
使用tensorflow2.0完成对notMNIST数据集的识别学习
tensorflow2.0 利用卷积神经网络对notMNIST数据集的识别
0.背景
工作的目标是对notMNIST数据集的识别,这是这个学期选修的神经网络课的期末大作业。notMNIST数据集与MNIST数据集相似,包含了590000+个28*28大小的A-J字符的灰度图像。因为做大作业的时候也正值tensorflow2.0正式版发布不久,因此使用了2.0版的tensorflow完成的。个人水平有限,最终只是初步的完成了对notMNIST_small数据集的训练与识别,经过20000轮训练,最终正确率0.98.
1.环境
在编程环境上,使用了anaconda配置了python3.7+tensorflow2.0的环境。
2.实现
2.1思路
由于之前对神经网络的框架包括tensorflow、pytorch都不熟悉,我首先找了关于tnsorflow2.0的相关资料,其中对我帮助最大的是简单粗暴tensorflow2.0.最终实现对notMNIST的网络架构就是此教程里的例程。可以说,作为一个初次接触神经网络实现的人而言,tensorflow2.0表现出的代码是很优雅的,比其他地方看到的tensorflow1.x的源码干净许多,但是相应的,网络上能直接使用的资料也少了很多。
言归正传,搭建好环境后,我利用教程里的MNIST进行了测试,能实现对MNIST的识别,效果与预期相当,并且代码可读性很好。希望能在教程的基础上对代码进行改写完成任务。现贴出MNIST的例程:
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import datasets
import os
class MNISTLoader():
def __init__(self):
mnist = tf.keras.datasets.mnist
(self.train_data,self.train_lable),(self.test_data,self.test_lable)=mnist.load_data()
self.train_data = np.expand_dims(self.train_data.astype(np.float32)/255.0,axis=-1)
self.test_data = np.expand_dims(self.test_data.astype(np.float32)/255.0,axis=-1)
self.train_lable=self.train_lable.astype(np.int32)
self.test_lable=self.test_lable.astype(np.int32)
self.num_train_data,self.num_test_data=self.train_data.shape[0],self.test_data.shape[0]
def get_batch(self,batch_size):
index=np.random.randint(0,np.shape(self.train_data)[0],batch_size)
return self.train_data[index,:],self.train_lable[index]
class MLP(tf.keras.Model):
def __init__(self):
super().__init__()
self.flatten = tf.keras.layers.Flatten()
self.dense1 = tf.keras.layers.Dense(units=100,activation = tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self,inputs):
x = self.flatten(inputs)
x = self.dense1(x)
x = self.dense2(x)
output = tf.nn.softmax(x)
return output
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32,
kernel_size = [5,5],
padding = 'same',
activation = tf.nn.relu
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size = [2,2],strides = 2)
self.conv2 = tf.keras.layers.Conv2D(
filters=64,
kernel_size = [5,5],
padding = 'same',
activation = tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size = [2,2],strides = 2)
self.flatten = tf.keras.layers.Reshape(target_shape=(7*7*64,))
self.dense1 = tf.keras.layers.Dense(units = 1024,activation = tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units = 10)
def call(self,inputs):
x = self.conv1(inputs)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.flatten(x)
x = self.dense1(x)
x = self.dense2(x)
output = tf.nn.softmax(x)
return output
num_epochs = 5
batch_size = 50
learning_rate = 0.001
#model = MLP()
model = MLP()
data_loader = MNISTLoader()
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
summary_writer = tf.summary.create_file_writer('./tensorboard')
num_batches = int(data_loader.num_train_data//batch_size*num_epochs)
for batch_index in range(100):
X,y = data_loader.get_batch(batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true = y,y_pred = y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f"%(batch_index,loss.numpy()))
with summary_writer.as_default(): # 指定记录器
tf.summary.scalar("loss", loss, step=batch_index) # 将当前损失函数的值写入记录器
grads = tape.gradient(loss,model.variables)
optimizer.apply_gradients(grads_and_vars = zip(grads,model.variables))
sparse_categorical_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
num_batches = int(data_loader.num_test_data//batch_size)
for batch_index in range(num_batches):
start_index,end_index = batch_index*batch_size,(batch_index + 1)*batch_size
y_pred = model.predict(data_loader.test_data[start_index:end_index])
sparse_categorical_accuracy.update_state(y_true = data_loader.test_lable[start_index:end_index],y_pred = y_pred)
print ("test accuracy : %f"%sparse_categorical_accuracy.result())
#model.save('1.tf')
2.2问题与解决
在过程中,我遇到的最大困难是对数据集的读取。在例程以及其他网络资料中,总爱以MNIST这种已经内置读取方式的数据集为例,但在对这种没有内置读取方法的数据集操作时,很大程度需要一些编程的能力,这也是最困扰我的地方。将notMNIST数据集解压后会得到10个文件夹,每个文件夹的名字就是其标签。一般而言,tensorflow读取数据集在小批量的时候可以将所有图片一次读入内存,但在大批量的时候一般使用从硬盘读取,tensorflow推荐使用tfrecord格式完成,但在2.0版本我屡次也没成功使用,最终还是用了读入内存的形式。对数据的处理主要参考了kaggle,贴上最终的源码:
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 9 19:41:27 2019
@author: 腾飞
"""
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import os
dir_ = 'E:/tfrecord/notMNIST_small/'
letters = os.listdir(dir_)
# Retrieve pictures files names
pictures_files = {}
for letter in letters:
images = [name for name in os.listdir(dir_ + '%s/' % letter) if name[-4:] == '.png']
pictures_files[letter] = images
# Get the actual pictures
data = {}
for letter in letters:
print('---------------------------')
print('Retrieving for %s' % letter)
print('---------------------------')
images = []
for name in pictures_files[letter]:
try:
images.append(plt.imread(dir_+'{}/{}'.format(letter, name)))
except Exception as e:
print(e, name)
data[letter] = images
print('Done')
from sklearn.preprocessing import LabelEncoder
# Merge all data to one list
X = []
Y = []
X_nd = np.zeros(shape=(18724, 28, 28))
Y_nd = np.zeros(shape=(18724))
for key, list_ in data.items():
for img in list_:
X.append(img)
Y.append(key)
for i in range(len(X)):
X_nd[i, :, :] = X[i]
lbl_enc = LabelEncoder()
labels = np.array(['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'])
lbl_enc.fit(labels)
Y = lbl_enc.transform(Y)
#Y_nd = keras.utils.np_utils.to_categorical(Y, num_classes=10)
Y_nd =Y
X_nd = np.expand_dims(X, -1).astype('float32')/255.0
from sklearn.model_selection import train_test_split
X_train, X_dev, Y_train, Y_dev = train_test_split(X_nd, Y_nd, test_size=.2)
X_train, X_test, Y_train, Y_test = train_test_split(X_train, Y_train, test_size=.1)
print('Training size: %s' % len(X_train))
print('DevSet size: %s' % len(X_dev))
print('TestSet size: %s' % (len(X_test)))
len(X_train) == len(Y_train)
print(Y_train.shape)
print(X_train.shape)
def get_batch(batch_size):
index=np.random.randint(0,np.shape(X_train)[0],batch_size)
return X_train[index,:],Y_train[index]
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32,
kernel_size = [5,5],
padding = 'same',
activation = tf.nn.relu
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size = [2,2],strides = 2)
self.conv2 = tf.keras.layers.Conv2D(
filters=64,
kernel_size = [5,5],
padding = 'same',
activation = tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size = [2,2],strides = 2)
self.flatten = tf.keras.layers.Reshape(target_shape=(7*7*64,))
self.dense1 = tf.keras.layers.Dense(units = 1024,activation = tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units = 10)
def call(self,inputs):
x = self.conv1(inputs)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.flatten(x)
x = self.dense1(x)
x = self.dense2(x)
output = tf.nn.softmax(x)
return output
num_epochs = 5
batch_size = 50
learning_rate = 0.001
#model = MLP()
model = CNN()
#data_loader = notMNISTLoader()
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
summary_writer = tf.summary.create_file_writer('./tensorboard')
checkpoint = tf.train.Checkpoint(myAwesomeModel=model)
#num_batches = int(Y_train[0]//batch_size*num_epochs)
for batch_index in range(20000):
X,y = get_batch(batch_size)
with tf.GradientTape() as tape:
y_pred = model(X)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_true = y,y_pred = y_pred)
loss = tf.reduce_mean(loss)
print("batch %d: loss %f"%(batch_index,loss.numpy()))
with summary_writer.as_default(): # 指定记录器
tf.summary.scalar("loss", loss, step=batch_index) # 将当前损失函数的值写入记录器
grads = tape.gradient(loss,model.variables)
optimizer.apply_gradients(grads_and_vars = zip(grads,model.variables))
if batch_index%1000==0:
path = checkpoint.save('./save/ctf_model_v.ckpt')
print("model saved to %s"%path)
#model.save('1.tf')
另外,写了一小段程序对模型进行评估,我在用的时候是单独写了个test程序,主要代码有:
model_to_be_restored = CNN()
#data_loader = notMNISTLoader()
checkpoint = tf.train.Checkpoint(myAwesomeModel=model_to_be_restored )
checkpoint.restore(tf.train.latest_checkpoint('./save'))
y_pred =np.argmax(model_to_be_restored.predict(X_test),axis=-1)
#print("test accuracy:%f"%(sum(y_pred==Y_test)/Y_test[0]))
#num_batches = int(Y_train[0]//batch_size*num_epochs)
i=0
right=0
dim = Y_test.shape[0]
for i in range(dim):
if Y_test[i]==y_pred[i]:
right = right+1
i=i+1
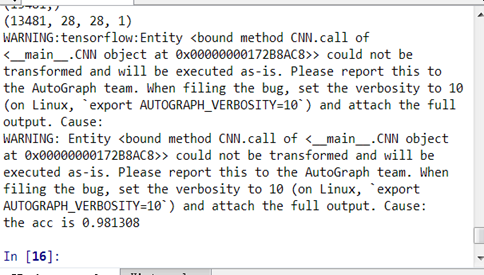
print("the acc is %f"%(right/dim))
3另附一些图
3.1数据集解压出的样子
3.2数据集图片详情
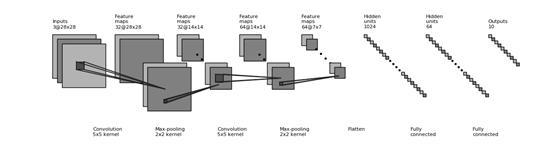
3.3网络结构示意
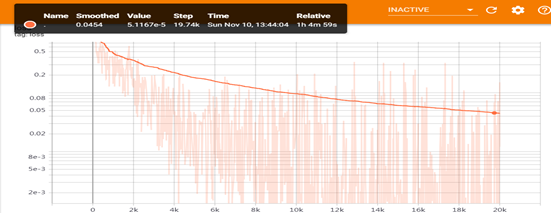
3.4loss下降过程
3.5测试正确率
4.一些说明
这个程序只是我一个选修课的大作业,做的其实很粗糙,包括由于读取数据集的方式和手里的条件导致最终只是使用notMNIST_small数据集完成了训练和测试,但这个整段代码结构是很简单也很易读的,希望也能提供一些参考。就我对tensorflow2.0的使用体验而言,tf2.0是很友好的,如果不考虑数据集的处理问题,那我这次实验还是很顺利的,如果后续对这个方向还有深入的学习,我会更新这部分内容。
