Elastic Stack:es 文档document入门
一.模板自带字段
当我们对文档操作时,前三个字段总是不变的
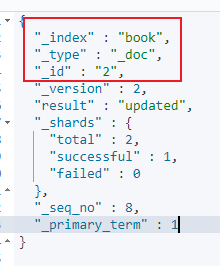
三个字段的含义:
_index:
原则:类似数据放在一个索引中。数据库中表的定义规则。如图书信息放在book索引中,员工信息放在employee索引中。各个索引存储和搜索时互不影响。(不同数据放到不同索引中)
定义规则:英文小写。尽量不要使用特殊字符。
_type:
注意:以后的es9将彻底删除此字段,所以当前版本在不断弱化type。不需要关注。见到_type都为doc。
_id:
含义:文档的唯一标识。就像表的id主键。结合索引可以标识和定义一个文档。
二.文档id的生成方式
1.手动生成:put /index/_doc/id
2.自动生成:put/index/_doc
生成的是20个字符的id,分布式唯一id,base64编码,GUID算法生成。
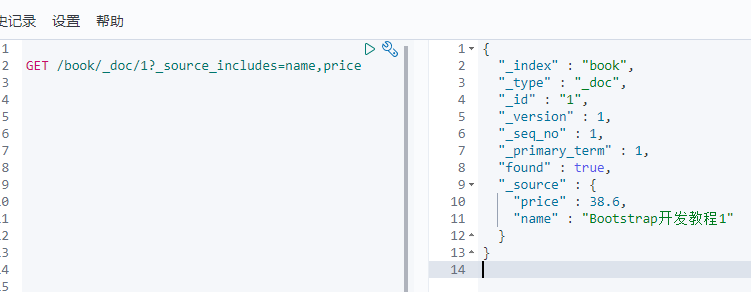
三.定制返回字段
语法:GET /index/type/id?_source_includes=field1,field2...
1 | GET /book/_doc/1?__source_includes=name,price |
四.文档的替换与删除
1.全量替换:PUT /index/type/id
执行两次,返回结果中版本号(_version)在不断上升。此过程为全量替换。
实质:旧文档的内容不会立即删除,只是标记为deleted。适当的时机,集群会将这些文档删除。
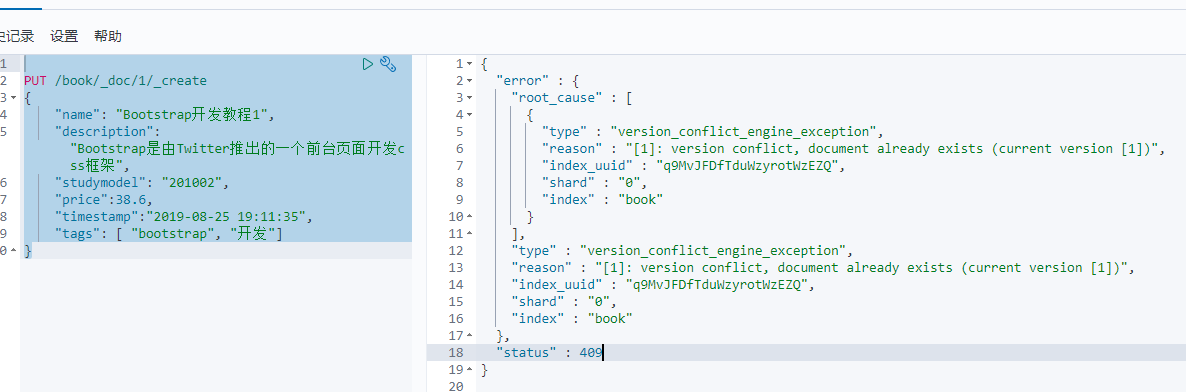
2.为防止覆盖原有数据,我们在新增时,设置为强制创建,不会覆盖原有文档。
语法:PUT /index/type/id/_create
3.删除文档
DELETE /index/_doc/id
实质:旧文档的内容不会立即删除,只是标记为deleted。适当的时机,集群会将这些文档删除。
五.局部替换
原理:1.es内部获取旧文档
2.将传来的文档field更新到旧数据(内存)
3.将就文档标记为delete
4.创建新文档
1 2 3 4 5 6 | post /index/type/id/_update { "doc": { "field":"value" }} |
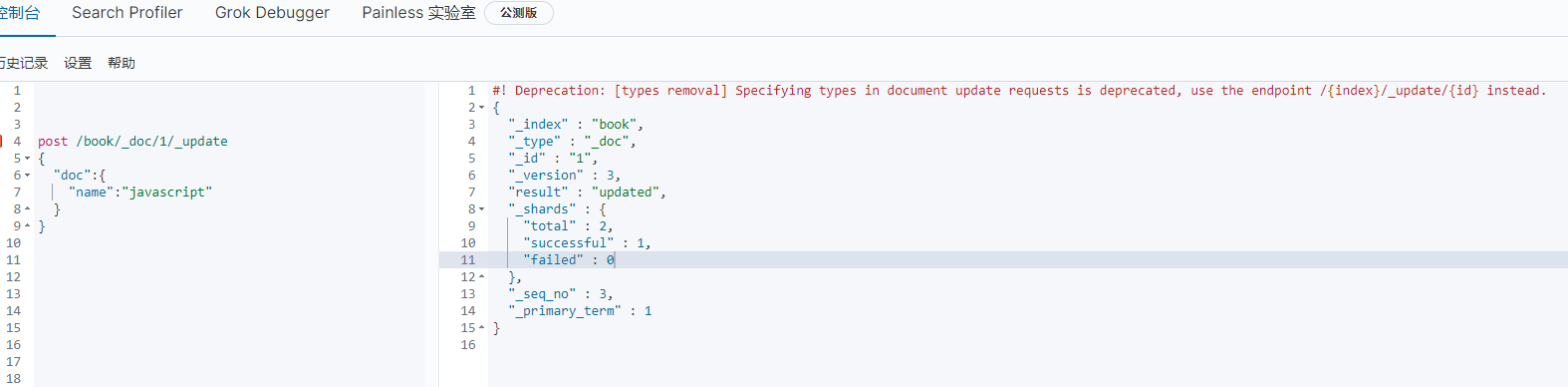
六.批量查询
1 2 3 4 5 6 7 8 | post /index/_doc/_search{ "query": { "ids" : { "values" : [id1, id2...] } }} |
七.批量增删改 bulk
1 2 3 | POST /_bulk{"action": {"metadata"}}{"data"} |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix