编译原理——实现一门脚本语言 原理篇(下)
作用域和生存期:实现块作用域和函数
什么是作用域和生存期,它们的重要性又体现在哪儿呢?
“作用域”和“生存期”是计算机语言中更加基础的概念,它们可以帮你深入地理解函数、块、闭包、面向对象、静态成员、本地变量和全局变量等概念。
作用域(Scope)
作用域是指计算机语言中变量、函数、类等起作用的范围,我们来看一个具体的例子。
下面这段代码是用C语言写的,我们在全局以及函数fun中分别声明了a和b两个变量,然后在代码里对这些变量做了赋值操作:
/*
scope.c
测试作用域。
*/
#include <stdio.h>
int a = 1;
void fun()
{
a = 2;
//b = 3; //出错,不知道b是谁
int a = 3; //允许声明一个同名的变量吗?
int b = a; //这里的a是哪个?
printf("in fun: a=%d b=%d \n", a, b);
}
int b = 4; //b的作用域从这里开始
int main(int argc, char **argv){
printf("main--1: a=%d b=%d \n", a, b);
fun();
printf("main--2: a=%d b=%d \n", a, b);
//用本地变量覆盖全局变量
int a = 5;
int b = 5;
printf("main--3: a=%d b=%d \n", a, b);
//测试块作用域
if (a > 0){
int b = 3; //允许在块里覆盖外面的变量
printf("main--4: a=%d b=%d \n", a, b);
}
else{
int b = 4; //跟if块里的b是两个不同的变量
printf("main--5: a=%d b=%d \n", a, b);
}
printf("main--6: a=%d b=%d \n", a, b);
}
这段代码编译后运行,结果是:
main--1: a=1 b=4
in fun: a=3 b=3
main--2: a=2 b=4
main--3: a=5 b=5
main--4: a=5 b=3
main--6: a=5 b=5
我们可以得出这样的规律:
- 变量的作用域有大有小,外部变量在函数内可以访问,而函数中的本地变量,只有本地才可以访问。
- 变量的作用域,从声明以后开始。
- 在函数里,我们可以声明跟外部变量相同名称的变量,这个时候就覆盖了外部变量。
下面这张图直观地显示了示例代码中各个变量的作用域:
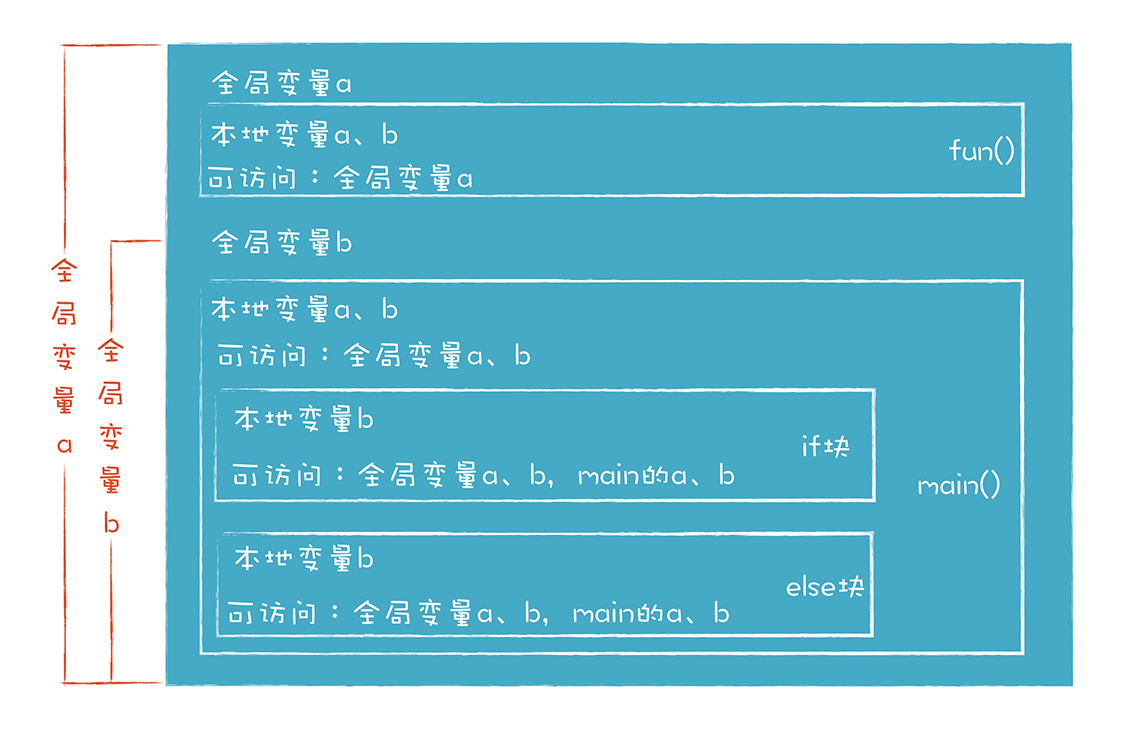
另外,C语言里还有块作用域的概念,就是用花括号包围的语句,if和else后面就跟着这样的语句块。块作用域的特征跟函数作用域的特征相似,都可以访问外部变量,也可以用本地变量覆盖掉外部变量。
你可能会问:“其他语言也有块作用域吗?特征是一样的吗?”其实,各个语言在这方面的设计机制是不同的。比如,下面这段用Java写的代码里,我们用了一个if语句块,并且在if部分、else部分和外部分别声明了一个变量c:
/**
* Scope.java
* 测试Java的作用域
*/
public class ScopeTest{
public static void main(String args[]){
int a = 1;
int b = 2;
if (a > 0){
//int b = 3; //不允许声明与外部变量同名的变量
int c = 3;
}
else{
int c = 4; //允许声明另一个c,各有各的作用域
}
int c = 5; //这里也可以声明一个新的c
}
}
你能看到,Java的块作用域跟C语言的块作用域是不同的,它不允许块作用域里的变量覆盖外部变量。那么和C、Java写起来很像的JavaScript呢?来看一看下面这段测试JavaScript作用域的代码:
/**
* Scope.js
* 测试JavaScript的作用域
*/
var a = 5;
var b = 5;
console.log("1: a=%d b=%d", a, b);
if (a > 0) {
a = 4;
console.log("2: a=%d b=%d", a, b);
var b = 3; //看似声明了一个新变量,其实还是引用的外部变量
console.log("3: a=%d b=%d", a, b);
}
else {
var b = 4;
console.log("4: a=%d b=%d", a, b);
}
console.log("5: a=%d b=%d", a, b);
for (var b = 0; b< 2; b++){ //这里是否能声明一个新变量,用于for循环?
console.log("6-%d: a=%d b=%d",b, a, b);
}
console.log("7: a=%d b=%d", a, b);
这段代码编译后运行,结果是:
1: a=5 b=5
2: a=4 b=5
3: a=4 b=3
5: a=4 b=3
6-0: a=4 b=0
6-1: a=4 b=1
7: a=4 b=2
你可以看到,JavaScript是没有块作用域的。我们在块里和for语句试图重新定义变量b,语法上是允许的,但我们每次用到的其实是同一个变量。
对比了三种语言的作用域特征之后,你是否发现原来看上去差不多的语法,内部机理却不同?这种不同其实是语义差别的一个例子。你要注意的是,现在我们讲的很多内容都已经属于语义的范畴了,对作用域的分析就是语义分析的任务之一。
生存期(Extent)
生存期是变量可以访问的时间段,也就是从分配内存给它,到收回它的内存之间的时间。
在前面几个示例程序中,变量的生存期跟作用域是一致的。出了作用域,生存期也就结束了,变量所占用的内存也就被释放了。这是本地变量的标准特征,这些本地变量是用栈来管理的。
但也有一些情况,变量的生存期跟语法上的作用域不一致,比如在堆中申请的内存,退出作用域以后仍然会存在。
下面这段C语言的示例代码中,fun函数返回了一个整数的指针。
出了函数以后,本地变量b就消失了,这个指针所占用的内存(&b)就收回了,其中&b是取b的地址,这个地址是指向栈里的一小块空间,因为b是栈里申请的。在这个栈里的小空间里保存了一个地址,指向在堆里申请的内存。
这块内存,也就是用来实际保存数值2的空间,并没有被收回,我们必须手动使用free()函数来收回。
/*
extent.c
测试生存期。
*/
#include <stdio.h>
#include <stdlib.h>
int * fun(){
int * b = (int*)malloc(1*sizeof(int)); //在堆中申请内存
*b = 2; //给该地址赋值2
return b;
}
int main(int argc, char **argv){
int * p = fun();
*p = 3;
printf("after called fun: b=%lu *b=%d \n", (unsigned long)p, *p);
free(p);
}
类似的情况在Java里也有。Java的对象实例缺省情况下是在堆中生成的。
下面的示例代码中,从一个方法中返回了对象的引用,我们可以基于这个引用继续修改对象的内容,这证明这个对象的内存并没有被释放:
/**
* Extent2.java
* 测试Java的生存期特性
*/
public class Extent2{
StringBuffer myMethod(){
StringBuffer b = new StringBuffer(); //在堆中生成对象实例
b.append("Hello ");
System.out.println(System.identityHashCode(b)); //打印内存地址
return b; //返回对象引用,本质是一个内存地址
}
public static void main(String args[]){
Extent2 extent2 = new Extent2();
StringBuffer c = extent2.myMethod(); //获得对象引用
System.out.println(c);
c.append("World!"); //修改内存中的内容
System.out.println(c);
//跟在myMethod()中打印的值相同
System.out.println(System.identityHashCode(c));
}
}
因为Java对象所采用的内存超出了申请内存时所在的作用域,所以也就没有办法自动收回。所以Java采用的是自动内存管理机制,也就是垃圾回收技术。
那么为什么说作用域和生存期是计算机语言更加基础的概念呢?
其实是因为它们对应到了运行时的内存管理的基本机制。虽然各门语言设计上的特性是不同的,但在运行期的机制都很相似,比如都会用到栈和堆来做内存管理。
实现作用域和栈
在之前的PlayScript脚本的实现中,处理变量赋值的时候,我们简单地把变量存在一个哈希表里,用变量名去引用,就像下面这样:
public class SimpleScript {
private HashMap<String, Integer> variables = new HashMap<String, Integer>();
...
}
但如果变量存在多个作用域,这样做就不行了。这时,我们就要设计一个数据结构,区分不同变量的作用域。分析前面的代码,你可以看到作用域是一个树状的结构,比如Scope.c的作用域:
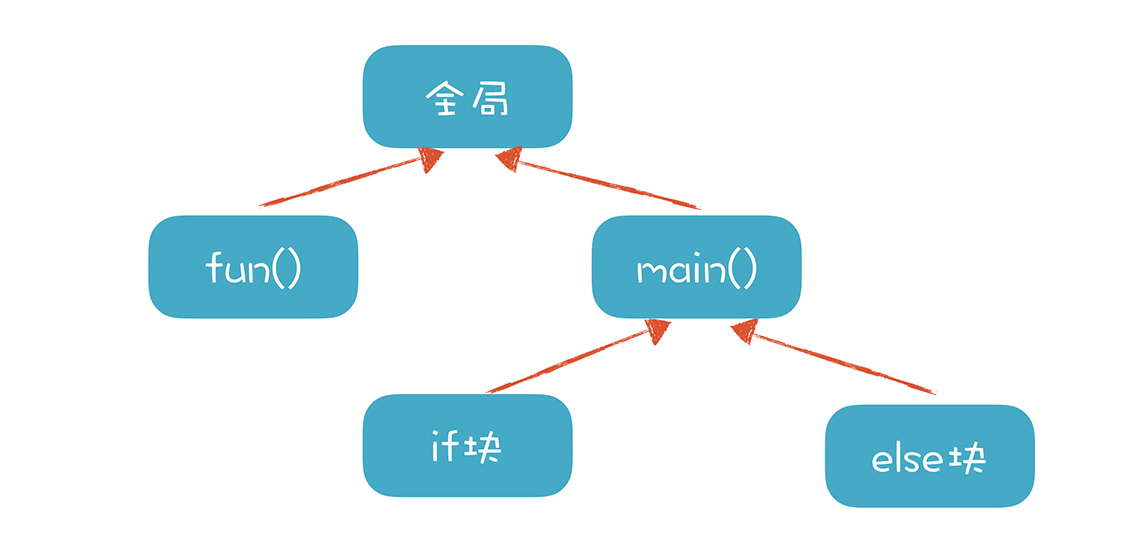
面向对象的语言不太相同,它不是一棵树,是一片树林,每个类对应一棵树,所以它也没有全局变量。在我们的playscript语言中,我们设计了下面的对象结构来表示Scope:
//编译过程中产生的变量、函数、类、块,都被称作符号
public abstract class Symbol {
//符号的名称
protected String name = null;
//所属作用域
protected Scope enclosingScope = null;
//可见性,比如public还是private
protected int visibility = 0;
//Symbol关联的AST节点
protected ParserRuleContext ctx = null;
}
//作用域
public abstract class Scope extends Symbol{
// 该Scope中的成员,包括变量、方法、类等。
protected List<Symbol> symbols = new LinkedList<Symbol>();
}
//块作用域
public class BlockScope extends Scope{
//...
}
//函数作用域
public class Function extends Scope implements FunctionType{
//...
}
//类作用域
public class Class extends Scope implements Type{
//...
}
目前我们划分了三种作用域,分别是块作用域(Block)、函数作用域(Function)和类作用域(Class)。
我们在解释执行playscript的AST的时候,需要建立起作用域的树结构,对作用域的分析过程是语义分析的一部分。也就是说,并不是有了AST,我们马上就可以运行它,在运行之前,我们还要做语义分析,比如对作用域做分析,让每个变量都能做正确的引用,这样才能正确地执行这个程序。
解决了作用域的问题以后,再来看看如何解决生存期的问题。还是看Scope.c的代码,随着代码的执行,各个变量的生存期表现如下:
- 进入程序,全局变量逐一生效;
- 进入main函数,main函数里的变量顺序生效;
- 进入fun函数,fun函数里的变量顺序生效;
- 退出fun函数,fun函数里的变量失效;
- 进入if语句块,if语句块里的变量顺序生效;
- 退出if语句块,if语句块里的变量失效;
- 退出main函数,main函数里的变量失效;
- 退出程序,全局变量失效。
通过下面这张图,你能直观地看到运行过程中栈的变化:
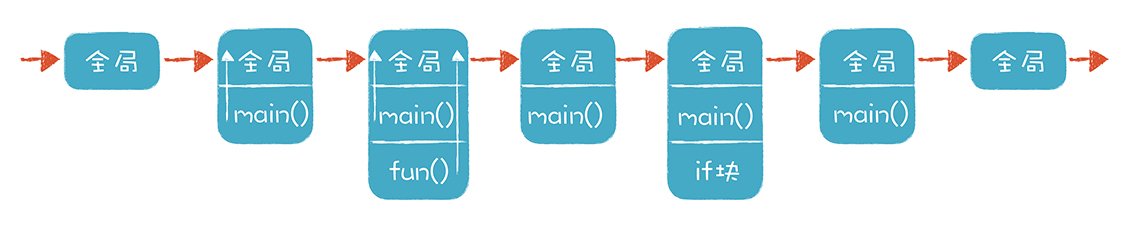
代码执行时进入和退出一个个作用域的过程,可以用栈来实现。
每进入一个作用域,就往栈里压入一个数据结构,这个数据结构叫做栈桢(Stack Frame)。
栈桢能够保存当前作用域的所有本地变量的值,当退出这个作用域的时候,这个栈桢就被弹出,里面的变量也就失效了。
你可以看到,栈的机制能够有效地使用内存,变量超出作用域的时候,就没有用了,就可以从内存中丢弃。我在ASTEvaluator.java中,用下面的数据结构来表示栈和栈桢,其中的PlayObject通过一个HashMap来保存各个变量的值:
private Stack<StackFrame> stack = new Stack<StackFrame>();
public class StackFrame {
//该frame所对应的scope
Scope scope = null;
//enclosingScope所对应的frame
StackFrame parentFrame = null;
//实际存放变量的地方
PlayObject object = null;
}
public class PlayObject {
//成员变量
protected Map<Variable, Object> fields = new HashMap<Variable, Object>();
}
目前,我们只是在概念上模仿栈桢,当我们用Java语言实现的时候,PlayObject对象是存放在堆里的,Java的所有对象都是存放在堆里的,只有基础数据类型,比如int和对象引用是放在栈里的。
虽然只是模仿,这不妨碍我们建立栈桢的概念。
要注意的是,栈的结构和Scope的树状结构是不一致的。
也就是说,栈里的上一级栈桢,不一定是Scope的父节点。
要访问上一级Scope中的变量数据,要顺着栈桢的parentFrame去找。
上图中展现了这种情况,在调用fun函数的时候,栈里一共有三个栈桢:全局栈桢、main()函数栈桢和fun()函数栈桢,其中main()函数栈桢的parentFrame和fun()函数栈桢的parentFrame都是全局栈桢。
实现块作用域
目前,我们已经做好了作用域和栈,在这之后,就能实现很多功能了,比如让if语句和for循环语句使用块作用域和本地变量。
以for语句为例,visit方法里首先为它生成一个栈桢,并加入到栈中,运行完毕之后,再从栈里弹出:
BlockScope scope = (BlockScope) cr.node2Scope.get(ctx); //获得Scope
StackFrame frame = new StackFrame(scope); //创建一个栈桢
pushStack(frame); //加入栈中
...
//运行完毕,弹出栈
stack.pop();
当我们在代码中需要获取某个变量的值的时候,首先在当前桢中寻找。找不到的话,就到上一级作用域对应的桢中去找:
StackFrame f = stack.peek(); //获取栈顶的桢
PlayObject valueContainer = null;
while (f != null) {
//看变量是否属于当前栈桢里
if (f.scope.containsSymbol(variable)){
valueContainer = f.object;
break;
}
//从上一级scope对应的栈桢里去找
f = f.parentFrame;
}
运行下面的测试代码,你会看到在执行完for循环以后,我们仍然可以声明另一个变量i,跟for循环中的i互不影响,这证明它们确实属于不同的作用域:
String script = "int age = 44; for(int i = 0;i<10;i++) { age = age + 2;} int i = 8;";
实现函数功能
先来看一下与函数有关的语法:
//函数声明
functionDeclaration
: typeTypeOrVoid? IDENTIFIER formalParameters ('[' ']')*
functionBody
;
//函数体
functionBody
: block
| ';'
;
//类型或void
typeTypeOrVoid
: typeType
| VOID
;
//函数所有参数
formalParameters
: '(' formalParameterList? ')'
;
//参数列表
formalParameterList
: formalParameter (',' formalParameter)* (',' lastFormalParameter)?
| lastFormalParameter
;
//单个参数
formalParameter
: variableModifier* typeType variableDeclaratorId
;
//可变参数数量情况下,最后一个参数
lastFormalParameter
: variableModifier* typeType '...' variableDeclaratorId
;
//函数调用
functionCall
: IDENTIFIER '(' expressionList? ')'
| THIS '(' expressionList? ')'
| SUPER '(' expressionList? ')'
;
在函数里,我们还要考虑一个额外的因素:参数。在函数内部,参数变量跟普通的本地变量在使用时没什么不同,在运行期,它们也像本地变量一样,保存在栈桢里。
我们设计一个对象来代表函数的定义,它包括参数列表和返回值的类型:
public class Function extends Scope implements FunctionType{
// 参数
protected List<Variable> parameters = new LinkedList<Variable>();
//返回值
protected Type returnType = null;
...
}
在调用函数时,我们实际上做了三步工作:
- 建立一个栈桢;
- 计算所有参数的值,并放入栈桢;
- 执行函数声明中的函数体。
我把相关代码放在了下面,你可以看一下:
//函数声明的AST节点
FunctionDeclarationContext functionCode = (FunctionDeclarationContext) function.ctx;
//创建栈桢
functionObject = new FunctionObject(function);
StackFrame functionFrame = new StackFrame(functionObject);
// 计算实参的值
List<Object> paramValues = new LinkedList<Object>();
if (ctx.expressionList() != null) {
for (ExpressionContext exp : ctx.expressionList().expression()) {
Object value = visitExpression(exp);
if (value instanceof LValue) {
value = ((LValue) value).getValue();
}
paramValues.add(value);
}
}
//根据形参的名称,在栈桢中添加变量
if (functionCode.formalParameters().formalParameterList() != null) {
for (int i = 0; i < functionCode.formalParameters().formalParameterList().formalParameter().size(); i++) {
FormalParameterContext param = functionCode.formalParameters().formalParameterList().formalParameter(i);
LValue lValue = (LValue) visitVariableDeclaratorId(param.variableDeclaratorId());
lValue.setValue(paramValues.get(i));
}
}
// 调用方法体
rtn = visitFunctionDeclaration(functionCode);
// 运行完毕,弹出栈
stack.pop();
你可以用playscript测试一下函数执行的效果,看看参数传递和作用域的效果:
String script = "int b= 10; int myfunc(int a) {return a+b+3;} myfunc(2);";
总结
实现了块作用域和函数,探究了计算机语言的两个底层概念:作用域和生存期。
- 对作用域的分析是语义分析的一项工作。Antlr能够完成很多词法分析和语法分析的工作,但语义分析工作需要我们自己做。
- 变量的生存期涉及运行期的内存管理,引出了栈桢和堆的概念。
面向对象:实现数据和方法的封装
在现代计算机语言中,面向对象是非常重要的特性,似乎常用的语言都支持面向对象特性,比如Swift、C++、Java……不支持的反倒是异类了。
而它重要的特点就是封装。也就是说,对象可以把数据和对数据的操作封装在一起,构成一个不可分割的整体,尽可能地隐藏内部的细节,只保留一些接口与外部发生联系。
在对象的外部只能通过这些接口与对象进行交互,无需知道对象内部的细节。这样能降低系统的耦合,实现内部机制的隐藏,不用担心对外界的影响。那么它们是怎样实现的呢?
下面将从语义设计和运行时机制的角度剖析面向对象的特性,带你深入理解面向对象的实现机制,让你能在日常编程工作中更好地运用面向对象的特性。
比如,你会对对象的作用域和生存期、对象初始化过程等有更清晰的了解。而且你不会因为学习了Java或C++的面向对象机制,在学习JavaScript和Ruby的面向对象机制时觉得别扭,因为它们的本质是一样的。
面向对象的语义特征
可以认为所有的计算机语言都是对世界进行建模的方式,只不过建模的视角不同罢了。面向对象的设计思想,在上世纪90年代被推崇,几乎被视为最好的编程模式。实际上,各种不同的编程思想,都会表现为这门语言的语义特征,所以,从语义角度,利用类型、作用域、生存期这样的概念带你深入剖析一下面向对象的封装特性。
- 从类型角度
类型处理是语义分析时的重要工作。现代计算机语言可以用自定义的类来声明变量,这是一个巨大的进步。因为早期的计算机语言只支持一些基础的数据类型,比如各种长短不一的整型和浮点型,像字符串这种我们编程时离不开的类型,往往是在基础数据类型上封装和抽象出来的。所以,我们要扩展语言的类型机制,让程序员可以创建自己的类型。
- 从作用域角度
首先是类的可见性。作为一种类型,它通常在整个程序的范围内都是可见的,可以用它声明变量。当然,一些像Java的语言,也能限制某些类型的使用范围,比如只能在某个命名空间内,或者在某个类内部。
对象的成员的作用域是怎样的呢?
我们知道,对象的属性(“属性”这里指的是类的成员变量)可以在整个对象内部访问,无论在哪个位置声明。也就是说,对象属性的作用域是整个对象的内部,方法也是一样。这跟函数和块中的本地变量不一样,它们对声明顺序有要求,像C和Java这样的语言,在使用变量之前必须声明它。
- 从生存期的角度
对象的成员变量的生存期,一般跟对象的生存期是一样的。
在创建对象的时候,就对所有成员变量做初始化,在销毁对象的时候,所有成员变量也随着一起销毁。
当然,如果某个成员引用了从堆中申请的内存,这些内存需要手动释放,或者由垃圾收集机制释放。
但还有一些成员,不是与对象绑定的,而是与类型绑定的,比如Java中的静态成员。
静态成员跟普通成员的区别,就是作用域和生存期不同,它的作用域是类型的所有对象实例,被所有实例共享。
生存期是在任何一个对象实例创建之前就存在,在最后一个对象销毁之前不会消失。
用这三个语义概念,就把面向对象的封装特性解释清楚了,无论语言在顶层怎么设计,在底层都是这么实现的。
设计类的语法,并解析它
我们要在语言中支持类的定义,在PlayScript.g4中,可以这样定义类的语法规则:
classDeclaration
: CLASS IDENTIFIER
(EXTENDS typeType)?
(IMPLEMENTS typeList)?
classBody
;
classBody
: '{' classBodyDeclaration* '}'
;
classBodyDeclaration
: ';'
| memberDeclaration
;
memberDeclaration
: functionDeclaration
| fieldDeclaration
;
functionDeclaration
: typeTypeOrVoid IDENTIFIER formalParameters ('[' ']')*
(THROWS qualifiedNameList)?
functionBody
;
我来简单地讲一下这个语法规则:
- 类声明以class关键字开头,有一个标识符是类型名称,后面跟着类的主体。
- 类的主体里要声明类的成员。在简化的情况下,可以只关注类的属性和方法两种成员。我们故意把类的方法也叫做function,而不是method,是想把对象方法和函数做一些统一的设计。
- 函数声明现在的角色是类的方法。
- 类的成员变量的声明和普通变量声明在语法上没什么区别。
你能看到,我们构造像class这样高级别的结构时,之前形成的一些基础的语法模块都可以复用,比如变量声明、代码块(block)等。
用上面的语法写出来的playscript脚本的效果如下,在示例代码里也有,你可以运行它:
/*
ClassTest.play 简单的面向对象特性。
*/
class Mammal{
//类属性
string name = "";
//构造方法
Mammal(string str){
name = str;
}
//方法
void speak(){
println("mammal " + name +" speaking...");
}
}
Mammal mammal = Mammal("dog"); //playscript特别的构造方法,不需要new关键字
mammal.speak(); //访问对象方法
println("mammal.name = " + mammal.name); //访问对象的属性
//没有构造方法,创建的时候用缺省构造方法
class Bird{
int speed = 50; //在缺省构造方法里初始化
void fly(){
println("bird flying...");
}
}
Bird bird = Bird(); //采用缺省构造方法
println("bird.speed : " + bird.speed + "km/h");
bird.fly();
接下来,我们让playscript解释器处理这些看上去非常现代化的代码,怎么处理呢?
做完词法分析和语法分析之后,playscript会在语义分析阶段扫描AST,识别出所有自定义的类型,以便在其他地方引用这些类型来声明变量。因为类型的声明可以在代码中的任何位置,所以最好用单独的一次遍历来识别和记录类型(类型扫描的代码在TypeAndScopeScanner.java里)。
接着,我们在声明变量时,就可以引用这个类型了。
语义分析的另一个工作,就是做变量类型的消解。当我们声明“Bird bird = Bird(); ”时,需要知道Bird对象的定义在哪里,以便正确地访问它的成员(变量类型的消解在TypeResolver.java里)。
在做语义分析时,要把类型的定义保存在一个数据结构中,我们来实现一下:
public class Class extends Scope implements Type{
//...
}
public abstract class Scope extends Symbol{
// 该Scope中的成员,包括变量、方法、类等。
protected List<Symbol> symbols = new LinkedList<Symbol>(
}
public interface Type {
public String getName(); //类型名称
public Scope getEnclosingScope();
}
在这个设计中,我们看到Class就是一个Scope,Scope里面原来就能保存各种成员,现在可以直接复用,用来保存类的属性和方法,画成类图如下:
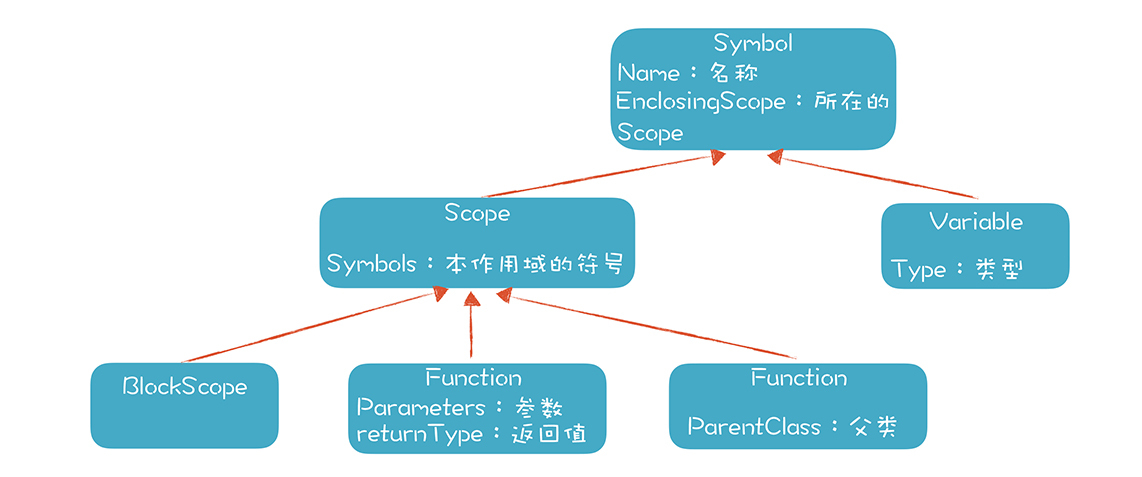
图里有几个类,比如Symbol、Variable、Scope、Function和BlockScope,它们是我们的符号体系的主要成员。在做词法分析时,我们会解析出很多标识符,这些标识符出现在不同的语法规则里,包括变量声明、表达式,以及作为类名、方法名等出现。
在语义分析阶段,我们要把这些标识符一一识别出来,这个是一个变量,指的是一个本地变量;那个是一个方法名等。
变量、类和函数的名称,我们都叫做符号,比如示例程序中的Mammal、Bird、mammal、bird、name、speed等。编译过程中的一项重要工作就是建立符号表,它帮助我们进一步地编译或执行程序,而符号表就用上面几个类来保存信息。
在符号表里,我们保存它的名称、类型、作用域等信息。对于类和函数,我们也有相应的地方来保存类变量、方法、参数、返回值等信息。你可以看一看示例代码里面是如何解析和记录这些符号的。
解析完这些语义信息以后,我们来看运行期如何执行具有面向对象特征的程序,
比如,如何实例化一个对象?如何在内存里管理对象的数据?以及如何访问对象的属性和方法?
对象是怎么实例化的
首先通过构造方法来创建对象。
在语法中,我们没有用new这个关键字来表示对象的创建,而是省略掉了new,直接调用一个跟类名称相同的函数,这是我们独特的设计,示例代码如下:
Mammal mammal = Mammal("dog"); //playscript特别的构造方法,不需要new关键字
Bird bird = Bird(); //采用缺省构造方法
但在语义检查的时候,在当前作用域中是肯定找不到这样一个函数的,因为类的初始化方法是在类的内部定义的,我们只要检查一下,Mammal和Bird是不是一个类名就可以了。
再进一步,Mammal类中确实有个构造方法Mammal(),而Bird类中其实没有一个显式定义的构造方法,但这并不意味着变量成员不会被初始化。
我们借鉴了Java的初始化机制,就是提供缺省初始化方法,在缺省初始化方法里,会执行对象成员声明时所做的初始化工作。所以,上面的代码里,我们调用Bird(),实际上就是调用了这个缺省的初始化方法。
无论有没有显式声明的构造方法,声明对象的成员变量时的初始化部分,一定会执行。对于Bird类,实际上就会执行“int speed = 50;”这个语句。
在RefResolver.java中做语义分析的时候,下面的代码能够检测出某个函数调用其实是类的构造方法,或者是缺省构造方法:
// 看看是不是类的构建函数,用相同的名称查找一个class
Class theClass = at.lookupClass(scope, idName);
if (theClass != null) {
function = theClass.findConstructor(paramTypes);
if (function != null) {
at.symbolOfNode.put(ctx, function);
}
//如果是与类名相同的方法,并且没有参数,那么就是缺省构造方法
else if (ctx.expressionList() == null){
at.symbolOfNode.put(ctx, theClass); // TODO 直接赋予class
}
else{
at.log("unknown class constructor: " + ctx.getText(), ctx);
}
at.typeOfNode.put(ctx, theClass); // 这次函数调用是返回一个对象
}
当然,类的构造方法跟普通函数还是有所不同的,例如我们不允许构造方法定义返回值,因为它的返回值一定是这个类的一个实例对象。
对象做了缺省初始化以后,再去调用显式定义的构造方法,这样才能完善整个对象实例化的过程。不过问题来了,我们可以把普通的本地变量的数据保存在栈里,那么如何保存对象的数据呢?
如何在内存里管理对象的数据
其实,我们也可以把对象的数据像其他数据一样,保存在栈里。
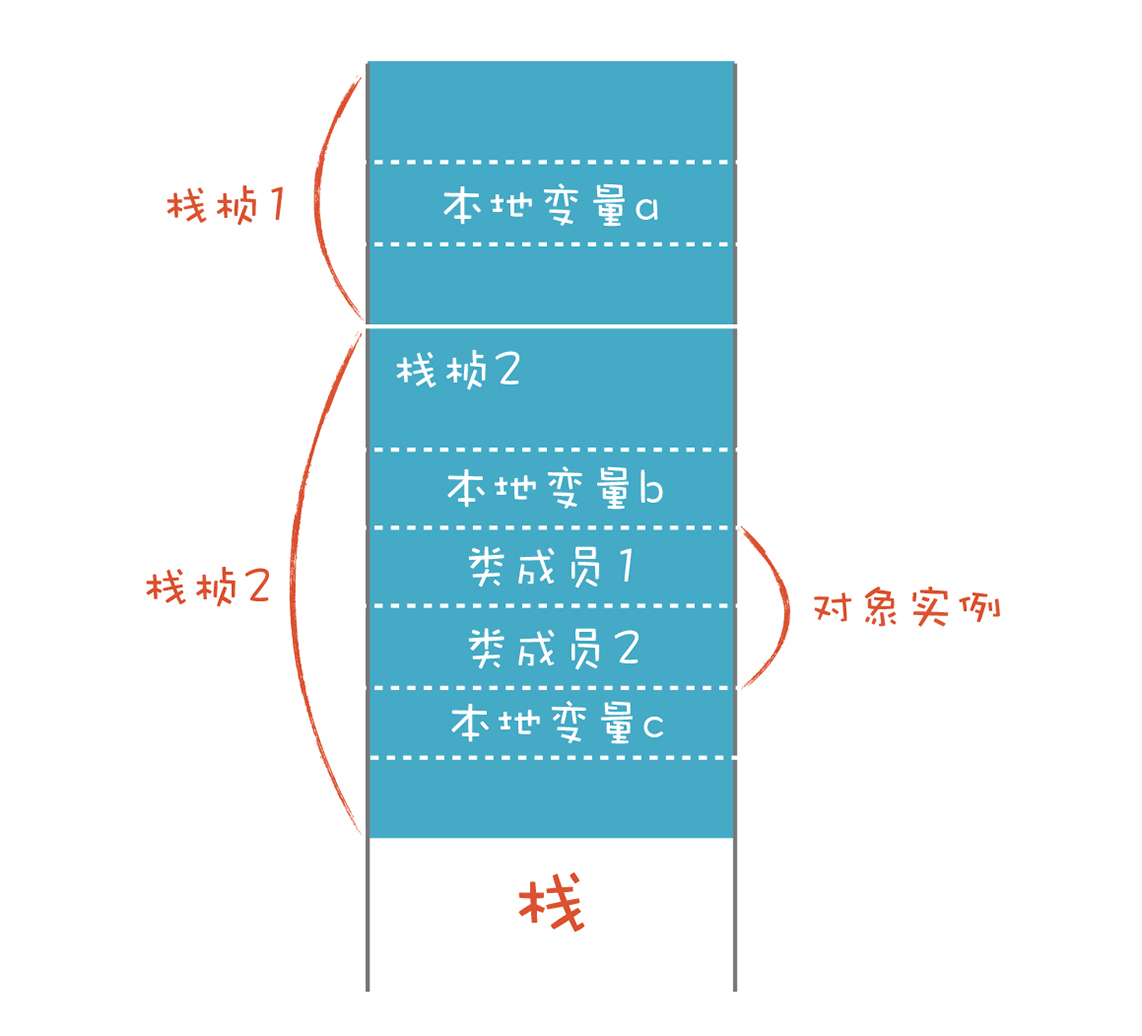
C语言的结构体struct和C++语言的对象,都可以保存在栈里。保存在栈里的对象是直接声明并实例化的,而不是用new关键字来创建的。如果用new关键字来创建,实际上是在堆里申请了一块内存,并赋值给一个指针变量,如下图所示:
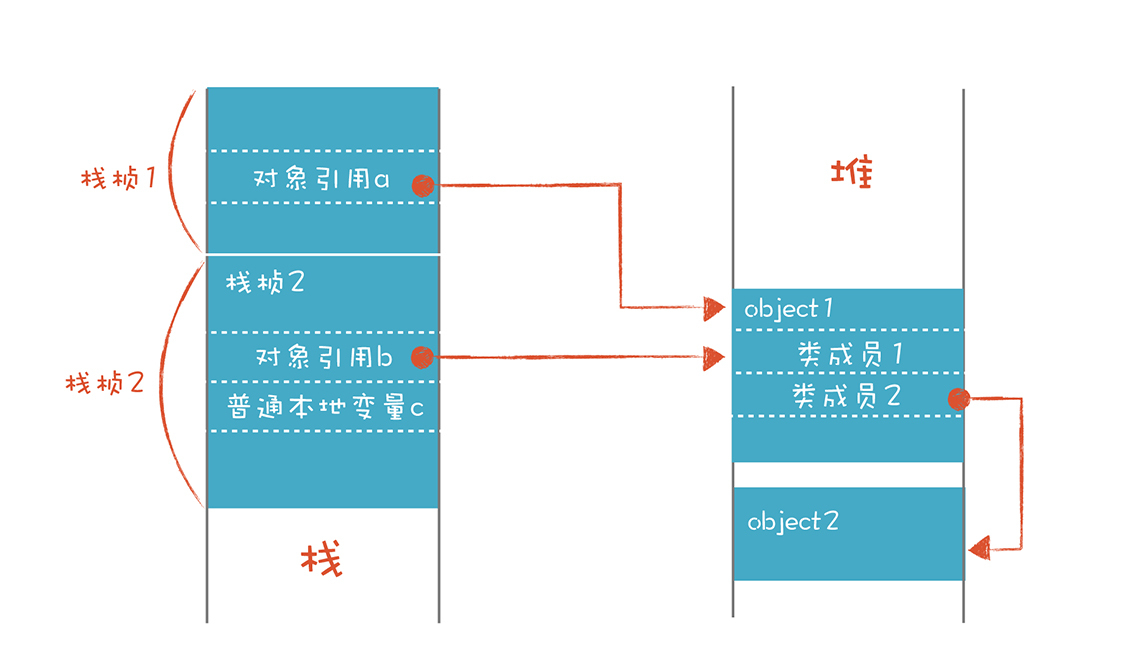
当对象保存在堆里的时候,可以有多个变量都引用同一个对象,比如图中的变量a和变量b就可以引用同一个对象object1。类的成员变量也可以引用别的对象,比如object1中的类成员引用了object2对象。对象的生存期可以超越创建它的栈桢的生存期。
我们可以对比一下这两种方式的优缺点。
如果对象保存在栈里,那么它的生存期与作用域是一样的,可以自动的创建和销毁,因此不需要额外的内存管理。缺点是对象没办法长期存在并共享。而在堆里创建的对象虽然可以被共享使用,却增加了内存管理的负担。
所以在C语言和C++语言中,要小心管理从堆中申请的内存,在合适的时候释放掉这些内存。在Java语言和其他一些语言中,采用的是垃圾收集机制,也就是说当一个对象不再被引用时,就把内存收集回来。
分析到这儿的时候,我们其实可以帮Java语言优化一下内存管理。比如我们在分析代码时,如果发现某个对象的创建和使用都局限在某个块作用域中,并没有跟其他作用域共享,那么这个对象的生存期与当前栈桢是一致的,可以在栈里申请内存,而不是在堆里。这样可以免除后期的垃圾收集工作。
分析完对象的内存管理方式之后,回到playscript的实现。在playscrip的Java版本里,我们用一个ClassObject对象来保存对象数据,而ClassObject是PlayObject的子类。我们已经讲过PlayObject,它被栈桢用来保存本地变量,可以通过传入Variable来访问对象的属性值:
//类的实例
public class ClassObject extends PlayObject{
//类型
protected Class type = null;
...
}
//保存对象数据
public class PlayObject {
//成员变量
protected Map<Variable, Object> fields = new HashMap<Variable, Object>();
public Object getValue(Variable variable){
Object rtn = fields.get(variable);
return rtn;
}
public void setValue(Variable variable, Object value){
fields.put(variable, value);
}
}
在运行期,当需要访问一个对象时,我们也会用ClassObject来做一个栈桢,这样就可以像访问本地变量一样访问对象的属性了。而不需要访问这个对象的时候,就把它从栈中移除,如果没有其他对象引用这个对象,那么它会被Java的垃圾收集机制回收。
访问对象的属性和方法
在示例代码中,我们用点操作符来访问对象的属性和方法,比如:
mammal.speak(); //访问对象方法
println("mammal.name = " + mammal.name); //访问对象的属性
属性和方法的引用也是一种表达式,语法定义如下:
expression
: ...
| expression bop='.'
( IDENTIFIER //对象属性
| functionCall //对象方法
)
...
;
注意,点符号的操作可以是级联的,比如:
obj1.obj2.field1;
obj1.getObject2().field1;
所以,对表达式的求值,要能够获得正确的对象引用,你可以运行一下ClassTest.play脚本。
另外,对象成员还可以设置可见性。也就是说,有些成员只有对象内部才能用,有些可以由外部访问。这个怎么实现呢?
这只是个语义问题,是在编译阶段做语义检查的时候,不允许私有的成员被外部访问,报编译错误就可以了,在其他方面,并没有什么不同。
总结
我们针对面向对象的封装特性,从类型、作用域和生存期的角度进行了重新解读,这样能够更好地把握面向对象的本质特征。我们还设计了与面向对象的相关的语法并做了解析,然后讨论了面向对象程序的运行期机制,例如如何实例化一个对象,如何在内存里管理对象的数据,以及如何访问对象的属性和方法。
通过对类的语法和语义的剖析和运行机制的落地,我相信你会对面向对象的机制有更加本质的认识,也能更好地使用语言的面向对象特性了。
闭包:理解了原理,它就不反直觉了
在JavaScript中,用外层函数返回一个内层函数之后,这个内层函数能一直访问外层函数中的本地变量。按理说,这个时候外层函数已经退出了,它里面的变量也该作废了。可闭包却非常执着,即使外层函数已经退出,但内层函数仿佛不知道这个事实一样,还继续访问外层函数中声明的变量,并且还真的能够正常访问。
不过,闭包是很有用的,对库的编写者来讲,它能隐藏内部实现细节;对面试者来讲,它几乎是前端面试必问的一个问题,比如如何用闭包特性实现面向对象编程?等等。
闭包的内在矛盾
来测试一下JavaScript的闭包特性:
/**
* clojure.js
* 测试闭包特性
* 作者:宫文学
*/
var a = 0;
var fun1 = function(){
var b = 0; // 函数内的局部变量
var inner = function(){ // 内部的一个函数
a = a+1;
b = b+1;
return b; // 返回内部的成员
}
return inner; // 返回一个函数
}
console.log("outside: a=%d", a);
var fun2 = fun1(); // 生成闭包
for (var i = 0; i< 2; i++){
console.log("fun2: b=%d a=%d",fun2(), a); //通过fun2()来访问b
}
var fun3 = fun1(); // 生成第二个闭包
for (var i = 0; i< 2; i++){
console.log("fun3: b=%d a=%d",fun3(), a); // b等于1,重新开始
}
在Node.js环境下运行上面这段代码的结果如下:
outside: a=0
fun2: b=1 a=1
fun2: b=2 a=2
fun3: b=1 a=3
fun3: b=2 a=4
观察这个结果,可以得出两点:
- 内层的函数能访问它“看得见”的变量,包括自己的本地变量、外层函数的变量b和全局变量a。
- 内层函数作为返回值赋值给其他变量以后,外层函数就结束了,但内层函数仍能访问原来外层函数的变量b,也能访问全局变量a。
这样似乎让人感到困惑:站在外层函数的角度看,明明这个函数已经退出了,变量b应该失效了,为什么还可以继续访问?
但是如果换个立场,站在inner这个函数的角度来看,声明inner函数的时候,告诉它可以访问b,不能因为把inner函数赋值给了其他变量,inner函数里原本正确的语句就不能用了啊。
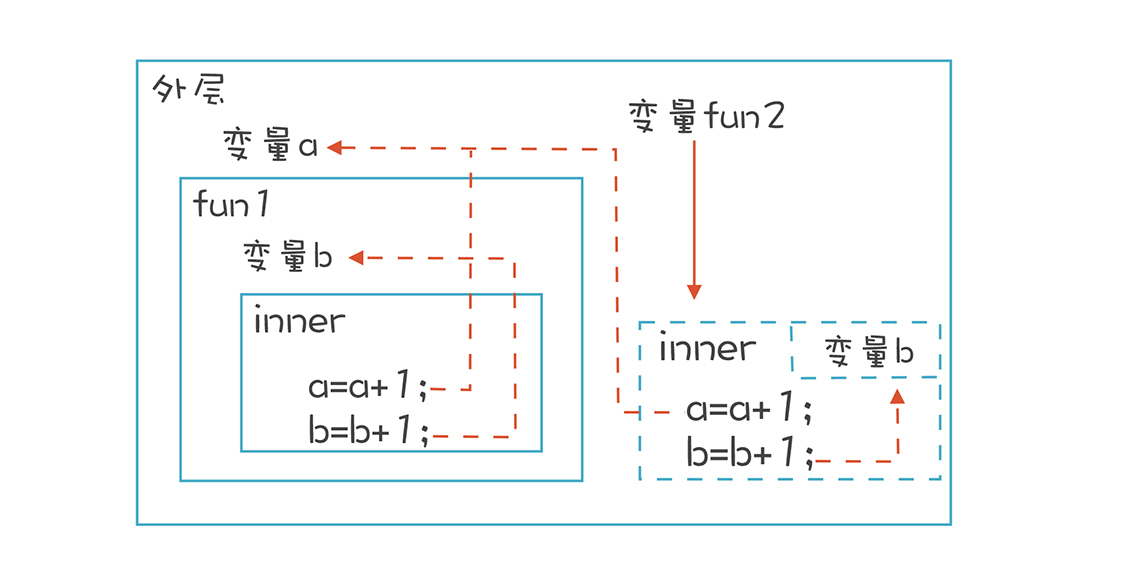
其实,只要函数能作为值传来传去,就一定会产生作用域不匹配的情况,这样的内在矛盾是语言设计时就决定了的。可以认为,闭包是为了让函数能够在这种情况下继续运行所提供的一个方案。这个方案有一些不错的特点,比如隐藏函数所使用的数据,歪打正着反倒成了一个优点了!
在这里,我想补充一下静态作用域(Static Scope)这个知识点,如果一门语言的作用域是静态作用域,那么符号之间的引用关系能够根据程序代码在编译时就确定清楚,在运行时不会变。某个函数是在哪声明的,就具有它所在位置的作用域。它能够访问哪些变量,那么就跟这些变量绑定了,在运行时就一直能访问这些变量。
看一看下面的代码,对于静态作用域而言,无论在哪里调用foo()函数,访问的变量i都是全局变量:
int i = 1;
void foo(){
println(i); // 访问全局变量
}
foo(); // 访问全局变量
void bar(){
int i = 2;
foo(); // 在这里调用foo(),访问的仍然是全局变量
}
我们目前使用的大多数语言都是采用静态作用域的。playscript语言也是在编译时就形成一个Scope的树,变量的引用也是在编译时就做了消解,不再改变,所以也是采用了静态作用域。
反过来讲,如果在bar()里调用foo()时,foo()访问的是bar()函数中的本地变量i,那就说明这门语言使用的是动态作用域(Dynamic Scope)。也就是说,变量引用跟变量声明不是在编译时就绑定死了的。在运行时,它是在运行环境中动态地找一个相同名称的变量。在macOS或Linux中用的bash脚本语言,就是动态作用域的。
静态作用域可以由程序代码决定,在编译时就能完全确定,所以又叫做词法作用域(Lexcical Scope)。不过这个词法跟我们做词法分析时说的词法不大一样。这里,跟Lexical相对应的词汇可以认为是Runtime,一个是编写时,一个是运行时。
用静态作用域的概念描述一下闭包,我们可以这样说:因为我们的语言是静态作用域的,它能够访问的变量,需要一直都能访问,为此,需要把某些变量的生存期延长。
当然了,闭包的产生还有另一个条件,就是让函数成为一等公民。这是什么意思?我们又怎样实现呢?
函数作为一等公民
在JavaScript和Python等语言里,函数可以像数值一样使用,比如给变量赋值、作为参数传递给其他函数,作为函数返回值等等。这时,我们就说函数是一等公民。
作为一等公民的函数很有用,比如它能处理数组等集合。我们给数组的map方法传入一个回调函数,结果会生成一个新的数组。整个过程很简洁,没有出现啰嗦的循环语句,这也是很多人提倡函数式编程的原因之一:
var newArray = ["1","2","3"].map(
fucntion(value,index,array){
return parseInt(value,10)
})
那么在playscript中,怎么把函数作为一等公民呢?
我们需要支持函数作为基础类型,这样就可以用这种类型声明变量。但问题来了,如何声明一个函数类型的变量呢?
在JavaScript这种动态类型的语言里,我们可以把函数赋值给任何一个变量,就像前面示例代码里的那样:inner函数作为返回值,被赋给了fun2和fun3两个变量。
然而在Go语言这样要求严格类型匹配的语言里,就比较复杂了:
type funcType func(int) int // Go语言,声明了一个函数类型funcType
var myFun funType // 用这个函数类型声明了一个变量
它对函数的原型有比较严格的要求:函数必须有一个int型的参数,返回值也必须是int型的。
而C语言中函数指针的声明也是比较严格的,在下面的代码中,myFun指针能够指向一个函数,这个函数也是有一个int类型的参数,返回值也是int:
int (*myFun) (int); //C语言,声明一个函数指针
playscript也采用这种比较严格的声明方式,因为我们想实现一个静态类型的语言:
function int (int) myFun; //playscript中声明一个函数型的变量
写成上面这样是因为个人喜欢把变量名称左边的部分看做类型的描述,不像Go语言把类型放在变量名称后面。最难读的就是C语言那种声明方式了,竟然把变量名放在了中间。当然,这只是个人喜好。
把上面描述函数类型的语法写成Antlr的规则如下:
functionType
: FUNCTION typeTypeOrVoid '(' typeList? ')'
;
typeList
: typeType (',' typeType)*
;
在playscript中,我们用FuntionType接口代表一个函数类型,通过这个接口可以获得返回值类型、参数类型这两个信息:
package play;
import java.util.List;
/**
* 函数类型
*/
public interface FunctionType extends Type {
public Type getReturnType(); //返回值类型
public List<Type> getParamTypes(); //参数类型
}
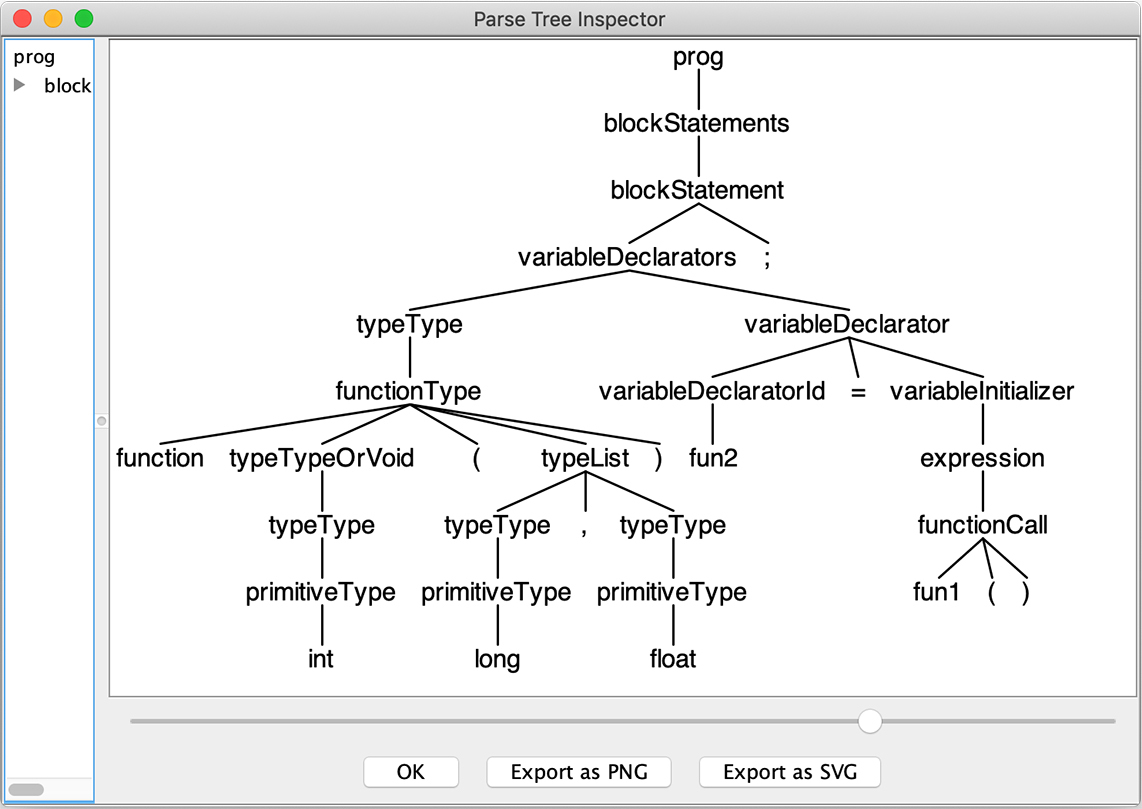
试一下实际使用效果如何,用Antlr解析下面这句的语法:
function int(long, float) fun2 = fun1();
它的意思是:调用fun1()函数会返回另一个函数,这个函数有两个参数,返回值是int型的。
我们用grun显示一下AST,你可以看到,它已经把functionType正确地解析出来了:
目前,我们只是设计完了语法,还要实现运行期的功能,让函数真的能像数值一样传来传去,就像下面的测试代码,它把foo()作为值赋给了bar():
/*
FirstClassFunction.play 函数作为一等公民。
也就是函数可以数值,赋给别的变量。
支持函数类型,即FunctionType。
*/
int foo(int a){
println("in foo, a = " + a);
return a;
}
int bar (function int(int) fun){
int b = fun(6);
println("in bar, b = " + b);
return b;
}
function int(int) a = foo; //函数作为变量初始化值
a(4);
function int(int) b;
b = foo; //函数用于赋值语句
b(5);
bar(foo); //函数做为参数
运行结果如下:
in foo, a = 4
in foo, a = 5
in foo, a = 6
in bar, b = 6
运行这段代码,你会发现它实现了用函数来赋值,而实现这个功能的重点,是做好语义分析。比如编译程序要能识别赋值语句中的foo是一个函数,而不是一个传统的值。在调用a()和b()的时候,它也要正确地调用foo()的代码,而不是报“找不到a()函数的定义”这样的错误。
实现了一等公民函数的功能以后,我们进入最重要的一环:实现闭包功能。
实现我们自己的闭包机制
在这之前,我想先设计好测试用例,所以先把一开始提到的那个JavaScript的例子用playscript的语法重写一遍,来测试闭包功能:
/**
* clojure.play
* 测试闭包特性
*/
int a = 0;
function int() fun1(){ //函数的返回值是一个函数
int b = 0; //函数内的局部变量
int inner(){ //内部的一个函数
a = a+1;
b = b+1;
return b; //返回内部的成员
}
return inner; //返回一个函数
}
function int() fun2 = fun1();
for (int i = 0; i< 3; i++){
println("b = " + fun2() + ", a = "+a);
}
function int() fun3 = fun1();
for (int i = 0; i< 3; i++){
println("b = " + fun3() + ", a = "+a);
}
代码的运行效果跟JavaScript版本的程序是一样的:
b = 1, a = 1
b = 2, a = 2
b = 3, a = 3
b = 1, a = 4
b = 2, a = 5
b = 3, a = 6
这段代码的AST让grun显示出来了,并截了一部分图,你可以直观地看一下外层函数和内层函数的关系:
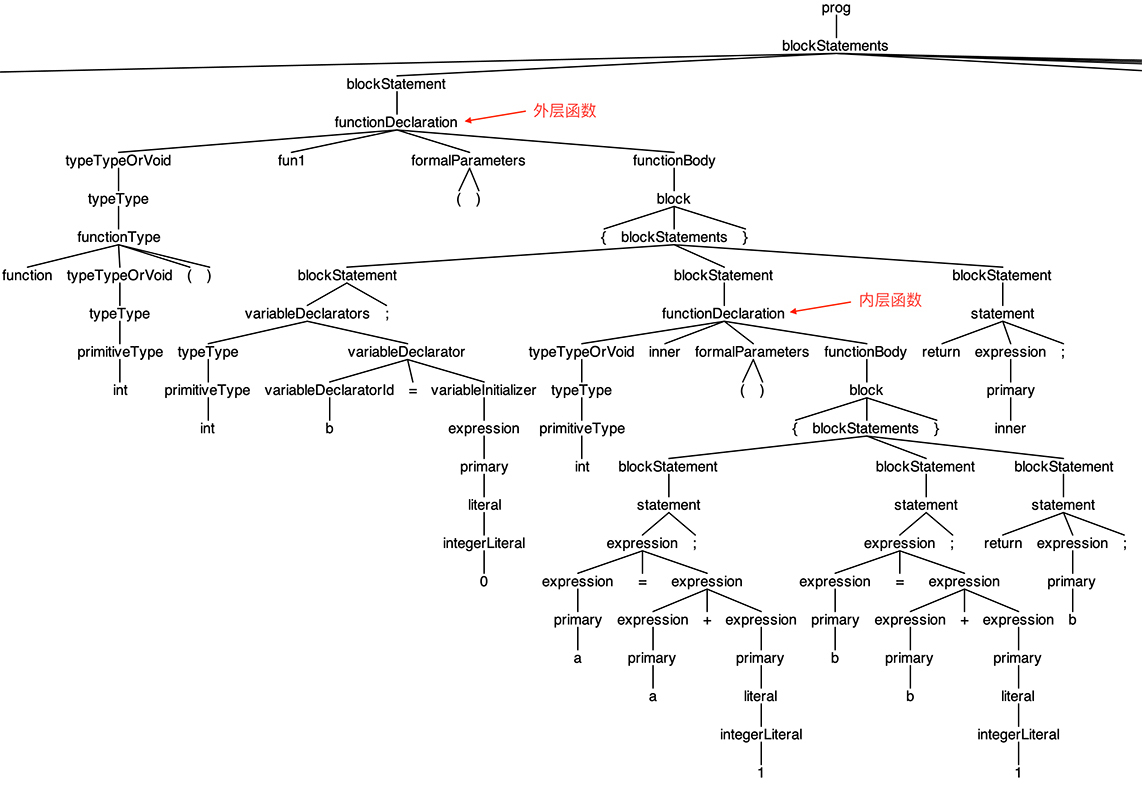
现在,测试用例准备好了,我们着手实现一下闭包的机制。
前面提到,闭包的内在矛盾是运行时的环境和定义时的作用域之间的矛盾。那么我们把内部环境中需要的变量,打包交给闭包函数,它就可以随时访问这些变量了。
在AST上做一下图形化的分析,看看给fun2这个变量赋值的时候,发生了什么事情:
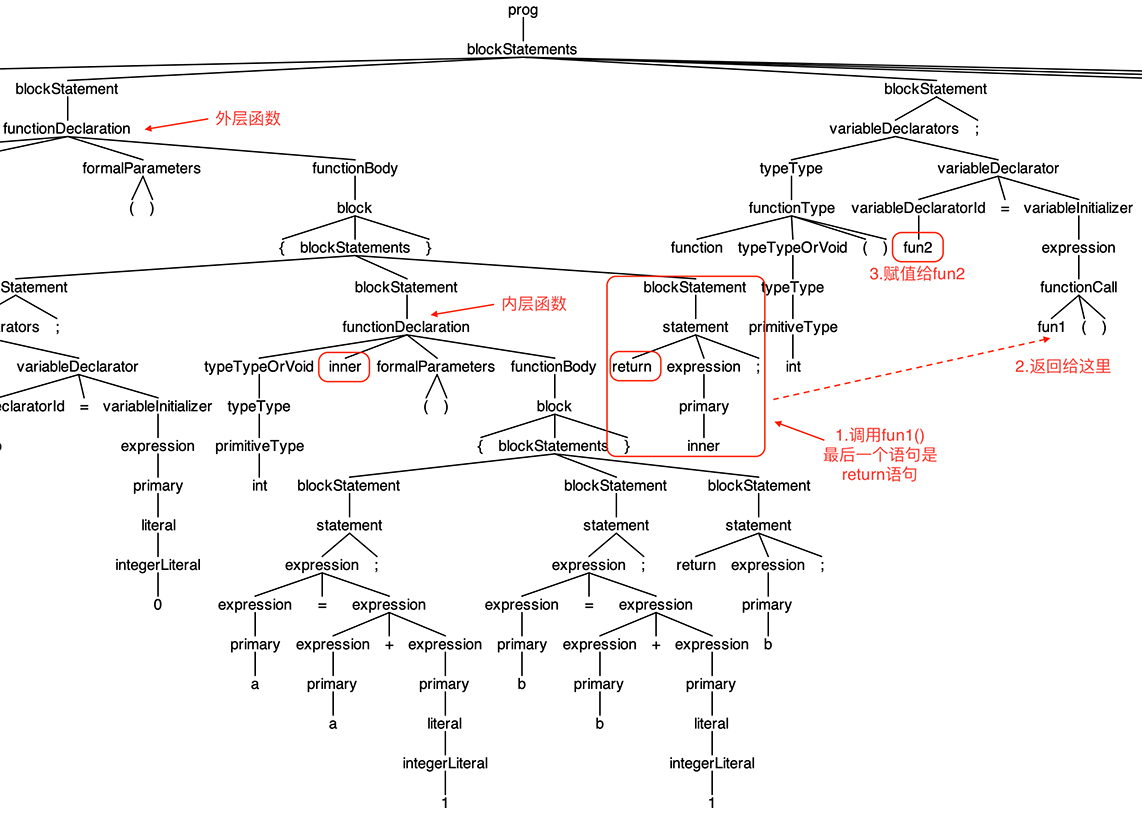
简单地描述一下给fun2赋值时的执行过程:
- 先执行fun1()函数,内部的inner()函数作为返回值返回给调用者。这时,程序能访问两层作用域,最近一层是fun1(),里面有变量b;外层还有一层,里面有全局变量a。这时是把环境变量打包的最后的机会,否则退出fun1()函数以后,变量b就消失了。
- 然后把内部函数连同打包好的环境变量的值,创建一个FunctionObject对象,作为fun1()的返回值,给到调用者。
- 给fun2这个变量赋值。
- 调用fun2()函数。函数执行时,有一个私有的闭包环境可以访问b的值,这个环境就是第二步所创建的FunctionObject对象。
最终,我们实现了闭包的功能。
在这个过程中,我们要提前记录下inner()函数都引用了哪些外部变量,以便对这些变量打包。这是在对程序做语义分析时完成的,你可以参考一下ClosureAnalyzer.java中的代码:
/**
* 为某个函数计算闭包变量,也就是它所引用的外部环境变量。
* 算法:计算所有的变量引用,去掉内部声明的变量,剩下的就是外部的。
* @param function
* @return
*/
private Set<Variable> calcClosureVariables(Function function){
Set<Variable> refered = variablesReferedByScope(function);
Set<Variable> declared = variablesDeclaredUnderScope(function);
refered.removeAll(declared);
return refered;
}
下面是ASTEvaluator.java中把环境变量打包进闭包中的代码片段,它是在当前的栈里获取数据的:
/**
* 为闭包获取环境变量的值
* @param function 闭包所关联的函数。这个函数会访问一些环境变量。
* @param valueContainer 存放环境变量的值的容器
*/
private void getClosureValues(Function function, PlayObject valueContainer){
if (function.closureVariables != null) {
for (Variable var : function.closureVariables) {
// 现在还可以从栈里取,退出函数以后就不行了
LValue lValue = getLValue(var);
Object value = lValue.getValue();
valueContainer.fields.put(var, value);
}
}
}
体验一下函数式编程
现在,我们已经实现了闭包的机制,函数也变成了一等公民。不经意间,我们似乎在一定程度上支持了函数式编程(functional programming)。
它是一种语言风格,有很多优点,比如简洁、安全等。备受很多程序员推崇的LISP语言就具备函数式编程特征,Java等语言也增加了函数式编程的特点。
函数式编程的一个典型特点就是高阶函数(High-order function)功能,高阶函数是这样一种函数,它能够接受其他函数作为自己的参数,javascript中数组的map方法,就是一个高阶函数。我们通过下面的例子测试一下高阶函数功能:
/**
LinkedList.play
实现了一个简单的链表,并演示了高阶函数的功能,比如在javascript中常用的map功能,
它能根据遍历列表中的每个元素,执行一个函数,并返回一个新的列表。给它传不同的函数,会返回不同的列表。
*/
//链表的节点
class ListNode{
int value;
ListNode next; //下一个节点
ListNode (int v){
value = v;
}
}
//链表
class LinkedList{
ListNode start;
ListNode end;
//添加新节点
void add(int value){
ListNode node = ListNode(value);
if (start == null){
start = node;
end = node;
}
else{
end.next = node;
end = node;
}
}
//打印所有节点内容
void dump(){
ListNode node = start;
while (node != null){
println(node.value);
node = node.next;
}
}
//高阶函数功能,参数是一个函数,对每个成员做一个计算,形成一个新的LinkedList
LinkedList map(function int(int) fun){
ListNode node = start;
LinkedList newList = LinkedList();
while (node != null){
int newValue = fun(node.value);
newList.add(newValue);
node = node.next;
}
return newList;
}
}
//函数:平方值
int square(int value){
return value * value;
}
//函数:加1
int addOne(int value){
return value + 1;
}
LinkedList list = LinkedList();
list.add(2);
list.add(3);
list.add(5);
println("original list:");
list.dump();
println();
println("add 1 to each element:");
LinkedList list2 = list.map(addOne);
list2.dump();
println();
println("square of each element:");
LinkedList list3 = list.map(square);
list3.dump();
运行后得到的结果如下:
original list:
2
3
5
add 1 to each element:
3
4
6
square of each element:
4
9
25
高阶函数功能很好玩,你可以修改程序,好好玩一下。
总结
闭包这个概念,对于初学者来讲是一个挑战。
其实,闭包就是把函数在静态作用域中所访问的变量的生存期拉长,形成一份可以由这个函数单独访问的数据。正因为这些数据只能被闭包函数访问,所以也就具备了对信息进行封装、隐藏内部细节的特性。
听上去是不是有点儿耳熟?
封装,把数据和对数据的操作封在一起,这不就是面向对象编程嘛!一个闭包可以看做是一个对象。反过来看,一个对象是不是也可以看做一个闭包呢?对象的属性,也可以看做被方法所独占的环境变量,其生存期也必须保证能够被方法一直正常的访问。
两个不相干的概念,在用作用域和生存期这样的话语体系去解读之后,就会很相似,在内部实现上也可以当成一回事。现在,你应该更清楚了吧?
语义分析(上):如何建立一个完善的类型系统?
在做语法分析时我们可以得到一棵语法树,而基于这棵树能做什么,是语义的事情。比如,+号的含义是让两个数值相加,并且通常还能进行缺省的类型转换。所以,如果要区分不同语言的差异,不能光看语言的语法。比如Java语言和JavaScript在代码块的语法上是一样的,都是用花括号,但在语义上是不同的,一个有块作用域,一个没有。
这样看来,相比词法和语法的设计与处理,语义设计和分析似乎要复杂很多。虽然我们借作用域、生存期、函数等特性的实现涉猎了很多语义分析的场景,但离系统地掌握语义分析,还差一点儿火候。所以,为了帮你攻破语义分析这个阶段,下面再梳理一下语义分析中的重要知识,让你更好地建立起相关的知识脉络。
这一节把注意力集中在类型系统这个话题上。
围绕类型系统产生过一些争论,有的程序员会拥护动态类型语言,有的会觉得静态类型语言好。要想探究这个问题,我们需要对类型系统有个清晰的了解,最直接的方式,就是建立一个完善的类型系统。
那么什么是类型系统?我们又该怎样建立一个完善的类型系统呢?
其实,类型系统是一门语言所有的类型的集合,操作这些类型的规则,以及类型之间怎么相互作用的(比如一个类型能否转换成另一个类型)。如果要建立一个完善的类型系统,形成对类型系统比较完整的认知,需要从两个方面出发:
- 根据领域的需求,设计自己的类型系统的特征。
- 在编译器中支持类型检查、类型推导和类型转换。
设计类型系统的特征
在进入这个话题之前,先问一个有意义的问题:类型到底是什么?我们说一个类型的时候,究竟在说什么?
要知道,在机器代码这个层面,其实是分不出什么数据类型的。在机器指令眼里,那就是0101,它并不对类型做任何要求,不需要知道哪儿是一个整数,哪儿代表着一个字符,哪儿又是内存地址。你让它做什么操作都可以,即使这个操作没有意义,比如把一个指针值跟一个字符相加。
那么高级语言为什么要增加类型这种机制呢?
对类型做定义很难,但大家公认的有一个说法:类型是针对一组数值,以及在这组数值之上的一组操作。比如,对于数字类型,你可以对它进行加减乘除算术运算,对于字符串就不行。
所以,类型是高级语言赋予的一种语义,有了类型这种机制,就相当于定了规矩,可以检查施加在数据上的操作是否合法。因此类型系统最大的好处,就是可以通过类型检查降低计算出错的概率。所以,现代计算机语言都会精心设计一个类型系统,而不是像汇编语言那样完全不区分类型。
不过,类型系统的设计有很多需要取舍和权衡的方面,比如:
- 面向对象的拥护者希望所有的类型都是对象,而重视数据计算性能的人认为应该支持非对象化的基础数据类型;
- 你想把字符串作为原生数据类型,还是像Java那样只是一个普通的类?
- 是静态类型语言好还是动态类型语言好?
- ……
虽然类型系统的设计有很多需要取舍和权衡的方面,但它最需要考虑的是,是否符合这门语言想解决的问题,我们用静态类型语言和动态类型语言分析一下。
根据类型检查是在编译期还是在运行期进行的,我们可以把计算机语言分为两类:
- 静态类型语言(全部或者几乎全部的类型检查是在编译期进行的)。
- 动态类型语言(类型的检查是在运行期进行的)。
静态类型语言的拥护者说:
因为编译期做了类型检查,所以程序错误较少,运行期不用再检查类型,性能更高。像C、Java和Go语言,在编译时就对类型做很多处理,包括检查类型是否匹配,以及进行缺省的类型转换,大大降低了程序出错的可能性,还能让程序运行效率更高,因为不需要在运行时再去做类型检查和转换。
而动态类型语言的拥护者说:
静态语言太严格,还要一遍遍编译,编程效率低,用动态类型语言方便进行快速开发。JavaScript、Python、PHP等都是动态类型的。
客观地讲,这些说法都有道理。目前的趋势是,
某些动态类型语言在想办法增加一些机制,在编译期就能做类型检查,比如用TypeScript代替JavaScript编写程序,做完检查后再输出成JavaScript。
而某些静态语言呢,却又发明出一些办法,部分地绕过类型检查,从而提供动态类型语言的灵活性。
再延伸一下,跟静态类型和动态类型概念相关联的,还有强类型和弱类型。
强类型语言中,变量的类型一旦声明就不能改变,弱类型语言中,变量类型在运行期时可以改变。
二者的本质区别是,强类型语言不允许违法操作,因为能够被检查出来,弱类型语言则从机制上就无法禁止违法操作,所以是不安全的。
比如你写了一个表达式a*b。如果a和b这两个变量是数值,这个操作就没有问题,但如果a或b不是数值,那就没有意义了,弱类型语言可能就检查不出这类问题。
也就是,静态类型和动态类型说的是什么时候检查的问题,强类型和弱类型说的是就算检查,也检查不出来,或者没法检查的问题,这两组概念经常会被搞混,所以我在这里带你了解一下。
接着说回来。关于类型特征的取舍,是根据领域问题而定的。举例来说,很多人可能都觉得强类型更好,但对于儿童编程启蒙来说,他们最好尽可能地做各种尝试,如果必须遵守与类型有关的规则,程序总是跑不起来,可能会打击到他们。
对于playscript而言,因为目前是用来做教学演示的,所以我们尽可能地多涉及与类型处理有关的情况,供大家体会算法,或者在自己的工作中借鉴。
-
首先,playscript是静态类型和强类型的,所以几乎要做各种类型检查,你可以参考看看这些都是怎么做的。
-
我们既支持对象,也支持原生的基础数据类型。这两种类型的处理特点不一样,你也可以借鉴一下。后面面向对象的一讲,我会再讲与之相关的子类型(Subtyping)和运行时类型信息(Run Time Type Information, RTTI)的概念,这里就不展开了。
-
我们还支持函数作为一等公民,也就是支持函数的类型。函数的类型是它的原型,包括返回值和参数,原型一样的函数,就看做是同样类型的,可以进行赋值。这样,你也就可以了解实现函数式编程特性时,要处理哪些额外的类型问题。
如何做类型检查、类型推导和类型转换
先来看一看,如果编写一个编译器,我们在做类型分析时会遇到哪些问题。以下面这个最简单的表达式为例,这个表达式在不同的情况下会有不同的运行结果:
a = b + 10
- 如果b是一个浮点型,b+10的结果也是浮点型。如果b是字符串型的,有些语言也是允许执行+号运算的,实际的结果是字符串的连接。这个分析过程,就是类型推导(Type Inference)。
- 当右边的值计算完,赋值给a的时候,要检查左右两边的类型是否匹配。这个过程,就是类型检查(Type Checking)。
- 如果a的类型是浮点型,而右边传过来的是整型,那么一般就要进行缺省的类型转换(Type Conversion)。
类型的检查、推导和转换是三个工作,可是采用的技术手段差不多,所以我们放在一起讲
类型的推导
在早期的playscript的实现中,是假设运算符两边的类型都是整型的,并做了强制转换。
这在实际应用中,当然不够用,因为我们还需要用到其他的数据类型。那怎么办呢?在运行时再去判断和转换吗?
当然可以,但我们还有更好的选择,就是在编译期先判断出表达式的类型来。比如下面这段代码,是在RefResolve.java中,推导表达式的类型:
case PlayScriptParser.ADD:
if (type1 == PrimitiveType.String || type2 == PrimitiveType.String){
type = PrimitiveType.String;
}
else if (type1 instanceof PrimitiveType &&
type2 instanceof PrimitiveType){
//类型“向上”对齐,比如一个int和一个float,取float
type = PrimitiveType.getUpperType(type1,type2);
}else{
at.log("operand should be PrimitiveType for additive operation", ctx);
}
break;
这段代码提到,如果操作符号两边有一边数据类型是String类型的,那整个表达式就是String类型的。如果是其他基础类型的,就要按照一定的规则进行类型的转换,并确定运算结果的类型。比如,+号一边是double类型的,另一边是int类型的,那就要把int型的转换成double型的,最后计算结果也是double类型的。
做了类型的推导以后,我们就可以简化运行期的计算,不需要在运行期做类型判断了:
private Object add(Object obj1, Object obj2, Type targetType) {
Object rtn = null;
if (targetType == PrimitiveType.String) {
rtn = String.valueOf(obj1) + String.valueOf(obj2);
} else if (targetType == PrimitiveType.Integer) {
rtn = ((Number)obj1).intValue() + ((Number)obj2).intValue();
} else if (targetType == PrimitiveType.Float) {
rtn = ((Number)obj1).floatValue() + ((Number)obj2).floatValue();
}
//...
return rtn;
}
通过这个类型推导的例子,我们又可以引出S属性(Synthesized Attribute)的知识点。
如果一种属性能够从下级节点推导出来,那么这种属性就叫做S属性,字面意思是综合属性,就是在AST中从下级的属性归纳、综合出本级的属性。更准确地说,是通过下级节点和自身来确定的。

与S属性相对应的是I属性(Inherited Attribute),也就是继承属性,即AST中某个节点的属性是由上级节点、兄弟节点和它自身来决定的,比如:
int a;
变量a的类型是int,这个很直观,因为变量声明语句中已经指出了a的类型,但这个类型可不是从下级节点推导出来的,而是从兄弟节点推导出来的。
在PlayScript.g4中,变量声明的相关语法如下:
variableDeclarators
: typeType variableDeclarator (',' variableDeclarator)*
;
variableDeclarator
: variableDeclaratorId ('=' variableInitializer)?
;
variableDeclaratorId
: IDENTIFIER ('[' ']')*
;
typeType
: (classOrInterfaceType| functionType | primitiveType) ('[' ']')*
;
把int a;这样一个简单的变量声明语句解析成AST,就形成了一棵有两个分枝的树:
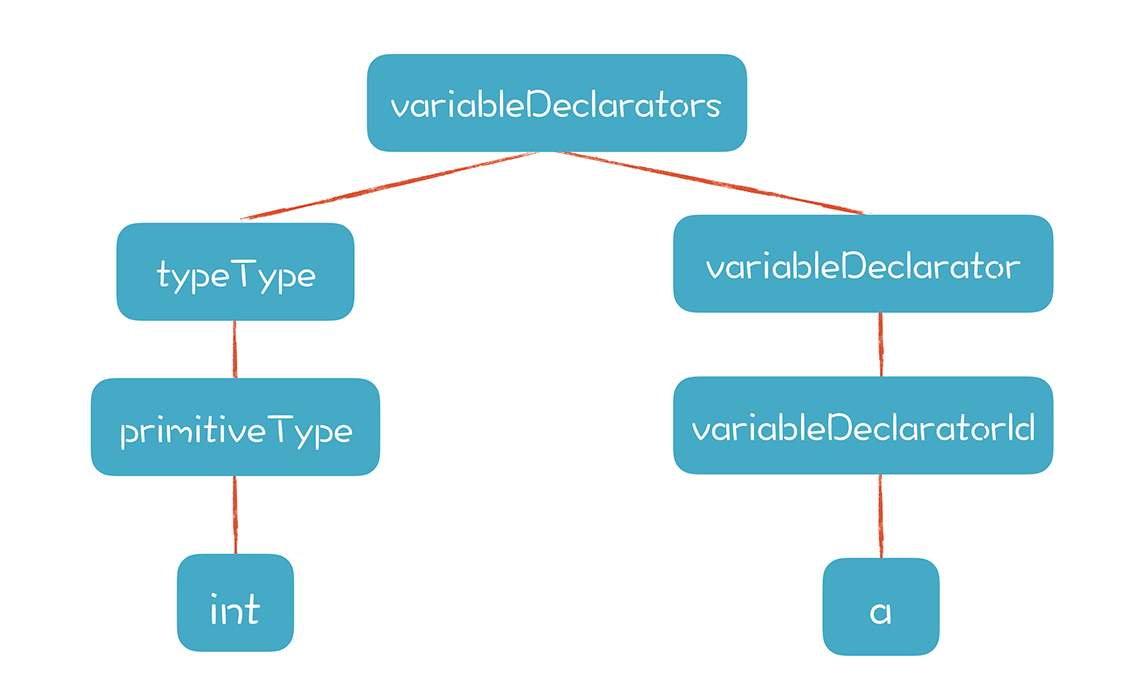
这棵树的左枝,可以从下向上推导类型,所以类型属性也就是S属性。而右枝则必须从根节点(也就是variableDeclarators)往下继承类型属性,所以对于a这个节点来说,它的类型属性是I属性。
这里插一句,RefResolver.java实现了PlayScriptListener接口。这样,我们可以用标准的方法遍历AST。代码中的enterXXX()方法表示刚进入这个节点,exitXXX()方法表示退出这个节点,这时所有的子节点都已经遍历过了。在计算S属性时,我一定是在exitXXX()方法中,因为可以利用下级节点的类型推导出自身节点的类型。
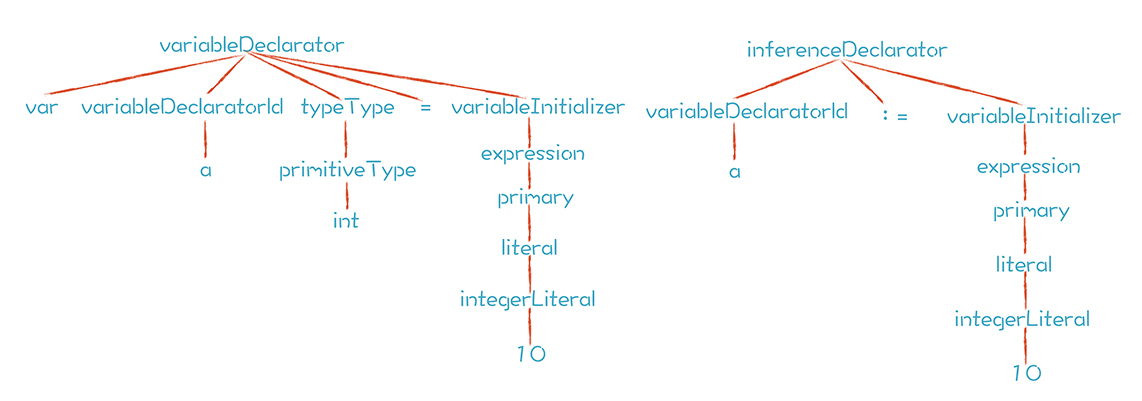
很多现代语言会支持自动类型推导,例如Go语言就有两种声明变量的方式:
var a int = 10 //第一种
a := 10 //第二种
第一种方式,a的类型是显式声明的;
第二种方式,a的类型是由右边的表达式推导出来的。
从生成的AST中,你能看到它们都是经历了从下到上的综合,再从上到下的继承的过程:
类型检查
类型检查主要出现在几个场景中:
- 赋值语句(检查赋值操作左边和右边的类型是否匹配)。
- 变量声明语句(因为变量声明语句中也会有初始化部分,所以也需要类型匹配)。
- 函数传参(调用函数的时候,传入的参数要符合形参的要求)。
- 函数返回值(从函数中返回一个值的时候,要符合函数返回值的规定)。
类型检查还有一个特点:以赋值语句为例,左边的类型,是I属性,是从声明中得到的;右边的类型是S属性,是自下而上综合出来的。当左右两边的类型相遇之后,就要检查二者是否匹配,被赋值的变量要满足左边的类型要求。
如果匹配,自然没有问题,如果不完全匹配,也不一定马上报错,而是要看看是否能进行类型转换。比如,一般的语言在处理整型和浮点型的混合运算时,都能进行自动的转换。像JavaScript和SQL,甚至能够在算术运算时,自动将字符串转换成数字。在MySQL里,运行下面的语句,会得到3,它自动将’2’转换成了数字:
select 1 + '2';
这个过程其实是有风险的,这就像在强类型的语言中开了一个后门,绕过或部分绕过了编译器的类型检查功能。把父类转成子类的场景中,编译器顶多能检查这两个类之间是否有继承关系,如果连继承关系都没有,这当然能检查出错误,制止这种转换。但一个基类的子类可能是很多的,具体这个转换对不对,只有到运行期才能检查出错误来。C语言因为可以强制做各种转换,这个后门开的就更大了。不过这也是C语言要达到它的设计目的,必须具备的特性。
关于类型的处理,大家可以参考playscript的示例代码,里面有三个类可以看一看:
- TypeResolver.java(做了自上而下的类型推导,也就是I属性的计算,包括变量- 声明、类的继承声明、函数声明)。
- RefResolver.java(有自下而上的类型推导的逻辑)。
- TypeChecker.java(类型检查)。
总结
本节课我们重点探讨了语义分析和语言设计中的一个重要话题:类型系统。
理解类型系统,了解它的本质对我们学习语言会有很大的帮助。我希望在这个过程中,你不会再被静态类型和动态类型,强类型和弱类型这样的概念难倒,甚至可以质疑已有的一些观念。比如,如果你仔细研究,会发现静态类型和动态类型不是绝对的,静态类型的语言如Java,也会在运行期去处理一些类型检查。强类型和弱类型可能也不是绝对的,就像C语言,你如果不允许做任何强制类型转换,不允许指针越界,那它也就完全变成强类型的了。
语义分析(下):如何做上下文相关情况的处理?
我们知道,词法分析和语法分析阶段,进行的处理都是上下文无关的。可仅凭上下文无关的处理,是不能完成一门强大的语言的。比如先声明变量,再用变量,这是典型的上下文相关的情况,我们肯定不能用上下文无关文法表达这种情况,所以语法分析阶段处理不了这个问题,只能在语义分析阶段处理。语义分析的本质,就是针对上下文相关的情况做处理。
我们之前讲到的作用域,是一种上下文相关的情况,因为如果作用域不同,能使用的变量也是不同的。类型系统也是一种上下文相关的情况,类型推导和类型检查都要基于上下文中相关的AST节点。
下面讲两个这样的场景:引用的消解、左值和右值,然后再介绍上下文相关情况分析的一种方法:属性计算。这样,你会把语义分析就是上下文处理的本质掌握得更清楚,并掌握属性计算这个强大的方法。
语义分析场景:引用的消解
在程序里使用变量、函数、类等符号时,我们需要知道它们指的是谁,要能对应到定义它们的地方。下面的例子中,当使用变量a时,我们需要知道它是全局变量a,还是fun()函数中的本地变量a。因为不同作用域里可能有相同名称的变量,所以必须找到正确的那个。这个过程,可以叫引用消解。
/*
scope.c
测试作用域
*/
#include <stdio.h>
int a = 1;
void fun()
{
a = 2; //这是指全局变量a
int a = 3; //声明一个本地变量
int b = a; //这个a指的是本地变量
printf("in func: a=%d b=%d \n", a, b);
}
在集成开发环境中,当我们点击一个变量、函数或类,可以跳到定义它的地方。另一方面,当我们重构一个变量名称、方法名称或类名称的时候,所有引用它的地方都会同步修改。这是因为IDE分析了符号之间的交叉引用关系。
函数的引用消解比变量的引用消解还要更复杂一些。
它不仅要比对函数名称,还要比较参数和返回值(可以叫函数原型,又或者叫函数的类型)。我们在把函数提升为一等公民的时候,提到函数类型(FunctionType)的概念。两个函数的类型相同,需要返回值、参数个数、每个参数的类型都能匹配得上才行。
在面向对象编程语言中,函数引用的消解也很复杂。
当一个参数需要一个对象的时候,程序中提供其子类的一个实例也是可以的,也就是子类可以用在所有需要父类的地方,例如下面的代码:
class MyClass1{} //父类
class MyClass2 extends MyClass1{} //子类
MyClass1 obj1;
MyClass2 obj2;
function fun(MyClass1 obj){} //参数需要父类的实例
fun(obj2); //提供子类的实例
在C++语言中,引用的消解还要更加复杂。
它还要考虑某个实参是否能够被自动转换成形参所要求的类型,比如在一个需要double类型的地方,你给它传一个int也是可以的。
命名空间也是做引用消解的时候需要考虑的因素。
像Java、C++都支持命名空间。如果在代码前头引入了某个命名空间,我们就可以直接引用里面的符号,否则需要冠以命名空间。例如:
play.PlayScriptCompiler.Compile() //Java语言
play::PlayScriptCompiler.Compile() //C++语言
而做引用消解可能会产生几个结果:
- 解析出了准确的引用关系。
- 重复定义(在声明新的符号的时候,发现这个符号已经被定义过了)。
- 引用失败(找不到某个符号的定义)。
- 如果两个不同的命名空间中都有相同名称的符号,编程者需要明确指定。
在playscript中,引用消解的结果被存到了AnnotatedTree.java类中的symbolOfNode属性中去了,从它可以查到某个AST节点引用的到底是哪个变量或函数,从而在运行期正确的执行,你可以看一下代码,了解引用消解和使用的过程。
语义分析场景:左值和右值
在开发编译器或解释器的过程中,你一定会遇到左值和右值的问题。比如,在playscript的ASTEvaluate.java中,我们在visitPrimary节点可以对变量求值。如果是下面语句中的a,没有问题,把a变量的值取出来就好了:
a + 3;
可是,如果针对的是赋值语句,a在等号的左边,怎么对a求值呢?
a = 3;
假设a变量原来的值是4,如果还是把它的值取出来,那么成了3=4,这就变得没有意义了。所以,不能把a的值取出来,而应该取出a的地址,或者说a的引用,然后用赋值操作把3这个值写到a的内存地址。这时,我们说取出来的是a的左值(L-value)。
左值最早是在C语言中提出的,通常出现在表达式的左边,如赋值语句的左边。左值取的是变量的地址(或者说变量的引用),获得地址以后,我们就可以把新值写进去了。
与左值相对应的就是右值(R-value),右值就是我们通常所说的值,不是地址。
在上面这两种情况下,变量a在AST中都是对应同一个节点,也就是primary节点。那这个节点求值时是该返回左值还是右值呢?
这要借助上下文来分析和处理。如果这个primary节点存在于下面这几种情况中,那就需要取左值:
- 赋值表达式的左边;
- 带有初始化的变量声明语句中的变量;
- 当给函数形参赋值的时候;
- 一元操作符: ++和––。
- 其他需要改变变量内容的操作。
在讨论primary节点在哪种情况下取左值时,我们可以引出另一个问题:不是所有的表达式,都能生成一个合格的左值。也就是说,出现在赋值语句左边的,必须是能够获得左值的表达式。
比如一个变量是可以的,一个类的属性也是可以的。但如果是一个常量,或者2+3这样的表达式在赋值符号的左边,那就不行。所以,判断表达式能否生成一个合格的左值也是语义检查的一项工作。
借讲过的S属性和I属性的概念,我们把刚才说的两个情况总结成primay节点的两个属性,你可以判断一下,这两个属性是S属性还是I属性?
- 属性1:某primary节点求值时,是否应该求左值?
- 属性2:某primary节点求值时,能否求出左值?
你可能发现了,这跟我们类型检查有点儿相似,一个是I属性,一个是S属性,两个一比对,就能检查求左值的表达式是否合法。从这儿我们也能看出,处理上下文相关的情况,经常用属性计算的方法。接下来,我们就谈谈如何做属性计算。
如何做属性计算。
属性计算是做上下文分析,或者说语义分析的一种算法。按照属性计算的视角,我们之前所处理的各种语义分析问题,都可以看做是对AST节点的某个属性进行计算。比如,针对求左值场景中的primary节点,它需要计算的属性包括:
- 它的变量定义是哪个(这就引用到定义该变量的Symbol)。
- 它的类型是什么?
- 它的作用域是什么?
- 这个节点求值时,是否该返回左值?能否正确地返回一个左值?
- 它的值是什么?
从属性计算的角度看,对表达式求值,或运行脚本,只是去计算AST节点的Value属性,Value这个属性能够计算,其他属性当然也能计算。
属性计算需要用到属性文法。在词法、语法分析阶段,我们分别学习了正则文法和上下文无关文法,在语义分析阶段我们要了解的是属性文法(Attribute Grammar)。
属性文法的主要思路是计算机科学的重要开拓者,高德纳(Donald Knuth)在《The Genesis of Attribute Grammers》中提出的。它是在上下文无关文法的基础上做了一些增强,使之能够计算属性值。下面是上下文无关文法表达加法和乘法运算的例子:
add → add + mul
add → mul
mul → mul * primary
mul → primary
primary → "(" add ")"
primary → integer
然后看一看对value属性进行计算的属性文法:
add1 → add1 + mul [ add1.value = add2.value + mul.value ]
add → mul [ add.value = mul.value ]
mul1 → mul2 * primary [ mul1.value = mul2.value * primary.value ]
mul → primary [ mul.value = primary.value ]
primary → "(" add ")" [ primary.value = add.value ]
primary → integer [ primary.value = strToInt(integer.str) ]
利用属性文法,我们可以定义规则,然后用工具自动实现对属性的计算。
“我们解析表达式2+3的时候,得到一个AST,但我怎么知道它运算的时候是做加法呢?”
因为我们可以在语法规则的基础上制定属性文法,在解析语法的过程中或者形成AST之后,我们就可以根据属性文法的规则做属性计算。
比如在Antlr中,你可以在语法规则文件中插入一些代码,在语法分析的过程中执行你的代码,完成一些必要的计算。
总结一下属性计算的特点:它会基于语法规则,增加一些与语义处理有关的规则。
所以,我们也把这种语义规则的定义叫做语法制导的定义(Syntax directed definition,SDD),如果变成计算动作,就叫做语法制导的翻译(Syntax directed translation,SDT)。
属性计算,可以伴随着语法分析的过程一起进行,也可以在做完语法分析以后再进行。这两个阶段不一定完全切分开。甚至,我们有时候会在语法分析的时候做一些属性计算,然后把计算结果反馈回语法分析的逻辑,帮助语法分析更好地执行(这是在工程实践中会运用到的一个技巧)。
那么,在解析语法的时候,如何同时做属性计算呢?
我们知道,解析语法的过程,是逐步建立AST的过程。在这个过程中,计算某个节点的属性所依赖的其他节点可能被创建出来了。
比如在递归下降算法中,当某个节点建立完毕以后,它的所有子节点一定也建立完毕了,所以S属性就可以计算出来了。同时,因为语法解析是从左向右进行的,它左边的兄弟节点也都建立起来了。
如果某个属性的计算,除了可能依赖子节点以外,只依赖左边的兄弟节点,不依赖右边的,这种属性就叫做L属性。它比S属性的范围更大一些,包含了部分的I属性。由于我们常用的语法分析的算法都是从左向右进行的,所以就很适合一边解析语法,一边计算L属性。
比如,C语言和Java语言进行类型分析,都可以用L属性的计算来实现。因为这两门语言的类型要么是从下往上综合出来的,属于S属性。要么是在做变量声明的时候,由声明中的变量类型确定的,类型节点在变量的左边。
2+3; //表达式类型是整型
float a; //a的类型是浮点型
那问题来了,Go语言的类型声明是放在变量后面的,这意味着类型节点一定是在右边的,那就不符合L属性文法了:
var a int = 10
没关系,我们没必要在语法分析阶段把属性全都计算出来,等到语法分析完毕后,再对AST遍历一下就好了。这时所有节点都有了,计算属性也就不是难事了。
在我们的playscript语言里,就采取了这种策略,实际上,为了让算法更清晰,把语义分析过程拆成了好几个任务,对AST做了多次遍历。
第1遍:类型和作用域解析(TypeAndScopeScanner.java)。
把自定义类、函数和和作用域的树都分析出来。这么做的好处是,你可以使用在前,声明在后。
比如你声明一个Mammal对象,而Mammal类的定义是在后面才出现的;在定义一个类的时候,对于类的成员也会出现使用在声明之前的情况,把类型解析先扫描一遍,就能方便地支持这个特性。
在写属性计算的算法时,计算的顺序可能是个最重要的问题。因为某属性的计算可能要依赖别的节点的属性先计算完。我们讨论的S属性、I属性和L属性,都是在考虑计算顺序。像使用在前,声明在后这种情况,就更要特殊处理了。
第2遍:类型的消解(TypeResolver.java)。
把所有出现引用到类型的地方,都消解掉,比如变量声明、函数参数声明、类的继承等等。做完消解以后,我们针对Mammal m;这样语句,就明确的知道了m的类型。这实际上是对I属性的类型的计算。
第3遍:引用的消解和S属性的类型的推导(RefResolver.java)。
这个时候,我们对所有的变量、函数调用,都会跟它的定义关联起来,并且完成了所有的类型计算。
第4遍:做类型检查(TypeChecker.java)。
比如当赋值语句左右两边的类型不兼容的时候,就可以报错。
第5遍:做一些语义合法性的检查(SematicValidator.java)。
比如break只能出现在循环语句中,如果某个函数声明了返回值,就一定要有return语句,等等。
语义分析的结果保存在AnnotatedTree.java类里,意思是被标注了属性的语法树。注意,这些属性在数据结构上,并不一定是AST节点的属性,我们可以借助Map等数据结构存储,只是在概念上,这些属性还是标注在树节点上的。
AnnotatedTree类的结构如下:
public class AnnotatedTree {
// AST
protected ParseTree ast = null;
// 解析出来的所有类型,包括类和函数
protected List<Type> types = new LinkedList<Type>();
// AST节点对应的Symbol
protected Map<ParserRuleContext, Symbol> symbolOfNode = new HashMap<ParserRuleContext, Symbol>();
// AST节点对应的Scope,如for、函数调用会启动新的Scope
protected Map<ParserRuleContext, Scope> node2Scope = new HashMap<ParserRuleContext, Scope>();
// 每个节点推断出来的类型
protected Map<ParserRuleContext, Type> typeOfNode = new HashMap<ParserRuleContext, Type>();
// 命名空间,作用域的根节点
NameSpace nameSpace = null;
//...
}
建议你看看这些语义分析的代码,了解一下如何保证语义分析的全面性。
总结
本节课我带你继续了解了语义分析的相关知识:
- 语义分析的本质是对上下文相关情况的处理,能做词法分析和语法分析所做不到的事情。
- 了解引用消解,左值和右值的场景,可以增加对语义分析的直观理解。
- 掌握属性计算和属性文法,可以使我们用更加形式化、更清晰的算法来完成语义分析的任务。
语义分析这个阶段十分重要。因为词法和语法都有很固定的套路,甚至都可以工具化的实现。但语言设计的核心在于语义,特别是要让语义适合所解决的问题。比如SQL语言针对的是数据库的操作,那就去充分满足这个目标就好了。
继承和多态:面向对象运行期的动态特性
面向对象是一个比较大的话题。之前我们了解了面向对象的封装特性,也探讨了对象成员的作用域和生存期特征等内容。本节课,我们再来了解一下面向对象的另外两个重要特征:继承和多态。
你也许会问,为什么没有在封装特性之后,马上讲继承和多态呢?
那是因为继承和多态涉及的语义分析阶段的知识点比较多,特别是它对类型系统提出了新的概念和挑战,所以我们先掌握语义分析,再了解这部分内容,才是最好的选择。
继承和多态对类型系统提出的新概念,就是子类型。
我们之前接触的类型往往是并列关系,你是整型,我是字符串型,都是平等的。
而现在,一个类型可以是另一个类型的子类型,比如我是一只羊,又属于哺乳动物。
这会导致我们在编译期无法准确计算出所有的类型,从而无法对方法和属性的调用做完全正确的消解(或者说绑定)。这部分工作要留到运行期去做,也因此,面向对象编程会具备非常好的优势,因为它会导致多态性。这个特性会让面向对象语言在处理某些类型的问题时,更加优雅。
从类型体系的角度理解继承和多态
继承的意思是一个类的子类,自动具备了父类的属性和方法,除非被父类声明为私有的。比如一个类是哺乳动物,它有体重(weight)的属性,还会做叫(speak)的操作。如果基于哺乳动物这个父类创建牛和羊两个子类,那么牛和羊就自动继承了哺乳动物的属性,有体重,还会叫。
所以继承的强大之处,就在于重用。也就是有些逻辑,如果在父类中实现,在子类中就不必重复实现。
多态的意思是同一个类的不同子类,在调用同一个方法时会执行不同的动作。这是因为每个子类都可以重载掉父类的某个方法,提供一个不同的实现。哺乳动物会“叫”,而牛和羊重载了这个方法,发出“哞”和“咩”的声音。这似乎很普通,但如果创建一个哺乳动物的数组,并在里面存了各种动物对象,遍历这个数组并调用每个对象“叫”的方法时,就会发出“哞”“咩”“喵~”等各种声音,这就有点儿意思了。
下面这段示例代码,演示了继承和多态的特性,a的speak()方法和b的speak()方法会分别打印出牛叫和羊叫,调用的是子类的方法,而不是父类的方法:
/**
mammal.play 演示面向对象编程:继承和多态。
*/
class Mammal{
int weight = 20;
boolean canSpeak(){
return true;
}
void speak(){
println("mammal speaking...");
}
}
class Cow extends Mammal{
void speak(){
println("moo~~ moo~~");
}
}
class Sheep extends Mammal{
void speak(){
println("mee~~ mee~~");
println("My weight is: " + weight); //weight的作用域覆盖子类
}
}
//将子类的实例赋给父类的变量
Mammal a = Cow();
Mammal b = Sheep();
//canSpeak()方法是继承的
println("a.canSpeak() : " + a.canSpeak());
println("b.canSpeak() : " + b.canSpeak());
//下面两个的叫声会不同,在运行期动态绑定方法
a.speak(); //打印牛叫
b.speak(); //打印羊叫
所以,多态的强大之处,在于虽然每个子类不同,但我们仍然可以按照统一的方式使用它们,做到求同存异。以前端工程师天天打交道的前端框架为例,这是最能体现面向对象编程优势的领域之一。
前端界面往往会用到各种各样的小组件,比如静态文本、可编辑文本、按钮等等。如果我们想刷新组件的显示,没必要针对每种组件调用一个方法,把所有组件的类型枚举一遍,可以直接调用父类中统一定义的方法redraw(),非常简洁。即便将来添加新的前端组件,代码也不需要修改,程序也会更容易维护。
总结一下:面向对象编程时,我们可以给某个类创建不同的子类,实现一些个性化的功能;写程序时,我们可以站在抽象度更高的层次上,不去管具体的差异。
如果把上面的结论抽象成一般意义上的类型理论,就是子类型(subtype)。
子类型(或者动名词:子类型化),是对我们前面讲的类型体系的一个补充。
子类型的核心是提供了is-a的操作。也就是对某个类型所做的所有操作都可以用子类型替代。因为子类型 is a 父类型,也就是能够兼容父类型,比如一只牛是哺乳动物。
这意味着只要对哺乳动物可以做的操作,都可以对牛来做,这就是子类型的好处。它可以放宽对类型的检查,从而导致多态。你可以粗略地把面向对象的继承看做是子类型化的一个体现,它的结果就是能用子类代替父类,从而导致多态。
子类型有两种实现方式:
一种就是像Java和C++语言,需要显式声明继承了什么类,或者实现了什么接口。这种叫做名义子类型(Nominal Subtyping)。
另一种是结构化子类型(Structural Subtyping),又叫鸭子类型(Duck Type)。也就是一个类不需要显式地说自己是什么类型,只要它实现了某个类型的所有方法,那就属于这个类型。鸭子类型是个直观的比喻,如果我们定义鸭子的特征是能够呱呱叫,那么只要能呱呱叫的,就都是鸭子。
如何对继承和多态的特性做语义分析
针对哺乳动物的例子,我们用前面语义分析的知识,看看如何在编译期针对继承和多态做语义分析,也算对语义分析的知识点进行应用和复盘。
首先,从类型处理的角度出发,我们要识别出新的类型:Mammal、Cow和Sheep。之后,就可以用它们声明变量了。
第二,我们要设置正确的作用域。
从作用域的角度来看,一个类的属性(或者说成员变量),是可以规定能否被子类访问的。以Java为例,除了声明为private的属性以外,其他属性在子类中都是可见的。所以父类的属性的作用域,可以说是以树状的形式覆盖到了各级子类:
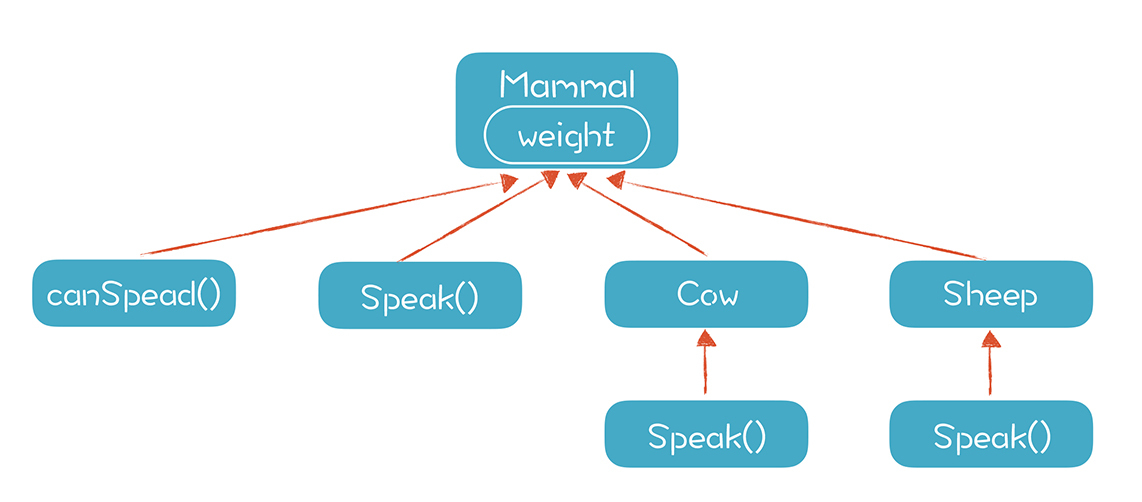
第三,要对变量和函数做类型的引用消解。
也就是要分析出a和b这两个变量的类型。那么a和b的类型是什么呢?是父类Mammal?还是Cow或Sheep?
注意,代码里是用Mammal来声明这两个变量的。按照类型推导的算法,a和b都是Mammal,这是个I属性计算的过程。也就是说,在编译期,我们无法知道变量被赋值的对象确切是哪个子类型,只知道声明变量时,它们是哺乳动物类型,至于是牛还是羊,就不清楚了。
你可能会说:“不对呀,我在编译的时候能知道a和b的准确类型啊,因为我看到了a是一个Cow对象,而b是一个Sheep,代码里有这两个对象的创建过程,我可以推导出a和b的实际类型呀。”
没错,语言的确有自动类型推导的特性,但你忽略了限制条件。比如,强类型机制要求变量的类型一旦确定,在运行过程就不能再改,所以要让a和b能够重新指向其他的对象,并保持类型不变。从这个角度出发,a和b的类型只能是父类Mammal。
所以说,编译期无法知道变量的真实类型,可能只知道它的父类型,也就是知道它是一个哺乳动物,但不知道它具体是牛还是羊。这会导致我们没法正确地给speak()方法做引用消解。正确的消解,是要指向Cow和Sheep的speak方法,而我们只能到运行期再解决这个问题。
如何在运行期实现方法的动态绑定
在运行期,我们能知道a和b这两个变量具体指向的是哪个对象,对象里是保存了真实类型信息的。具体来说,在playscript中,ClassObject的type属性会指向一个正确的Class,这个类型信息是在创建对象的时候被正确赋值的:
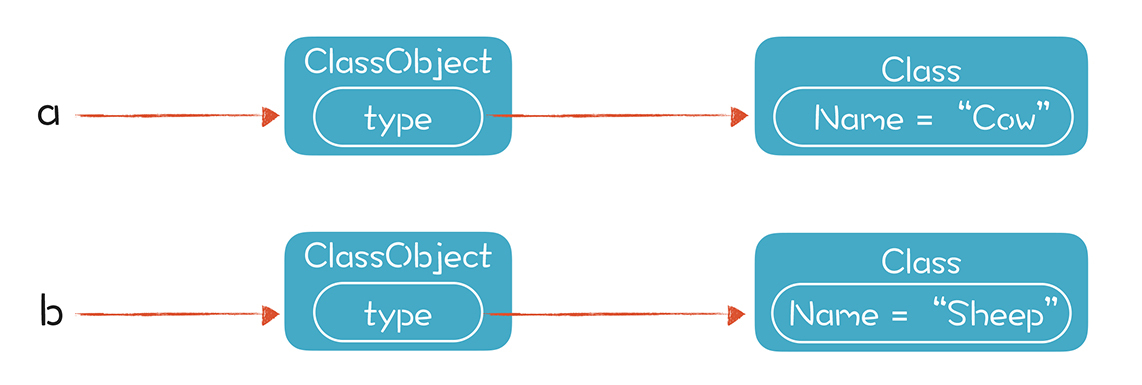
在调用类的属性和方法时,我们可以根据运行时获得的,确定的类型信息进行动态绑定。下面这段代码是从本级开始,逐级查找某个方法的实现,如果本级和父类都有这个方法,那么本级的就会覆盖掉父类的,这样就实现了多态:
protected Function getFunction(String name, List<Type> paramTypes){
//在本级查找这个这个方法
Function rtn = super.getFunction(name, paramTypes); //TODO 是否要检查visibility
//如果在本级找不到,那么递归的从父类中查找
if (rtn == null && parentClass != null){
rtn = parentClass.getFunction(name,paramTypes);
}
return rtn;
}
如果当前类里面没有实现这个方法,它可以直接复用某一级的父类中的实现,这实际上就是继承机制在运行期的原理。
你看,只有了解运行期都发生了什么,才能知道继承和多态是怎么发生的吧。
这里延伸一下。我们刚刚谈到,在运行时可以获取类型信息,这种机制就叫做运行时类型信息(Run Time Type Information, RTTI)。C++、Java等都有这种机制,比如Java的instanceof操作,就能检测某个对象是不是某个类或者其子类的实例。
汇编语言是无类型的,所以一般高级语言在编译成目标语言之后,这些高层的语义就会丢失。如果要在运行期获取类型信息,需要专门实现RTTI的功能,这就要花费额外的存储开销和计算开销。就像在playscript中,我们要在ClassObject中专门拿出一个字段来存type信息。
继承情况下对象的实例化
在存在继承关系的情况下,创建对象时,不仅要初始化自己这一级的属性变量,还要把各级父类的属性变量也都初始化。比如,在实例化Cow的时候,还要对Mammal的成员变量weight做初始化。
所以我们要修改playscript中对象实例化的代码,从最顶层的祖先起,对所有的祖先层层初始化:
//从父类到子类层层执行缺省的初始化方法,即不带参数的初始化方法
protected ClassObject createAndInitClassObject(Class theClass) {
ClassObject obj = new ClassObject();
obj.type = theClass;
Stack<Class> ancestorChain = new Stack<Class>();
// 从上到下执行缺省的初始化方法
ancestorChain.push(theClass);
while (theClass.getParentClass() != null) {
ancestorChain.push(theClass.getParentClass());
theClass = theClass.getParentClass();
}
// 执行缺省的初始化方法
StackFrame frame = new StackFrame(obj);
pushStack(frame);
while (ancestorChain.size() > 0) {
Class c = ancestorChain.pop();
defaultObjectInit(c, obj);
}
popStack();
return obj;
}
在逐级初始化的过程中,我们要先执行缺省的成员变量初始化,也就是变量声明时所带的初始化部分,然后调用这一级的构造方法。如果不显式指定哪个构造方法,就会执行不带参数的构造方法。不过有的时候,子类会选择性地调用父类某一个构造方法,就像Java可以在构造方法里通过super()来显式地调用父类某个具体构造方法。
如何实现this和super
我们通过一个示例程序,把本节课的所有知识复盘检验一下,加深对它们的理解,也加深对this和super机制的理解。
这个示例程序是用Java写的,在Java语言中,为面向对象编程专门提供了两个关键字:this和super,这两个关键字特别容易引起混乱。
比如在下面的ThisSuperTest.Java代码中,Mammal和它的子类Cow都有speak()方法。
如果我们要创建一个Cow对象,会调用Mammal的构造方法Mammal(int weight),而在这个构造方法里调用的this.speak()方法,是Mammal的,还是Cow的呢?
package play;
public class ThisSuperTest {
public static void main(String args[]){
//创建Cow对象的时候,会在Mammal的构造方法里调用this.reportWeight(),这里会显示什么
Cow cow = new Cow();
System.out.println();
//这里调用,会显示什么
cow.speak();
}
}
class Mammal{
int weight;
Mammal(){
System.out.println("Mammal() called");
this.weight = 100;
}
Mammal(int weight){
this(); //调用自己的另一个构造函数
System.out.println("Mammal(int weight) called");
this.weight = weight;
//这里访问属性,是自己的weight
System.out.println("this.weight in Mammal : " + this.weight);
//这里的speak()调用的是谁,会显示什么数值
this.speak();
}
void speak(){
System.out.println("Mammal's weight is : " + this.weight);
}
}
class Cow extends Mammal{
int weight = 300;
Cow(){
super(200); //调用父类的构造函数
}
void speak(){
System.out.println("Cow's weight is : " + this.weight);
System.out.println("super.weight is : " + super.weight);
}
}
运行结果如下:
Mammal() called
Mammal(int weight) called
this.weight in Mammal : 200
Cow's weight is : 0
super.weight is : 200
Cow's weight is : 300
super.weight is : 200
答案是Cow的speak()方法 ,而不是Mammal的。怎么回事?代码里不是调用的this.speak()吗?怎么这个this不是Mammal,却变成了它的子类Cow呢?
其实,在这段代码中,this用在了三个地方:
- this.weight 是访问自己的成员变量,因为成员变量的作用域是这个类本身,以及子类。
- this()是调用自己的另一个构造方法,因为这是构造方法,肯定是做自身的初始化。换句话说,构造方法不存在多态问题。
- this.speak()是调用一个普通的方法。这时,多态仍会起作用。运行时会根据对象的实际类型,来绑定到Cow的speak()方法上。
只不过,在Mammal的构造方法中调用this.speak()时,虽然访问的是Cow的speak()方法,打印的是Cow中定义的weight成员变量,但它的值却是0,而不是成员变量声明时“int weight = 300;”的300。为什么呢?
要想知道这个答案,我们需要理解多层继承情况下对象的初始化过程。在Mammal的构造方法中调用speak()的时候,Cow的初始化过程还没有开始呢,所以“int weight = 300;”还没有执行,Cow的weight属性还是缺省值0。
怎么样?一个小小的例子,却需要用到三个方面的知识:面向对象的成员变量的作用域、多态、对象初始化。Java程序员可以拿这个例子跟同事讨论一下,看看是不是很好玩。
讨论完this,super就比较简单了,它的语义要比this简单,不会出现歧义。super的调用,也是分成三种情况:
- super.weight。这是调用父类或更高的祖先的weight属性,而不是Cow这一级的weight属性。不一定非是直接父类,也可以是祖父类中的。根据变量作用域的覆盖关系,只要是比Cow这一级高的就行。
- super(200)。这是调用父类的构造方法,必须是直接父类的。
- super.speak()。跟访问属性的逻辑一样,是调用父类或更高的祖先的speak()方法。
总结
实现了面向对象中的另两个重要特性:继承和多态。在这节课中,我建议你掌握的重点内容是:
- 从类型的角度,面向对象的继承和多态是一种叫做子类型的现象,子类型能够放宽对类型的检查,从而支持多态。
- 在编译期,无法准确地完成对象方法和属性的消解,因为无法确切知道对象的子类型。
- 在运行期,我们能够获得对象的确切的子类型信息,从而绑定正确的方法和属性,实现继承和多态。另一个需要注意的运行期的特征,是对象的逐级初始化过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号