CSAPP第六章概念
CSAPP第六章概念
1.时间局部性:程序有在一段时间多次访问同一数据块的倾向
空间局部性:程序往往有访问一个聚集空间数据块的倾向
空间局部性的例子:我们可以选择在读取内存块的时候,把它附近的内存块也读进来(prefetch)
2.B KB MB
1GB=1024MB=1024*1024KB=1024*1024*1024B
3.Tmax rotation=1/旋转速率RPM*60s/min*1000ms
Tavg rotation=1/2*Tmax rotation
Tavg transfer=1/旋转速率RPM*60s/min*1000ms*1/(平均扇区数/磁道)
4.逻辑块数=文件大小/每个逻辑块大小
随机情况Taccess =逻辑块数*(Tavg seek+Tavg rotation)
最好情况 Taccess =(Tavg seek+Tavg rotation)+(文件大小/(扇区大小*(平均扇区数/磁道))*Tmax rotation
5.练习题6.8类似结构体中数组的存储
p[0].vel[3] 0 4 8
p[0].acc[3] 12 16 20
P[1].vel[3] 24 28 32
循环体越小,循环迭代次数越多,局部性越好
6.缓存不命中
当tag和valid校验成功是,我们称为cache命中,这时只要将cache中的单元取出,放入CPU寄存器中即可。
当tag或valid校验失败的时候,就说明要访问的内存单元(也可能是连续的一些单元不在缓存中,这时就需要去内存中取了,出现miss.
Cold miss the cache starts empty
Conflict miss 一些对象会映射到同一缓存块
Capacity miss 缓存太小,不能处理整个工作集
工作集( working set)一个特定时间段内,一个进程所需要的内存
7.cache address 由t位tag,s位set index和b 位block offset组成
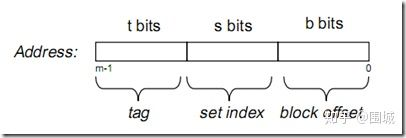
中间的位来做索引的原因
如果高位做索引,一些连续的内存块就会映射到相同的高速缓存块。顺序扫描一个数组时,cache在任何时候都只保存一个块的大小的数组内容。
由于空间局部性原理(程序往往有访问一个聚集空间内存块的倾向)相邻的块之间conflict miss的可能性较高。
如果用中间位做索引,相邻的块总是会映射到不同的高速缓存行,使用效率大大提高,此时高速缓存能够存放整个数组片。
用中间位做索引可以尽量减少conflict miss.
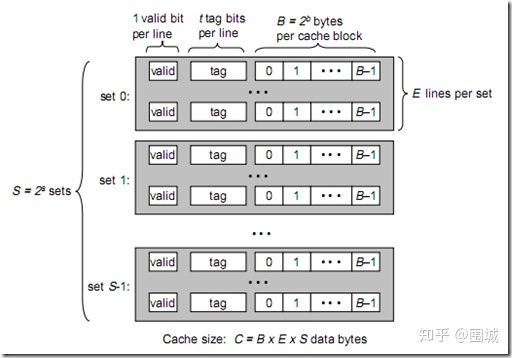
8.C=B*E*S
S--组数
E--每组的行数(cache line)
B--块大小
m--物理地址位数
t=m-(s+b)
s=log2(S)
9.计算机存储体系简介(摘自知乎)
离CPU越近的存储器,速度越快,每字节的成本越高,同时容量也因此越小。
存储器分级,利用的是局部性原理。我们可以以经典的阅读书籍为例。我在读的书,捧在手里(寄存器),我最近频繁阅读的书,放在书桌上(缓存),随时取来读。当然书桌上只能放有限几本书。我更多的书在书架上(内存)。如果书架上没有的书,就去图书馆(磁盘)。我要读的书如果手里没有,那么去书桌上找,如果书桌上没有,去书架上找,如果书架上没有去图书馆去找。可以对应寄存器没有,则从缓存中取,缓存中没有,则从内存中取到缓存,如果内存中没有,则先从磁盘读入内存,再读入缓存,再读入寄存器。
10.cache概述
第一次访问某区域是,就将其复制到cache中,以后访问该区域的指令或者数据时,就不再从主存中取出了。
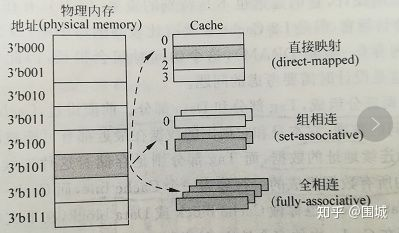
1)direct-mapped cache
每个组只有一个line E=1
2) Set associative cache
S个组,每个组E个line 1<E<C/B
替换策略 LFU 把频次最低的淘汰
LRU 把访问时间最久远的淘汰
LRU,最近最少使用,把数据加入一个链表中,按访问时间排序,发生淘汰的时候,把访问时间最旧的淘汰掉。
比如有数据 1,2,1,3,2
此时缓存中已有(1,2)
当3加入的时候,得把后面的2淘汰,变成(3,1)
LFU,最近不经常使用,把数据加入到链表中,按频次排序,一个数据被访问过,把它的频次+1,发生淘汰的时候,把频次低的淘汰掉。
比如有数据 1,1,1,2,2,3
缓存中有(1(3次),2(2次))
当3加入的时候,得把后面的2淘汰,变成(1(3次),3(1次))
区别:LRU 是得把 1 淘汰。
显然
LRU对于循环出现的数据,缓存命中不高
比如,这样的数据,1,1,1,2,2,2,3,4,1,1,1,2,2,2.....
当走到3,4的时候,1,2会被淘汰掉,但是后面还有很多1,2
LFU对于交替出现的数据,缓存命中不高
比如,1,1,1,2,2,3,4,3,4,3,4,3,4,3,4,3,4......
由于前面被(1(3次),2(2次))
3加入把2淘汰,4加入把3淘汰,3加入把4淘汰,然而3,4才是最需要缓存的,1去到了3次,谁也淘汰不了它了。
来源:简书
3) Fully associative cache
由一个包含所有高速缓存行的组组成 不用hash判断在哪个组中,在该组中挨个查找 E=C/B
11.关于写的问题
write through :write immediately to memory
write back:defer write memory until replacement of line
use a dirty bit to set if data defers from memory
1)WB(write back)+WA(write allocation)

2)WT(write through )+WN(write no allocation)

http://en.wikipedia.org/wiki/Cache_(computing)
3)Write allocate: data at the missed-write location is loaded to cache, followed by a write-hit operation. In this approach, write misses are similar to read misses.
4)No-write allocate : data at the missed-write location is not loaded to cache, and is written directly to the backing store. In this approach, data is loaded into the cache on read misses only.
write-back cache uses write allocate,
write-through cache uses no-write allocate.
12.

E=8
B=64
C=32*1024
S=64
t=m(47)-(s+b)=47-6-6=35
13.cache performance
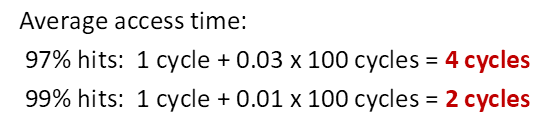
miss 也要访问一次cache 故1cycle+...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号