Redis安装及使用
使用
安装
下载:
wget http://download.redis.io/releases/redis-3.2.10.tar.gz
解压:
tar xzf redis-3.2.10.tar.gz mv redis-3.2.10 redis
安装:
cd redis make
启动:
src/redis-server & # &后台启动,启动后可以ctrl+c退出
重启
# 连接redis后 shutdown exit /application/redis/src/redis-cli -p 1111
配置文件使用
创建文件,写入内容
是否后台运行: daemonize yes 默认端口: port 6379 日志文件位置 logfile /var/log/redis.log RDB持久化数据文件: dbfilename dump.rdb 持久化文件的位置: dir /data/redis
配置文件的使用
/application/redis/src/redis-server /etc/redis.conf # 启动redis时指定配置文件 /application/redis/src/redis-cli -p 1111 # 连接redis
安全配置
bind 10.0.0.200 127.0.0.1 # 指定IP进行监听 protected-mode yes/no # 保护模式,是否只允许本地访问,默认为yes,设置band后变为no requirepass 123 # 设置密码
重启后登录
src/redis-cli -h 10.0.0.200 -p 1111 # ip端口 # 验证密码的两种方式 src/redis-cli -h 10.0.0.200 -p 1111 -a 123 # ip 端口 密码 # 二 src/redis-cli -h 10.0.0.200 -p 1111 auth 123
在线修改配置
在线只可修改部分配置
# 修改密码实例 CONFIG GET * # 获取当前配置 CONFIG SET requirepass 123456 # 设置密码
db0-15
redis下,数据库是由一个整数索引标识,而不是由一个数据库名称。默认情况下,一个客户端连接到数据库0。
切换db select 15
不过这并没什么卵用,看一下就好了
redis持久化
RDB持久化
基于时间点快照的方式,复用方式进行数据持久化
比较常用的方式,效率较高,安全性相对较低
配置信息
dbfilename dump.rdb # rdb文件名 dir /data/redis # rdb的放置路径 save 900 1 # 900秒(15分钟)内有1个更改 save 300 10 # 300秒(5分钟)内有10个更改 save 60 10000 # 60秒内有10000个更改
AOF持久化
只追加的方式记录所有redis中执行过的修改类命令
效率相对较低,安全性较高
配置信息
appendonly yes
appendfsync {always:每次修改更新,everysec:每秒更新,no:不会更新}
redis不重启, 将rdb备份切换到aof备份
--在redis2.2以上版本, 可以通过config set可以在不重启的情况下,从rdb切换到aof. config set appendonly yes -- 开启aof功能,redis会阻塞,直到初始Aof文件创建完为止 config set save "" -- 关闭rdb, 你可以选择同时使用rdb和aof两种方式 -- 配置完之后, 不要忘了在conf中打开aof, 不然重启后通过config set设置的配置会被遗忘
数据类型
全局类操作
KEYS * 查看KEY支持通配符 DEL 删除给定的一个或多个key EXISTS 检查是否存在 RENAME 变更KEY名 TYPE 返回键所存储值的类型 EXPIRE\ PEXPIRE 以秒\毫秒设定生存时间 TTL\ PTTL 以秒\毫秒为单位返回生存时间 PERSIST 取消生存时间设置
管理类操作
Info Clinet list Client kill ip:port config get * CONFIG RESETSTAT 重置统计 CONFIG GET/SET 动态修改 Dbsize FLUSHALL 清空所有数据 select 1 FLUSHDB 清空当前库 MONITOR 监控实时指令 SHUTDOWN 关闭服务器 save将当前数据保存 SLAVEOF host port 主从配置 SLAVEOF NO ONE SYNC 主从同步 ROLE返回主从角色
string
增 set mykey "test" 为键设置新值,并覆盖原有值 getset mycounter 0 设置值,取值同时进行 setex mykey 10 "hello" 设置指定 Key 的过期时间为10秒,在存活时间可以获取value setnx mykey "hello" 若该键不存在,则为键设置新值 mset key3 "zyx" key4 "xyz" 批量设置键 删 del mykey 删除已有键 改 append mykey "hello" 若该键并不存在,返回当前 Value 的长度 该键已经存在,返回追加后 Value的长度 incr mykey 值增加1,若该key不存在,创建key,初始值设为0,增加后结果为1 decrby mykey 5 值减少5 setrange mykey 20 dd 把第21和22个字节,替换为dd, 超过value长度,自动补0 查 exists mykey 判断该键是否存在,存在返回 1,否则返回0 get mykey 获取Key对应的value strlen mykey 获取指定 Key 的字符长度 ttl mykey 查看一下指定 Key 的剩余存活时间(秒数) getrange mykey 1 20 获取第2到第20个字节,若20超过value长度,则截取第2个和后面所有的 mget key3 key4 批量获取键
应用场景:常规计数:微博数,粉丝数等
HASH类型
增 hset myhash field1 "s" 若字段field1不存在,创建该键及与其关联的Hashes, Hashes中,key为field1 ,并设value为s ,若存在会覆盖原value hsetnx myhash field1 s 若字段field1不存在,创建该键及与其关联的Hashes, Hashes中,key为field1 ,并设value为s, 若字段field1存在,则无效 hmset myhash field1 "hello" field2 "world 一次性设置多个字段 删 hdel myhash field1 删除 myhash 键中字段名为 field1 的字段 del myhash 删除键 改 hincrby myhash field 1 给field的值加1 查 hget myhash field1 获取键值为 myhash,字段为 field1 的值 hlen myhash 获取myhash键的字段数量 hexists myhash field1 判断 myhash 键中是否存在字段名为 field1 的字段 hmget myhash field1 field2 field3 一次性获取多个字段 hgetall myhash 返回 myhash 键的所有字段及其值 hkeys myhash 获取myhash 键中所有字段的名字 hvals myhash 获取 myhash 键中所有字段的值
应用场景:
存储部分变更的数据,如用户信息等。需要将MySQL表数据进行缓存时,可以使用此种数据类型。
list
增 lpush mykey a b 若key不存在,创建该键及与其关联的List,依次插入a ,b, 若List类型的key存在,则插入value中 lpushx mykey2 e 若key不存在,此命令无效, 若key存在,则插入value中 linsert mykey before a a1 在 a 的前面插入新元素 a1 linsert mykey after e e2 在e 的后面插入新元素 e2 rpush mykey a b 在链表尾部先插入b,在插入a rpushx mykey e 若key存在,在尾部插入e, 若key不存在,则无效 rpoplpush mykey mykey2 将mykey的尾部元素弹出,再插入到mykey2 的头部(原子性的操作) 删 del mykey 删除已有键 lrem mykey 2 a 从头部开始找,按先后顺序,值为a的元素,删除数量为2个,若存在第3个,则不删除 ltrim mykey 0 2 从头开始,索引为0,1,2的3个元素,其余全部删除 改 lset mykey 1 e 从头开始, 将索引为1的元素值,设置为新值 e,若索引越界,则返回错误信息 rpoplpush mykey mykey 将 mykey 中的尾部元素移到其头部 查 lrange mykey 0 -1 取链表中的全部元素,其中0表示第一个元素,-1表示最后一个元素。 lrange mykey 0 2 从头开始,取索引为0,1,2的元素 lrange mykey 0 0 从头开始,取第一个元素,从第0个开始,到第0个结束 lpop mykey 获取头部元素,并且弹出头部元素,出栈 lindex mykey 6 从头开始,获取索引为6的元素 若下标越界,则返回nil
应用场景
消息队列系统
比如sina微博:
在Redis中我们的最新微博ID使用了常驻缓存,这是一直更新的。
但是做了限制不能超过5000个ID,因此获取ID的函数会一直询问Redis。只有在start/count参数超出了这个范围的时候,才需要去访问数据库。
系统不会像传统方式那样“刷新”缓存,Redis实例中的信息永远是一致的。
SQL数据库(或是硬盘上的其他类型数据库)只是在用户需要获取“很远”的数据时才会被触发,而主页或第一个评论页是不会麻烦到硬盘上的数据库了。
集合
增 sadd myset a b c 若key不存在,创建该键及与其关联的set,依次插入a ,b,若key存在,则插入value中,若a 在myset中已经存在,则插入了 d 和 e 两个新成员。 删 spop myset 尾部的b被移出,事实上b并不是之前插入的第一个或最后一个成员 srem myset a d f 若f不存在, 移出 a、d ,并返回2 改 smove myset myset2 a 将a从 myset 移到 myset2, 查 sismember myset a 判断 a 是否已经存在,返回值为 1 表示存在。 smembers myset 查看set中的内容 scard myset 获取Set 集合中元素的数量 srandmember myset 随机的返回某一成员 sdiff myset1 myset2 myset3 1和2得到一个结果,拿这个集合和3比较,获得每个独有的值 sdiffstore diffkey myset myset2 myset3 3个集和比较,获取独有的元素,并存入diffkey 关联的Set中 sinter myset myset2 myset3 获得3个集合中都有的元素 sinterstore interkey myset myset2 myset3 把交集存入interkey 关联的Set中 sunion myset myset2 myset3 获取3个集合中的成员的并集 sunionstore unionkey myset myset2 myset3 把并集存入unionkey 关联的Set中
应用场景:
案例:
在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。
Redis还为集合提供了求交集、并集、差集等操作,可以非常方便的实现如共同关注、共同喜好、二度好友等功能,
对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
有序集合
增
zadd myzset 2 "two" 3 "three" 添加两个分数分别是 2 和 3 的两个成员
删
zrem myzset one two 删除多个成员变量,返回删除的数量
改
zincrby myzset 2 one 将成员 one 的分数增加 2,并返回该成员更新后的分数
查
zrange myzset 0 -1 WITHSCORES 返回所有成员和分数,不加WITHSCORES,只返回成员
zrank myzset one 获取成员one在Sorted-Set中的位置索引值。0表示第一个位置
zcard myzset 获取 myzset 键中成员的数量
zcount myzset 1 2 获取分数满足表达式 1 <= score <= 2 的成员的数量
zscore myzset three 获取成员 three 的分数
zrangebyscore myzset 1 2 获取分数满足表达式 1 < score <= 2 的成员
#-inf 表示第一个成员,+inf最后一个成员
#limit限制关键字
#2 3 是索引号
zrangebyscore myzset -inf +inf limit 2 3 返回索引是2和3的成员
zremrangebyscore myzset 1 2 删除分数 1<= score <= 2 的成员,并返回实际删除的数量
zremrangebyrank myzset 0 1 删除位置索引满足表达式 0 <= rank <= 1 的成员
zrevrange myzset 0 -1 WITHSCORES 按位置索引从高到低,获取所有成员和分数
#原始成员:位置索引从小到大
one 0
two 1
#执行顺序:把索引反转
位置索引:从大到小
one 1
two 0
#输出结果: two
one
zrevrange myzset 1 3 获取位置索引,为1,2,3的成员
#相反的顺序:从高到低的顺序
zrevrangebyscore myzset 3 0 获取分数 3>=score>=0的成员并以相反的顺序输出
zrevrangebyscore myzset 4 0 limit 1 2 获取索引是1和2的成员,并反转位置索引
应用场景:
排行榜应用,取TOP N操作
这个需求与上面需求的不同之处在于,前面操作以时间为权重,这个是以某个条件为权重,
比如按顶的次数排序,这时候就需要我们的sorted set出马了,将你要排序的值设置成sorted set的score,将具体的数据设置成相应的value,每次只需要执行一条ZADD命令即可。
发布订阅模式的消息队列
PUBLISH channel msg # 将信息 message 发送到指定的频道 channel SUBSCRIBE channel [channel ...] # 订阅频道,可以同时订阅多个频道 PSUBSCRIBE pattern [pattern ...] # 订阅一个或多个符合给定模式的频道,每个模式以 * 作为匹配符,比如 it* 匹配所 有以 it 开头的频道( it.news 、 it.blog 、 it.tweets 等等), news.* 匹配所有 以 news. 开头的频道( news.it 、 news.global.today 等等),诸如此类 PUNSUBSCRIBE [pattern [pattern ...]] # 退订指定的规则, 如果没有参数则会退订所有规则 PUBSUB sub command [argument [argument ...]] # 查看订阅与发布系统状态
注意:使用发布订阅模式实现的消息队列,当有客户端订阅channel后只能收到后续发布到该频道的消息,之前发送的不会缓存,必须Provider和Consumer同时在线。
事务
WATCH key [key ...] 监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。 UNWATCH 取消 WATCH 命令对所有 key 的监视。 MULTI 标记一个事务块的开始。 DISCARD 取消事务,放弃执行事务块内的所有命令。 EXEC 执行所有事务块内的命令。
命令示例
redis 127.0.0.1:6379> watch ticket
OK
redis 127.0.0.1:6379> multi
OK
redis 127.0.0.1:6379> decr ticket
QUEUED # 这是加入队列,并没有修改
redis 127.0.0.1:6379> decrby money 100
QUEUED
# 如果另一个窗口将ticket的值改动了
redis 127.0.0.1:6379> exec
(nil) // 返回nil,说明监视的ticket已经改动了,事务就取消了.队列就不执行了。
主从复制及集群搭建
主从赋值redis-sentinel集群
基于RDB的快照技术,但是不依赖于RDB持久化。当主服务器宕机在从服务器选出一个最为主服务器,主服务器开启后会变成从服务器
应用示例
# 配置文件 bind 127.0.0.1 10.0.0.200 port 6382 # 可以在一台机器上使用不同的端口号来启动redis,模仿多个主机 daemonize yes pidfile /data/6382/redis.pid loglevel notice logfile "/data/6382/redis.log" dbfilename dump.rdb dir /data/6382 appendonly no appendfilename "appendonly.aof" appendfsync everysec slowlog-log-slower-than 10000 slowlog-max-len 128 protected-mode no
进入从服务器redis的命令行
SLAVEOF 127.0.0.1 6380 # 主服务器IP,端口
安放哨兵-哨兵用来监测主从服务器状态,以及变更主从服务器
# 哨兵配置信息 port 26380 dir "/tmp" sentinel monitor mymaster[主机名字] 127.0.0.1[IP] 6380[端口] 1[几个哨兵判断生效] sentinel down-after-milliseconds mymaster 5000[验证时间] sentinel config-epoch mymaster 0 # 指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步 #可选的安全连接密码 #sentinel auth-pass mymaster xxx
启动哨兵
cp /application/redis/src/redis-sentinel /data/26380 cd /data/26380 ./redis-sentinel ./sentinel.conf # 哨兵配置文件, ----port 端口
在哨兵中查看当前主服务器相关信息:
redis-cli -p 26380 # 与连接redis一样,连接哨兵端口 127.0.0.1:26380> sentinel masters
python连接连接redis-sentinel集群
安装redis的python驱动:点这里
安装
unzip redis-py-master.zip cd redis-py-master python3 setup.py install
使用
from redis.sentinel import Sentinel
sentinel = Sentinel([('localhost', 26380)], socket_timeout=0.1) # 连接烧饼
sentinel.discover_master('mymaster') # 根据主机名返回主机信息元组
sentinel.discover_slaves('mymaster') # 返回丛机信息元组的列表
master = sentinel.master_for('mymaster', socket_timeout=0.1)
slave = sentinel.slave_for('mymaster', socket_timeout=0.1)
master.set('foo', 'bar')
slave.get('foo')
redis-cluster集群搭建
了解
Redis 集群是一个可以在多个 Redis 节点之间进行数据共享的设施(installation)。 Redis 集群不支持那些需要同时处理多个键的 Redis 命令, 因为执行这些命令需要在多个 Redis 节点之间移动 数据, 并且在高负载的情况下, 这些命令将降低 Redis 集群的性能, 并导致不可预测的行为。 Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者 无法进行通讯, 集群也可以继续处理命令请求。 将数据自动切分(split)到多个节点的能力。 当集群中的一部分节点失效或者无法进行通讯时, 仍然可以继续处理命令请求的能力 Redis 集群使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现: 一个 Redis 集群包 含 16384 个哈希槽(hash slot), 数据库中的每个键都属于这 16384 个哈希槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验 和 。 节点 A 负责处理 0 号至 5500 号哈希槽。 节点 B 负责处理 5501 号至 11000 号哈希槽。 节点 C 负责处理 11001 号至 16384 号哈希槽。
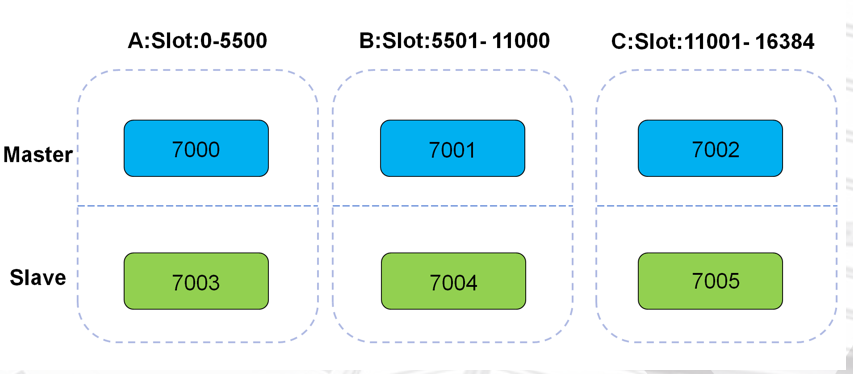
创建集群
安装集群软件
# EPEL源安装ruby支持 yum install ruby rubygems -y # 使用国内源 gem sources -a http://mirrors.aliyun.com/rubygems/ gem sources --remove http://rubygems.org/ gem sources -l gem install redis -v 3.3.3
redis配置文件
port 7000 daemonize yes pidfile /data/7000/redis.pid logfile "/var/log/redis7000.log" dbfilename dump.rdb dir /data/7000 cluster-enabled yes # 开实例的集群模式 cluster-config-file nodes.conf # 保存节点配置文件的路径 cluster-node-timeout 5000 appendonly yes
启动6个节点(要让集群正常运作至少需要三个主节点,另外三个做为从节点)
/application/redis/src/redis-server /data/7000/redis.conf /application/redis/src/redis-server /data/7001/redis.conf /application/redis/src/redis-server /data/7002/redis.conf /application/redis/src/redis-server /data/7003/redis.conf /application/redis/src/redis-server /data/7004/redis.conf /application/redis/src/redis-server /data/7005/redis.conf
ps -ef |grep 700
创建集群
/application/redis/src/redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 \ 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 # 选项–replicas 1 表示我们希望为集群中的每个主节点创建一个从节点 # 之后跟着的其他参数则是这个集群实例的地址列表,3个master3个slave redis-trib 会打印出一份预想中的配 # 置给你看, 如果你觉得没问题的话, 就可以输入 yes
集群状态查看
/application/redis/src/redis-cli -p 7000 cluster nodes | grep master /application/redis/src/redis-cli -p 7000 cluster nodes | grep slave
python连接
redis-py并没有提供redis-cluster的支持,点这里
安装
unzip redis-py-cluster-unstable.zip cd redis-py-cluster-unstable python3 setup.py install
使用
from rediscluster import StrictRedisCluster
startup_nodes = [{"host": "127.0.0.1", "port": "7000"}]
# python3 中decode_responses=True
rc = StrictRedisCluster(startup_nodes=startup_nodes, decode_responses=True)
rc.set("foo", "bar")
print(rc.get("foo"))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号