G1:记忆集、位图、卡表、DCQ
记忆集--RSet
RSet:Remember Set
我们知道JVM使用的垃圾回收的算法,其中是包括标记算法,标记出来需要回收的对象,和存活对象,然后进行垃圾回收,根对象(gc roots)可达性分析算法。即从根对象(gc roots)出发,标记所有存活对象,然后遍历对象的每一个字段,继续标记,直到所有的对象标记完毕。 要么是存活对象,要么是垃圾对象需要被回收。
而分代模型的JVM GC中,老年代和新生代的回收,一般都是不同的,新生代一般都是先触发,实在是无法腾出足够的空间,才会进入老年代GC,或者是full gc。在G1中,其实也差不多。先新生代回收,然后实在不行,就MIXED,然后最后才可能会full gc。
由于新生代,老年代gc的阶段是不同的,所以假如我们只回收新生代,此时还是按照上面的gc roots可达性分析算法,就会把老年代全部都给标记一遍,而我们又不收集老年代,这样就会非常浪费时间。
新生代对象,一定只有新生代引用吗?有可能会有老年代的对象引用新生代的对象。那我们直接在触发新生代gc的时候,我们在老年代的里面有一些对象也在我们的引用链中。
同样的道理,如果说,我们要回收老年代,我们也需要把其他代的所有对象遍历一遍,非常耗时。
RSet记忆集,就是为了解决这种问题而设计的。RSet记忆集,用一组key - value结构,记录了跨代引用的引用关系,在gc的时候,可以快速的借助记忆集+gc roots搞定同代引用及跨代引用的可达对象分析问题。
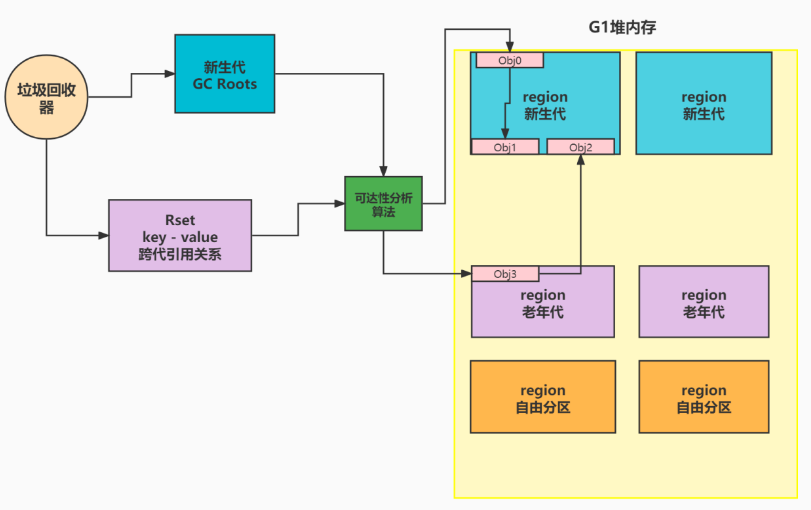
怎么记录跨代的引用关系?
假如我们很多块儿region,一部分属于新生代,一部分属于老年代,老年代的对象引用了新生代的对象,我直接针对被引用对象搞一块儿内存,用来存储到底是谁引用了我。
当遍历新生代所有对象前,直接把这块儿内存里面的引用了我的那个对象,也给加入到gc roots里面,然后进行遍历。这样子就能避免遍历老年代整个分代了。从效率,从分代隔离的层面,这样做都是非常合理的。
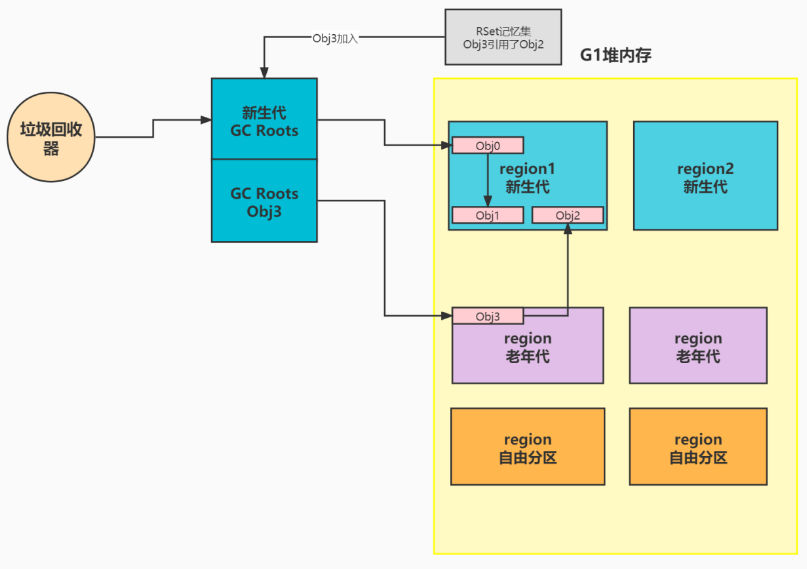
记忆集的维度应该是什么?针对新生代和老年代各搞一个?还是针对region,每个region都搞一个?
对于G1来说,它是以region为最小内存管理维度的,它的RSet记忆集的维度是对每一个region,都搞一块儿内存,存储region里面所有的对象被引用的引用关系。
针对region这个维度,是因为,每次回收之后,老年代,新生代,大对象区域的region可能都会变化,所以,如果说,对每个分代都搞一份儿的话,不太合理,因为region不断的在变化,同时也会有并发问题,效率问题。
同时,除了新生代的回收是需要选择所有新生代的region,老年代的回收,是需要找性价比高的region来回收的,也就是选择一部分去回收,那么选择一部分回收的时候,还要去整个分代对应的这么一大块儿引用关系数据,去做遍历,筛选,才能拿到需要的数据。
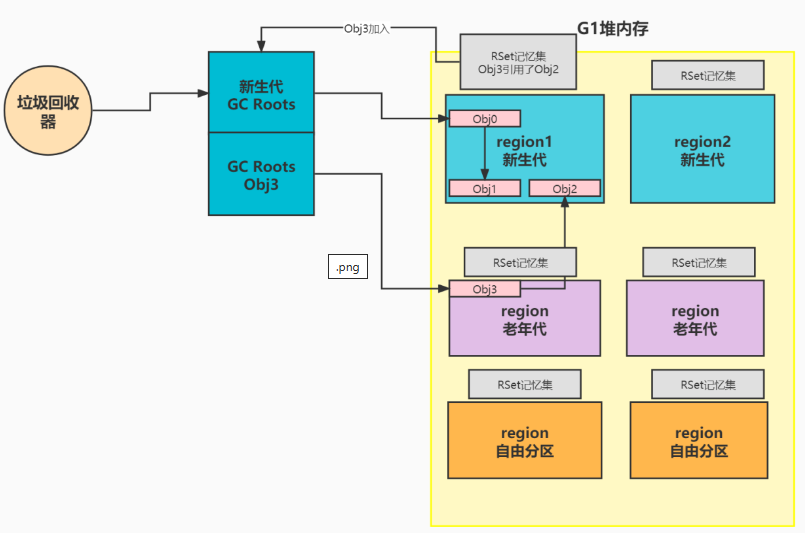
那么最终,G1就选择了使用Rset记忆集这种方式,记录了这些引用关系,方便在进行垃圾回收的时候去找到有哪些GC roots,大大减少了不必要的遍历操作。
位图--bitMap
描述并发阶段的时候,内存使用状态的一个数据结构。
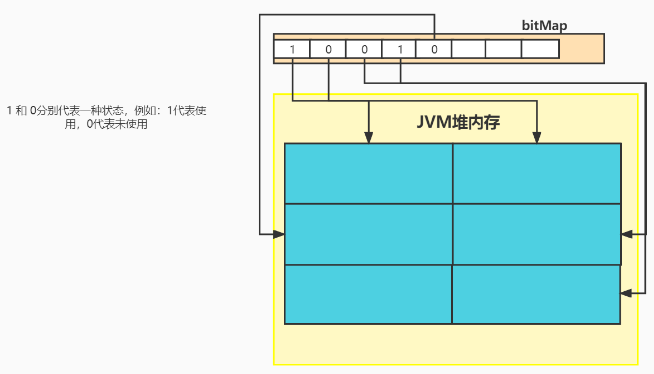
大家知道,JVM管理的是内存。内存的使用状态,其实是不太好标记的 000000001010。最笨的方法就是,直接遍历整个内存块儿,看看它到底有没有东西,没有东西,我就认为它是空闲的。有东西,我就认为它是使用中的。
那大家想,这种简单粗暴的方式,适合JVM吗?如果JVM想看看哪些内存被使用了,还要直接去遍历这个内存去分析分析到底有没有被使用吗?很明显这样子是不行的。效率太低太低了。
所以说,为了描述内存的使用状态,G1采取了位图的方式来做描述。在一个位图里面记录了所有内存的使用状态,如果要看内存是否被使用了,就直接访问位图中这块儿内存对应的坐标里面的内容,就能知道内存是否已经使用了。
举个例子:
卡表 -- cardTable
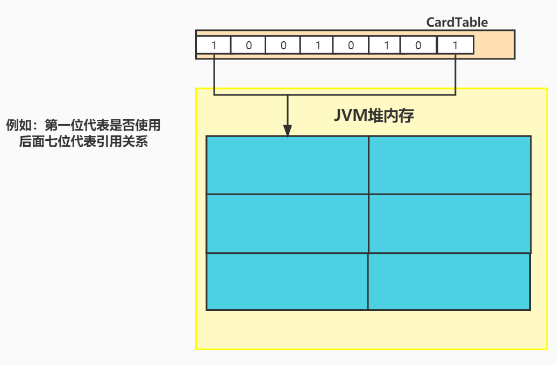
卡表和位图其实是类似的东西。都是用一段数据去描述另外一块儿内存的情况。跟位图不一样的地方是:由于位图只能用一位来描述,也就是只能记录使用,或者未使用。因为一个位只能有0 1 这两种状态。而卡表为了描述更多的信息,比如内存是否使用,内存的引用关系等,使用的是8位,也就是一个字节来描述一块儿内存的使用情况,是否使用,使用了多少。
所以说,本质上卡表在数据结构层面和位图没有什么太大区别。只是描述符比位图长,描述的内容比位图多。
在G1中,卡表是用一个字节(8位)来描述512字节的空间的使用情况,及内存被谁使用了。并且卡表在G1中,是一个全局卡表,也就是,整个堆内存公用一个全局卡表,来描述全局的内存使用情况及对象引用关系。
当然,因为512字节的内存,可能会被引用多次,里面可能有多个对象,或者说,同一个个对象,被多个对象引用,所以说,卡表的描述,可以理解为一个大概的引用关系描述。
在G1中,JVM使用了RSet+卡表来作为分代模型中,跨代引用关系不好判定,不好追踪问题的解决思路。
一个Rset,它是由一个一个key - value对组成的。其中,key是引用了当前region的其他区域的地址。Value是一个数组,value中的元素是引用方的对象所在内存块儿在CardTable中的下标。
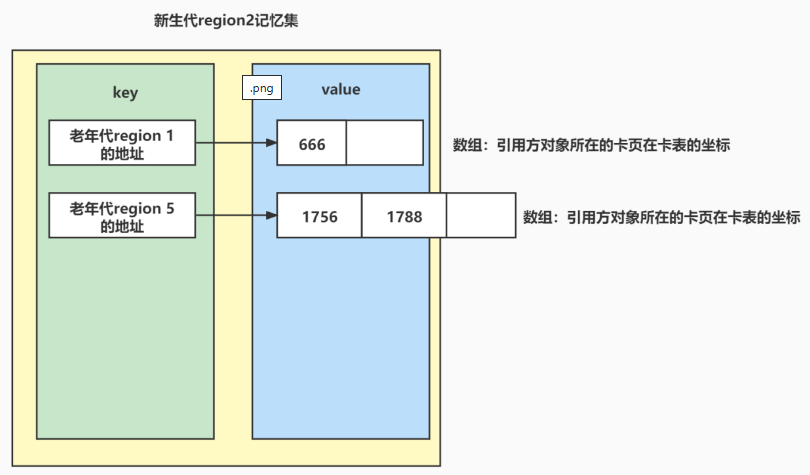
也就是说,如果我们在遍历对象的时候,直接找对象所在region的记忆集,从里面就能拿到所有引用了当前对象所在region的卡表数据,及卡表对应的512内存块儿的地址。
以上是Rset记忆集中存储的信息。所以说,记忆集存储的其实不是哪些对象引用了当前region,而是对象所在的卡页对当前region的引用关系,粒度相比对象来说会稍微大一些(如果对象大的话,粒度可能反而更小,要看具体对象的大小情况。)
总结来说就是,一旦有老年代的对象引用了一个新生代(老年代)的region中的对象,那么就会在这个新生代的(老年代)region 的记忆集中维护一个key - value对,其中key是引用方对象对应的region的地址,也就是那个老年代的对象所在region的地址,value是一个数组,里面存储的是这个对象所在的cardpage(512字节的卡页)在全局卡表中的下标。通过这个Rset,我们在遍历一个region的时候,就能根据这个region的Rset快速定位到引用方所在的region及引用对象所在的cardpage。从而避免对老年代进行全局扫描。
举例:
(1)新生代region2中有一个对象Obj2
(2)老年代region1 和老年代 region5里面有Obj1 Obj3 Obj4 Obj5均引用了Obj2这个对象
(3)其中Obj3 Obj4位于老年代region1的同一个cardPage里面,这个cardPage在全局卡表的坐标位:666
(4)Obj1和Obj5分别位于老年代region5的两个cardPage里面,这两个cardPage在全局卡表的坐标为:1788和1756
把这个引用关系图画出来:
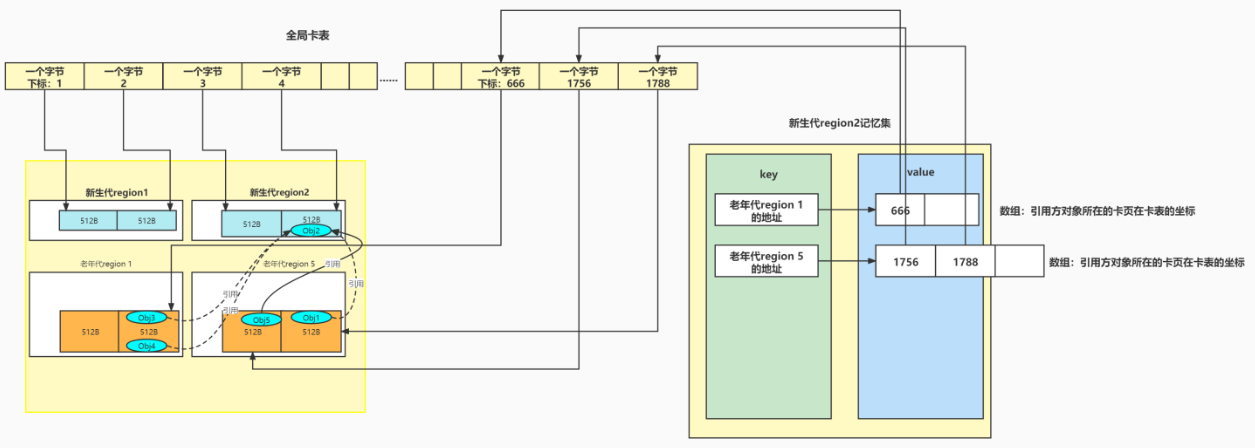
当我们在进行新生代垃圾回收的时候,就可以通过新生代region2的记忆集Rset + GC roots来找到新生代自己的引用关系,以及老年代跨代引用的所有引用关系。
DCQ
如果引用关系发生了改变,RSet是否需要更新,应该怎么更新?
如果说有对象引用变更,比如说,新增了一个对象引用,或者失去了一个对象的引用,RSet肯定是要更新的,不然肯定会出现回收的时候引用关系错误,回收会出现把正常对象当垃圾对象,或者把垃圾对象当正常对象,没有回收的情况,所以在引用关系变更的时候,一定是需要更新Rset的。
我们需要思考两个问题:
(1)每次更新引用关系,RSet是一定需要立即更新的吗?不立即更新有什么影响?
(2)立即更新会产生什么问题?不立即更新的话,有什么合理的方案?
如果每次引用关系变更都更新:
首先,一个region有一个RSet,所以说,一旦发生了同一个对象,或者同一个region内对象的引用关系变更,一定是有可能出现并发访问统一个RSet的情况的,因为一个region是共享同一个RSet的。所以,第一个需要解决的问题就是并发问题,而解决并发问题的最好的方式就是串行化处理,要么就是分而治之。
Rset的更新操作应该什么时候做?
我们想想看,RSet的数据,我们什么时候才会用到?JVM最核心的两大操作就是,对象分配,和垃圾回收对不对?这两个过程是JVM的核心过程。我们来分析分析这两个过程。
首先分配对象,需要用到RSet的数据吗?
并不需要,因为我们在分配一个对象的时候,只需要看看内存够不够,剩余空间是否能够分配一个对象,分配完成以后,直接更新一下内存的使用情况就OK了,并不需要借助RSet。
那么就还剩下一个垃圾回收,垃圾回收要不要用到RSet?答案是肯定的,RSet本身就是为了垃圾回收的时候更加方便,不需要遍历的空间而设计的,所以在垃圾回收的时候才需要用到RSet。
那么我们是不是可以得出一个结论,即,在大多数时间里,RSet即使需要更新,而我们没有把它更新,其实也无所谓,因为不影响程序运行。只有在垃圾回收的时候,我一定需要最新的RSet,不然就会出错。
基于前面的分析,我们知道只要在垃圾回收之前把所有引用更新的操作做完就OK了。而在垃圾回收之前,我们有大把大把的时间慢慢更新这个引用关系。所以G1就设计了一个队列,叫做DCQ(Dirty Card Queue)队列,在每次有引用关系变更的时候,就把这个变更操作,发送一个消息放到DCQ里面,然后有一个专门的线程去异步消费。大家看下面的图:
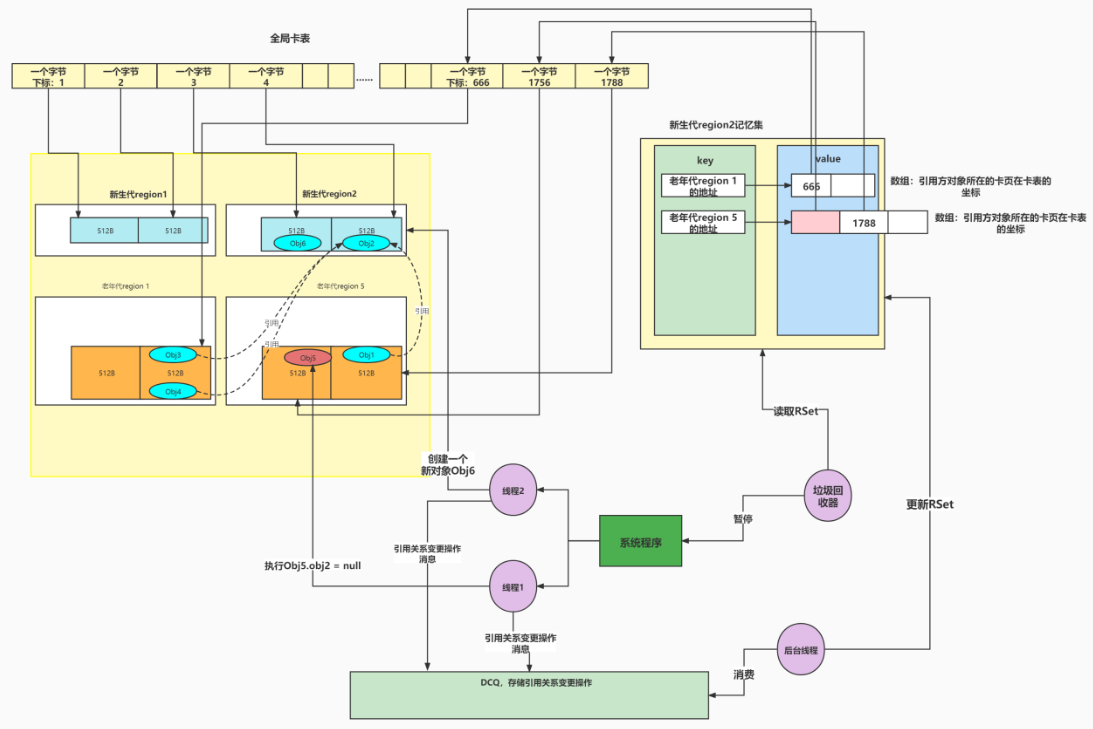
在G1中,有一个refine线程的概念,refine线程,其主要的工作内容,就是去消费DCQ里面的消息,然后去更新RSet。
当然还有其他的作用,比如说,我们之前说过的新生代的动态扩展问题,它就会做新生代分区的抽样工作,在满足响应时间的这个前提下,根据抽样的数据(GC时间,垃圾数量,新生代region个数等),去调整新生代的region个数。
但是它的主要工作其实就是管理RSet,也就是去消费DCQ然后去更新RSet里面的引用关系。
如果说Refine忙不过来了怎么办?DCQ中变更消息的数量很多,导致refine线程超负荷工作,还是无法全部消费,应该怎么处理?
因为平常只会有少量的Refine线程去消费DCQ里面的数据,当系统并发非常高的时候,DCQ里面的变更消息可能会非常非常多,那么refine线程肯定是忙不过来的,这个时候就需要有多个refine线程参与进来来一起处理这个引用变更数据了,甚至还有可能会有其他的线程一起处理。关于refine线程的数量,可以自己去指定。其默认的数量是G1ConcRefinementThreads +1
如果实在是忙不过来,那么就只能在指定参数的时候多设置几个refine线程了(因为G1一般是大内存,多核机器,所以设置4-5个线程其实也无所谓)。
如果说refine线程已经够多了,这个时候还是忙不过来怎么办?这个时候,其实G1会借助系统的工作线程,也就是说,你创建完对象之后,这个线程很可能还没有去等着接收其他的请求,而是帮忙去消费DCQ去了。
DCQ的长度是无限的吗?多个线程消费同一个DCQ,岂不是还是有并发问题?
其实G1是设计了二级缓存来解决并发冲突的。
简单来说第一层缓存是在线程这一层,也就是说,DCQ其实是属于每一个线程的。也就是说,每一个工作线程都会关联一个DCQ,每个线程在执行了引用更新操作的时候,都会往自己持有的那个DCQ里面写入变更信息。DCQ的长度默认是256,如果写满了,就重新申请一个新的DCQ,并把这个老DCQ提交到第二级缓存,也就是一个DCQ Set里面去,我们叫这个二级缓存为DCQS。
这样的话,其实就解决了并发写的问题。因为每个线程只写自己持有的DCQ就OK了,写满了就提交到DCQS,顶多这个时候会加一个锁。在线程持有的DCQ满了以后,就提交到DCQS中去。
那么当refine线程实在是忙不过来的时候,是怎么处理的呢?其实也很简单,因为refine线程是直接从DCQS取DCQ去消费的,那么如果说refine线程忙不过来的时候,也就是意味着,DCQS已经不能再放下更多的DCQ了,此时工作线程就会去判断,能不能提交到DCQS啊?不能提交啊,不能提交我就自己处理了。这个时候,工作线程就会自己去处理这个DCQ,更新RSet。
DCQ里面的数据到底是怎么写进去的呢?
这个问题其实很简单,G1给每个变更操作前都加了一层写屏障,注意,这个写屏障和内存屏障可不一样,这个写屏障是类似于增强代码,或者AOP切面的一个概念。
什么意思呢,其实就是说,我们在修改了内存值的时候(实际上就是往内存里面写东西的时候),额外执行一些操作。比如,判断是否需要写到DCQ啊(新生代与新生代的引用就不需要写),比如判断本次的写入操作是否改变了引用啊,比如发送一条消息到DCQ啊等等。
这么一层加强代码,就是所谓的写屏障。
那么这层加强代码到底有什么用呢?作用其实很大,因为不是任何写内存的操作都会改变引用关系什么的,如果没有改变引用关系,我们是不是就不需要写这么一条数据到DCQ里面了?
这样子其实可以大大减少后续refine线程处理DCQ的压力,同时也可以避免DCQ快速填满,导致refine线程被快速启动。
所以这个写屏障的作用主要有两点:第一过滤掉不需要写的引用变更操作,比如我新生代到新生代的引用,比如同一个分区内的引用等。第二就是,把正常的变更数据,写入一条到DCQ里面。
DCQS的白绿黄红四个挡位:
DCQS肯定是有上限的,当达到一定的阈值不能再提交的时候,工作线程就得自己去处理了。这个时候说明系统负载已经很重很重了,系统的运行速度可能会比较慢,因为工作线程要去处理DCQ更新RSet的引用关系去了。
refine线程的数量怎么设置?什么时候应该用多少个线程?针对这个问题G1对DCQS的数量做了四个区域。
有三个参数来划分这四个区域:G1ConcRefinementGreenZone、G1ConcRefinementYellowZone、G1ConcRefinementRedZone,三个值默认都是0,如果说没有设置,G1会自动推断这个三个值。
白区:[0,green) 如果说在这个区域,refine线程也不处理,也就是不启动refine线程来处理DCQ,只会有refine线程去新生代做抽样
绿区:[green,yellow) refine线程开始启动,并且个数DCQS的大小来计算启动refine线程的个数
黄:[yellow,red) 所有refine线程都参与到DCQS的处理
红:[red,正无穷) 所有refine线程以及系统工作线程都参与DCQ的处理
如果说DCQS直到最终GC的时候还是没有处理完,会怎么办?
启动了refine线程,然而DCQ在GC的时候还是没有处理完,这个时候,就会由GC线程,参与处理没有完成处理的DCQ。直到全部处理完成,然后才会进行下一步的GC操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号