34、Scrapy 知识总结
Scrapy 知识总结
1、安装
1 pip install wheel 2 pip install https://download.lfd.uci.edu/pythonlibs/q5gtlas7/Twisted-19.2.0-cp37-cp37m-win_amd64.whl 3 pip install scrapy 4 5 ps: 因为twisted是whl包,所以需要先安装whl包对应的工具 wheel;第二步安装 Twisted方法,在https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 页面找到对应自己操作系统位数和python版本的whl文件
2、创建 Scrapy 项目
scrapy startproject douban
创建好的项目目录如下
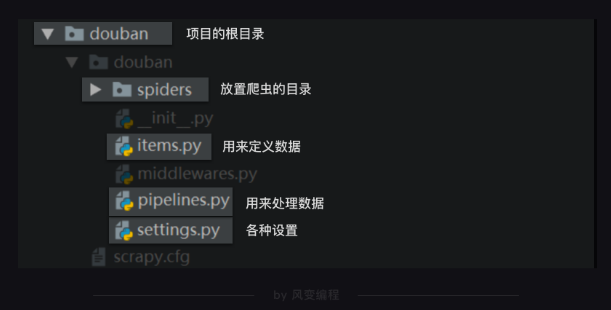
3、在 douban - douban - spiders 目录中创建爬虫文件 top250.py
1 import scrapy 2 import bs4 3 from ..items import DoubanItem 4 5 class DoubanSpider(scrapy.Spider): 6 name = 'douban' 7 allowed_domains = ['https://book.douban.com'] 8 start_urls = [] 9 for x in range(3): 10 url = 'https://book.douban.com/top250?start=' + str(x * 25) 11 start_urls.append(url) 12 13 def parse(self,response): 14 bs = bs4.BeautifulSoup(response.text,'html.parser') 15 datas = bs.find_all('tr',class_='item') 16 for data in datas: 17 item = DoubanItem() 18 item['title'] = data.find_all('a')[1]['title'] 19 item['publish'] = data.find('p',class_='pl').text 20 item['score'] = data.find('span',class_='rating_nums').text 21 #print(item['title']) 22 yield item
4、编辑 douban - douban - items.py
1 import scrapy 2 3 class DoubanItem(scrapy.Item): 4 title = scrapy.Field() 5 publish = scrapy.Field() 6 score = scrapy.Field()
5、编辑 douban - douban - settings.py
1 BOT_NAME = 'douban' 2 SPIDER_MODULES = ['douban.spiders'] 3 NEWSPIDER_MODULE = 'douban.spiders' 4 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' 5 ROBOTSTXT_OBEY = False
6、在 douban 目录下执行 scrapy crawl douban ,或者在豆瓣目录下创建main.py,然后执行 main.py
1 from scrapy import cmdline 2 #导入cmdline模块,可以实现控制终端命令行。 3 cmdline.execute(['scrapy','crawl','douban']) 4 #用execute()方法,输入运行scrapy的命令。




Scrapy 保存结果到csv , 只需在 settings.py 文件中添加下面三行
1 FEED_URI='./storage/data/%(name)s.csv' 2 FEED_FORMAT='CSV' 3 FEED_EXPORT_ENCODING='utf-8-sig'
保存到与 settings.py 同目录下的storage目录下的data目录下,文件名是该项目名字.csv
Scrapy 保存结果到excel, 只需在 settings.py 文件中添加下面三行
1 ITEM_PIPELINES = { 2 'jobuitest.pipelines.JobuitestPipeline': 300, 3 }
然后编辑 pipelines.py
1 import openpyxl 2 3 class JobuiPipeline(object): 4 #定义一个JobuiPipeline类,负责处理item 5 def __init__(self): 6 #初始化函数 当类实例化时这个方法会自启动 7 self.wb =openpyxl.Workbook() 8 #创建工作薄 9 self.ws = self.wb.active 10 #定位活动表 11 self.ws.append(['公司', '职位', '地址', '招聘信息']) 12 #用append函数往表格添加表头 13 14 def process_item(self, item, spider): 15 #process_item是默认的处理item的方法,就像parse是默认处理response的方法 16 line = [item['company'], item['position'], item['address'], item['detail']] 17 #把公司名称、职位名称、工作地点和招聘要求都写成列表的形式,赋值给line 18 self.ws.append(line) 19 #用append函数把公司名称、职位名称、工作地点和招聘要求的数据都添加进表格 20 return item 21 #将item丢回给引擎,如果后面还有这个item需要经过的itempipeline,引擎会自己调度 22 23 def close_spider(self, spider): 24 #close_spider是当爬虫结束运行时,这个方法就会执行 25 self.wb.save('./jobui.xlsx') 26 #保存文件 27 self.wb.close() 28 #关闭文件
Scrapy 设置 下载延时 编辑settings.py 文件 ,默认没有延时,单位秒
1 DOWNLOAD_DELAY = 3
Scrapy 未解之谜
1、自带解析器怎么用
2、如何带参数请求数据
3、如何写入cookies
4、如何发送邮件
5、如何与 selenium联动
6、如何完成超厉害的分布式爬虫
Scrapy 核心代码,callback
1 #导入模块: 2 import scrapy 3 import bs4 4 from ..items import JobuiItem 5 6 7 class JobuiSpider(scrapy.Spider): 8 name = 'jobs' 9 allowed_domains = ['www.jobui.com'] 10 start_urls = ['https://www.jobui.com/rank/company/'] 11 12 #提取公司id标识和构造公司招聘信息的网址: 13 def parse(self, response): 14 #parse是默认处理response的方法 15 bs = bs4.BeautifulSoup(response.text, 'html.parser') 16 ul_list = bs.find_all('ul',class_="textList flsty cfix") 17 for ul in ul_list: 18 a_list = ul.find_all('a') 19 for a in a_list: 20 company_id = a['href'] 21 url = 'https://www.jobui.com{id}jobs' 22 real_url = url.format(id=company_id) 23 yield scrapy.Request(real_url, callback=self.parse_job) 24 #用yield语句把构造好的request对象传递给引擎。用scrapy.Request构造request对象。callback参数设置调用parsejob方法。 25 26 27 def parse_job(self, response): 28 #定义新的处理response的方法parse_job(方法的名字可以自己起) 29 bs = bs4.BeautifulSoup(response.text, 'html.parser') 30 #用BeautifulSoup解析response(公司招聘信息的网页源代码) 31 company = bs.find(id="companyH1").text 32 #用fin方法提取出公司名称 33 datas = bs.find_all('li',class_="company-job-list") 34 #用find_all提取<li class_="company-job-list">标签,里面含有招聘信息的数据 35 for data in datas: 36 #遍历datas 37 item = JobuiItem() 38 #实例化JobuiItem这个类 39 item['company'] = company 40 #把公司名称放回JobuiItem类的company属性里 41 item['position']=data.find('h3').find('a').text 42 #提取出职位名称,并把这个数据放回JobuiItem类的position属性里 43 item['address'] = data.find('span',class_="col80").text 44 #提取出工作地点,并把这个数据放回JobuiItem类的address属性里 45 item['detail'] = data.find('span',class_="col150").text 46 #提取出招聘要求,并把这个数据放回JobuiItem类的detail属性里 47 yield item 48 #用yield语句把item传递给引擎


 浙公网安备 33010602011771号
浙公网安备 33010602011771号