Elastic Stack:es ik分词器
安装插件包
elasticsearch-analysis-ik-7.7.1.zip
链接:https://pan.baidu.com/s/1HXiQ5vEYU1cSMt6dhUhxoQ
提取码:uzcv
在es的plugins目录下新建一个ik文件夹,把压缩包放入ik中
目录结构是这样的:
/opt/elasticsearch-7.7.1/plugins/ik
解压zip包:
安装支持ZIP的工具
yum install -y unzip zip
安装完成后,直接解压:
unzip elasticsearch-analysis-ik-7.7.1.zip
rm -rf elasticsearch-analysis-ik-7.7.1.zip
完成后,重启es服务即可。
ik的基本使用
ik_max_word: 会将文本做最细粒度的拆分
ik_smart: 会做最粗粒度的拆分
GET /_analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}

GET /_analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
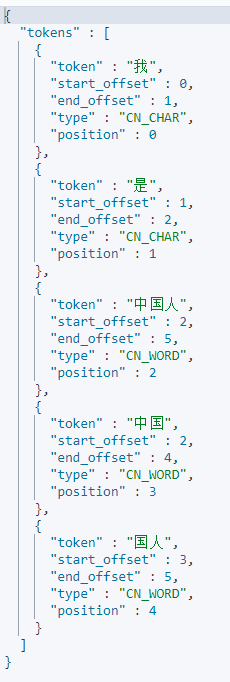
存储时,使用ik_max_word,搜索时,使用ik_smart
PUT /my_index
{
"mappings": {
"properties": {
"text": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
ik相关配置
es/plugins/ik/config
相关文件介绍:
IKAnalyzer.cfg.xml:用来配置自定义词库
main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起
preposition.dic: 介词
quantifier.dic:放了一些单位相关的词,量词
suffix.dic:放了一些后缀
surname.dic:中国的姓氏
stopword.dic:英文停用词
自定义词库:
(1)自己建立词库:每年都会涌现一些特殊的流行词,网红,蓝瘦香菇,喊麦,鬼畜,一般不会在ik的原生词典里
自己补充自己的最新的词语,到ik的词库里面
IKAnalyzer.cfg.xml:ext_dict,创建mydict.dic。
补充自己的词语,然后需要重启es,才能生效
(2)自己建立停用词库:比如了,的,啥,么,我们可能并不想去建立索引,让人家搜索
custom/ext_stopword.dic,已经有了常用的中文停用词,可以补充自己的停用词,然后重启es
标签:
Elastic Stack


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix