论文翻译——Deep contextualized word representations
Abstract
We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (eg, syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e. to model polysemy).
我们引入了一种新型的“深层语境化”单词表示,它模拟了(1)单词使用的复杂特征(例如,语法和语义),以及(2)这些用法如何在不同的语言环境中变化(例如,以模拟一词多义)。
Our word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pretrained on a large text corpus.
我们的词向量是深度双向语言模型(biLM)内部状态的习得函数,该模型是在大型文本语料库上预先训练的。
We show that these representations can be easily added to existing models and significantly improve the state of the art across six challenging NLP problems, including question answering, textual entailment and sentiment analysis.
我们证明了这些表示可以很容易地添加到现有的模型中,并通过6个具有挑战性的NLP问题(包括问题回答、文本隐含和情感分析)显著地改进现有模型的状态。
We also present an analysis showing that exposing the deep internals of the pre-trained network is crucial, allowing downstream models to mix different types of semi-supervision signals.
我们还提出了一个分析表明,暴露预先训练的网络的深层内部是至关重要的,允许下游模型混合不同类型的半监督信号。
1 Introduction
Pre-trained word representations(Mikolov et al 2013, Pennington et al 2014)are a key component in many neural language understanding models.
训练前的单词表示(Mikolov et al 2013, Pennington et al 2014)是许多神经语言理解模型的关键组成部分。
However, learning high quality representations can be challenging.
然而,学习高质量的表现是有挑战性的。
They should ideally model both (1) complex characteristics of word use (eg, syntax and semantics), and (2) how these uses vary across linguistic contexts (ie, to model polysemy).
理想情况下,他们应该模拟(1)单词使用的复杂特征(例如,语法和语义),以及(2)这些用法如何在不同的语言环境中变化(例如,模拟一词多义)。
Our representations differ from traditional word type embeddings in that each token is assigned a representation that is a function of the entire input sentence.
我们的表示与传统的词类型嵌入不同,因为每个标记都被分配了一个表示,它是整个输入语句的一个函数。
We use vectors derived from a bidirectional LSTM that is trained with a coupled language model (LM) objective on a large text corpus.
我们使用来自双向LSTM的向量,该向量是用一个耦合语言模型(LM)目标在一个大型文本语料库上训练的。
For this reason, we call them ELMo (Embeddings from Language Models) representations.
因此,我们称它们为ELMo(来自语言模型的嵌入)表示。
Unlike previous approaches for learning contextualized word vectors (Peters et al, 2017,McCann et al, 2017), ELMo representations are deep, in the sense that they are a function of all of the internal layers of the biLM.
与以往的语境化词汇向量学习方法不同(Peters等,2017, McCann et al, 2017), ELMo表示是深层的,因为它们是biLM所有内层的功能。
More specifically, we learn a linear combination of the vectors stacked above each input word for each end task, which markedly improves performance over just using the top LSTM layer.
更具体地说,我们学习了每个结束任务的每个输入字之上的向量的线性组合,这显著地提高了性能,而不只是使用顶层LSTM层。
Combining the internal states in this manner allows for very rich word representations.
以这种方式组合内部状态允许非常丰富的单词表示。
Using intrinsic evaluations, we show that the higher-level LSTM states capture context-dependent aspects of word meaning (eg, they can be used without modification to perform well on supervised word sense disambiguation tasks) while lower-level states model aspects of syntax (eg, they can be used to do part-of-speech tagging).
使用内在的评价,我们表明,高级LSTM状态捕获词义的上下文相关的方面(例如,他们可以使用不需要修改监督词义消歧任务上的表现良好)虽然低级状态模型方面的语法(例如,他们可以用来做词性标注)。
Simultaneously exposing all of these signals is highly beneficial, allowing the learned models select the types of semi-supervision that are most useful for each end task.
同时暴露所有这些信号是非常有益的,允许学习的模型选择对每个最终任务最有用的半监督类型。
Extensive experiments demonstrate that ELMo representations work extremely well in practice.
大量的实验表明,ELMo表示在实践中效果非常好。
We first show that they can be easily added to existing models for six diverse and challenging language understanding problems, including textual entailment, question answering and sentiment analysis.
我们首先表明,它们可以很容易地添加到现有的六个不同的和具有挑战性的语言理解问题的模型中,包括文本蕴涵、问题回答和情感分析。
The addition of ELMo representations alone significantly improves the state of the art in every case, including up to 20% relative error reductions.
单独添加ELMo表示可以显著地改进每种情况下的技术状态,包括最多减少20%的相对错误。
For tasks where direct comparisons are possible, ELMo outperforms CoVe (McCann et al, 2017), which computes contextualized representations using a neural machine translation encoder.
在可以进行直接比较的任务中,ELMo的性能优于CoVe (McCann et al, 2017),后者使用神经机器翻译编码器计算上下文化的表示。
Finally, an analysis of both ELMo and CoVe reveals that deep representations outperform those derived from just the top layer of an LSTM.
最后,对ELMo和CoVe的分析表明,深层表示优于仅来自LSTM顶层的表示。
Our trained models and code are publicly available, and we expect that ELMo will provide similar gains for many other NLP problems.
我们训练的模型和代码是公开可用的,我们期望ELMo将为许多其他NLP问题提供类似的收益。
2 Related work
Due to their ability to capture syntactic and semantic information of words from large scale unlabeled text, pretrained word vectors (Turian et al, 2010, Mikolov et al, 2013,
由于它们能够从大规模未标记文本中捕获单词的语法和语义信息,因此,预先训练的单词向量(Turian et al, 2010, Mikolov et al, 2013,
Pennington et al, 2014) are a standard component of most state-ofthe-art NLP architectures, including for question answering (Liu et al, 2017), textual entailment (Chen et al,2017) and semantic role labeling (He et al, 2017).
Pennington等人(2014)是大多数最先进的NLP架构的标准组件,包括用于问题回答(Liu等人,2017)、文本隐含(Chen等人,2017)和语义角色标记(He等人,2017)。
However, these approaches for learning word vectors only allow a single context-independent representation for each word.
但是,这些学习单词向量的方法只允许每个单词有一个上下文无关的表示。
Previously proposed methods overcome some of the shortcomings of traditional word vectors by either enriching them with subword information (eg, Wieting et al, 2016, Bojanowski et al,2017) or learning separate vectors for each word sense (eg, Neelakantan et al, 2014).
之前提出的方法克服了传统词向量的一些缺点,要么用子词信息丰富它们(例如,Wieting et al, 2016, Bojanowski et al,2017),要么为每个词意义学习单独的向量(例如,Neelakantan et al, 2014)。
Our approach also benefits from subword units through the use of character convolutions, and we seamlessly incorporate multi-sense information into downstream tasks without explicitly training to predict predefined sense classes.
我们的方法还受益于通过使用字符卷积的子单词单元,并且我们无缝地将多义信息合并到下游任务中,而不需要显式地培训来预测预定义的义类。
Other recent work has also focused on learning context-dependent representations.
其他最近的工作也集中在学习上下文相关的表示。
context2vec (Melamud et al, 2016) uses a bidirectional Long Short Term Memory (LSTM,
context2vec (Melamud et al, 2016)使用双向长短时记忆(LSTM,
Hochreiter and Schmidhuber, 1997) to encode the context around a pivot word.
Hochreiter和Schmidhuber, 1997)将上下文编码到一个关键字周围。
Other approaches for learning contextual embeddings include the pivot word itself in the representation and are computed with the encoder of either a supervised neural machine translation (MT) system (CoVe, McCann et al, 2017) or an unsupervised language model (Peters et al, 2017).
学习上下文嵌入的其他方法包括关键字本身在表示中,并使用监督神经机器翻译(MT)系统(CoVe, McCann et al, 2017)或非监督语言模型(Peters et al, 2017)的编码器进行计算。
Both of these approaches benefit from large datasets, although the MT approach is limited by the size of parallel corpora.
这两种方法都受益于大型数据集,尽管MT方法受到并行语料库大小的限制。
In this paper, we take full advantage of access to plentiful monolingual data, and train our biLM on a corpus with approximately 30 million sentences (Chelba et al, 2014).
在本文中,我们充分利用了获取大量单语数据的优势,在大约3000万个句子的语料库上训练我们的biLM (Chelba et al, 2014)。
We also generalize these approaches to deep contextual representations, which we show work well across a broad range of diverse NLP tasks.
我们还将这些方法推广到深层上下文表示,我们发现这些方法在各种NLP任务中都能很好地工作。
Previous work has also shown that different layers of deep biRNNs encode different types of information.
以前的工作也表明,不同层次的深度biRNNs编码不同类型的信息。
For example, introducing multi-task syntactic supervision (eg, part-of-speech tags) at the lower levels of a deep LSTM can improve overall performance of higher level tasks such as dependency parsing (Hashimoto et al, 2017) or CCG super tagging (Søgaard and Goldberg, 2016).
例如,在深层LSTM的低层引入多任务语法监督(如词性标记)可以提高高级任务的整体性能,如依赖项解析(Hashimoto et al, 2017)或CCG超级标记(Søgaard and Goldberg, 2016)。
In an RNN-based encoder-decoder machine translation system, (Belinkov et al, 2017) showed that the representations learned at the first layer in a 2-layer LSTM encoder are better at predicting POS tags then second layer.
在一个基于rnn的编码器-解码器机器翻译系统中,(Belinkov et al, 2017)表明,在两层LSTM编码器的第一层学习的表示比第二层更能预测POS标签。
Finally, the top layer of an LSTM for encoding word context (Melamud et al, 2016) has been shown to learn representations of word sense.
最后,用于编码单词上下文的LSTM的顶层(Melamud et al, 2016)已经被证明可以学习单词意义的表示。
We show that similar signals are also induced by the modified language model objective of our ELMo representations, and it can be very beneficial to learn models for downstream tasks that mix these different types of semi-supervision.
我们发现,类似的信号也会被我们的ELMo表示的修改后的语言模型目标所诱导,并且对于混合了这些不同类型的半监督的下游任务来说,学习模型是非常有益的。
Dai and Le (2015) and Ramachandran et al (2017) pretrain encoder-decoder pairs using language models and sequence autoencoders and then fine tune with task specific supervision.
Dai和Le(2015)和Ramachandran等人(2017)使用语言模型和序列自动编码器对编码器-解码器进行预训练,然后在特定任务的监督下进行微调。
In contrast, after pretraining the biLM with unlabeled data, we fix the weights and add additional task-specific model capacity, allowing us to leverage large, rich and universal biLM representations for cases where downstream training data size dictates a smaller supervised model.
相反,在使用未标记的数据对biLM进行预培训之后,我们修正了权重,并添加了额外的特定于任务的模型容量,允许我们在下游培训数据大小要求较小的监督模型的情况下,利用大型、丰富和通用的biLM表示。
3 ELMo: Embeddings from Language Models
Unlike most widely used word embeddings (Pennington et al, 2014), ELMo word representations are functions of the entire input sentence, as described in this section.
与最广泛使用的词嵌入(Pennington et al, 2014)不同,ELMo词表示是整个输入语句的函数,如本节所述。
They are computed on top of two-layer biLMs with character convolutions (Sec 3.1), as a linear function of the internal network states (Sec 3.2).
它们是在具有字符卷积的两层biLMs之上计算的(第3.1节),作为内部网络状态的线性函数(第3.2节)。
This setup allows us to do semi-supervised learning, where the biLM is pretrained at a large scale (Sec 3.4) and easily incorporated into a wide range of existing neural NLP architectures (Sec 3.3).
这种设置允许我们进行半监督学习,其中biLM在大范围内进行了预训练(第3.4节),并且很容易被合并到现有的广泛的神经NLP体系结构中(第3.3节)。
3.1 Bidirectional language models
Given a sequence of N tokens, (t_1, t_2, ..., t_N ), a forward language model computes the probability of the sequence by modeling the probability of token t_k given the history (t_1, ... , t_k−1):
给定一个N个标记序列(t_1, t_2,, t_N),正向语言模型通过对给定历史(t_1, ... ,t_k−1)的标记t_k的概率建模来计算序列的概率:
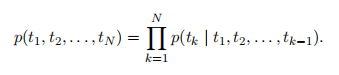
Recent state-of-the-art neural language models (Jozefowicz et al, 2016, Melis et al, 2017, Merity et al, 2017) compute a context-independent token representation x^LM_k (via token embeddings or a CNN over characters) then pass it through L layers of forward LSTMs.
最新的神经语言模型(Jo’zefowicz et al, 2016, Melis et al, 2017, Merity et al, 2017)计算上下文无关的标记表示x^LM_k(通过标记嵌入或CNN字符),然后将其通过L层正向LSTMs传递。
At each position k, each LSTM layer outputs a context-dependent representation H where j = 1, ... , L. The top layer LSTM output, H , is used to predict the next token t^k+1 with a Softmax layer.
在每个位置k,每个LSTM层输出一个上下文相关的表示H,其中j = 1,... , L。
A backward LM is similar to a forward LM, except it runs over the sequence in reverse, predicting the previous token given the future context:
倒向LM类似于前向LM,只是它以相反的顺序运行,根据未来上下文预测前一个标记:
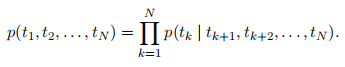
It can be implemented in an analogous way to a forward LM, with each backward LSTM layer j in a L layer deep model producing representations H of t_k given (t_k+1, ... , t_N ).
它可以用与前向LM类似的方式实现,每个后向LSTM层j在一个L层深度模型中产生表示t_k (t_k+1,... , t_N)的H。
A biLM combines both a forward and backward LM.
biLM结合了向前和向后LM。
Our formulation jointly maximizes the log likelihood of the forward and backward directions:
我们的公式共同最大化正向和反向方向的对数似然:
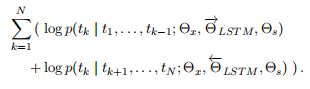
We tie the parameters for both the token representation (Θx) and Softmax layer (Θs) in the forward and backward direction while maintaining separate parameters for the LSTMs in each direction.
我们系的参数(Θx)和Softmax标记表示层(Θs)向前和向后的方向,同时保持独立的参数LSTMs在每个方向。
Overall, this formulation is similar to the approach of Peters et al (2017), with the exception that we share some weights between directions instead of using completely independent parameters.
总的来说,这个公式类似于Peters等人(2017)的方法,除了我们在方向之间共享一些权重而不是使用完全独立的参数。
In the next section, we depart from previous work by introducing a new approach for learning word representations that are a linear combination of the biLM layers.
在下一节中,我们将介绍一种学习单词表示的新方法,该方法是biLM层的线性组合,从而与以前的工作有所不同。
3.2 ELMo
ELMo is a task specific combination of the intermediate layer representations in the biLM.
ELMo是biLM中中间层表示的特定于任务的组合。
For each token t_k, a L-layer biLM computes a set of 2L + 1 representations
对于每个标记t_k,一个L层biLM计算一组2L + 1表示
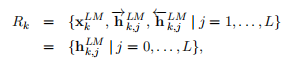
where h^LM_k0 is the token layer and H = [H , H ], for each biLSTM layer.
其中h^LM_k0是标记层,H = [H, H],对于每个biLSTM层。
For inclusion in a downstream model, ELMo collapses all layers in R into a single vector, ELMo_k = E(R_k, Θ_e).
包含在下游模型中,ELMo 崩溃所有层R为一个向量,ELMo_k = E (R_kΘ_e)。
In the simplest case,ELMo just selects the top layer, E(R_k) = H ,as in TagLM (Peters et al, 2017) and CoVe (McCann et al, 2017).
在最简单的情况下,ELMo只是选择了顶层,E(R_k) = H,如TagLM (Peters等,2017)和CoVe (McCann等,2017)。
More generally, we compute a task specific weighting of all biLM layers:
更一般地,我们计算所有biLM层的任务特定权重:
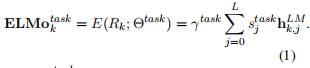
In (1), s^task are softmax-normalized weights and the scalar parameter γ^task allows the task model to scale the entire ELMo vector.
In(1), s ^task softmax-normalized重量和标量参数γ^task 允许任务模型规模整个ELMo向量。
γ is of practical importance to aid the optimization process (see supplemental material for details).
γ的实际意义来帮助优化过程(见补充材料)。
Considering that the activations of each biLM layer have a different distribution, in some cases it also helped to apply layer normalization (Ba et al, 2016) to each biLM layer before weighting.
考虑到每个biLM层的激活具有不同的分布,在某些情况下,在加权之前对每个biLM层应用层标准化(Ba et al, 2016)也有所帮助。
3.3 Using biLMs for supervised NLP tasks
Given a pre-trained biLM and a supervised architecture for a target NLP task, it is a simple process to use the biLM to improve the task model.
对于一个目标NLP任务,给定一个预先训练的biLM和一个监督架构,使用biLM来改进任务模型是一个简单的过程。
We simply run the biLM and record all of the layer representations for each word.
我们只需运行biLM并记录每个单词的所有层表示。
Then, we let the end task model learn a linear combination of these representations, as described below.
然后,我们让end task模型学习这些表示的线性组合,如下所述。
First consider the lowest layers of the supervised model without the biLM.
首先考虑无biLM的监督模型的最低层。
Most supervised NLP models share a common architecture at the lowest layers, allowing us to add ELMo in a consistent, unified manner.
大多数监督的NLP模型在最低层共享一个公共架构,允许我们以一致的、统一的方式添加ELMo。
Given a sequence of tokens (t_1, ... , t_N ), it is standard to form a context-independent token representation x_k for each token position using pre-trained word embeddings and optionally character-based representations.
给定一个标志序列(t_1, ... , t_N),使用预先训练的单词嵌入和可选的基于字符的表示形式为每个标记位置形成上下文无关的标记表示x_k是标准的。
Then, the model forms a context-sensitive representation h_k, typically using either bidirectional RNNs, CNNs, or feed forward networks.
然后,模型形成上下文语义的表示h_k,通常使用双向RNNs、CNNs或前馈网络。
To add ELMo to the supervised model, we first freeze the weights of the biLM and then concatenate the ELMo vector ELMo with x_k and pass the ELMo enhanced representation x_k, ELMo^task] into the task RNN.
为了将ELMo添加到监督模型中,我们首先冻结biLM的权值,然后将ELMo向量ELMo与x_k连接,并将ELMo增强表示x_k, ELMo^task]传递给任务RNN。
For some tasks (eg, SNLI, SQuAD), we observe further improvements by also including ELMo at the output of the task RNN by introducing another set of output specific linear weights and replacing h_k with h_k, ELMo^task].
对于某些任务(例如,SNLI,SQuAD),我们观察到进一步的改进,通过引入另一组输出特定的线性权值,并将h_k替换为h_k, ELMo^task,从而在任务RNN的输出中加入ELMo。
As the remainder of the supervised model remains unchanged, these additions can happen within the context of more complex neural models.
由于监督模型的其余部分保持不变,这些附加部分可以在更复杂的神经模型上下文中发生。
For example, see the SNLI experiments in Sec 4 where a bi-attention layer follows the biLSTMs, or the coreference resolution experiments where a clustering model is layered on top of the biLSTMs.
例如,参见第4节中的SNLI实验,其中双注意层跟随biLSTMs,或在biLSTMs之上分层集群模型的coreference分辨率实验。
Finally, we found it beneficial to add a moderate amount of dropout to ELMo (Srivastava et al, 2014) and in some cases to regularize the ELMo weights by adding λ to the loss.
最后,我们发现它有利于添加适量dropout ELMo(Srivastava等,2014),在某些情况下调整ELMo权重通过添加λ的损失。
This imposes an inductive bias on the ELMo weights to stay close to an average of all biLM layers.
这对ELMo权重施加了一个归纳偏差,使其接近所有biLM层的平均值。
3.4 Pre-trained bidirectional language model architecture
The pre-trained biLMs in this paper are similar to the architectures in Jozefowicz et al (2016) and Kim et al (2015), but modified to support joint training of both directions and add a residual connection between LSTM layers.
本文中预训练的biLMs与Jozefowicz等人(2016)和Kim等人(2015)的体系结构相似,但进行了修改,支持两个方向的联合训练,并在LSTM层之间添加了残余连接。
We focus on large scale biLMs in this work, as Peters et al (2017) highlighted the importance of using biLMs over forward-only LMs and large scale training.
在这项工作中,我们重点关注大规模的bilm,因为Peters等人(2017)强调了使用bilm比只使用前LMs和大规模培训的重要性。
To balance overall language model perplexity with model size and computational requirements for downstream tasks while maintaining a purely character-based input representation, we halved all embedding and hidden dimensions from the single best model CNN-BIG-LSTM in Jozefowicz et al7(2016).
为了在保持纯粹基于字符的输入表示的同时平衡整体语言模型复杂性与模型大小和下游任务的计算需求,我们将Jozefowicz等(2016)中单个最佳模型cn big lstm的所有嵌入和隐藏维度减半。
The final model uses L = 2 biLSTM layers with 4096 units and 512 dimension projections and a residual connection from the first to second layer.
最终的模型使用L = 2个biLSTM层,包含4096个单元和512个维度投影,并且从第一层到第二层有一个剩余连接。
The context insensitive type representation uses 2048 character n-gram convolutional filters followed by two highway layers (Srivastava et al, 2015) and a linear projection down to a 512 representation.
上下文不敏感类型表示使用2048个字符n-gram卷积过滤器,然后是两个高速公路层(Srivastava et al, 2015)和一个线性投影到512表示。
As a result, the biLM provides three layers of representations for each input token, including those outside the training set due to the purely character input.
因此,biLM为每个输入标记提供三层表示,包括那些由于纯字符输入而在训练集之外的标记。
In contrast, traditional word embedding methods only provide one layer of representation for tokens in a fixed vocabulary.
相比之下,传统的单词嵌入方法仅为固定词汇表中的标记提供一层表示。
After training for 10 epochs on the 1B Word Benchmark (Chelba et al), 2014), the average forward and backward perplexities is 39.7, compared to 30.0 for the forward CNN-BIG-LSTM.
在1B词基准上训练10个epoch后(Chelba et al, 2014),正向和反向的perplex7平均值为39.7,而正向的CNN-BIG-LSTM的perplex0平均值为30.0。
Generally, we found the forward and backward perplexities to be approximately equal, with the backward value slightly lower.
一般来说,我们发现前后的perplexings大致相等,而后向的值略低。
Once pretrained, the biLM can compute representations for any task.
经过预先训练后,biLM可以为任何任务计算表示。
In some cases, fine tuning the biLM on domain specific data leads to significant drops in perplexity and an increase in downstream task performance.
在某些情况下,对领域特定数据上的biLM进行微调会导致perplexity显著下降,并提高下游任务的性能。
This can be seen as a type of domain transfer for the biLM.
这可以看作是biLM的一种域转移类型。
As a result, in most cases we used a fine-tuned biLM in the downstream task.
因此,在大多数情况下,我们在下游任务中使用了经过调优的biLM。
See supplemental material for details.
详见补充资料。
4 Evaluation
Table 1 shows the performance of ELMo across a diverse set of six benchmark NLP tasks.
表1显示了ELMo在一组不同的基准测试NLP任务中的性能。
In every task considered, simply adding ELMo establishes a new state-of-the-art result, with relative error reductions ranging from 6 -20% over strong base models.
在考虑的每一项任务中,简单地添加ELMo就可以建立一个新的最先进的结果,与强基础模型相比,可以减少6 -20%的相对误差。
This is a very general result across a diverse set model architectures and language understanding tasks.
这是一个非常普遍的结果,适用于不同的集模型体系结构和语言理解任务。
In the remainder of this section we provide high-level sketches of the individual task results,
在本节的其余部分中,我们将提供各个任务结果的高级示意图,
see the supplemental material for full experimental details.
完整的实验细节见补充材料。
Question answering
The Stanford Question Answering Dataset (SQuAD) (Rajpurkar et al, 2016) contains 100K+ crowd sourced question answer pairs where the answer is a span in a given Wikipedia paragraph.
斯坦福问答数据集(SQuAD) (Rajpurkar et al, 2016)包含了100K+的众包问题答案对,其中的答案是一个给定的Wikipedia段落跨度。
Our baseline model (Clark and Gardner, 2017) is an improved version of the Bidirectional Attention Flow model in Seo et al(BiDAF, 2017).
我们的基线模型(Clark and Gardner, 2017)是Seo等人(BiDAF, 2017)的双向注意流模型的改进版本。
It adds a self-attention layer after the bidirectional attention component, simplifies some of the pooling operations and substitutes the LSTMs for gated recurrent units (GRUs, Cho et al, 2014).
它在双向注意组件之后添加了一个self-attention,简化了一些池操作,并将LSTMs替换为门控重复单元(GRUs, Cho等,2014)。
After adding ELMo to the baseline model, test set F1 improved by 4.7% from 81.1% to 85.8%, a 24.9% relative error reduction over the baseline, and improving the overall single model state-of-the-art by 1.4%.
在基线模型中加入ELMo后,测试集F1从81.1%提高到85.8%,提高了4.7%,相对基线误差降低了24.9%,整体单模型水平提高了1.4%。
A 11 member ensemble pushes F1 to 87.4, the overall state-of-the-art at time of submission to the leaderboard.
一个11人的组合将F1推到了87.4,这是提交给排行榜时的最高水平。
The increase of 4.7% with ELMo is also significantly larger then the 1.8% improvement from adding CoVe to a baseline model (McCann et al, 2017).
与添加CoVe到基线模型相比,添加ELMo后的增长4.7%,明显大于添加CoVe后1.8%的增长(McCann等,2017)。
| TASK | PREVIOUS SOTA | OURBASELINE | ELMO +BASELINE | INCREASE(ABSOLUTE/ RELATIVE) | |
|---|---|---|---|---|---|
| SQuAD | Liu et al 6(2017) | 84.4 | 81.1 | 85.8 | 4.7 / 24.9% |
| SNLISRL | Chen et al 3(2017)He et al 4(2017) | 88.681.7 | 88.081.4 | 88.7 ± 0.1784.6 | 0.7 / 5.8%3.2 / 17.2% |
| Coref | Lee et al 4(2017) | 67.2 | 67.2 | 70.4 | 3.2 / 9.8% |
| NERSST-5 | Peters et al 9(2017)McCann et al 9(2017) | 91.93 ± 0.1953.7 | 90.1551.4 | 92.22 ± 0.1054.7 ± 0.5 | 2.06 / 21%3.3 / 6.8% |
Table 1: Test set comparison of ELMo enhanced neural models with state-of-the-art single model baselines across six benchmark NLP tasks.
表1:在6个基准NLP任务中,ELMo增强的神经模型与最先进的单个模型基线的测试集比较。
The performance metric varies across tasks accuracy for SNLI and SST-5,F1 for SQuAD, SRL and NER, average F1 for Coref.
不同的任务,SNLI和SST-5的性能指标是不同的,F1代表小队,SRL和NER代表平均F1代表Coref。
Due to the small test sizes for NER and SST-5, we report the mean and standard deviation across five runs with different random seeds.
由于NER和SST-5的测试规模较小,我们报告了不同随机种子的5次测试的平均值和标准差。
The “increase” column lists both the absolute and relative improvements over our baseline.
“增加”一栏列出了基线的绝对和相对改进。
Textual entailment
Textual entailment is the task of determining whether a “hypothesis” is true, given a “premise”.
文本蕴涵是在给定“前提”的情况下,判断“假设”是否为真。
The Stanford Natural Language Inference (SNLI) corpus (Bowman et al, 2015) provides approximately 550K hypothesis/premise pairs.
斯坦福自然语言推理(SNLI)语料库(Bowman et al, 2015)提供了大约550K的假设/前提对。
Our baseline, the ESIM sequence model from Chen et al (2017), uses a biLSTM to encode the premise and hypothesis, followed by a matrix attention layer, a local inference layer, another biLSTM inference composition layer, and finally a pooling operation before the output layer.
我们的基线,Chen等人(2017)的ESIM序列模型,使用biLSTM对前提和假设进行编码,接着是矩阵注意层、局部推理层、另一个biLSTM推理复合层,最后是输出层之前的池操作。
Overall, adding ELMo to the ESIM model improves accuracy by an average of 0.7% across five random seeds.
总的来说,在ESIM模型中加入ELMo平均可以提高0.7%的准确率。
A five member ensemble pushes the overall accuracy to 89.3%, exceeding the previous ensemble best of 88.9% (Gong et al2, 2018).
五人合奏将整体精度提高到89.3%,超过了之前合奏最好的88.9% (Gong et al2, 2018)。
Semantic role labeling
A semantic role labeling (SRL) system models the predicate-argument structure of a sentence, and is often described as answering “Who did what to whom”.
语义角色标注(SRL)系统模型的predicate-argument结构的句子,和通常被描述为回答“谁对谁做了什么”。
He et al(2017) modeled SRL as a BIO tagging problem and used an 8-layer deep biLSTM with forward and backward directions interleaved, following Zhou and Xu (2015).
He等(2017)建模SRL作为生物标记问题,使用了一个8-层深biLSTM向前和向后的方向交错,Zhou 和 Xu(2015)。
As shown in Table , when adding ELMo to a re-implementation of HH et al(2017) the single model test set F1 jumped 3.2% from 81.4% to 84.6% – a new state-of-the-art on the OntoNotes benchmark (Pradhan et al, 20130), even improving over the previous best ensemble result by 1.2%.
如表所示,当添加ELMo He等人(2017)的重新实现一个模型测试集F1上涨3.2%从81.4%降至84.6%——一个新的先进的OntoNotes基准(普拉丹等,20130),甚至过去最好的整体结果提高1.2%。
Coreference resolution
Coreference resolution is the task of clustering mentions in text that refer to the same underlying real world entities.
共引用解析是指在文本中引用相同的底层实体的聚类。
Our baseline model is the end-to-end span-based neural model of Lee et al (2017).
我们的基线模型是Lee等(2017)的端到端基于span的神经模型。
It uses a biLSTM and attention mechanism to first compute span representations and then applies a softmax mention ranking model to find coreference chains.
它首先使用biLSTM和注意力机制来计算跨度表示,然后应用softmax提及排序模型来寻找共参考链。
In our experiments with the OntoNotes coreference annotations from the CoNLL 2012 shared task (Pradhan et al, 2012), adding ELMo improved the average F1 by 3.2% from 67.2 to 70.4, establishing a new state of the art, again improving over the previous best ensemble result by 1.6% F1.
在我们的实验中,使用来自CoNLL 2012共享任务的OntoNotes coreference注释(Pradhan et al, 2012),添加ELMo将平均F1提高了3.2%,从67.2提高到70.4,建立了一种新的技术状态,再次将之前的最佳集成结果提高了1.6% F1。
Named entity extraction
The CoNLL 2003 NER task (Sang and Meulder, 2003) consists of newswire from the Reuters RCV1 corpus tagged with four different entity types (PER, LOC, ORG, MISC).
CoNLL 2003 NER任务(Sang和Meulder, 2003)由Reuters RCV1语料库中的newswire组成,该语料库标记了四种不同的实体类型(PER、LOC、ORG、MISC)。
Following recent state-of-the-art systems (Lample et al, 2016, Peters et al, 2017), the baseline model uses pre-trained word embeddings, a character-based CNN representation, two biLSTM layers and a conditional random field (CRF) loss (Lafferty et al2), 2001), similar to Collobert et al8(2011).
根据最新的系统(Lample et al, 2016, Peters et al, 2017),基线模型使用预先训练的词嵌入,一个基于字符的CNN表示,两个biLSTM层和一个条件随机字段(CRF)损失(Lafferty et al2, 2001),类似于Collobert et al8(2011)。
As shown in Table, our ELMo enhanced biLSTM-CRF achieves 92.22% F1 averaged over five runs.
如表1所示,我们的ELMo增强型biLSTM-CRF在5次运行中平均F1达到92.22%。
The key difference between our system and the previous state of the art from Peters et al(2017) is that we allowed the task model to learn a weighted average of all biLM layers, whereas Pe-9) ters et al 9(2017) only use the top biLM layer.
我们的系统与Peters等人(2017)之前的技术状态的关键区别在于,我们允许任务模型学习所有biLM层的加权平均值,而Peters等人(2017)只使用顶层biLM层。
As shown in Sec 5.11), using all layers instead of just the last layer improves performance across multiple tasks.
如第5.11节所示),使用所有层而不是仅使用最后一层可以提高跨多个任务的性能。
Sentiment analysis
The fine-grained sentiment classification task in the Stanford Sentiment Treebank (SST-5, Socher et al, 2013) involves selecting one of five labels (from very negative to very positive) to describe a sentence from a movie review.
斯坦福情感树银行(SST-5, Socher et al, 2013)的细粒度情感分类任务涉及从五个标签(从非常负面到非常正面)中选择一个来描述电影评论中的一句话。
The sentences contain diverse linguistic phenomena such as idioms and complex syntactic constructions such as negations that are difficult for models to learn.
句子中包含了各种各样的语言现象,如习语和复杂的句法结构,如否定句,这些都是模型难以学习的。
Our baseline model is the biattentive classification network (BCN) from McCann et al(2017), which also held the prior state-of-the-art result when augmented with CoVe embeddings.
我们的基线模型是来自McCann等人(2017)的双关注分类网络(BCN),它在扩大CoVe嵌入时也保持了先前的最新结果。
Replacing CoVe with ELMo in the BCN model results in a 1.0% absolute accuracy improvement over the state of the art.
在BCN模型中,用ELMo替换CoVe的结果是1.0%的绝对精度提高。
| Task | Baseline | Last Only | All layers λ=1 λ=0.001 |
|---|---|---|---|
| SQuAD | 80.8 | 84.7 | 85.0 85.2 |
| SNLI | 88.1 | 89.1 | 89.3 89.5 |
| SRL | 81.6 | 84.1 | 84.6 84.8 |
Table 2: Development set performance for SQAD, SNLI and SRL comparing using all layers of the biLM (with different choices of regularization strength λ) to just the top layer.
表2:开发SQuAD集性能、SNLI和SRL比较使用的所有层biLM(不同的选择正则化强度λ)顶层。
| Task | InputOnly | Input &Output | OutputOnly |
|---|---|---|---|
| SQuAD | 85.1 | 85.6 | 84.8 |
| SNLI | 88.9 | 89.5 | 88.7 |
| SRL | 84.7 | 84.3 | 80.9 |
Table 3: Development set performance for SQuAD, SNLI and SRL when including ELMo at different locations in the supervised model.
表3:在监督模型中,当将ELMo包含在不同位置时,为SQuAD、SNLI和SRL设置开发性能。
5 Analysis
This section provides an ablation analysis to validate our chief claims and to elucidate some interesting aspects of ELMo representations.
本节提供一个消融分析,以验证我们的主要主张,并阐明一些有趣的方面,ELMo 的表现。
Sec 5.11 shows that using deep contextual representations in downstream tasks improves performance over previous work that uses just the top layer, regardless of whether they are produced from a biLM or MT encoder, and that ELMo representations provide the best overall performance.
Sec 5.11表明,在下游任务中使用深层上下文表示比以前只使用顶层的工作提高了性能,不管它们是由biLM还是MT编码器生成的,而ELMo表示提供了最佳的总体性能。
Sec 5.35 explores the different types of contextual information captured in biLMs and uses two intrinsic evaluations to show that syntactic information is better represented at lower layers while semantic information is captured a higher layers, consistent with MT encoders.
Sec 5.35探索了在biLMs中捕获的不同类型的上下文信息,并使用了两个内在的评价来表明,较低层次的语法信息更好地表示,而较高层次的语义信息则与MT编码器一致。
It also shows that our biLM consistently provides richer representations then CoVe.
它还表明我们的biLM始终提供比CoVe更丰富的表示。
Additionally, we analyze the sensitivity to where ELMo is included in the task model (Sec 5.2), training set size (Sec 5.4), and visualize the ELMo learned weights across the tasks (Sec 5.5).
此外,我们还分析了ELMo在任务模型中位置的敏感性(Sec 5.2)、训练集大小(Sec 5.4),并可视化了ELMo在任务中学习到的权重(Sec 5.5)。
5.1 Alternate layer weighting schemes
There are many alternatives to Equation 1 for combining the biLM layers.
对于结合biLM层,有许多方法可以替代公式1。
Previous work on contextual representations used only the last layer, whether it be from a biLM (Peters et al, 2017) or an MT encoder (CoVe, McCann et al, 2017).
之前关于上下文表示的工作只使用了最后一层,无论是biLM (Peters et al, 2017)还是MT编码器(CoVe, McCann et al, 2017)。
The choice of the regularization parameter λ is also important, as large values such as λ = 1 effectively reduce the weighting function to a simple average over the layers, while smaller values (eg, λ = 0.001) allow the layer weights to vary.
正则化参数λ的选择也很重要,等大值λ= 1有效降低权重函数简单的平均层,而更小的值(例如,λ= 0.001)允许层权重有所不同。
Table 2 compares these alternatives for SQuAD, SNLI and SRL.
表2比较了阵容、SNLI和SRL的选择。
Including representations from all layers improves overall performance over just using the last layer, and including contextual representations from the last layer improves performance over the baseline.
包含所有层的表示可以提高最后一层的总体性能,包含最后一层的上下文表示可以提高基线的性能。
For example, in the case of SQuAD, using just the last biLM layer improves development F1 by 3.9% over the baseline.
例如,在SQuAD的情况下,只使用最后一层biLM可以提高F1比基线提高3.9%。
Averaging all biLM layers instead of using just the last layer improves F1 another 0.3% (comparing “Last Only” to λ=1 columns), and allowing the task model to learn individual layer weights improves F1 another 0.2% (λ=1 vs. λ=0.001).
平均所有biLM层而不是仅仅使用最后一层提高F1另外0.3%(比较“最后只有“λ= 1列),并允许任务模型学习个体层权重提高F1另外0.2%(λ= 1比λ= 0.001)。
A small λ is preferred in most cases with ELMo, although for NER, a task with a smaller training set, the results are insensitive to λ (not shown).
小λ与ELMo首选在大多数情况下,虽然NER,任务与一个较小的训练集,结果对λ(没有显示)。
The overall trend is similar with CoVe but with smaller increases over the baseline.
整体趋势与CoVe相似,但在基线上的增长幅度较小。
For SNLI, averaging all layers with λ=1 improves development accuracy from 88.2 to 88.7% over using just the last layer.
SNLI,所有层平均λ= 1改善发展精度从88.2到88.7%仅使用最后一层。
SRL F1 increased a marginal 0.1% to 82.2 for the λ=1 case compared to using the last layer only.
SRL F1边际0.1%上升到82.2λ= 1例相比,使用最后一层。
5.2 Where to include ELMo?
All of the task architectures in this paper include word embeddings only as input to the lowest layer biRNN.
本文中所有的任务体系结构都只将词嵌入作为最低层biRNN的输入。
However, we find that including ELMo at the output of the biRNN in task-specific architectures improves overall results for some tasks.
然而,我们发现在任务特定的体系结构中,将ELMo包含在biRNN的输出中可以改善某些任务的总体结果。
As shown in Table 30, including ELMo at both the input and output layers for SNLI and SQuAD improves over just the input layer, but for SRL (and coreference resolution, not shown) performance is highest when it is included at just the input layer.
如表30所示,为SNLI和SQuAD在输入层和输出层都包含了ELMo,这在输入层上得到了改进,但是对于SRL(和coreference分辨率,没有显示),当它只包含在输入层上时,性能是最高的。
One possible explanation for this result is that both the SNLI and SQuAD architectures use attention layers after the biRNN, so introducing ELMo at this layer allows the model to attend directly to the biLM’s internal representations.
一个可能的解释是SNLI和小队架构在biRNN之后都使用了注意力层,所以在这一层引入ELMo允许模型直接关注biLM的内部表现。
In the SRL case, the task-specific context representations are likely more important than those from the biLM.
在SRL的情况下,特定于任务的上下文表示可能比来自biLM的上下文表示更重要。

Table 4: Nearest neighbors to “play” using GloVe and the context embeddings from a biLM.
表4:使用GloVe和来自biLM的上下文嵌入来“玩”。

Table 5: All-words fine grained WSD F1.
表5:全词细粒度WSD F1。
For CoVe and the biLM, we report scores for both the first and second layer biLSTMs.
对于CoVe和biLM,我们报告第一层和第二层biLSTMs的评分。
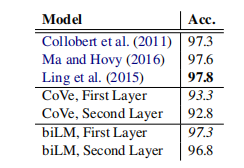
Table 6: Test set POS tagging accuracies for PTB.
表6:测试集PTB的词性标注精度。
For CoVe and the biLM, we report scores for both the first and second layer biLSTMs.
对于CoVe和biLM,我们报告第一层和第二层biLSTMs的评分。
5.3 What information is captured by the biLM’s representations?
Since adding ELMo improves task performance over word vectors alone, the biLM’s contextual representations must encode information generally useful for NLP tasks that is not captured in word vectors.
由于添加ELMo可以提高任务性能,因此biLM的上下文表示必须对那些在单词向量中没有捕获的NLP任务有用的信息进行编码。
Intuitively, the biLM must be disambiguating the meaning of words using their context.
直观地说,biLM必须通过上下文消除单词的歧义。
Consider “play”, a highly polysemous word.
以“play”为例,这是一个高度多义词。
The top of Table 43 lists nearest neighbors to “play” using GloVe vectors.
表43的顶部列出了使用GloVe向量进行“游戏”的最近的邻居。
They are spread across several parts of speech (eg, “played”, “playing” as verbs, and “player”, “game” as nouns) but concentrated in the sportsrelated senses of “play”.
它们分布在一些词类中(如“play”,“playing”作为动词,“player”,“game”作为名词,但集中在与体育相关的“play”的意义上。
In contrast, the bottom two rows show nearest neighbor sentences from the SemCor dataset (see below) using the biLM’s context representation of “play” in the source sentence.
相反,下面的两行显示来自SemCor数据集(见下文)的最近邻的句子,使用的是源句中“play”的biLM上下文表示。
In these cases, the biLM is able to disambiguate both the part of speech and word sense in the source sentence.
在这些情况下,biLM能够消除源句中词性和词义的歧义。
These observations can be quantified using an intrinsic evaluation of the contextual representations similar to Belinkov et al (2017).
这些观察结果可以使用类似于Belinkov等人(2017)的上下文表示的内在评价来量化。
To isolate the information encoded by the biLM, the representations are used to directly make predictions for a fine grained word sense disambiguation (WSD) task and a POS tagging task.
为了隔离biLM编码的信息,这些表示形式被用来直接预测细粒度的词义消歧(WSD)任务和词性标记任务。
Using this approach, it is also possible to compare to CoVe, and across each of the individual layers.
使用这种方法,它也可以与CoVe进行比较,并跨越每个单独的层。
Word sense disambiguation Given a sentence, we can use the biLM representations to predict the sense of a target word using a simple 1nearest neighbor approach, similar to Melamud0) et al(2016).
在给定一个句子的情况下,我们可以使用biLM表示来预测目标单词的意义,使用一个简单的最近邻方法,类似于Melamud0等(2016)。
To do so, we first use the biLM to compute representations for all words in SemCor 3.0, our training corpus (Miller et al4), 1994, and then take the average representation for each sense.
为此,我们首先使用biLM来计算SemCor 3.0(我们的训练语料库)中所有单词的表示(Miller et al, 1994),然后取每种意义的平均表示。
At test time, we again use the biLM to compute representations for a given target word and take the nearest neighbor sense from the training set, falling back to the first sense from WordNet for lemmas not observed during training.
在测试时,我们再次使用biLM来计算给定目标单词的表示,并从训练集中获取最近邻的感觉,对于训练期间没有观察到的引理,则回落到WordNet中的第一个感觉。
Table 5 compares WSD results using the evaluation framework from Raganato et al(2017b) across the same suite of four test sets in Raganato et al (2017a).
表5使用Raganato等人(2017b)的评估框架比较了WSD的结果,该评估框架使用了Raganato等人(2017a)的同一套四个测试集。
Overall, the biLM top layer representations have F1 of 69.0 and are better at WSD then the first layer.
总的来说,biLM顶层的表面层的F1值为69.0,在WSD上比第一层表现得更好。
This is competitive with a state-of-the-art WSD-specific supervised model using hand crafted features (Iacobacci et al6), 2016) and a task specific biLSTM that is also trained with auxiliary coarse-grained semantic labels and POS tags (Raganato et al, 2017a).
这与使用手工特性的最先进的特定于wsd的监督模型(Iacobacci et al6, 2016)和使用辅助粗粒度语义标签和POS标记训练的特定于任务的biLSTM (Raganato et al, 2017a)形成了竞争。
The CoVe biLSTM layers follow a similar pattern to those from the biLM (higher overall performance at the second layer compared to the first), however, our biLM outperforms the CoVe biLSTM, which trails the WordNet first sense baseline.
CoVe biLSTM层的模式与来自biLM层的模式类似(第二层的总体性能比第一层更高),但是,我们的biLM优于CoVe biLSTM,后者落后于WordNet first sense基线。
POS tagging
To examine whether the biLM captures basic syntax, we used the context representations as input to a linear classifier that predicts POS tags with the Wall Street Journal portion of the Penn Treebank (PTB Marcus et al, 1993).
为了检验biLM是否捕获了基本语法,我们使用上下文表示作为线性分类器的输入,该分类器使用Penn Treebank的华尔街日报部分预测POS标记(PTB Marcus et al, 1993)。
As the linear classifier adds only a small amount of model capacity, this is direct test of the biLM’s representations.
由于线性分类器只增加了少量的模型容量,这是对biLM表示的直接检验。
Similar to WSD, the biLM representations are competitive with carefully tuned, task specific biLSTMs (Ling et al, 2015, Ma and Hovy, 2016).
与WSD类似,biLM表示与经过仔细调优的特定任务的biLSTMs具有竞争性(Ling et al, 2015, Ma和Hovy, 2016)。
However, unlike WSD, accuracies using the first biLM layer are higher than the top layer, consistent with results from deep biLSTMs in multi-task training (Søgaard and Goldberg, 2016, Hashimoto et al, 2017) and MT (Belinkov et al, 2017).
但是,与WSD,精度使用第一个biLM层高于顶层,深biLSTMs一致的结果在多任务训练(Goldberg等Søgaard和Hashimoto ,2016年,2017年)和(Belinkov等,2017)。
CoVe POS tagging accuracies follow the same pattern as those from the biLM, and just like for WSD, the biLM achieves higher accuracies than the CoVe encoder.
CoVe POS标签精度遵循与来自biLM相同的模式,就像WSD一样,biLM实现了比CoVe编码器更高的精度。
Implications for supervised tasks
Taken together, these experiments confirm different layers in the biLM represent different types of information and explain why including all biLM layers is important for the highest performance in downstream tasks.
综上所述,这些实验证实了biLM中的不同层代表不同类型的信息,并解释了为什么包含所有的biLM层对于下游任务的最高性能非常重要。
In addition, the biLM’s representations are more transferable to WSD and POS tagging than those in CoVe, helping to illustrate why ELMo outperforms CoVe in downstream tasks.
此外,与CoVe相比,biLM的表示更适合于WSD和POS标记,这有助于说明为什么ELMo在下游任务中表现优于CoVe。
5.4 Sample efficiency
Adding ELMo to a model increases the sample efficiency considerably, both in terms of number of parameter updates to reach state-of-the-art performance and the overall training set size.
将ELMo添加到模型中可以极大地提高样本效率,无论是为了达到最新性能而进行的参数更新的数量,还是整个训练集的大小。
For example, the SRL model reaches a maximum development F1 after 486 epochs of training without ELMo.
例如,在没有ELMo的情况下,SRL模型在经过486个周期的训练后达到最大的F1发展。
After adding ELMo, the model exceeds the baseline maximum at epoch 10, a 98% relative decrease in the number of updates needed to reach the same level of performance.
添加ELMo后,模型在epoch 10时超过了基线最大值,达到相同性能水平所需的更新数量相对减少了98%。
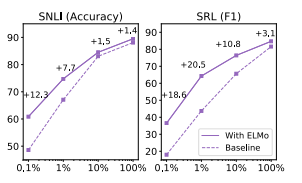
Figure 1: Comparison of baseline vs. ELMo performance for SNLI and SRL as the training set size is varied from 0.1% to 100%.
图1:训练集大小为0.1%到100%时,SNLI和SRL的基线与ELMo性能的比较。
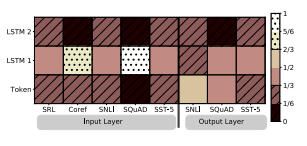
Figure 2: Visualization of softmax normalized biLM layer weights across tasks and ELMo locations.
图2:跨任务和ELMo位置的softmax规范化biLM层权重的可视化。
Normalized weights less then 1/3 are hatched with horizontal lines and those greater then 2/3 are speckled.
小于1/3的归一化权重用水平线表示,大于2/3的归一化权重用斑点表示。
In addition, ELMo-enhanced models use smaller training sets more efficiently than models without ELMo.
此外,与没有ELMo的模型相比,ELMo增强的模型更有效地使用更小的训练集。
Figure 1 compares the performance of baselines models with and without ELMo as the percentage of the full training set is varied from 0.1% to 100%.
图1比较了有和没有ELMo的基线模型的性能,因为整个训练集的百分比从0.1%到100%不等。
Improvements with ELMo are largest for smaller training sets and significantly reduce the amount of training data needed to reach a given level of performance.
ELMo最大的改进是针对更小的训练集,并显著减少了达到给定性能水平所需的训练数据量。
In the SRL case, the ELMo model with 1% of the training set has about the same F1 as the baseline model with 10% of the training set.
在SRL的情况下,包含1%训练集的ELMo模型与包含10%训练集的基线模型的F1值大致相同。
5.5 Visualization of learned weights
Figure 2 visualizes the softmax-normalized learned layer weights.
图2显示了softmax规范化的学习层权重。
At the input layer, the task model favors the first biLSTM layer.
在输入层,任务模型倾向于第一个biLSTM层。
For coreference and SQuAD, the this is strongly favored, but the distribution is less peaked for the other tasks.
对于coreference和SQuAD, 是非常受欢迎的,但是对于其他任务来说,它的分布并没有达到峰值。
The output layer weights are relatively balanced, with a slight preference for the lower layers.
输出层的权重相对平衡,较低的层略有偏好。
6 Conclusion
We have introduced a general approach for learning high-quality deep context-dependent representations from biLMs, and shown large improvements when applying ELMo to a broad range of NLP tasks.
我们介绍了一种从biLMs中学习高质量的上下文相关表示的通用方法,并在将ELMo应用于广泛的NLP任务时展示了巨大的改进。
Through ablations and other controlled experiments, we have also confirmed that the biLM layers efficiently encode different types of syntactic and semantic information about wordsin-context, and that using all layers improves overall task performance.
通过ablations和其他控制实验,我们也证实了biLM层可以有效地编码关于wordsin-context的不同类型的语法和语义信息,并且使用所有层可以提高整体任务性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号