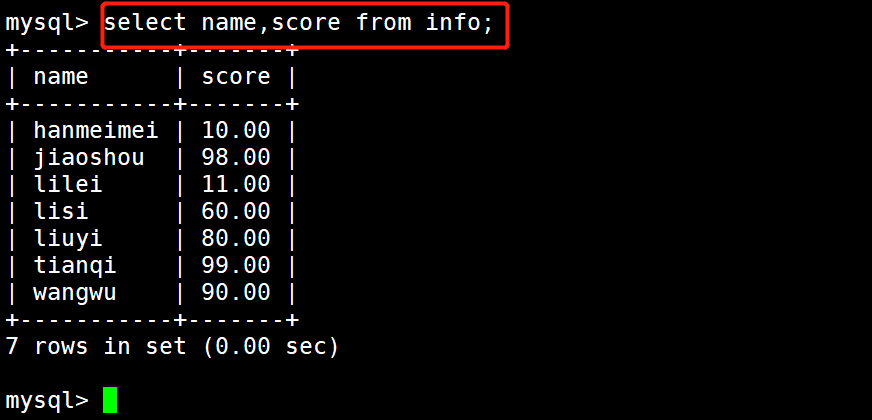
示例2:
select name,score from info;
3. distinct
- 查询不重复记录
1 #语法:
2 select distinct 字段 from 表名﹔
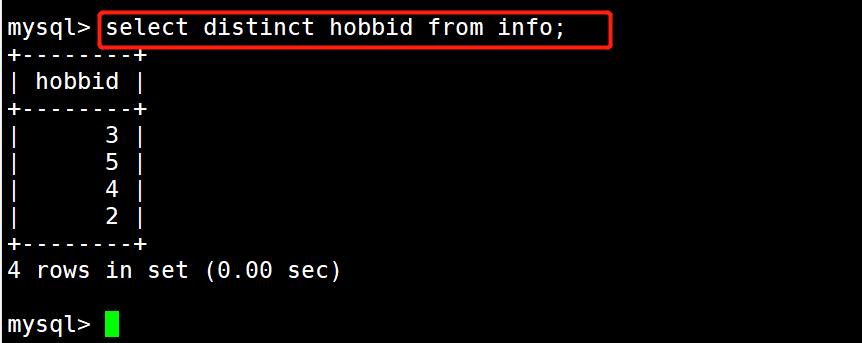
1 1 #示例1:去除hobbid字段中重复
2 2 select distinct hobbid from info;
4.where
- where 有条件的查询
1 #语法:
2 select '字段' from 表名 where 条件
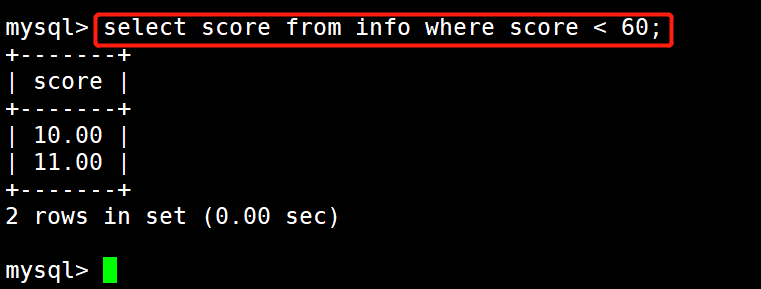
#示例:显示score 小于60的
select score from info where score < 60;
5.and;or
- and 且 ; or 或
1 #语法:
2 select 字段名 from 表名 where 条件1 (and|or) 条件2 (and|or)条件3;
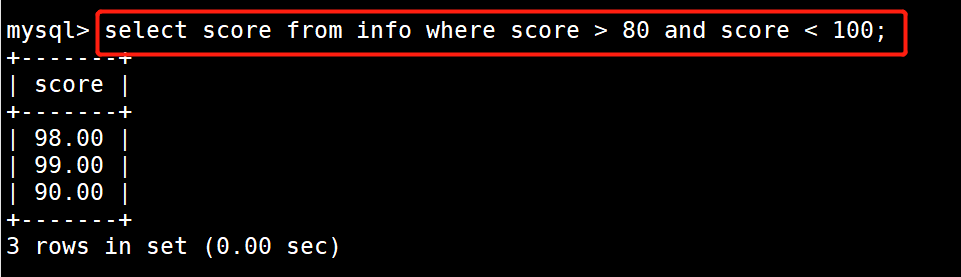
示例1:显示score 并且要找到score大于80小于100
select score from info where score > 80 and score < 100;
6.in
- 显示已知值的资料
1 #语法:
2 select 字段名 from 表名 where 字段 in ('值1','值2'....);
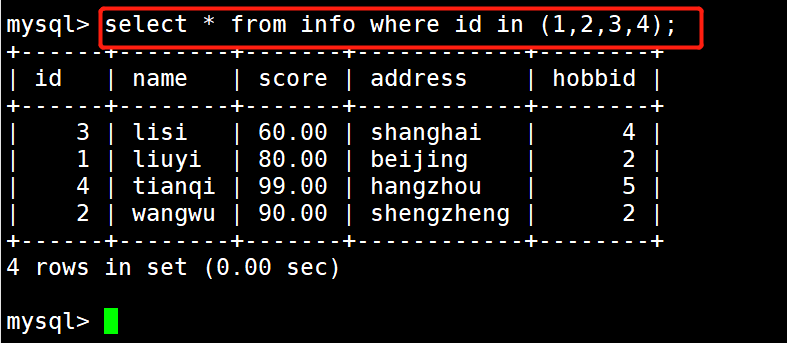
1 #示例1:显示id为1,2,3,4的学生记录
2 select * from info where id in (1,2,3,4);
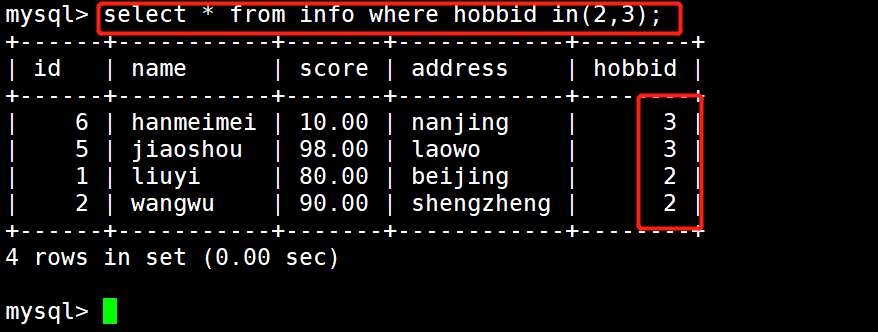
1 #示例2:显示hobbid为2和3的学生记录
2 select * from info where hobbid in (2,3);
7.between
- 显示两个值范围内的资料
1 #语法:
2 select 字段名 from 表名 where 字段 between '值1' and '值2';
3 包括 and两边的值
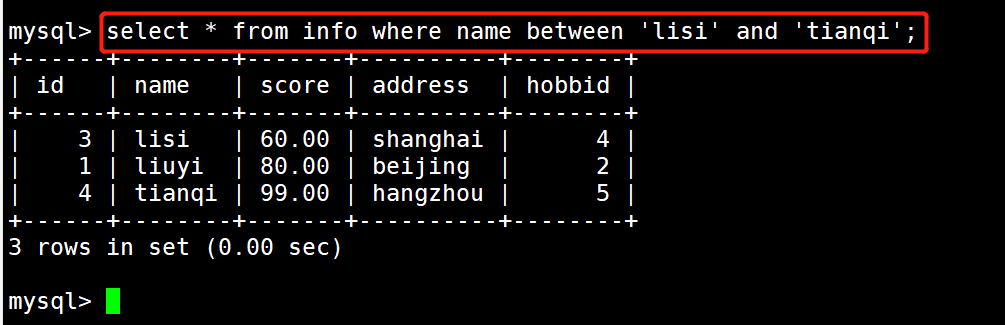
1 #示例1:显示学生姓名在lisi和tianqi中的学生记录
2 select * from info where name between 'lisi' and 'tianqi';
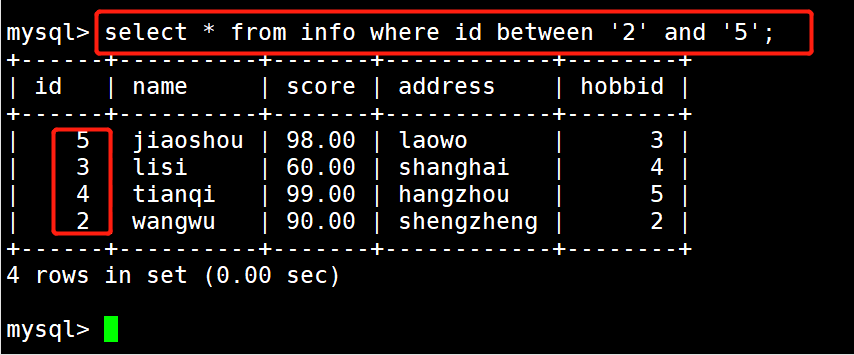
#示例2:显示学生号码id在2-5 的信息
select * from info where id between 2 and 5;
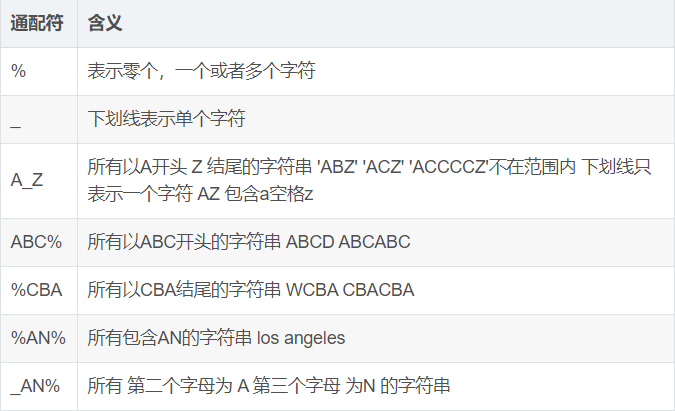
8.like通配符
- 通配符通常是和 like 一起使用
1 #语法:
2 select 字段名 from 表名 where 字段 like 模式
1 #示例1:查找名字以l开头的学生记录
2 select * from info where name like 'l%';

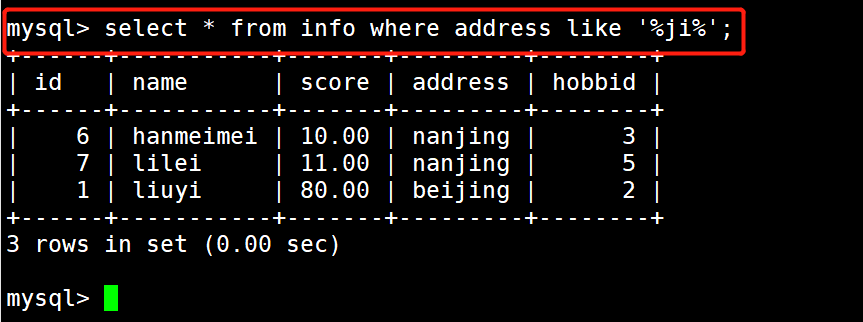
1 #示例2:查找地址包含ji的学生记录
2 select * from info where address like '%ji%';
9. order by
- order by 按关键字排序
1 #语法:
2 select 字段名 from 表名 where 条件 order by 字段 [asc,desc];
3 asc :正向排序
4 desc :反向排序
5 默认是正向排序
1 #示例1:按学生的分数正向排序显示分数和姓名字段
2 select name,score from info order by score;
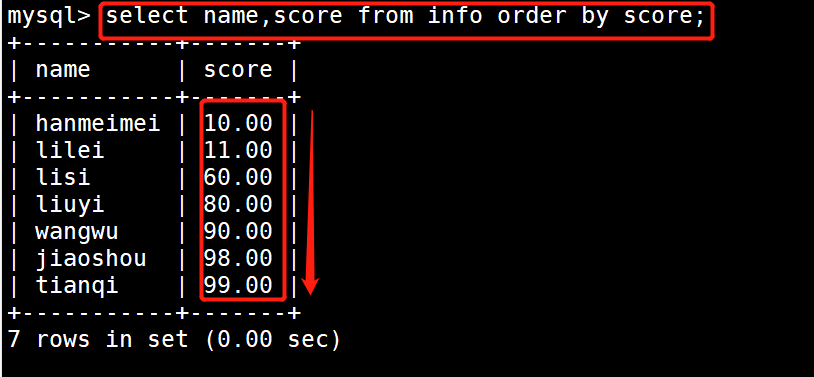
1 #示例1:按学生的分数反向排序显示分数和姓名字段
2 select name,score from info order by score desc;

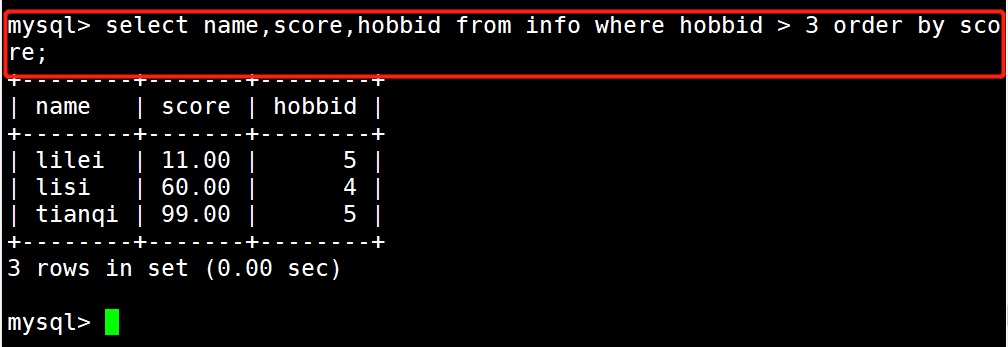
1 #示例3:显示name、age和hobbid字段的数据 并且只显示hobbid字段大于3 的 并且以score字段正向排序
2 select name,score,hobbid from info where hobbid > 3 order by score;
10.函数
10.1数学函数
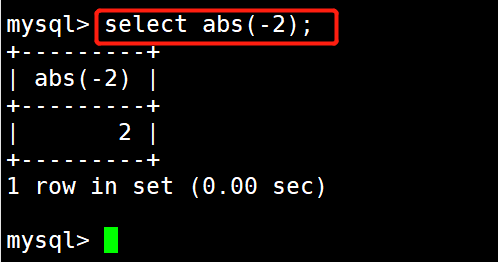
1 #示例1:返回-2的绝对值
2 select abs(-2);
1 #示例2:随机生成一个数
2 select rand (2);
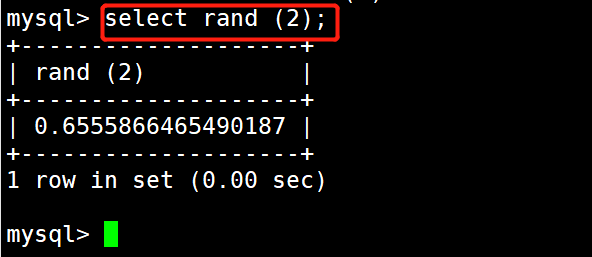
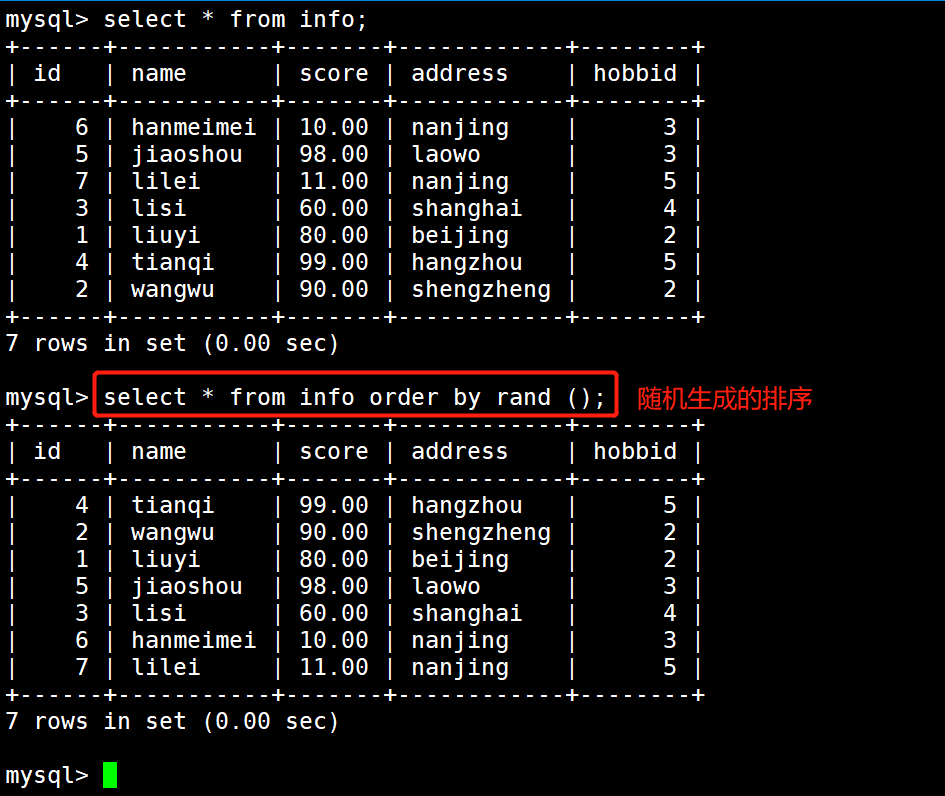
1 #示例3:随机生成排序
2 select * from info order by rand ();
#示例4:返回8除以2以后的余数
select mod(8,2);

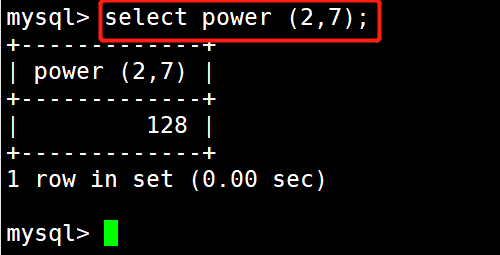
#示例5:返回2的7次方
select power(2,7);
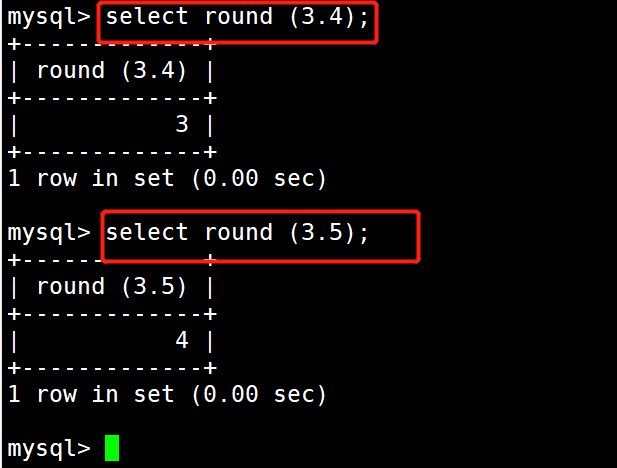
#示例6:返回离3.4最近的数
select round(3.4);
#返回离3.5最近的数
select round(3.5);
#示例7:保留3.141527的3位小数四舍五入后的值
select round(3.141527,2);
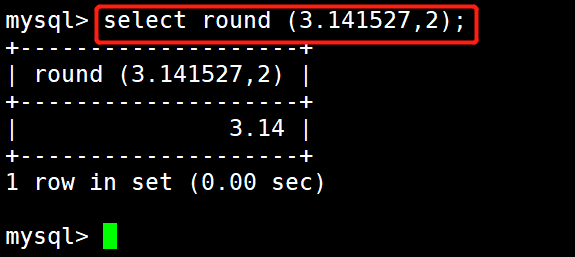
#示例8:返回数字 3.145527 截断为2位小数的值
select truncate(3.145527,2);
1 #示例9:返回大于或等于3.141527 的最小整数
2 select ceil(3.141527);
3
4 返回小于或等于 3.141527 的最大整数
5 select floor(3.141527);

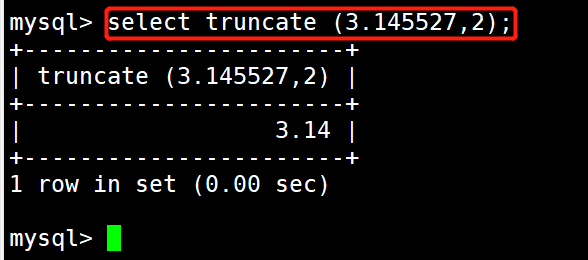
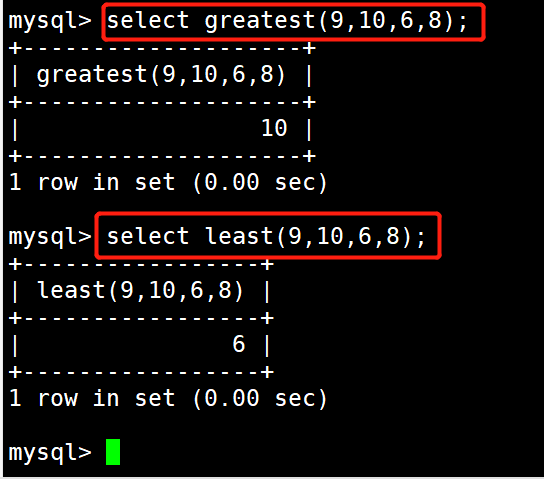
#示例11:返回集合中最大的值
select greatest(9,10,6,8);
返回集合中最小的值
select least(9,10,6,8);
10.2聚合函数

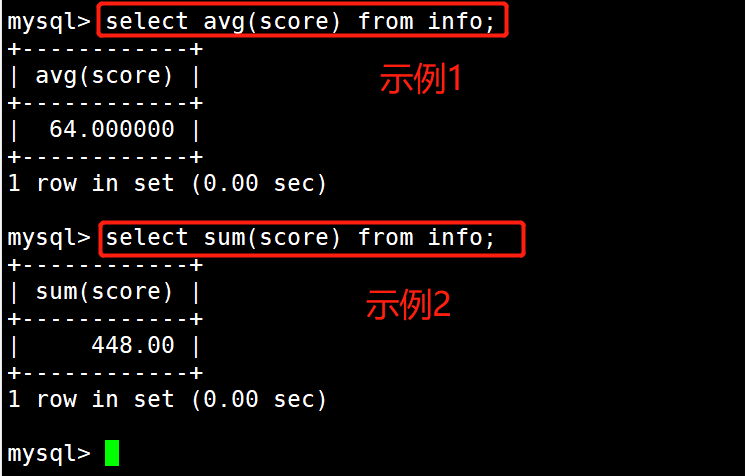
1 #示例1:求表中分数的平均值
2 select avg(score) from info;
3 #示例2:求表中分数的总和
4 select sum(score) from info;
5 #示例3:求表中分数的最大值
6 select max(score) from info;
7 #示例4:求表中分数的最小值
8 select min(score) from info;

#示例5:求表中有多少分数字段非空记录
select count(score) from info;
count(明确字段):不会忽略空记录
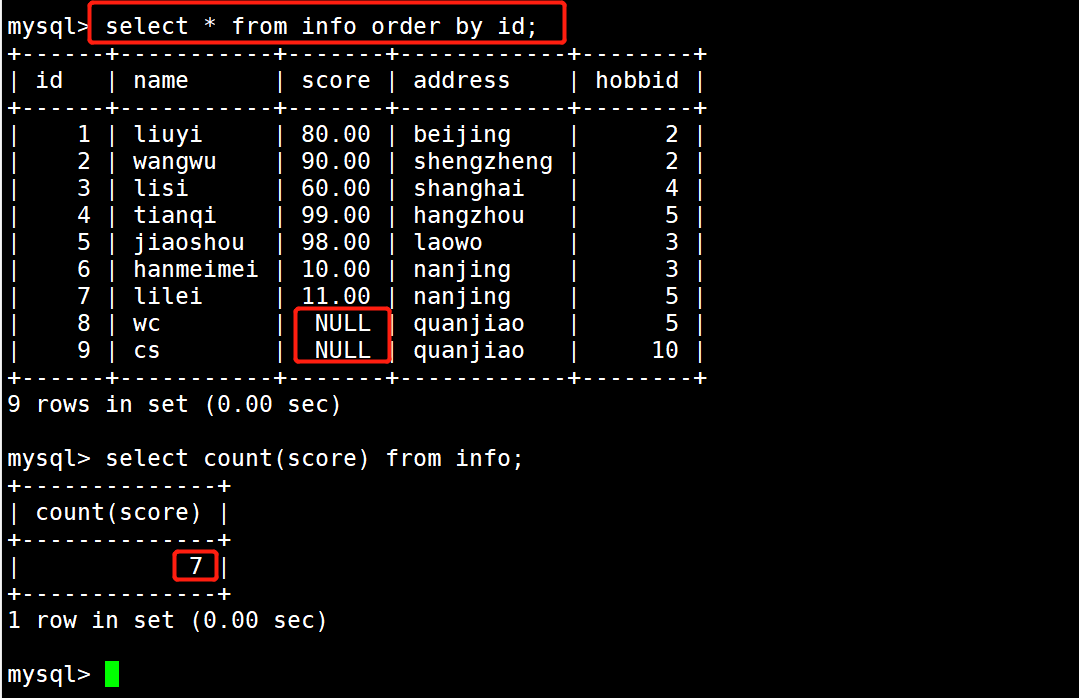
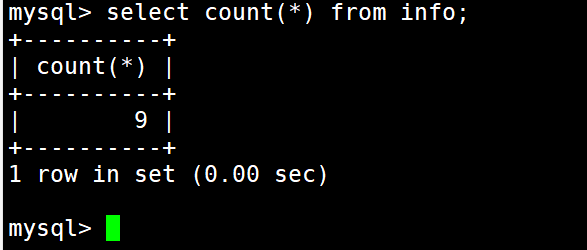
1 #示例6:求表中有多少条记录
2 select count(*) from info;
3
4 count(*)包含空字段,会忽略空记录
10.3字符串函数
11.group by
-
对group by 后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的
-
group by 有一个原则,就是select 后面的所有列中,没有使用聚合函数的列必须出现在 group by 的后面。
1 #语法:
2 select 字段1,sum(字段2) from 表名 group by 字段1;
3
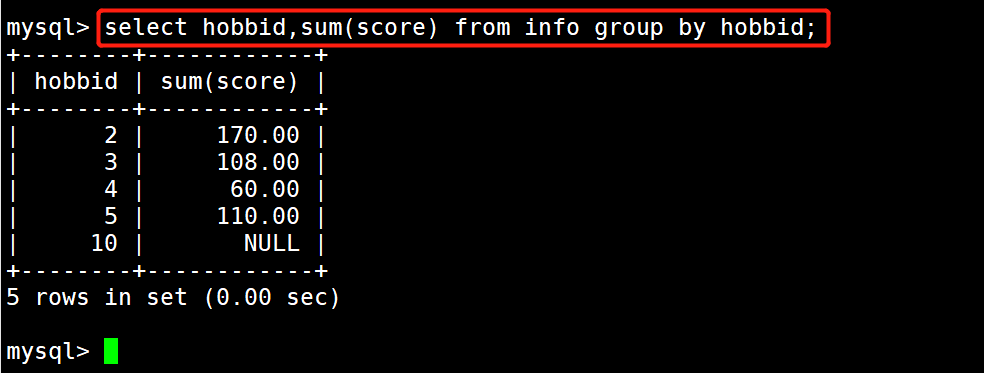
4 #示例1:求不同业余爱好段分数总和
5 select hobbid,sum(score) from info group by hobbid;
1 #示例2:求不同业余爱好个数段平均分数
2 select hobbid,avg(score) from info group by hobbid;
3
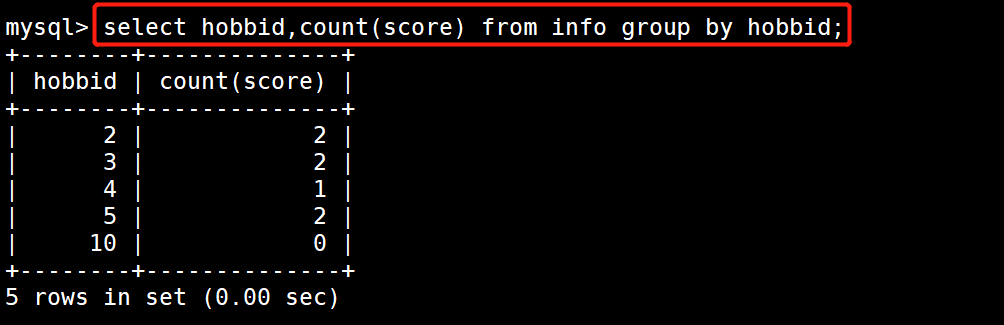
4 #示例3:根据业余爱好查看分数人数
5 select hobbid,count(score) from info group by hobbid;
12.having
-
having:用来过滤由group by语句返回的记录集,通常与group by语句联合使用
-
having语句的存在弥补了where关键字不能与聚合函数联合使用的不足。如果被SELECT的只有函数栏,那就不需要GROUP BY子句。
-
要根据新表中的字段,来指定条件
1 #语法:
2 SELECT 字段1,SUM("字段")FROM 表格名 GROUP BY 字段1 having(函数条件);
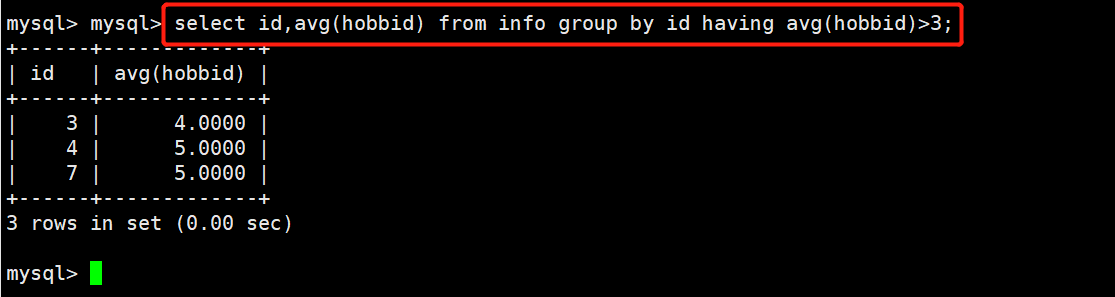
1 #示例:查看平均兴趣爱好在3以上
2 select id,avg(hobbid) from info group by id having avg(hobbid)>3;
13.别名
栏位別名 表格別名
1 v#语法:
2 SELECT "表格別名"."栏位1" [AS] "栏位別名" FROM "表格名" [AS] "表格別名";
3
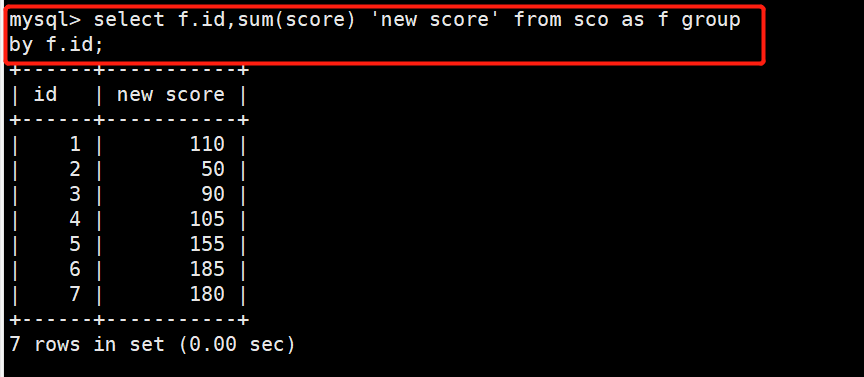
4 #示例:设置表名别名为f,基于id来统计分数总和,sum(score)定义别名为new score
5 select f.id,sum(score) 'new score' from sco as f group by f.id;
14.连接查询
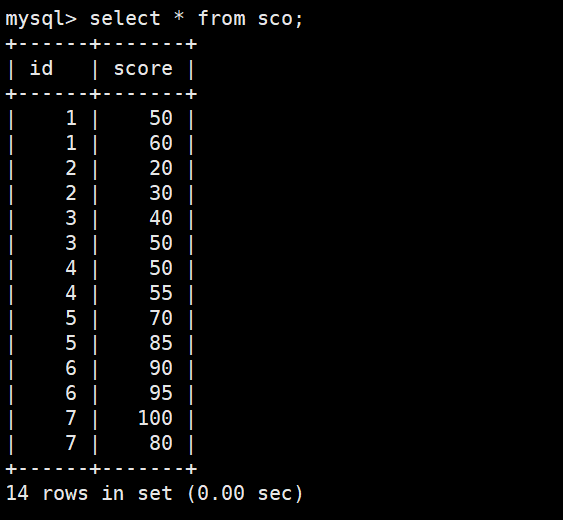
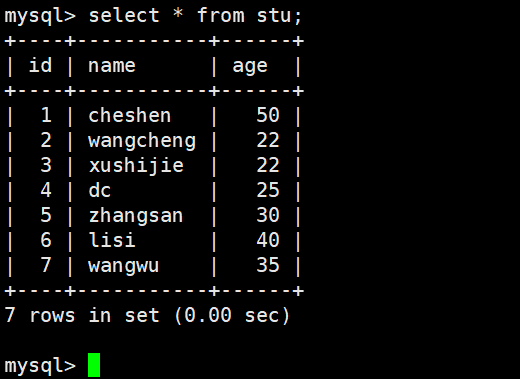
① inner join(等值相连)
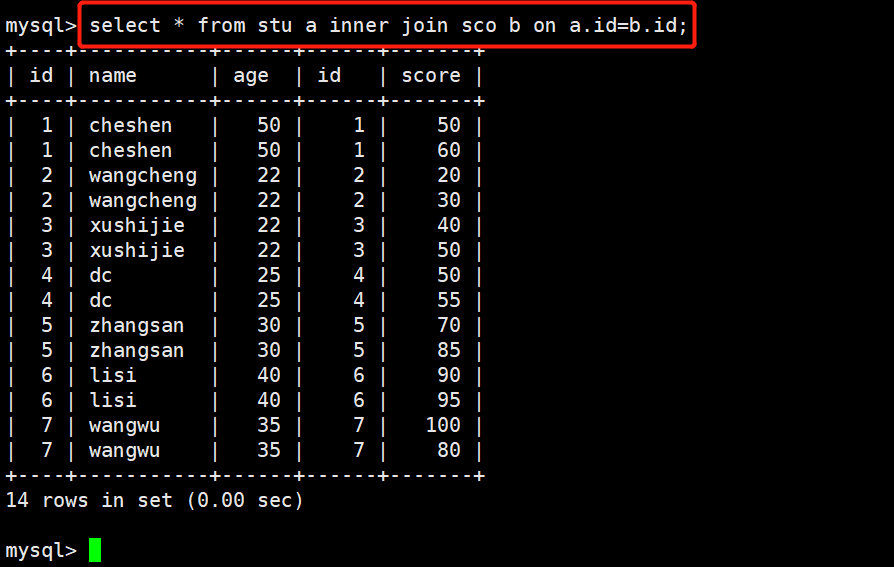
只返回两个表中联结字段相等的行
1 select * from stu a inner join sco b on a.id=b.id;
② left join(左联接)
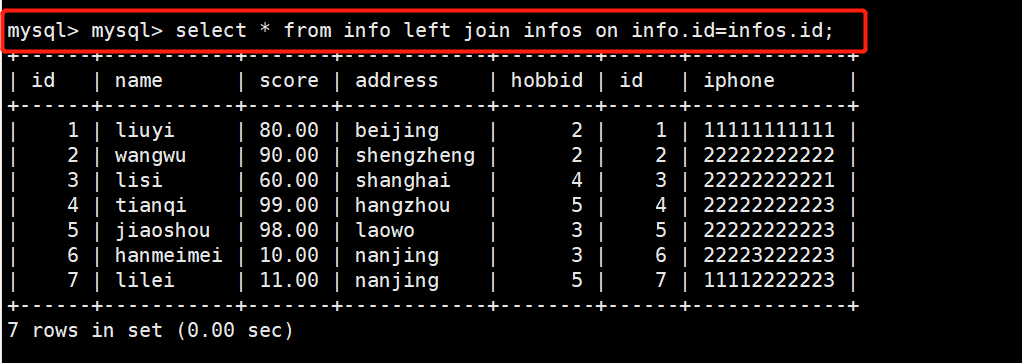
返回包括左表中的所有记录和右表中联结字段相等的记录
1 select * from info left join infos on info.id=infos.id;
③ right join(右联接)
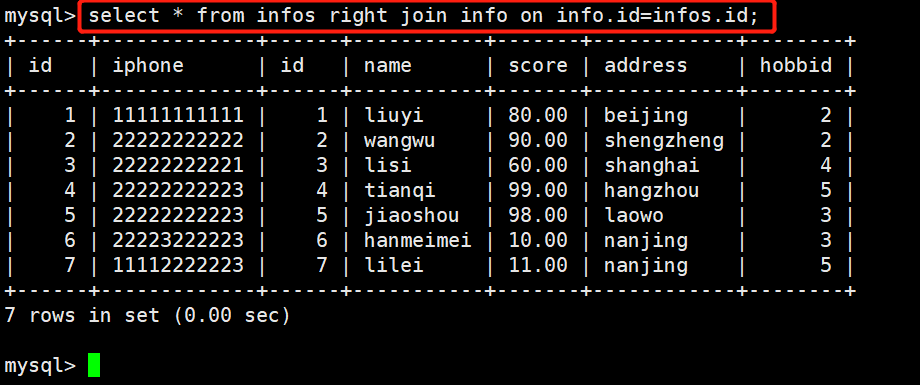
1 select * from infos right join info on info.id=infos.id;
15.子查询
连接表格,在WHERE 子句或HAVING 子句中插入另一个SQL语句
1 语法:
2 SELECT "栏位1" FROM "表格1" WHERE "栏位2" [比较运算符]
3 #外查询
4 (SELECT "栏位1" FROM "表格1" WHERE "条件");
1 #示例:查询两个兴趣爱好的学生得分总和
2 select sum(score) from info where hobbid in (select hobbid from info where hobbid=3);

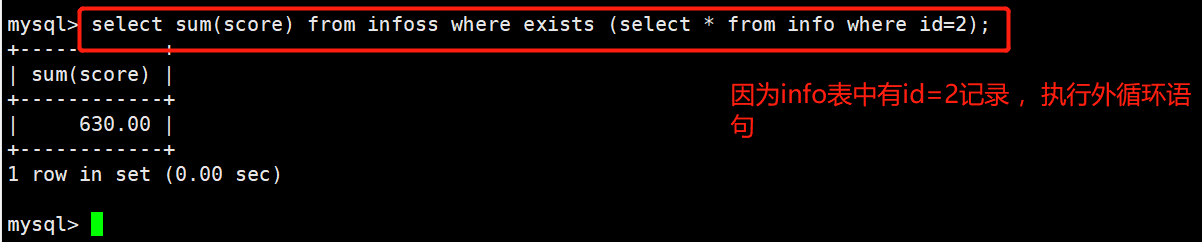
16.EXISTS
-
用来测试内查询有没有产生任何结果类似布尔值是否为真
-
如果有的话,系统就会执行外查询中的SQL语句。若是没有的话,那整个 SQL 语句就不会产生任何结果。
1
2 #语法:
3 SELECT "栏位1" FROM "表格1" WHERE EXISTS (SELECT * FROM "表格2" WHERE "条件");
二、CREATE VIEW(视图)
可以被当作是虚拟表或存储查询
(1)视图跟表格的不同是,表格中有实际储存资料,而视图是建立在表格之上的一个架构,它本身并不实际储存资料。
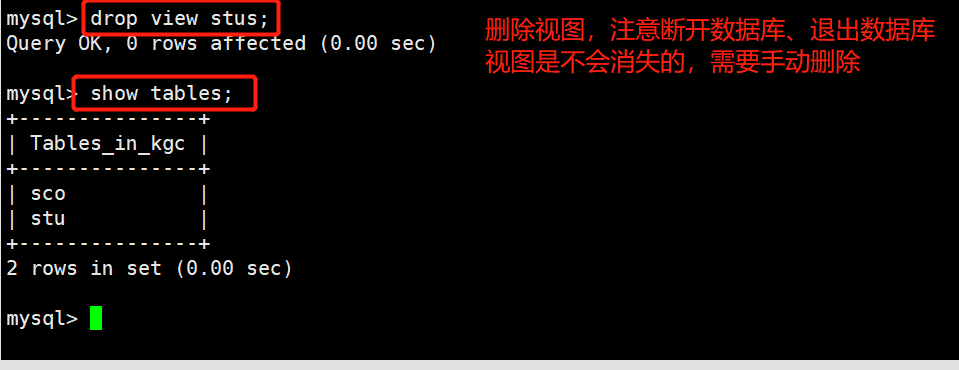
(2)临时表在用户退出或同数据库的连接断开后就自动消失了,而视图不会消失。
(3)视图不含有数据,只存储它的定义,它的用途一般可以简化复杂的查询。比如你要对几个表进行连接查询,而且还要进行统计排序等操作,写SQL语句会很麻烦的,用视图将几个表联结起来,然后对这个视图进行查询操作,就和对一个表查询一样,很方便。
1 #语法:
2 CREATE VIEW "视图表名" AS "SELECT 语句";
3
4 #示例1:创建视图表,表名为stus,数据是跟在as后面的select语句,sco表的别名为a,stu表的别名为b;将a表和b表等值连接,连接字段为id,将a表的score和id列显示到新表中为score和id;将b表中的name,age列显示到新表为name,age
5 create view stus as select a.score score,a.id id,b.name name,b.age age from sco a inner join stu b on a.id=b.id;
6
7 #删除视图
8 drop view stus;
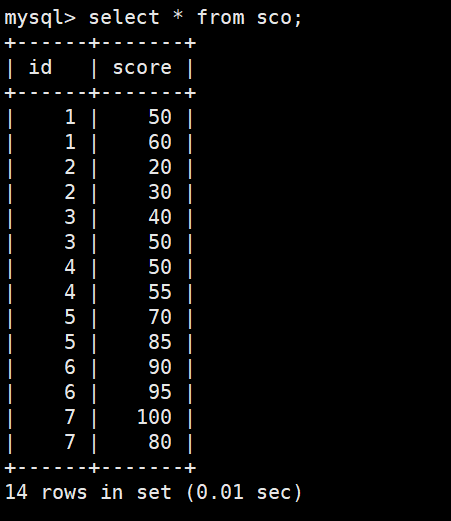

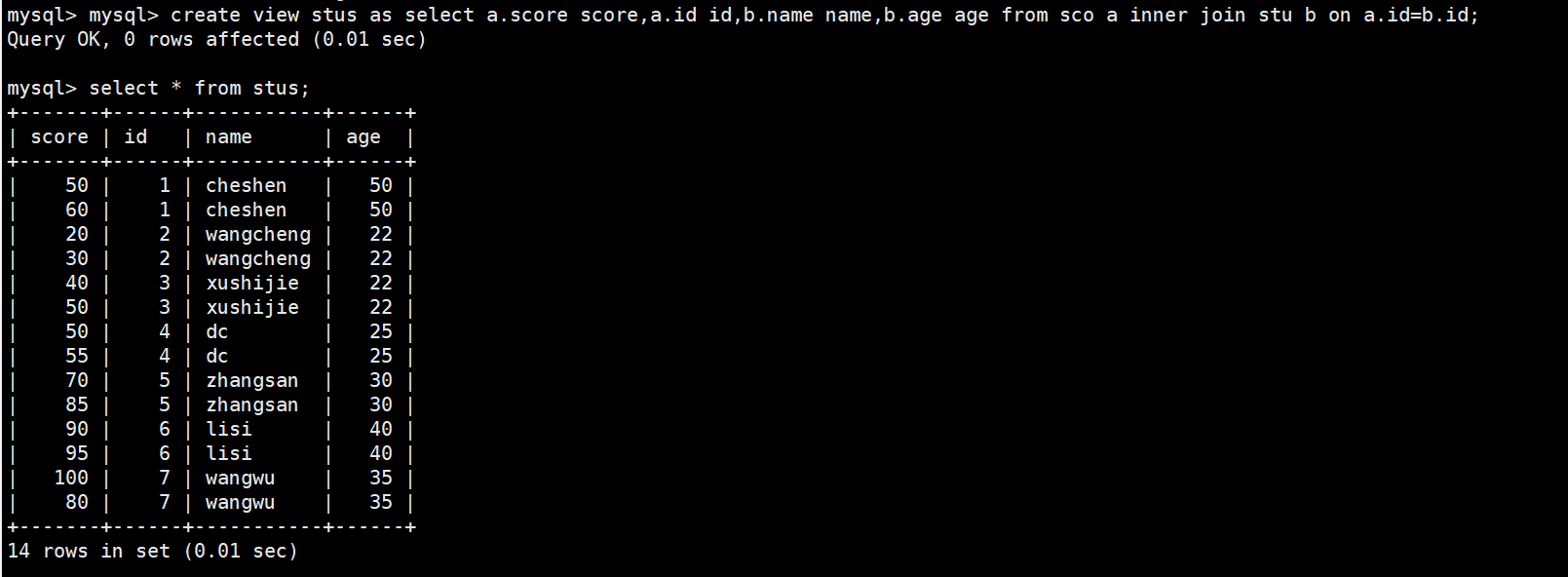
视图能显示出数据。但是视图中不存储数据只能存储它的定义
三、存储过程
-
存储过程是组为了完成特定功能的SQL语句集合。
-
存储过程在使用过程中是将常用或者复杂的工作预先使用SQL语句写好并用一个指定的名称存储起来,这个过程经编译和优化后存储在数据库服务器中。当需要使用该存储过程时,只需要调用它即可。存储过程在执行上比传统SQL速度更快、执行效率更高。
3.1存储过程的优点
①封装性
通常完成一个逻辑功能需要多条 SQL 语句,而且各个语句之间很可能传递参数,所以,编写逻辑功能相对来说稍微复杂些,而存储过程可以把这些 SQL 语句包含到一个独立的单元中,使外界看不到复杂的 SQL 语句,只需要简单调用即可达到目的。并且数据库专业人员可以随时对存储过程进行修改,而不会影响到调用它的应用程序源代码
②可增强 SQL 语句的功能和灵活性
存储过程可以用流程控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
③可减少网络流量
由于存储过程是在服务器端运行的,且执行速度快,因此当客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而可降低网络负载。
④提高性能
当存储过程被成功编译后,就存储在数据库服务器里了,以后客户端可以直接调用,这样所有的 SQL 语句将从服务器执行,从而提高性能。但需要说明的是,存储过程不是越多越好,过多的使用存储过程反而影响系统性能
⑤提高数据库的安全性和数据的完整性
存储过程提高安全性的一个方案就是把它作为中间组件,存储过程里可以对某些表做相关操作,然后存储过程作为接口提供给外部程序。这样,外部程序无法直接操作数据库表,只能通过存储过程来操作对应的表,因此在一定程度上,安全性是可以得到提高的。
⑥使数据独立
数据的独立可以达到解耦的效果,也就是说,程序可以调用存储过程,来替代执行多条的 SQL 语句。这种情况下,存储过程把数据同用户隔离开来,优点就是当数据表的结构改变时,调用表不用修改程序,只需要数据库管理者重新编写存储过程即可。
3.2创建、调用和查看存储的过程
3.2.1创建存储过程
1 #语法:
2 CREATE PROCEDURE <存储过程名> ( [过程参数[,…] ] ) <过程体>
3 [过程参数[,…] ] 格式
4 <过程名>:尽量避免与内置的函数或字段重名
5 <过程体>:语句
6 [ IN | OUT | INOUT ] <参数名><类型>
①过程名 存储过程的名称,默认在当前数据库中创建。若需要在特定数据库中创建存储过程,则要在名称前面加上数据库的名称,即 db_name.sp_name。 需要注意的是,名称应当尽量避免选取与 MySQL 内置函数相同的名称,否则会发生错误。
② 过程参数 存储过程的参数列表。其中,<参数名>为参数名,<类型>为参数的类型(可以是任何有效的 MySQL 数据类型)。当有多个参数时,参数列表中彼此间用逗号分隔。存储过程可以没有参数(此时存储过程的名称后仍需加上一对括号),也可以有 1 个或多个参数。 MySQL 存储过程支持三种类型的参数,即输入参数、输出参数和输入/输出参数,分别用 IN、OUT 和 INOUT 三个关键字标识。其中,输入参数可以传递给一个存储过程,输出参数用于存储过程需要返回一个操作结果的情形,而输入/输出参数既可以充当输入参数也可以充当输出参数。
③ 过程体 存储过程的主体部分,也称为存储过程体,包含在过程调用的时候必须执行的 SQL 语句。这个部分以关键字 BEGIN 开始,以关键字 END 结束 在 MySQL 中,服务器处理 SQL 语句默认是以分号作为语句结束标志的。然而,在创建存储过程时,存储过程体可能包含有多条 SQL 语句,这些 SQL 语句如果仍以分号作为语句结束符,那么 MySQL 服务器在处理时会以遇到的第一条 SQL 语句结尾处的分号作为整个程序的结束符,而不再去处理存储过程体中后面的 SQL 语句,这样显然不行。
为解决以上问题,通常使用 DELIMITER 命令将结束命令修改为其他字符。语法格式如下: delimiter $ $
1 语法说明如下:
2 $$ 是用户定义的结束符,通常这个符号可以是一些特殊的符号,如两个“?”或两个“¥”等。
3 当使用 DELIMITER 命令时,应该避免使用反斜杠“\”字符,因为它是 MySQL 的转义字符
4
5 成功执行这条 SQL 语句后,任何命令、语句或程序的结束标志就换为两个??
6 mysql > DELIMITER ??
7 若希望换回默认的分号“;”作为结束标志,则在 MySQL 命令行客户端输入下列语句即可
8 mysql > DELIMITER ;
9 注意:DELIMITER 和分号“;”之间一定要有一个空格
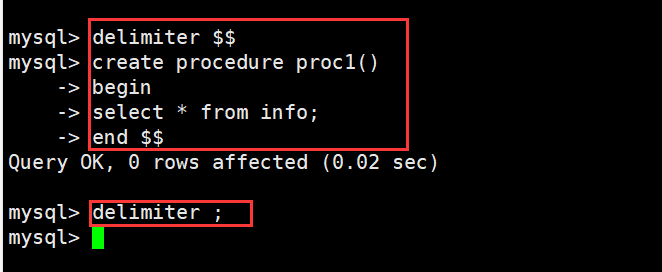
1 delimiter $$ #将语句的结束符号从分号;临时改为两个$$ (可以是自定义)
2 create procedure proc1() #创建存储过程,过程名为proc, 不带参数
3 -> begin #过程体以关键字BEGIN开始
4 -> select * from info; #过程体语句(自己根据需求进行编写)
5 -> end $$ #过程体以关键字END结束
6 delimiter ; #将语句的结束符号恢复为分号
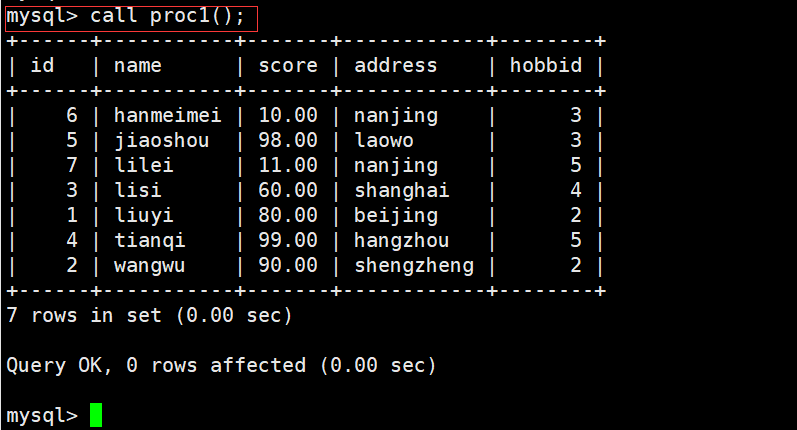
3.2.2调用存储过程
1 #语法
2 call 过程名
3
4 #示例:
5 call proc1
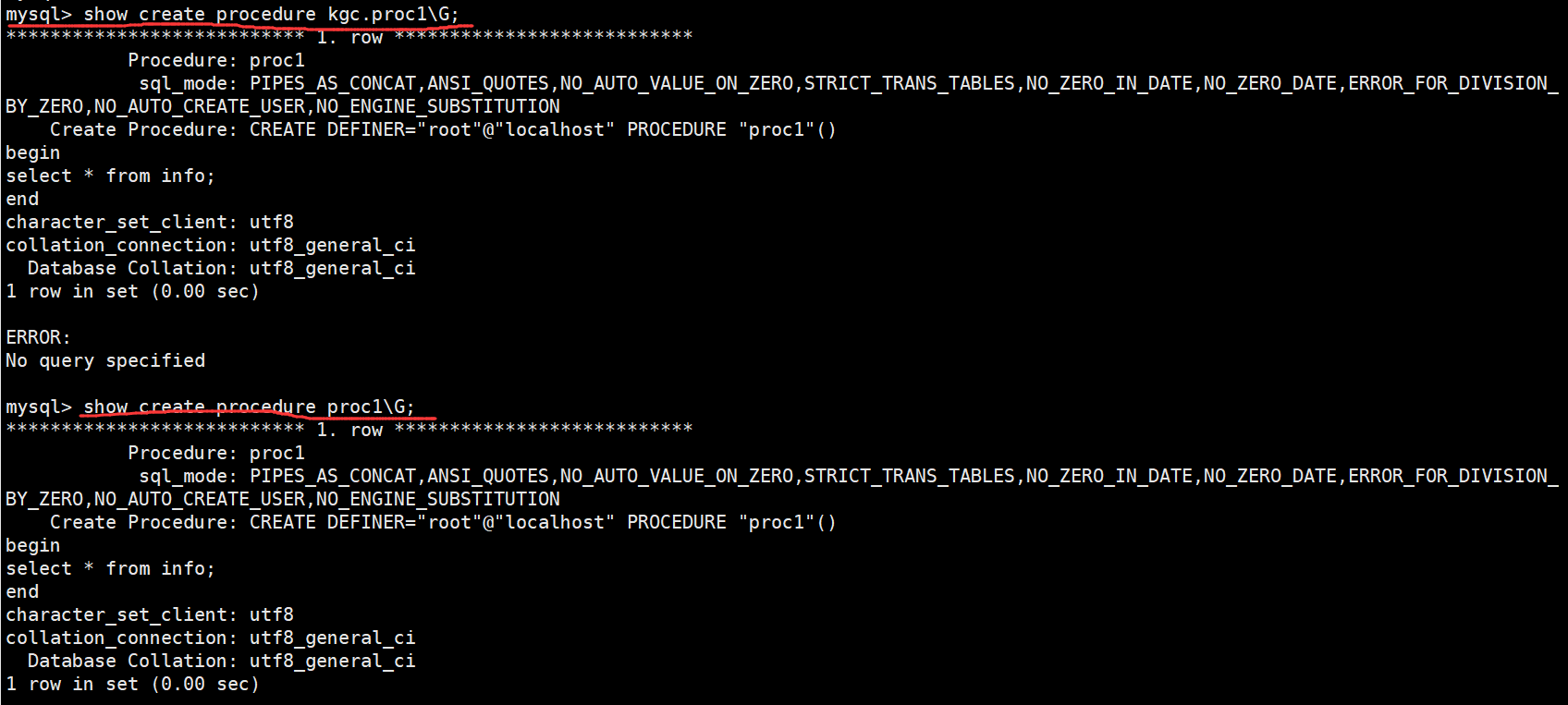
3.2.3查看存储过程
1 #查看某个存储过程的具体信息(如果在指定库中,库名可以省略)
2 SHOW CREATE PROCEDURE [数据库.] 存储过程名;
3 ##示例1:
4 show create procedure kgc.proc1\G;
5
6 ##示例2:
7 show create procedure proc1\G;
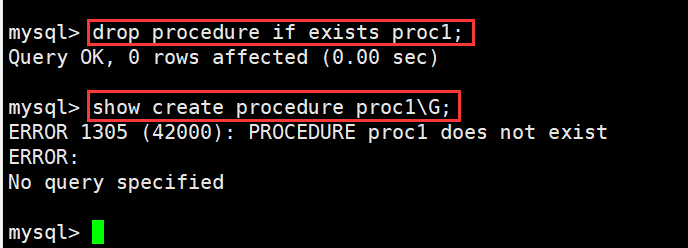
3.2.4删除存储过程
1 #语法
2 DROP PROCEDURE IF EXISTS 过程名;
3
4 #示例:
5 drop procedure if exists proc1;
3.3存储过程的参数
-
IN输入参数: 表示调用者向过程传入值(传入值可以是字面量或变量)
-
OUT输出参数: 表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
-
INOUT输入输出参数: 既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
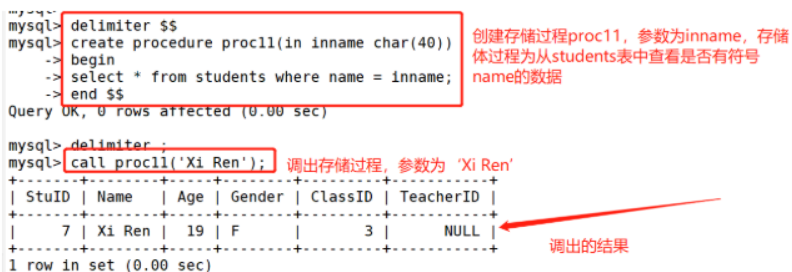
#示例:
delimiter $$
create procedure proc11(in inname char(40))
-> begin
-> select * from students where name = inname;
-> end $$
mysql> delimiter ;
call proc11('Xi Ren');


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律