知识点汇总
基础部分
Python介绍
python是一门解释型(程序运行时一行一行的解释,并运行),动态类型(在程序执行过程中,可以改变变量的类型)的语言,他的语法比较优美,没有那么多的{}的嵌套,而是使用了缩进
python2和3的一些区别
# print语句被python3废弃,统一使用print函数
# exec语句被python3废弃,统一使用exec函数
# execfile语句被Python3废弃,推荐使用exec(open("./filename").read())
# 不相等操作符"<>"被Python3废弃,统一使用"!="
# long整数类型被Python3废弃,统一使用int
#xrange函数被Python3废弃,统一使用range,Python3中range的机制也进行修改并提高了大数据集生成效率
# raw_input函数被Python3废弃,统一使用input函数
# 字典变量的has_key函数被Python废弃,统一使用in关键词
# file函数被Python3废弃,统一使用open来处理文件,可以通过io.IOBase检查文件类型
# 异常StandardError 被Python3废弃,统一使用Exception
# python3的默认编码方式utf-8
# 整数除法>>2:取整,3:正常除法
# nonlocal关键字 >>python3中的函数可以使用nonlocal使内部函数修改外部的值
# yield from关键字 >>python3中yield from a 相当于for i in a:yield i
在看一些源码的过程中遇到的基本数据类型的方法
str
rsplit() # 反向分割字符串,比如Django中中间件的导入,还有spilt() startswith() # 判断是否以什么开头,比如wtform中使用此方法在dir(form)排除掉了以_开头的属性及方法 upper() # 全部大写,Django的配置文件,如果使用小写不会将他添加进配置字典中 strip() # 去空格 还有lstrip()和rstrip() join() # 将一个可迭代对象中的元素按指定字符拼接,
list
sort() # 排序,在wtforms中自己定义的form类被实例化时,会将其中字段按生成顺序排序,字段类的实例化过程需要注意一下 append() # 追加 pop() # 取出 insert() 插入 remove() # 根据值移除 reveser() # 反转列表
python的列表实际是开辟一块内存,其中存放的是元素的内存地址,当内存满了时会另外开辟一块内存,将之前的内容copy过去
tuple
tuple相当于不可变的列表,但是他内部可以嵌套可变的元素
另外列表和元组的索引取值如果超出会抛出异常,切片不会
dict
get() # 取值,可以设置默认值 setdefault() # 没有添加,有则返回原来的值,不会做修改 pop() # 根据键删除,并获取到值,可以设置默认值
set
集合和字典都是基于哈希表的,他们的值必须是不可变类型,并且不可重复
# 交集。(& 或者 intersection set1 & set2 set1.intersection(set2) # 并集。(| 或者 union) set1 | set2 set2.union(set1) # 反交集。 (^ 或者 symmetric_difference) set1 ^ set2 set1.symmetric_difference(set2)
更多数据类型
collections模块中提供了更多的数据类型
命名元组
P = namedtuple('Point',['x','y']) # 类名及为每个位置的元素起名
p1 = P(1,2)
print(p1.x) # 1
print(p1.y) # 2
print(type(p1)) # <class '__main__.Point'>
deque
# 双端队列,可以快速的从另外一侧追加和推出对象
from collections import deque
dq = deque()
dq.append('a')#追加
dq.append('b')
dq.appendleft('c')#添加在前面
print(dq)#deque(['c', 'a', 'b'])
print(dq.popleft())#c 从前边取
print(dq.pop())#b 从后边取
Counter
# Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素
作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)
c = Counter('abcdeabcdabcaba')
print(c)
# Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
OrderedDict(3.6后的字典是有序的)
from collections import OrderedDict
od = OrderedDict([('a', [1,2,3,4]), ('b', 2), ('c', 3)])
for k in od:
print(k,od[k])
# OrderedDict的key会按照插入顺序排列,不是key本身排序
defaultdict
#使用dict时,如果引用的key不存在,就会报错,如果希望key不存在时,返回一个默认值,就可以用defaultdict
#设置的默认值必须是一个可callble调用的,所以他可以是一个匿名函数
from collections import defaultdict
dd = defaultdict(lambda: 'N/A')
dd['key1'] = 'abc'
dd['key1'] # key1存在
#'abc'
dd['key2'] # key2不存在,返回默认值
#'N/A'
#有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的
#第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66 , 'k2': 小于66}
from collections import defaultdict
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = defaultdict(list) # list()返回一个空列表
for value in values:
if value>66:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value)
函数中容易被忽略的地方
函数参数的传递
d = (1,2)
def a(c):
print(id(c))
print(c is d)
a(d)
print(id(d))
# python中函数参数传递的是引用,返回的也是引用
def a(c):
return c
aaa = a(aa)
print(aa is aaa)
例外还存在一个函数参数默认值的问题
def a(z,b=[]):
b.append(z)
return b
c = a("1")
print(c) # ['1']
d = a("2")
print(d) # ['1', '2']
# 原因是函数在声明时创建了一个空列表,并不是每次调用时产生空列表
# 同理还有类的字段
import time
class Text:
time_ = time.time()
a = Text()
time.sleep(2)
b = Text()
print(a.time_==b.time_) # True
内置函数
enumertae:枚举,返回索引与值的元组
zip:拉链函数,接收多个可迭代对象,将对象相同索引位置放在一个元组中,返回一个迭代器,返回迭代器中元素个数由最短的可迭代对象决定
filter:过滤函数,接收一个函数和一个可迭代对象,生成一个迭代器.将可迭代对象的每一个元素带入函数中,如果返回结果为True,则把元素添加入迭代器中
map:处理函数,接收一个函数和一个可迭代对象,生成一个迭代器,将可迭代对象的每一个元素带入函数中,把返回值添加入迭代器中
callble:判断参数是不是可调用的
dir:查看内置属性和方法的字符串
super:根据__mro__属性去查找方法
isinstance:判断一个对象是不是这个类实例化出来的
iscubclass:判断一个类是不是另一个类的子类,也可以判断两个类是不是相同的类
property:在类中定义一个可控属性
class C(object):
def __init__(self):
self._x = None
def getx(self):
return self._x
def setx(self, value):
self._x = value
def delx(self):
del self._x
x = property(getx, setx, delx, "I'm the 'x' property.")
# 还和用作装饰器
class C(object):
def __init__(self):
self._x = None
@property
def x(self):
"""I'm the 'x' property."""
return self._x
@x.setter
def x(self, value):
self._x = value
@x.deleter
def x(self):
del self._x
装饰器的本质
一门语言中装饰器可以产生是因为一个函数可以参数传递给另一个函数,
这里是一篇之前的博客装饰器本质以及装饰器产生的问题
迭代器生成器
1.迭代器协议是指:对象必须提供一个next方法,执行方法要么返回迭代器中的下一项,要么就引起一个StopIteration异常,以终止迭代(只能往后走,不能往前退)
2.可迭代对象:实现了迭代器协议的对象(实现方式:对象内部定义了一个iter()方法)
之前写的博客同学,迭代器生成器了解一下
这里经常见到的问题就是关于列表和生成器表达式之间变量的问题
val = [lambda :i+1 for i in range(10)] # i是最后的i val = (lambda :i+1 for i in range(10)) # i是取到的i
单例模式
# 一个类只有一个实例存在。 # 可用的方式 # 使用 __new__ # 使用模块 # 使用装饰器(decorator) # 使用元类(metaclass)
面向对象与函数的比较
类的特点继承封装和多态
多态
class A:
def send(self):
pass
class B:
def send(self):
pass
def func(arg):
arg.send() # 同一操作作用于不同的对象,可以有不同的解释,产生不同的执行结果。
obj = B()
func(obj)
在封装这一特点中,类与函数相比,在参数的使用上还是比较方便的,比如:
- 当频繁对数据进行相同操作时,类的封装能减少参数的传递次数.
- 还有对数据进行加工时,获得多种值时最好也是用类的封装
方法与函数的区别:
- 方法是绑定的对象上的,由对象调用.
- 由类直接调用下面的方法算是使用他作用域下的函数,而并非方法
可以通过两个类来判断
from types import MethodType,FunctionType
class Foo(object):
def fetch(self):
pass
print(isinstance(Foo.fetch,MethodType))
print(isinstance(Foo.fetch,FunctionType)) # True
obj = Foo()
print(isinstance(obj.fetch,MethodType)) # True
print(isinstance(obj.fetch,FunctionType))
另外python还提供了一些内置方法,还有元类来控制类的产生
我遇到过的自己实现魔法方法最多的地方
# Flask中的LocalProxy()是我见过自己实现魔法方法最多的类 # request和session都是这个类的实例,他的对象通过他自己实现的魔法方法来修改_request_ctx_stack # 中的值
面向对象的其他部分
类的继承问题
在经典类中,是深度优先,先把一条线查完(栈,) 在新式类中,广度优先(顺着一条线查,如果还有别的路可以查到一个类,这条路就终止了,换一条线查) python3中都是新式类
super方法
# super()方法可以根据__mro__的继承关系去执行对象的方法
# super(Class,obj).func() # 会去根据obj的继承关系去执行func()方法,当然排除了括号中的Class
# 并且在类中使用super()可以不传参数,默认是当前类和self
class Base(object):
def func(self):
print("Base.func")
class Foo(Base):
def func1(self):
print("Foo.func")
class Bar(object):
def func(self):
print("Bar.func")
class CC(Foo,Bar):
def func(self):
print("CC.func")
super().func()
obj = CC()
obj.func()
# CC.func
# Base.func
super(CC,obj).func()
# Base.func
私有属性
__变量名这样的属性就是私有属性,在其子类的实例中不可以调用属性
class Base(object):
def __init__(self):
self.__age = 123
class Foo(Base):
def func(self):
print(self.__age)
obj = Foo()
obj.func()
# AttributeError: 'Foo' object has no attribute '_Foo__age'
# 当去调用__开头的属性时会自动加上_类名
进阶部分
常见的模块以及其中遇到的一些问题
常用的一些内置模块re(正则匹配),json(序列化),logging(日志),os(操作系统相关),sys(解释器相关)
另外还有做爬虫时遇到的requests(做请求),beautifulsoup4(解析HTML文本)
re模块中的贪婪匹配
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result1 = re.match('^He.*(\d+).*Demo$', content) # 贪婪匹配,尽可能多的匹配
result2 = re.match('^He.*?(\d+).*Demo$', content) # 非贪婪匹配,尽可能少的匹配
print(result1.group(1)) # 7
print(result2.group(1)) # 1234567
进程线程与协程
# 进程 一个任务,进程之间内存隔离,一个进程修改数据不会影响其他进程(创建变量,修改变量值) # 线程 线程位于进程内 一个进程内至少有一个线程,线程之间资源共享.一个线程修改数据其他进程也会受影响 所以有了锁的概念 # 协程 并发的本质是切换+保存状态 python的yield+send yield # 保存状态 send # 向生成器传递参数
GIL锁
全局解释器锁的本质是互斥锁,不过套在python解释器上的,这就使得同一时刻只有一个线程拿到python解释器的执行权限,就是同一时刻只有一个线程在执行,而Lock是套在代码段上,使得同一时刻只有一个线程来使用这个代码的功能。
就相当于你开两个python解释器,每个python解释器都会有一个GIL,在一个python解释器的进程内同一时刻只会有一个线程在使用解释器源码
进程池和线程池
一般来说,服务器的硬件资源相对充裕,很多时候我们使用以空间换时间的方法来提高服务器的性能,不惜浪费更多的空间以换取服务器运行效率。具体做法是提前保存大量的资源,以备不时之需以及重复使用。这就是池的概念。池是一组资源的集合,这组资源在服务器启动之初就已经被创建并初始化,这称为静态资源分配。当服务器正式运行,开始处理客户请求的时候,如果需要相关的资源,服务器就可以直接从池中获取,无需动态分配。动态分配即由系统实时分配资源,而右系统调用分配资源都是很耗时的。所以直接从池中取得资源比动态分配资源的效率更高。而且当服务器使用完资源后,可以直接放回资源池无需执行系统调用来释放资源。池相当于服务器系统调用管理资源,避免了服务器对内核的频繁访问,从而提高服务器性能。
由于在实际应用当中,分配内存、创建进程、线程都会设计到一些系统调用,系统调用需要程序从用户态切换到内核态,是非常耗时的操作。因此,当程序中需要频繁的进行内存申请释放,进程、线程创建销毁等操作时,通常会使用内存池、进程池、线程池技术来提升程序的性能。
异步非阻塞
阻塞
#阻塞调用是指调用结果返回之前,当前线程会被挂起(如遇到io操作)
同步
# 所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不会返回。 # 对于同步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回而已。
非阻塞
# 非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前也会立刻返回,同时该函数不会阻塞当前线程
异步
#异步的概念和同步相对。当一个异步功能调用发出后,调用者不能立刻得到结果。当该异步功能完成后,通过状态、 通知或回调来通知调用者。
三次握手四次挥手
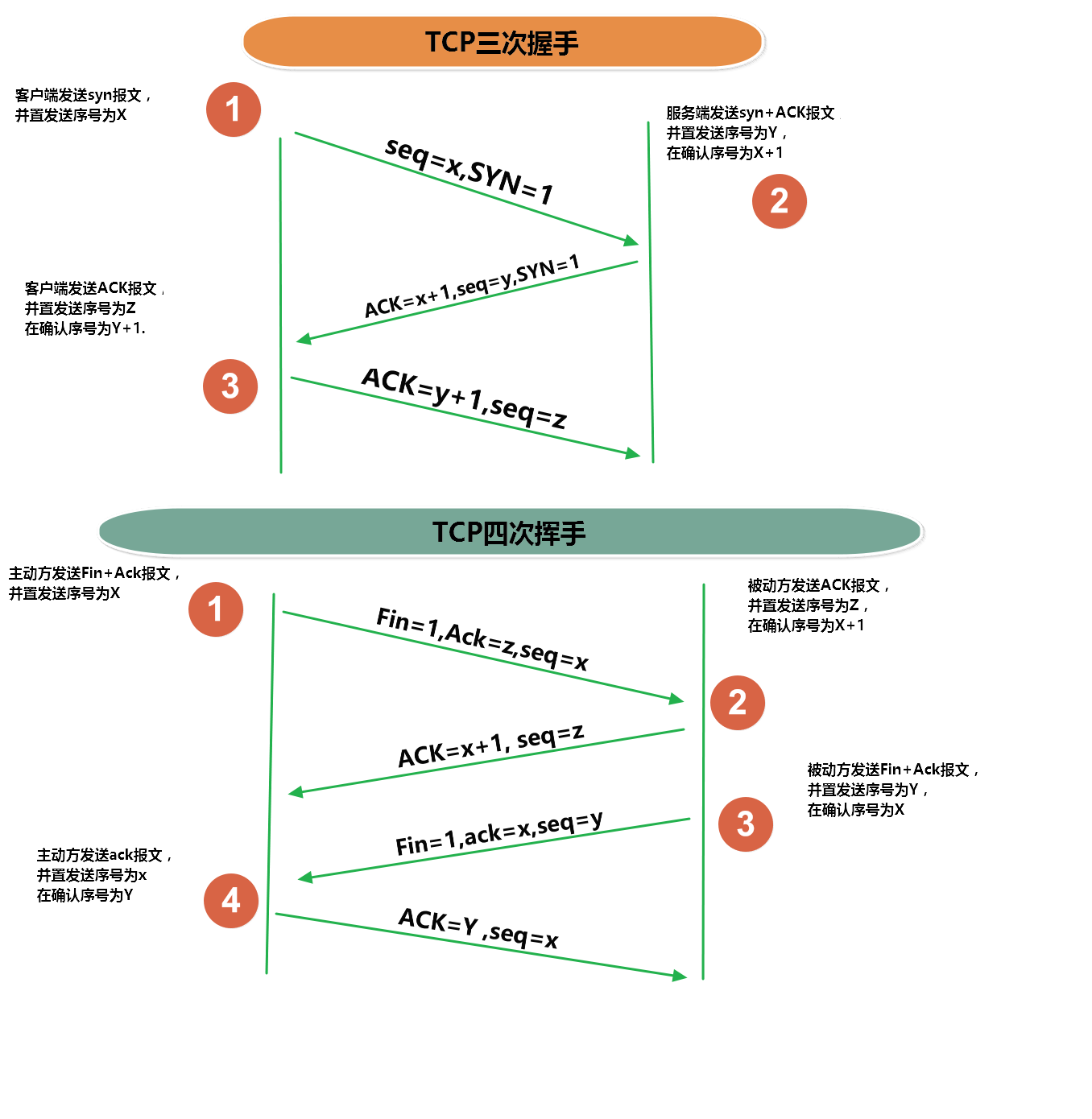
三次握手
第一次握手:Client什么都不能确认;Server确认了对方发送正常 第二次握手:Client确认了:自己发送、接收正常,对方发送、接收正常;Server确认了:自己接收正常,对方发送正常 第三次握手:Client确认了:自己发送、接收正常,对方发送、接收正常;Server确认了:自己发送、接收正常,对方发送接收正常
四次挥手
# 四次握手之所以比三次握手多一步,是因为服务端要等待数据发送完毕 客户端:我要离开你了 服务端:...我知道了, # 服务端把客户端想要的东西全部给他以后 服务端:你走吧 客户端:再见
TCP协议与UDP协议
TCP(控制传输协议)
面向连接的套接字,即在通信前建立一条连接(TCP的三次握手和四次挥手)
# 服务端
import socket
ip_port=('127.0.0.1',9000) # IP端口
BUFSIZE=1024 #收发消息的尺寸
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) #创建服务器套接字
s.bind(ip_port) #把地址绑定到套接字
s.listen(5) # 监听链接
conn,addr=s.accept() # 接受客户端链接
# print(conn) socket对象
# print(addr) 客户端的IP端口
msg=conn.recv(BUFSIZE) #接收信息
conn.send(msg.upper()) #发送信息
conn.close() #关闭连接
s.close() #关闭套接字
# 客户端
import socket
ip_port=('127.0.0.1',9000)
BUFSIZE=1024
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) # 创建客户端套接字
s.connect(ip_port) # 连接服务器
s.send('linhaifeng nb'.encode('utf-8')) # 发送消息(只能发送字节类型)
feedback=s.recv(BUFSIZE) # 收消息
s.close() # 挂电话
UDP(用户数据报协议)
是无连接的,面向消息的,提供高效率服务。
# 服务端
from socket import *
server=socket(AF_INET,SOCK_DGRAM)
server.bind(('127.0.0.1',8083))
data,client_addr=server.recvfrom(1024) # recvfrom 收到的内容第一个元素是对面发送的内容,第二个是对面的ip端口元组
server.sendto(data.upper(),client_addr) #sendto 第一个参数是要发送内容,第二个是目标ip端口元组
# 客户端
from socket import *
client=socket(AF_INET,SOCK_DGRAM)
client.sendto(msg.encode('utf-8'),('127.0.0.1',8083)) #sendto 第一个参数是要发送内容,第二个是目标ip端口元组
data,server_addr=client.recvfrom(1024) # recvfrom 收到的内容第一个元素是对面发送的内容,第二个是对面的ip端口元组
比较
udp的recvfrom是阻塞的,一个recvfrom(x)必须对唯一一个sendinto(y),收完了x个字节的数据就算完成,若是y>x数据就丢失,这意味着udp根本不会粘包,但是会丢数据,不可靠
tcp的协议数据不会丢,没有收完包,下次接收,会继续上次继续接收,己端总是在收到ack时才会清除缓冲区内容。数据是可靠的,但是会粘包。
粘包
由接收方造成的粘包
当接收方不能及时接收缓冲区的包,造成多个包接收就产生了粘包
客户端发送一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次
遗留的数据
由传输方造成的粘包
tcp协议中会使用Nagle算法来优化数据。发送时间间隔短,数据量小的包会一起发送,造成粘包
OSI7层模型TCP/IP五层模型
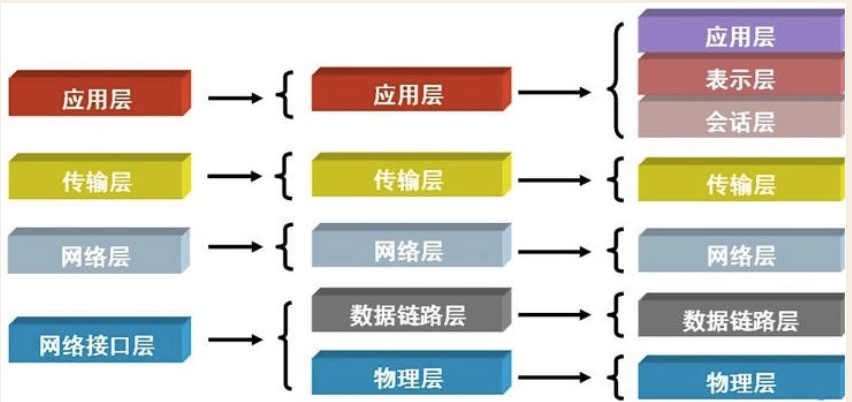
物理层
建立连接,传递信号
物理层功能:主要是基于电器特性发送高低电压(电信号),高电压对应数字1,低电压对应数字0
协议:RS-232、RS-449、X.21、V.35、ISDN、以及FDDI、IEEE802.3、IEEE802.4、和IEEE802.5
数据链路层
数据链路层的功能:定义了电信号的分组方式
统一分组标准--以太网协议ethernet
ethernet规定
一组电信号构成一个数据包,叫做‘帧’
每一数据帧分成:报头head和数据data两部分
# 其他的还有
Point-to-Point Protocal-PPP点到点
网络层
网络层功能:引入一套新的地址用来区分不同的广播域/子网,这套地址即网络地址
IP协议:
规定网络地址的协议叫ip协议,它定义的地址称之为ip地址,广泛采用的v4版本即ipv4,它规定网络地址由32 位2进制表示
范围0.0.0.0-255.255.255.255
一个ip地址通常写成四段十进制数,例:172.16.10.1
传输层
传输层功能:建立端口到端口的通信
tcp协议
udp协议
应用层
应用层功能:规定应用程序的数据格式。
比如:Email、WWW、FTP
数据库部分
存储引擎
InnoDB,MyISAM,NDB,Memory等
InnoDB
支持事务,特点是行锁
-- 表锁:
start transaction;
select * from tb for update;
commit;
-- 行锁,只为查到的加锁:
start transaction;
select id,name from tb where id=2 for update ;
commit
MyISAM
-- 不支持支持事务,也没有行锁,支持全文索引 start transaction; select * from tb for update; commit;
索引分类
普通索引,唯一索引,主键索引,联合索引,联合唯一索引
ps: 索引覆盖,索引合并
索引命中
索引的优缺点
好处:可以帮助你提高查询效率,数据量越大越明显缺点: 新增和删除数据时,效率较低(需重新排列索引)
无法命中索引的几种情况
- like '%xx' - 使用函数 - 类型不一致 - 不满足组合索引最左前缀
数据库其他
视图
函数
触发器
存储过程
数据库优化
表级别的优化
- 不用select *
- 固定字段在前面
- 将固定数据放入内存:choice
数据库级别的优化
- 读写分离(数据库的主从关系)
- 分库
- 分表
- 横向分 : 将拥有大量字段的表分成多张表
- 纵向分 : 将数据量大的表分成多张
- 利用缓存
WEB开发
MVC与MTV模型
MVC就是把web应用分为模型(M),控制器(C),视图(V)三层
模型负责业务对象与数据库的对象(ORM),视图负责与用户的交互(页面),控制器(C)接受用户的输入调用模型和视图完成用户的请求。
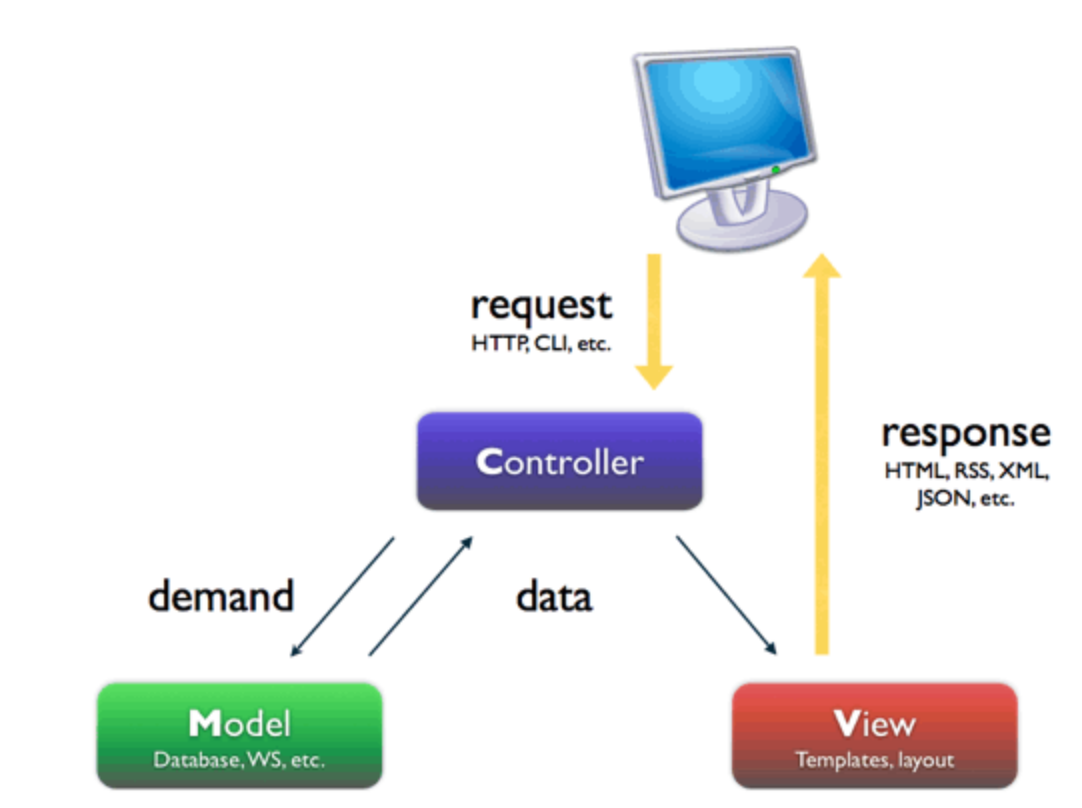
Django的MTV模式本质上与MVC模式没有什么差别,也是各组件之间为了保持松耦合关系,只是定义上有些许不同,Django的MTV分别代表:
- Model(模型):负责业务对象与数据库的对象(ORM)
- Template(模版):负责如何把页面展示给用户
- View(视图):负责业务逻辑,并在适当的时候调用Model和Template
ORM
对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。
简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中。
ORM解决的主要问题是对象和关系的映射。它通常把一个类和一个表一一对应,类的每个实例对应表中的一条记录,类的每个属性对应表中的每个字段。
- 类 --> 表
- 类的普通属性 --> 字段
- 类的一对一外键或多对一外键 --> 关联
- 对象 --> 一行数据
Django中在带了ORM,其余常用的就是SQLAlchemy,SQLAlchemy是脱离于WEB框架的ORM框架.
HTTP协议
HTTP协议基于TCP协议,规定了发送数据的格式,其特点是无状态,短连接
轮循长轮循
轮循长轮循的目的:因为HTTP请求是短连接,一次请求后得到相应就关闭连接,不能检测到数据的变化.轮循长轮循通过不断的连接服务器使得浏览器获得最新数据.
轮循 : 每隔固定时间就去访问一次服务器,获得新的数据. 缺点是不能够实时获取数据,有着固定时间的延迟,二是不断的连接服务器压力大
长轮循 : 最多连接服务器固定时间,在这期间有服务器检测数据变化,发生变化后立即响应,浏览器收到响应后再次发起连接. 缺点,还是不断的连接,服务器的压力大.
另外实现是浏览器可以获得新数据的方式还有WebSocket
WebSocket协议
WebSocket本质也是Socket,是基于TCP的一种新的网络协议。他实现了浏览器与服务器的长连接,使得服务器可以主动向浏览器发送数据.
其连接过程,可以分为握手过程和收发数据过程
握手过程: 浏览器连接后发送数据,服务器由数据中取出websocket-key,与魔法字符串拼接在进行加密,将结果添加进响应内容中,返回给浏览器.浏览器收到结果后验证,验证成功就会一直保持连接,
数据发送过程: 浏览器接收到的数据加密后的,解密方式是根据数据内容的第二个字节的后7位(payload_key)来判断数据部分的位置(127,126,<=125,分别对应着10字节后,4字节后,2字节后),数据部分的前四位是Mask_key,将他与后面的部分进行位运算,就可以得到相应内容
WSGI
web服务网关接口(Web Server Gateway Interface),是一套协议。WSGI接口定义非常简单,它只要求Web开发者实现一个函数,就可以响应HTTP请求.
WSGI的模块:
- wsgiref
- werkzurg
- uwsgi
以上模块本质:实现socket监听请求,获取请求后将数据封装,然后交给web框架处理。
常见请求类型
常见类型有GET,POST
跨域相关的有OPTION
RESTful的请求方式GET,POST,PUT,DELETE,PATCH
跨域请求:
跨域问题的产生
# 浏览器的同源策略
jsonp
# jsonp是利用了script标签的特性,动态的生成script标签,只能发送get请求
cors
# 本质上是添加响应头
RESTful规范
一种软件架构风格、设计风格,而不是标准,只是提供了一组设计原则和约束条件。
协议,域名,版本,路由,请求方式,url上的条件,响应状态码,响应内容,响应错误信息,Hypermedia API
显式特点:
- url后是名词s + GET请求 : 返回全部名词对象
- url后是名词s + POST请求 : 添加一个名词对象,并返回新增的数据对象
- url后是名词s/一个对象 + GET请求 : 返回单个资源对象
- url后是名词s/一个对象 + PUT请求 : 在服务器更新资源(客户端提供改变后的完整资源,返回单个资源对象
- url后是名词s/一个对象 + PATCH请求 : 在服务器更新资源(客户端提供改变的属性),返回单个资源对象
- url后是名词s/一个对象 + DELETE请求 : 删除一个资源对象,返回一个空文档
作用 : 响应内容是JSON字符串,使得Web,iOS,Android和第三方开发者变为平等的角色通过一套API来共同消费Server提供的服务
与其类似的还有更早的WebService架构
WebService是一个SOA(面向服务的编程)的架构,它是不依赖于语言,不依赖于平台,可以实现不同的语言间的相互调用,通过Internet进行基于Http协议的网络应用间的交互。 WebService实现不同语言间的调用,是依托于一个标准,webservice是需要遵守WSDL(web服务定义语言)/SOAP(简单请求协议)规范的。 WebService=WSDL+SOAP+UDDI(webservice的注册) Soap是由Soap的part和0个或多个附件组成,一般只有part,在part中有Envelope和Body。 Web Service是通过提供标准的协议和接口,可以让不同的程序集成的一种SOA架构。 Web Service的优点 (1) 可以让异构的程序相互访问(跨平台)(2) 松耦合 (3) 基于标准协议(通用语言,允许其他程序访问) Web Service的基本原理 (1) Service Provider采用WSDL描述服务 (2) Service Provider 采用UDDI将服务的描述文件发布到UDDI服务器(Register server) (3) Service Requestor在UDDI服务器上查询并 获取WSDL文件 (4) Service requestor将请求绑定到SOAP,并访问相应的服务。
Django的rest_fraemwork的一些注释主要是注视了views文件,表明了认证,权限的过程
Django中的rest_framework框架
自己通过CBV的方式去实现restful接口是非常麻烦的,其中请求数据(非GET,POST)的获取,以及获取数据的序列化都需要自己去完成,
而rest_framework提供了解析器和序列化功能,
rest_framework的view关系
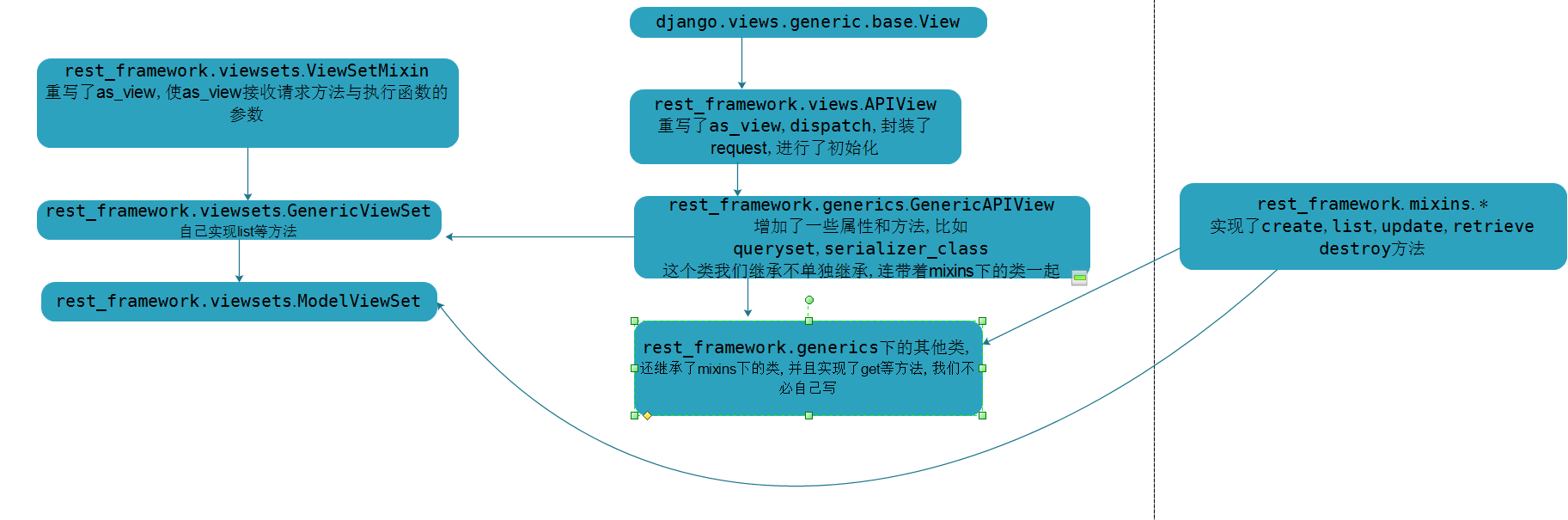
主要分类:
- APIview
- 简单封装了view
- GenericAPIView
- 增加了一些属性和方法,如queryset,serializer
- 其包下还有一些类,继承了mixins下的一些类和GenericAPIView,并且实现了get,post等方法
- GenericViewSet
- 其父类中重写as_view,使其接收请求方式与执行函数的关系,执行函数需自己实现
- 其包下还有一些类(主要是ModelViewSet),继承了mixins下的一些类和GenericViewSet,只要在路由里指定请求方式与list,create等函数的对应关系即可,并且可以自动生成url
ContentType请求头
# 发送信息至服务器时内容编码类型。用来指明当前请求的数据编码格式 # 默认方式application/x-www-form-urlencoded 数据形式a=1&b=2 # application/json 发送json字符串 # multipart/form-data 上传文件
JS中的变量提升与函数提升
// 在ES6之前,JavaScript没有块级作用域(一对花括号{}即为一个块级作用域),只有全局作用域和函数作用域。
// 变量提升即将变量声明提升到它所在作用域的最开始的部分.即在作用域的最开始就声明了变量,但到复制部分才赋值
// js中创建函数有两种方式:函数声明式和函数字面量
console.log(f1); // function f1() {}
console.log(f2); // undefined
function f1() {} // 函数声明式
var f2 = function() {} // 函数字面量式式。只有函数声明才存在函数提升!
// 而在ES6新增了局部变量声明和常量声明
let a = 12; // 局部变量的声明
const b=5; //常量声明,不可被修改
常见请求头
User-Agent : 浏览器信息 Host : 服务区域名 Referer : 通过哪里的链接过来的 Origin : 跨域相关 Content-Type : POST和PUT请求的数据类型 Cookie : 客户端存储的保持会话信息 # 关于Django获取请求头 request.META中可以获取去获取请求头,但对于一些请求头Django会在其前面加上HTTP_,并将请求头大写
常用的一些状态码
2开头 (请求成功)表示成功处理了请求的状态代码。 200 (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。 201 (已创建) 请求成功并且服务器创建了新的资源。 202 (已接受) 服务器已接受请求,但尚未处理。 203 (非授权信息) 服务器已成功处理了请求,但返回的信息可能来自另一来源。 204 (无内容) 服务器成功处理了请求,但没有返回任何内容。 205 (重置内容) 服务器成功处理了请求,但没有返回任何内容。 206 (部分内容) 服务器成功处理了部分 GET 请求。 3开头 (请求被重定向)表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。 300 (多种选择) 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。 301 (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。 302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。 303 (查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。 304 (未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。 305 (使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。 307 (临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。 4开头 (请求错误)这些状态代码表示请求可能出错,妨碍了服务器的处理。 400 (错误请求) 服务器不理解请求的语法。 401 (未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。 403 (禁止) 服务器拒绝请求。 404 (未找到) 服务器找不到请求的网页。 405 (方法禁用) 禁用请求中指定的方法。 406 (不接受) 无法使用请求的内容特性响应请求的网页。 407 (需要代理授权) 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。 408 (请求超时) 服务器等候请求时发生超时。 409 (冲突) 服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。 410 (已删除) 如果请求的资源已永久删除,服务器就会返回此响应。 411 (需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。 412 (未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。 413 (请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。 414 (请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。 415 (不支持的媒体类型) 请求的格式不受请求页面的支持。 416 (请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态代码。 417 (未满足期望值) 服务器未满足"期望"请求标头字段的要求。 5开头(服务器错误)这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错。 500 (服务器内部错误) 服务器遇到错误,无法完成请求。 501 (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。 502 (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。 503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。 504 (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。 505 (HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。
Django请求声明周期
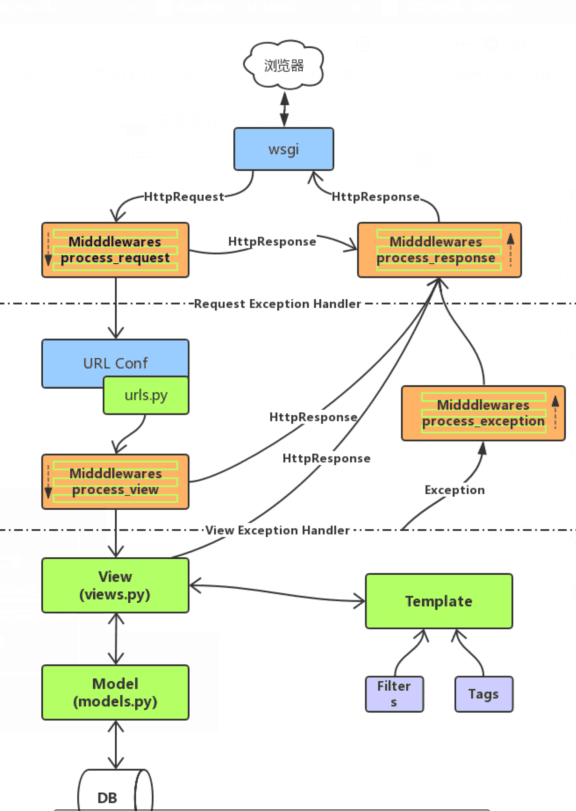
Flask中的上下文管理(request,session的封装与调用)
这里是之前写的一篇博客Flask请求流程超清大图
- 项目启动时会生成两个LocalStack实例_request_ctx_stack和_app_ctx_stack ,每个对象都有一个_local属性,是一个Local实例
- 还会产生4个LocalProxy实例,分别是request,session,current_app还有g
- Local类似于threading.local,但是Local还能够为协程来分隔数据
- 当请求来临时,会产生一个ctx即RequestContext对象,这个类封装了request和session,session在实例化是还是个None
- 然后会调用ctx的push()方法,而ctx的push回将自身作为参数,调用LocalStack实例的push方法,在LocalStack的方法中通过.的方式向_local实例中设置了一个空列表,又将RequestContext实例追加进其中,而Local的setattr方法则是完成了以进程或线程ID为键将设置的列表作为置
- 取值过程则是通过导入rsquest,或session,调用了LocalProxy中的__getattr__或__setitem__,其中有执行了类初始化时是传递的偏函数,通过LocalStack从Local中取得RequestContext,又获得了想要的属性,为此属性设置值或从此属性中取值
Django与Flask的区别
Django框架比较全面,内部组件多比如 admin ORM 认证 Form modelForm Session
Falsk只提供了必备的功能,但是可以下载组件来拓展他
另外,Django与Falsk的请求数据也是以不同的方式传递的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号